pg join
1. 기본 개념
1) tb_rfq_file 테이블의 pk

postgres pk는 자동적으로 인덱스를 생성한다. (fk는 인덱스 생성 X)
2) tb_rfq_file 테이블의 index

복합 인덱스일 경우, 첫번때 인덱스 키가 조회조건에 없으면 사용할 수 없다 → 첫번째 키를 조회조건에 자주 사용하는 칼럼으로 세팅을 해야함(순서가 중요함)
file_type = A and file_id = B 가능
file_type = A and rfq_id = C 가능
file_id = B and rfq_id = C 불가능
3) tb_rfq_file 테이블의 FK 로는 인덱싱을 할 수 없다.
postgres의 fk 자동으로 인덱스를 생성하지 않는다.

4) 인덱스 생성 시 데이터를 정렬해서 저장하기 때문에 order by 에서 인덱스를 탈 수 있다.
5) postgres scan algorithm
-
Sequential Scan → full scan
-
Index Scan
-
Index Only Scan
-
Bitmap Scan
-
TID Scan
-
index 가 있다고 무조건 index scan 하는 것은 아니다 (ex. 100만개의 데이터 중에 99만개를 가져올때는 그냥 full scan 한다)
select tf.file_id from tb_file tf where tf.file_id > 10;
select tf.file_id from tb_file tf where tf.file_id > 100000;
2. 예시
원본
select *
from tb_rfq tr
join (select *
from tb_rfq_file trf
join tb_file tf on trf.file_id = tf.file_id
) file
on file.rfq_id = tr.rfq_id
where
tr.status_type_id = 1
and tq.rfq_id is null
-
pk로도 index 로도 index scan 을 할수가 없는데 왜 Index Scan 으로 분석할까?
[ sorting by join table, joined table column ]
select * from tb_rfq_file trf join tb_file tf on trf.file_id = tf.file_id order by trf.file_type, tf.file_id;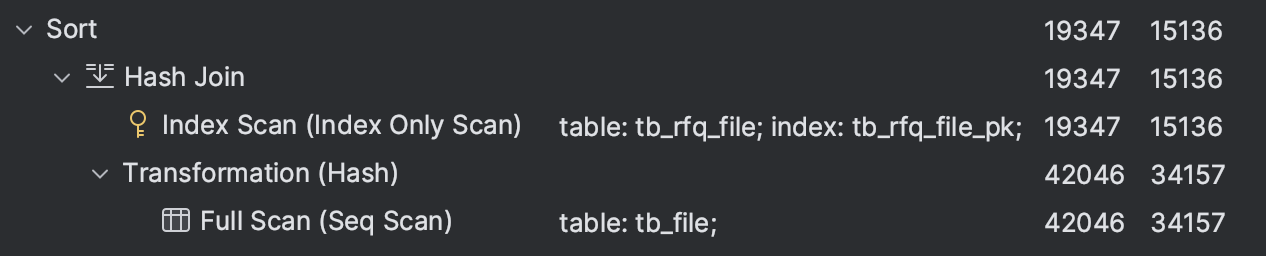
index 의 첫번째 key 인 file_type 으로 sorting 하니까 인덱스를 타는건가…?
[ sorting by join table column ]
select * from tb_rfq_file trf join tb_file tf on trf.file_id = tf.file_id order by trf.file_type;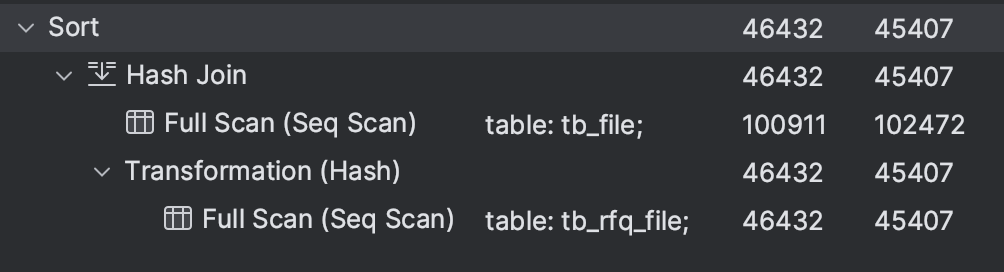
join 이 걸려 있을 경우 join 주체 테이블의 칼럼으로 sorting 하려고 하면 index 를 안탄다
[ sorting by joined table column ]
select * from tb_rfq_file trf join tb_file tf on trf.file_id = tf.file_id order by tf.extension;
이건 왜 타는거지…?
