저번에 pg_pool_connection_timed_out 에러가 발생했었다.
일반적으로 디비를 이용하기 위해 pool 안에 몇개의 connection을 담아두고, 필요할 때 마다 사용하고 반납하고 사용하고 반납하고 하는 방식의 방법을 사용한다.
예상1.
어디선가 connection release를 안해주던가… → 지금까지 확인해본 결과 없는 것으로 판단
예상2.
fetch 중에 지연율이 높은 쿼리가 connection을 반환하지 않아, 다른 워커스레드들이 connection을 가져갈 수 없었다. 지연이 지속되다 보면 그럴 수 있다. → 쿼리속도 개선 필요
예상3.
AUTO VACUUM이 정상적으로 처리가 되지 않아서..?
AUTO VACUUM
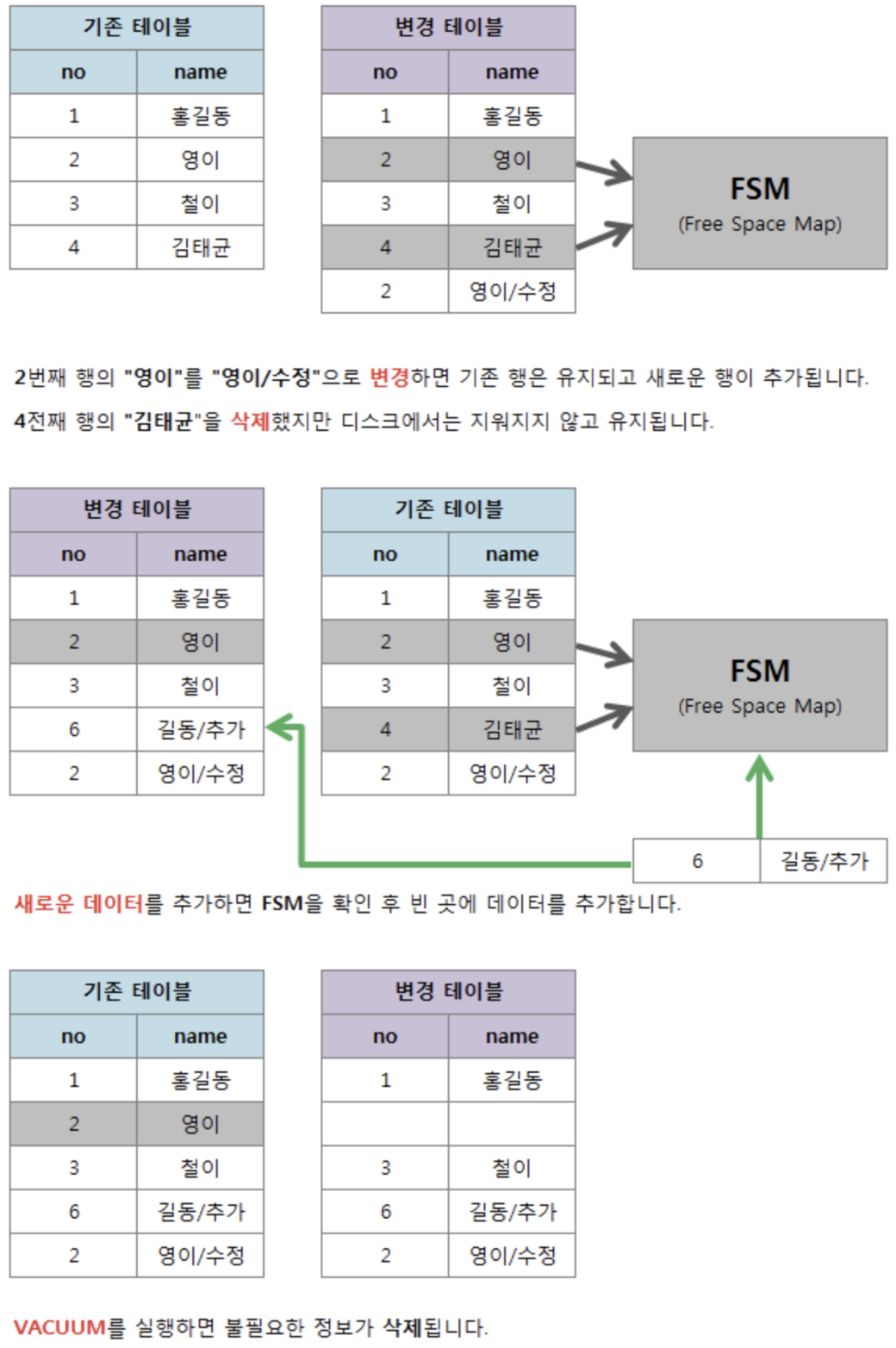
postgresql 에서는 update, delete 할때, 실제로 row를 제거하지 않고, 새로 수정되는 정보를 추가하고, 기존에 있는 데이터에는 삭제표시를 한다(백업용, 다른 rdbms와 다르게 ) → 이렇게 해서 남겨지는 기존의 row들을 dead tuple 이라고 한다. 이러한 dead tuple 들을 제거하여 FSM(Free Space Map)으로 넘겨주기 위한 역할을 한다.
