
사실 서버 모니터링 처음이다.
정보 공유를 할 입장은 안되지만 최대한 여기저기서 찾아와서 정리해보겠다.
📌 현재 진행중인 서비스
쿠버네티스 기반으로 MSA 서비스를 제작중이다. 각 서비스 역할이 철저히 분리되어 있는 상황이고, 나는 여기서 달리3 API를 이용한 스프링 서비스와 엘라스틱 서치의 벡터디비를 이용한 FAST API서비스를 맡고 있다.
자세한건 프로젝트 다 끝나고 회고하며 적도록 하겠다.
위 내용은 몇번 언급했어서 아마 내 예전 글들을 보면 대충 과정이 나올 것이다. 적은게 꽤 있어서 이걸 하나의 글 폴더로 묶어야하나 고민중이다.
아무튼 서비스 개발이 거의 끝나가는 단계이기에 서버 모니터링과 test code작성만이 남아있다.
그 중에서 서버 모니터링과 관련한 부분에 관해 정리해보고 실습까지 해볼 예정이다.
📌 서버 모니터링의 필요성
- 문제 즉시 감지 및 대응
- 성능 저하, 서비스 중단, 보안 침해와 같은 문제 즉시 감지 가능
- 사전에 문제를 예측하고, 빠른 대응을 할 수 있음
- 자원 사용량을 추적하고, 필요에 따라 자원을 할당/확장이 가능
- 보안 위협 감지
- 모니터링을 통한 규정 준수 지원
- 규정 준수: 기업이 법적으로 요구되는 표준과 규칙을 지키는 것
- 서버 모니터링을 통해 민감한 정보가 저장되고 전송되는 방식 지속적 감지
- IT 인프라의 효과적인 계획 및 확장
- 사용량 패턴, 성능 추세, 자원의 최적화된 할당을 이해하는 데 중요한 데이터를 제공
📌 서버 모니터링의 종류
🔍 장비 모니터링
- 시스템을 구성하는 장비에 문제가 있는지 체크하여 하드웨어나 네트워크 장애 발생 유무를 확인
- 클라우드로 시스템을 구축한 경우에는 클라우드 서비스 정상 여부를 클러스터 밖에서 모니터링함.
🔍 서비스 모니터링
- 서비스에 문제가 있는지 체크
- 만약 문제가 있는 경우에는 로그를 확인하고 프로세스를 재기동하는 등 필요한 조치를 취함.
🔍 서버 및 네트워크 리소스 모니터링
- 서버의 CPU, 메모리, 스토리지 등의 리소스 사용률과 네트워크 대역을 모니터링하여 병목현상이 발생할 수 있는 지점이 있는지를 체크
- 시스템 부하에 따라 장비나 회선을 증설할 수 있도록 검토
- 클라우드 시스템인 경우 불필요한 리소스가 있는지도 모니터링 하여 운영비를 절감
📌 스프링부트, FAST API 모니터링 방법
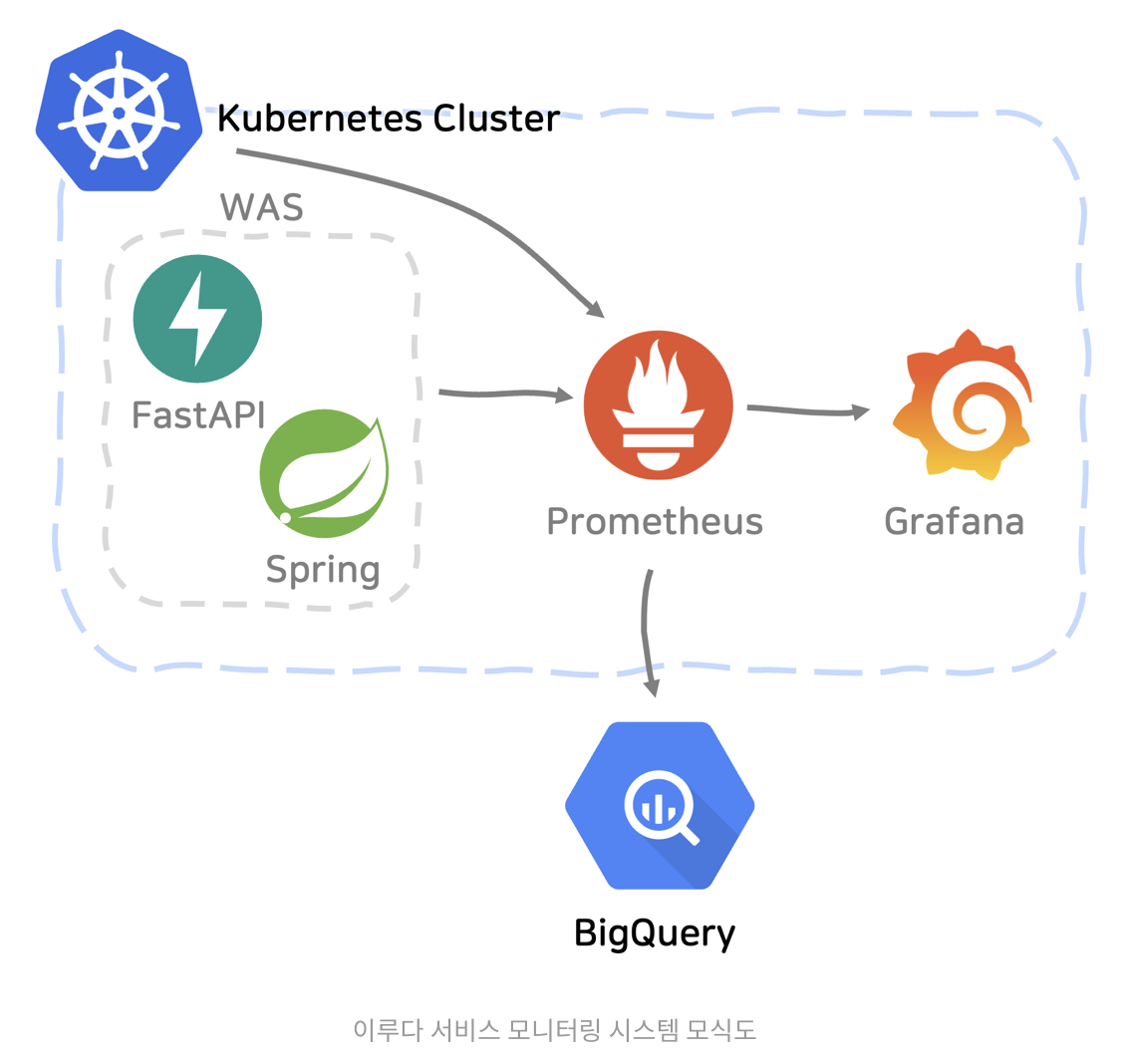
위의 사진이 현재 내 서비스의 모습과 굉장히 유사해서 가져왔다.
Prometheus를 사용하면 개발 언어나 서버 프레임워크에 구애받지 않고, 여러 서비스의 지표를 모아 볼 수 있다고 한다.
🔍 Prometheus

- 프로메테우스는 모니터링 주체인 프로메테우스가 모니터링 대상(서버)에게 HTTP 요청을 해서 metric을 가져오는 pull 방식을 사용함.
- 프로메테우스가 요청을 보내고 가져오기 때문에 모니터링 주기는 프로메테우스가 통제함.
이부분을 고려해서 서버가 어떤 메트릭을 제공할 지 설계해야 함.