join 대상자의 칼럼으로 sorting 을 할때 join 주체자의 PK 로 인덱스를 탄다…
[ sorting by one table indexed key column ]
select * from tb_rfq_file trf order by trf.file_type;
아무 join 없이 sorting 할때는 index 에 의해서 조회한다 → 일반적으로 알고 있는 사항
[sorting by joined table column & join with any column]
select * from tb_rfq_file trf join tb_file tf on trf.create_date = tf.create_date order by tf.extension;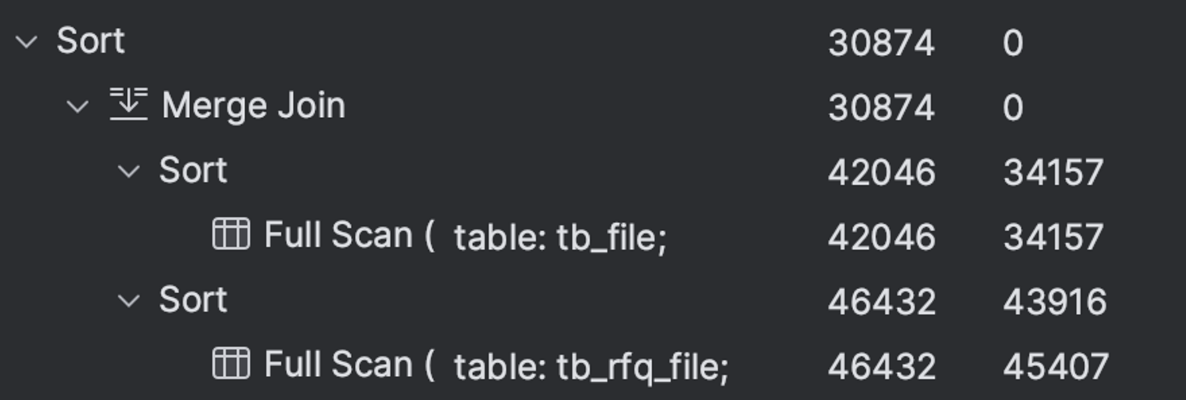
joined table 의 column 으로 sorting 해도 join column 이 무관한 column 이면 full scan 한다.
이로써 내릴 수 있는 결론!
join, sorting 을 한다? → joined table 의 column으로 sorting + fk 로 join → join table 의 pk 들 중 한개로 index scan 을 한다→ driving table, driven table 을 때때로 결정한다.
→ 인덱스 걸려 있는 테이블이 driven 으로 된다 일반적응로
join table 의 index key 로 scan 안하는 이유 → joined table 과는 fk 로 관계가 맺어져 있기 때문에 pk 로 index scan 한다.
1차 개선
select *
from tb_rfq tr
join lateral (select *
from tb_rfq_file trf
join tb_file tf on trf.file_id = tf.file_id and tr.rfq_id = trf.rfq_id
limit 1) file
on true
join (select *
from tb_rfq_subservice_type trst
join tb_type_service tts2 on trst.service_type_id = tts2.service_type_id
group by trst.rfq_id) sub_services on sub_services.rfq_id = tr.rfq_id
where
tr.status_type_id = 1
and tq.rfq_id is null
여기서 index scan 하는 이유는?
lateral join 은 column의 특정 값을 정해 놓고 nested loop 이기 때문에 tr.rfq_id 가 정해진 상태이다
→ 하나의 값을 두고 scan 할때는 index scan 을 한다.
