
입사했을 당시, 회사 백엔드 코드의 스택은 nestjs + graphql 이었다.
그 당시 graphql 에 대해서 잘 알지 못했고, 코드 구조를 보고 graphql 은 원래 이렇게 사용하는구나 싶었다.
새로 오신 시니어 개발자 분이 현재 코드 구조가 graphql 의 철학과 맞지 않는 것 같다 라는 의견과 함께,
대규모 개편에 앞서 graphql 을 철학에 맞게 사용하거나 혹은 restapi 를 새롭게 도입하자 라는 의견을 제시해줘 고민을 하다가 시간이 촉박한 탓에 그래도 좀 더 익숙하고 레퍼런스가 많은 restapi 를 사용하자라는 결론이 났었다.
결과적으로 대규모 개편은 restapi 로 개발을 하였다.
배포를 하고 나니, 그렇다면 정말 graphql 의 철학은 무엇인가? 라는 의문이 들기 시작한다.
다시 초심의 마인드로 겸손하게 하나하나 차근차근 공부해보자.
graphql 은 ql 에서 유추할 수 있듯이, 데이터를 가져오는 쿼리 언어이자, 서버측 런타임이다.
restapi 는 하나의 api 요청에 하나의 데이터를 가져올 수 있지만,
graphql 은 하나의 api 요청에 여러 데이터 소스에서 데이터를 가져올 수 있다.
✅ schema
gql 에서 사용하는 모든 resolver(query, mutation, subscription), model 등을 설명 및 정리한 것이다.
# ------------------------------------------------------
# THIS FILE WAS AUTOMATICALLY GENERATED (DO NOT MODIFY)
# ------------------------------------------------------
type Message {
id: String!
message: String!
}
type Query {
getMessages: Message!
}graphql 의 가장 큰 장점은 프레임워크와 상관없이 프론트에서 schema generate 를 통해서 schema.gql 전체를 한번에 긁어올 수 있다는 것 같다. 이는 정말 엄청난 생산성을 높일 수 있다.
rest api 는 이것이 불가능해서 생각보다 불편했다.
✅ resolver
schema 에 정리된 데이터를 호출하기 위한 일종의 controller 같은 것이다. 실제 데이터를 가져오는 로직이 들어가 있다.
✅ schema first vs code fisrt
- 설계 방법 중에 스키마를 먼저 설계 하고 이를 바탕으로 코드를 짜는 방법이 있고,
- 코드를 먼저 생성하고 graphql module 의
autoSchemaFile를 이용하여 스키마를 자동 생성하는 방법이 있다.
검색을 해보니 말들이 많다. 각자의 장점과 단점이 있다.
schema fisrt 가 레퍼런스가 더 많고, 이를 우선적으로 공부를 하라고 많이들 나와있다. 하지만, 이 방법이 현업에서 정말 더 좋을까?
schema 를 먼저 설계를 하고 배포를 하면 시간을 더 줄일 수 있는건 확실하다. schema 를 기반으로 프론트와 백엔드가 동시에 개발을 할 수 있기 때문이다.
하지만 결정적으로 resolver 와 schema 간의 동기화가 맹점이다.
nestjs 를 restapi 로 개발을 하다 보니, 동기화 작업이 여간 귀찮고 까탈스러운 일이 아니였다. swagger 를 도입한다고 해도, 불편한 점이 더러 있었다.
동기화를 위해서는 code-first 방식이 더 좋을 것 같다.
(개발을 하면서 장단점을 좀 더 비교해보겠다)
✅ graphql 장점
GraphQL 호출은 단일 왕복으로 처리되며 클라이언트는 오버페칭 없이 요청한 결과만 얻습니다 라는 말은 너무 매력적으로 다가온다. fetching 이 하나라면, 네트워크 비용을 줄일 수 있다는 말로 들리는데, 대규모 배포 전의 graphql 백엔드 코드는 단일 왕복이 아니였다. 이를 중점적으로 공부를 해보려고 한다.
REST API의 단점으로 많이 거론되는 바로 ‘오버패칭(필요한 정보 외에도 불필요한 정보까지 받게 되는 것)’과 ‘언더패칭(필요한 정보를 서버에서 가져오지 못해 추가 요청을 해야 하는 경우)’ 문제도 있다.
한 예로, 현재 운영중인 서비스에는 제조 파트너 정보를 보여주는 화면이 있다.
해당 화면에는 파트너의 각 종 정보를 다 보여줘야 한다. (프로필, 포트폴리오, 리뷰, 소개서, 인증서, 통계, 장비, etc..)
이것들을 호출하기 위해 너무 많은 api 를 호출해야 한다고 생각했다. 이러한 문제도 graphql 로 어느정도 해결할 수 있지 않을까?
