
출처
시작하기에 앞서 우리 프로젝트에 대해 간단하게 설명하고 넘어가겠다.
우리는 해시태그 기반 추천 서비스 가 하위 요소로 있는 블로그 제작 프로젝트를 진행하고 있다.
원래는 좀 더 거창했지만 프로젝트가 구체화되는 과정에서 알고리즘이 굉장히 간단해졌다.
결과적으로, TF-IDF, cosine similarity를 이용한 추천 서비스를 구현하게 될 계획이다.
TF-IDF란?

TF-IDF(Term Frequency-Inverse Document Frequency)는 단어의 빈도와 역 문서 빈도(문서의 빈도에 특정 식을 취함)를 사용하여 DTM 내의 각 단어들마다 중요한 정도를 가중치로 주는 방법. 우선 DTM을 만든 후, TF-IDF 가중치를 부여합니다.
(DTM은 문서 단어 행렬, 즉 문서에서 단어의 등장 빈도를 나타낸 행렬임.)
TF-IDF는 주로 문서의 유사도를 구하는 작업, 검색 시스템에서 검색 결과의 중요도를 정하는 작업, 문서 내에서 특정 단어의 중요도를 구하는 작업 등에 쓰일 수 있습니다.
Cosine silmilarity란?
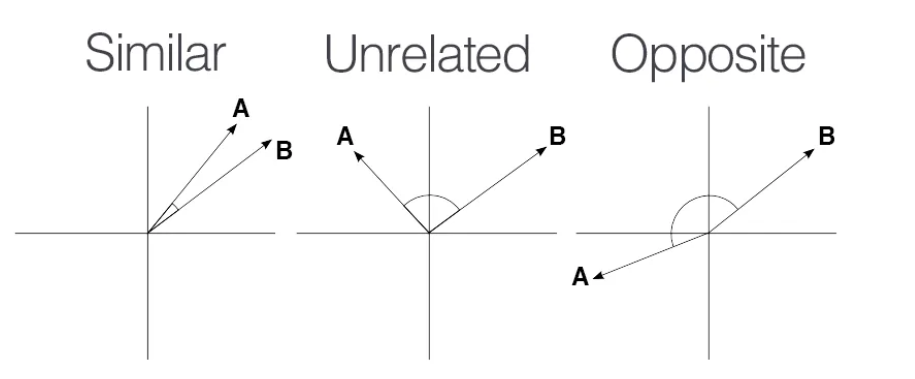
코사인 유사도는 두 벡터 간의 코사인 각도를 이용하여 구할 수 있는 두 벡터의 유사도를 의미합니다.
(우리 프로젝트에선 유저가 작성한 해시태그 간 유사도라고 할 수 있음.)
두 벡터의 방향이 완전히 동일한 경우에는 1의 값을 가지며, 90°의 각을 이루면 0, 180°로 반대의 방향을 가지면 -1의 값을 갖게 됩니다.
즉, 결국 코사인 유사도는 -1 이상 1 이하의 값을 가지며 값이 1에 가까울수록 유사도가 높다고 판단할 수 있습니다.
위의 자료를 이용하여 서비스를 어떻게 배포하냐! 라고 생각이 들 것이다.
우리 프로젝트의 개요는 이렇다.
- 사용자가 해시태그를 작성한다.
- 사용자가 작성한 해시태그를 띄어쓰기로 구분되는 단순한 문자열 형태로 변환한다.
- 변환된 문자열을 다른 사용자들의 문자열(해시태그)과 함께 tf-idf 행렬로 변경한다.
- 결과로 나온 tf-idf 행렬에 코사인 유사도를 적용한다.
- 특정 사용자를 값으로 넣을 시, 코사인 유사도가 가까운 순으로 정렬하여 유사한 사용자를 추천한다.
그리고 예상되는 필수 기능
사용자가 추가적인 해시태그를 작성할 시, 해시태그 문자열에 업데이트를 진행한다.
업데이트 된 문자열은 다시 다른 사용자들과 함께 tf-idf 행렬로 변환되어 코사인 유사도가 계산되고, 그 결과를 기반으로 새로운 추천을 받을 수 있다.
이렇게 되면 ,, 이제 학습 데이터는 필요 없어진게 됐다.
괜히 지피티 에이피아이까지 써가며 자동화시킨 데이터 생성기가 아까워졌다....

그래서 사실.... 왜 내가 FAST API를 사용해야되는지 모르겠다 ㅜㅜ 학교 프로젝트라 가이드라인을 따라가기는 하지만 도커를 통한 배포만 하면 되는게 아닌가!!
그래도 일단 이걸 사용하라고 하니 FAST API를 이용해야겠다.
이제부턴 FAST API에 관한 배포 관련 글을 적어봐야겠다.
일단 FAST API를 통해 구현해야 하는 수행되어야 하는 기능들은 아래와 같은 것이 있다.
- FAST API를 통해 파이썬 코드를 작성한다.
- 사용자가 작성한 게시글에서 해시태그를 받아와 FAST API로 보내고, FAST API에서 위에서 작성한 코드를 실행시킨다.
- FAST API를 통해 값을 받아온 후, 해당 값을 프론트에서 실행시킨다.
➡️ 이게 플로우인데.. 먼가 감이 안잡힌다.
사실 REST API도 정확한 개념은 잘 모르는지라,, 아마 이 시리즈는 좀 "시행착오"에 포커스가 가지 않을까 싶다.
.jpeg)