→ 데이터의 양 및 분포도에 따라 결정되기 때문에 lateral join 을 쓸지 말지 잘 결정해야 한다
일반화를 위한 샘플 테스트
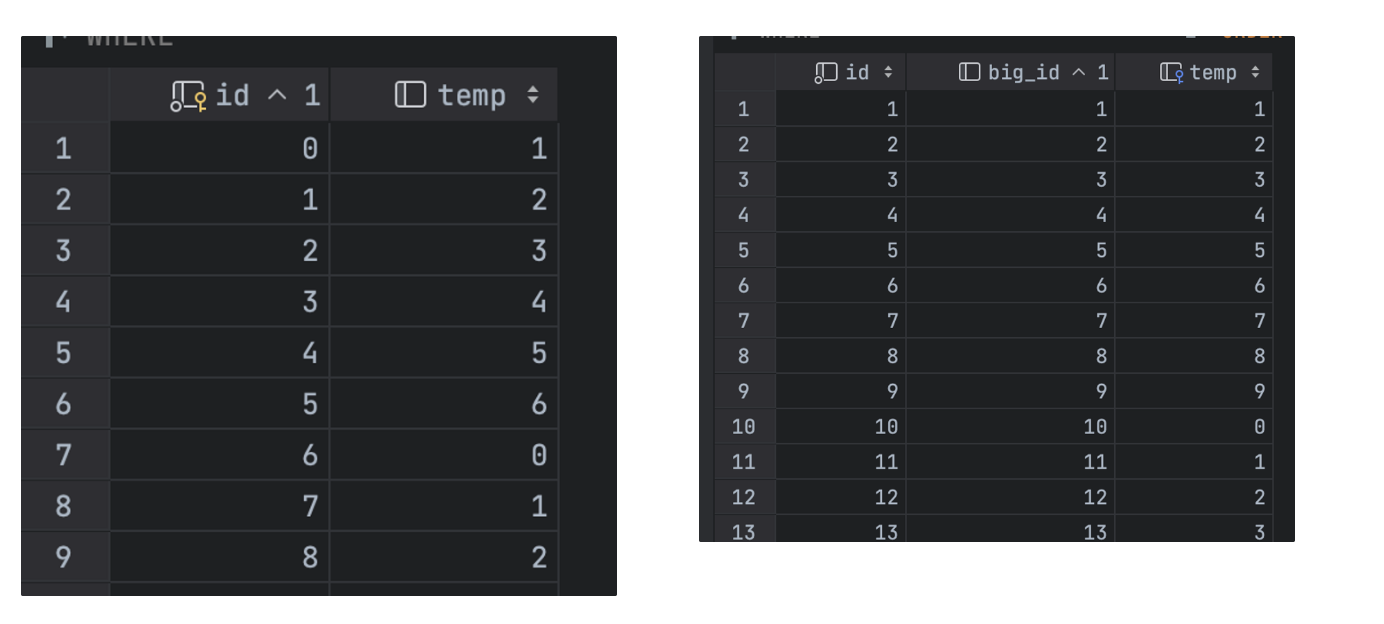
데이터 삽입 sp
-- big --
create procedure _insert_bulk_big(IN _range integer)
language plpgsql
as
$$
declare
_i integer;
max_v integer;
BEGIN
select max(tjtb.id)
into max_v
from _tb_join_test_big tjtb;
for _i in 1.._range
loop
insert into _tb_join_test_big(id, temp) VALUES (_i + max_v, (_i + _range) % 7);
end loop;
end;
$$;
-- small --
create procedure _insert_bulk_small(IN _range integer)
language plpgsql
as
$$
declare
_i integer;
max_v integer;
BEGIN
select max(tjts.id) into max_v from _tb_join_test_small tjts;
for _i in 1.._range
loop
insert into _tb_join_test_small(id, big_id, temp) VALUES (_i + max_v, _i, (_i + _range) % 10);
end loop;
end;
$$;
데이터 분산도 : 기준 테이블의 pk가 fk 테이블에 몇개정도 있는지
ex) [rfq테이블 총 100개, 견적서 테이블 총 100개] rfq A 하나에 견적서 두개가 달렸다? → 2% (2/100)1. 데이터 분산도 10%
실행 쿼리 1
select *
from
_tb_join_test_big tjtb
join
_tb_join_test_small tjts
on tjtb.id = tjts.temp;쿼리 실행 분석 기준
-
데이터의 양
index scan 할 수 있는 테이블은 big table 밖에 없다 (PK)
table tb_join_test_big tb_join_test_small row count 1,000,000 1,000 
driving table : small
driven table : big
small 의 데이터양이 적지 않아 big table 먼저 인덱스 scan 하고 그거에 대해서 small table 을 full scan
table tb_join_test_big tb_join_test_small row count 1000,000 10,000 
small 의 데이터양이 적지 않아 big table 먼저 인덱스 scan 하고 그거에 대해서 small table 을 full scan
driving table : big
driven table : small
nested loop 을 이용한다는 것은 driving table 의 row 가 현저히 적다는 것이다 (row 가 많다면 그만큼 여러번 반복해야 하기 때문에 사용하지 않음) → 여기서 driving table 은 driving table 의 index table!