만약, U,D가 발생을 하면, postgresql은 다음과 같이 작동한다.
- FSM 에 여유가 있는지 확인한다. 없으면 FSM 을 추가적으로 확보한다
- FSM 의 빈 공간에 업데이트 될 데이터를 기록한다. 이 때 기존 테이블에 새로운 tuple 이 추가 된다.
- 기록이 완료되면, 기존 column(혹은 row)을 가리키는 포인터를 새로 기록된 tuple 로 변경한다.
- 업데이트 이전 정보가 기록된 공간은 더 이상 참조가 되지 않게 한다. 이 참조가 되지 않는 tuple 이 dead tuple 이다.
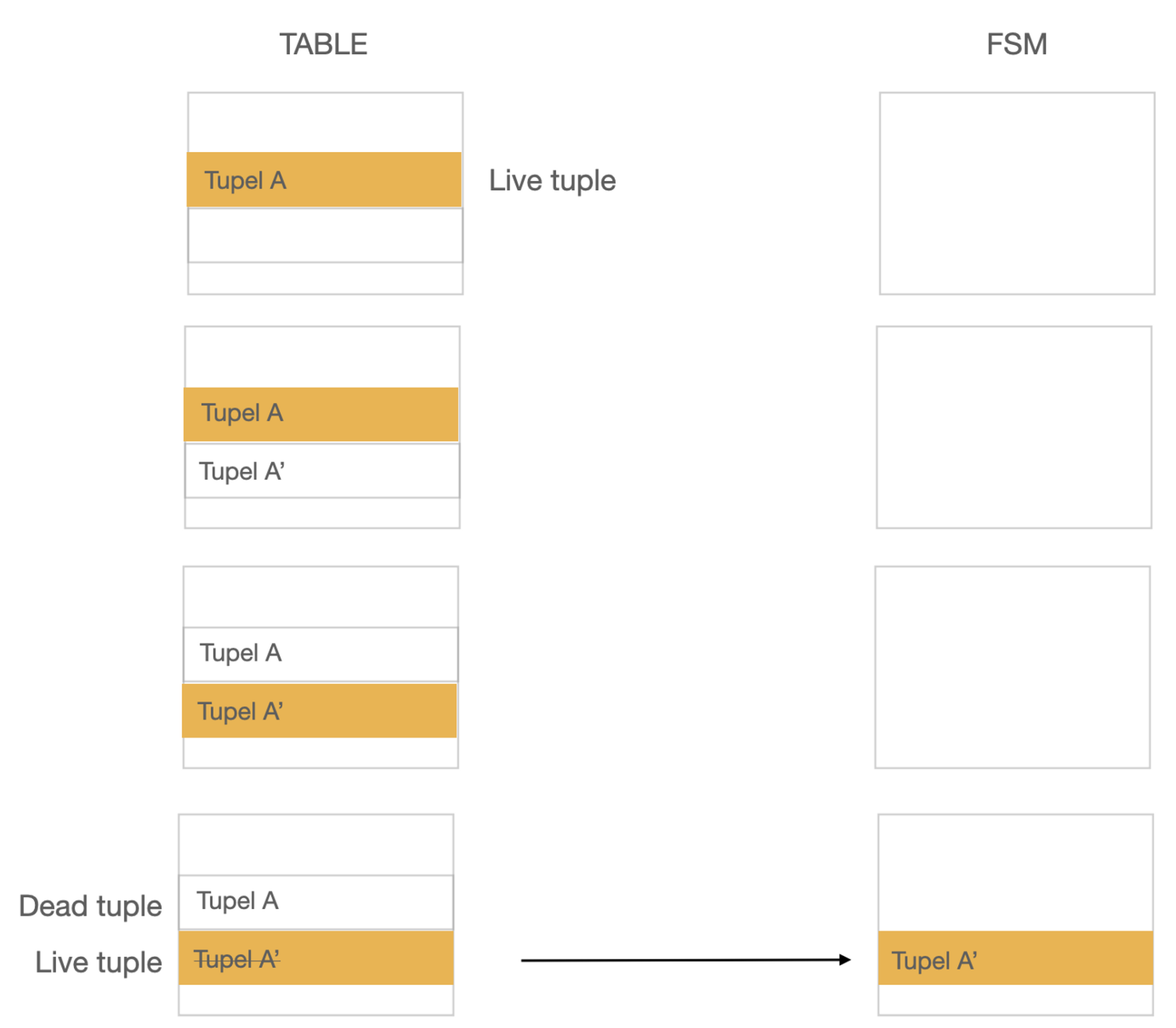
이런작업이 반복되면 FSM이 불필요한 데이터로 쌓이게 된다.
이러한 데이터를 지워주는 작업을 VACUUM이라고 한다.
이렇게 auto vacuum 으로 FSM을 비워줘야 하는데, vacuum 작업에도 리소스가 들기 때문에 부하를 일으킬 수 있다.
VACUUM 최적화
실행중인 VACUUM 세션 확인하기
SELECT
datname,
usename,
pid,
CURRENT_TIMESTAMP - xact_start AS xact_runtime,
query
FROM
pg_stat_activity
WHERE
upper(query)
LIKE '%VACUUM%'
ORDER BY
xact_start;장애 대응 프로세스
1.응답 지연이 되고 있는 쿼리 세션 중단하기 (superuser 만 가능)
SELECT
pg_terminate_backend(pid)
FROM
pg_stat_activity
WHERE
state IN ('active')
AND (now() - query_start) > interval '1 seconds'
AND wait_event IN ('MultiXactOffsetControlLock', 'multixact_offset', 'SLRURead');2.AUTO VACUUM 강제 종료하기