ex) 서버에서 최근 10초간 요청 수라는 metric을 제공하고 프로메테우스가 30초에 한번씩 스크랩핑 한다면 20초에 해당하는 정보가 날라감.
➡️ 누적 요청 수 metric을 제공하는 것이 효과적
- counter metic: 시간이 지남에 따라 단조 증가하는(감소할 수 없는) metric
Kubernetes + Prometheus
- Prometheus Operator를 이용하면 쿠버네티스 환겨에 친숙한 방법으로 프로메테우스의 모니터링 설정을 쉽게 변경할 수 있음.
- 프로메테우스가 수집한 메트릭을 쿠버네티스가 이용해 수평확장을 진행할 수도 있음.
Prometheus + BigQuery
위의 인프라 아키텍처를 보면 BigQuery라는 툴이 존재한다.
프로메테우스와 그라파나는 워낙 유명해서 들어봤었지만 빅쿼리는 정말 초면이었다.
- 프로메테우스는 시계열 데이터를 저장하기 위한 자체 데이터베이스를 가지고 있다.
- 자체 데이터베이스는 로컬 디스크를 사용하는데 시간이 지남에 따라 메트릭 정보가 많이 축척되면 디스크 용량에 부담이 된다.
--storage.tsdb.retention.time또는--storage.tsdb.retention.size옵션을 통해 특정 범위를 넘어가는 오래도니 데이터를 자동으로 지우게 설정할 수 있음.
위와 같은 방법도 존재하긴 한지만, 사실 삭제한다는 것이 좀 조심스러워야 하는 작업이다.
과거의 데이터에서 문제를 찾아야 할수도 있는 노릇이니 말이다.
따라서 이 문제를 해결하기 위해 프로메테우스에서 지원하는 remote storage integration을 이용해서 외부 저장소에 시계열 정보를 저장할 수 있다.
내가 참고한 글에서는 Bigquery를 이용하여 프로메테우스가 수집한 메트릭을 빅쿼리에 적재하도록 설정했다고 한다.
다만 빅쿼리가 정답은 아니다! 프로메테우스는 여러 데이터 플랫폼 연동을 지원하기에 다른 플랫폼과 비교를 해보며 선택하는 것이 좋을 것 같다.
아래는 그 예시이다.
- https://prometheus.io/docs/prometheus/latest/storage/
- https://prometheus.io/docs/operating/integrations/#remote-endpoints-and-storage
🔍 Grafana

그라파나 사진이 너무 크다..
- 그라파나는 프로메테우스를 포함하여 다양한 데이터를 대시보드 형태로 시각화 할 수 있다.
- Alerting 기능을 이요해 지표가 정상 범위를 벗어났을 때 slack과 같은 서비스로 알림을 보낼 수 도 있다.
출처
https://blog.daouidc.com/blog/monitoring-server#:~:text=내릴%20수%20있습니다.-,서버%20모니터링%20시스템의%20종류,기반%20시스템%2C%20그리고%20모바일%20시스템.
https://12bme.tistory.com/116
https://yozm.wishket.com/magazine/detail/2280/
.jpeg)