table tb_join_test_big tb_join_test_small row count 1,000,000 1,000,000 
-
join 조건에 index 가 걸려있는 테이블(A) 보다 그렇지 않은 테이블(B)의 rows 수가 현저히 적으면 B를 먼저 scan하고 (driving table) A를 추후에 index scan 한다.
optimizer가 Merge join 이 더 빠르다고 판단
-
그 반대인 경우 A 의 index table 을 scan 하고 B 테이블을 full scan 한다.
optimizer가 nested loop 이 더 빠르다고 판단
-
2. 데이터 분산도 0% → 거의 1:1 매칭이다
실행 쿼리 1
select *
from
_tb_join_test_big tjtb
join
_tb_join_test_small tjts on tjtb.id = tjts.big_id;쿼리 실행 분석 기준
-
데이터의 양
table tb_join_test_big tb_join_test_small row count 10 10 
table tb_join_test_big tb_join_test_small row count 1,000 10 
table tb_join_test_big tb_join_test_small row count 1,000,000 1,000,000 
driving table : big
driven table : small
hash table : 상대적으로 row 수가 적은 테이블을 대상으로 hash table 을 만들고 row 수가 큰 테이블을 scan 하면서 해당 row에 맞는 row를 hash table에서 찾는다일반적으로 인덱스 테이블로는 해시테이블을 사용하지 않고, b tree 테이블을 사용한다고 한다 → 인덱스 테이블을 사용하지 않고, 저 방법이 더 빠르니 optimizer 가 저 방법을 선택하지 않았을까
실행 쿼리 2
select *
from
_tb_join_test_big tjtb
join
_tb_join_test_small tjts on tjtb.id = tjts.big_id **where tjtb.id > 10;**쿼리 실행 분석 기준
-
데이터의 양
-
table tb_join_test_big tb_join_test_small row count 10 10 
-
table tb_join_test_big tb_join_test_small row count 1,000 10 
-
table tb_join_test_big tb_join_test_small row count 1,000,000 10 
where 조건절에 index가 걸려있어도,
1,000,000 전까지는 그냥 full scan 이 더 빠르다고 판단했지만, 1,000,000 이후로는 index scan 이 더 빠르다고 판단함
optimizer 가 nested loop 을 이용해서 조회하는 것이 가장 이상적이라고 판단
-
하지만 여기서 small table 의 row를 증가시켜보자
table tb_join_test_big tb_join_test_small row count 1,000,000 1,000,000 
데이터수가 적당해야 index scan 을 했을 경우 효과를 볼 수 있지만 너무 많으면 index scan 이 더 오래걸린다고 판단하고 hash join 을 통한 full scan 하는 것을 볼 수 있다.
-
추가적으로 small table 에 index 를 걸어주면?