ALTER TABLE public.[table_name] SET (autovacuum_enabled = false);강제종료할 테이블 조회
2-1. 나이가 많은 테이블
SELECT
c.oid::regclass AS table_name,
greatest(age(c.relfrozenxid), age(t.relfrozenxid)) AS age,
pg_size_pretty(pg_table_size(c.oid)) AS table_size
FROM
pg_class c
LEFT JOIN pg_class t ON c.reltoastrelid = t.oid
WHERE
c.relkind = 'r'
ORDER BY
2 DESC
LIMIT 150;2-2. dead tuple 이 많은 테이블
SELECT relname AS TableName,
n_live_tup AS LiveTuples,
n_dead_tup AS DeadTuples,
n_dead_tup / n_live_tup AS ratio,
last_autovacuum AS Autovacuum,
last_autoanalyze AS Autoanalyze,
*
FROM pg_stat_user_tables
WHERE n_dead_tup > 0
order by n_dead_tup desc;→ last_autovacuum 확인하면 auto_vacuum 이 돌고 있는 것을 알 수 있다.
3.VACUUM 수동으로 실행하기
vacuum VERBOSE public.[table_name];디비에 돌아가고 있는 auto vaccum은 정상적으로 돌아가고 있던 것으로 확인되었다.
그렇다면 이유는 너무 오래 걸리는 쿼리가 있던가, 혹은 spec 이 딸려서...?는 아닌거 같고..
전반적으로 오래 걸리는 쿼리들을 걷어내야겠다.