✅ 코드
/// app.module.ts
@Module({
imports: [
GraphQLModule.forRoot<ApolloDriverConfig>({
driver: ApolloDriver,
playground: true,
autoSchemaFile: 'src/schema.gql',
path: 'v1/gql',
}),
ChatModule,
],
controllers: [AppController],
providers: [AppService],
})
export class AppModule {}/// chat.resolver.ts
import { Resolver, Query } from '@nestjs/graphql';
import { ChatService } from './chat.service';
import { Message } from './model';
@Resolver('Chat')
export class ChatResolver {
constructor(private readonly chatService: ChatService) {}
@Query(() => Message)
async getMessages(): Promise<Message> {
return await this.chatService.getMessages();
}
}
/// model/message.ts
import { Field, Int, ObjectType } from '@nestjs/graphql';
import { randomUUID } from 'crypto';
@ObjectType()
export class Message {
@Field(() => String)
id: string;
@Field(() => String)
message: string;
}
ApolloDriver 이 @Resolver(), @ObjectType(), @InputType() decorator 를 다 긁어와서 schema 를 자동 생성해주는 것 같다.
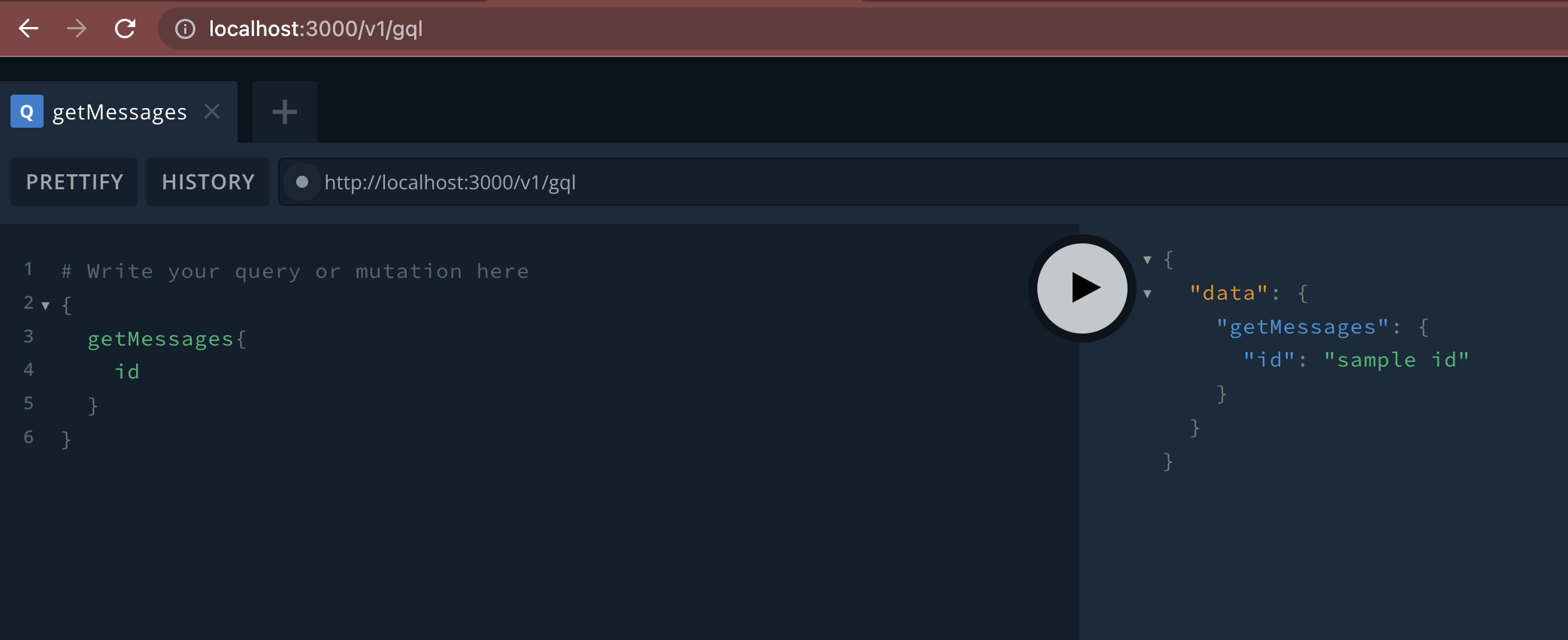
다음과 같이 프론트는 백엔드에서 던져주는 값들 중에 원하는 값만 받을 수 있다. (message 필드는 무시하고, id 만 받은 것을 볼 수 있음)
다음에는 orm 및 mutation 에 대해서 알아보겠다.
REF