select * from _tb_join_test_big tjtb join _tb_join_test_small tjts on tjtb.id = tjts.big_id where tjtb.id > 10 **and tjts.temp > 4;**
더 효과를 볼 수 있는 small table 먼저 index scan 하고, big table 은 그냥 full scan 한다.
-
index가 걸려있는 where 조건절의 범위를 줄여보자
select * from _tb_join_test_big tjtb join _tb_join_test_small tjts on tjtb.id = tjts.big_id where **tjtb.id > 500000 and tjts.temp > 4;**
이 경우에는 big table 을 먼저 full scan 하고 small table 을 index scan 하는 것을 알 수 있다.
바로 5 예시와 다른점은 where 조건절에서의 big table 의 pk 범위인데
위에서는 10보다 큰 범위를 조회하면 거의 99%을 조회해야 한다. 하지만 6 예시에서는 50%만 조회 하면 된다.
driving table을 최대한 줄일 수 있기 때문에 big table 먼저 조회하는 것을 알 수 있다.
-
결론
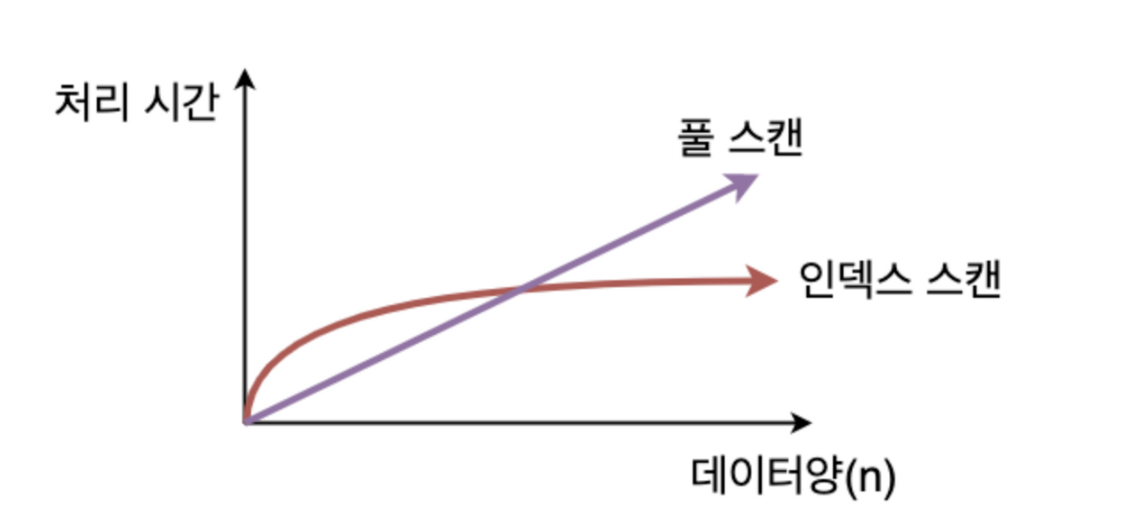
데이터의 양 및 분포도에 따라 postgresql optimizer 가 driving table 과 driven table 을 결정한다.
결정하는 방향성은 index 를 탈 수 있는지, 탔을 때 데이터가 현저히 줄어드는지, full scan 을 했을 때 어떤 테이블의 row 수가 적은지 등등을 기준으로 판단한다.
그 후에 어떤 join algorithm 을 선택하는지 또한 optimizer 의 소관이다.
- hash join
- merge join
- nested loop
중에 어떤 것을 쓸 지는 indexed scan 된 테이블 혹은 full scan 된 테이블간의 관계성을 보고 결정한다.
처음에 스키마를 잘 설계 하는것이 가장 중요하지만, 운용하고 있는 서비스의 특성 및 스키마의 성질에 따라 인덱스를 잘 설계 하는 것이 가장 간단하고 효율적인 방법이라고 생각한다.
또한 조건절에서 indexed key 를 사용하고 데이터를 전체를 보여주는 것이 아니라면 최대한 제한을 걸어서 조회하면 높은 효율을 볼 수 있다. 때에 따라 lateral join 이 좋은 결과를 보일 수 있는 것 처럼
