
벌써 수업만 4번이나 들은 데이터베이스..!!! 과연 평소 하던 자바와 아예 다른 문법으로 잘 헤쳐나갈 수 있을지
출처
ORM이란?
Object Relation Mapping: 파이썬의 문법만으로도 데이터베이스를 다룰 수 있음. 개발자가 직접 쿼리를 다루지 않아도 DB의 데이터 처리 가능
📌 파이썬 코드로의 ORM
난 자바로만 ORM을 공부했기에 파이썬 ORM 기초가 아예 없는 상태이다. 따라서 파이썬 ORM 예제부터 확인해보려 한다.
쿼리를 이용한 새 데이터 삽입
insert into question (subject, content) values ('안녕하세요', '가입 인사드립니다 ^^');
insert into question (subject, content) values ('질문 있습니다', 'ORM이 궁금합니다');ORM을 이용한 새 데이터 삽입
question1 = Question(subject=’안녕하세요’, content='가입 인사드립니다 ^^')
db.add(question1)
question2 = Question(subject=’질문 있습니다’, content='ORM이 궁금합니다')
db.add(question2)코드만 보고 생각해보면 Question이라는 클래스가 question이라는 데이터베이스를 담당하고 있다는 것을 알 수 있다.
📌 SQLAlchemy ORM 라이브러리 사용하기
파이썬 ORM 라이브러리 중 사용률이 제일 높음.
🔍 ORM 라이브러리 설치(터미널 실행)
pip install sqlalchemy
난 fast api설치 시에 함께 깔렸던 것 같다.
🔍 설정 파일 추가하기
- ORM을 적용하려면 당연히! DB 설정이 필요하다.
참고로 현재 나의 파일 상태이다. 미리 실습해둔게 있어서 추가된 것이 있지만, 앞전 글에서 설명했던 database.py, models.py, main.py, domain 폴더를 기본으로 만들어두었다.
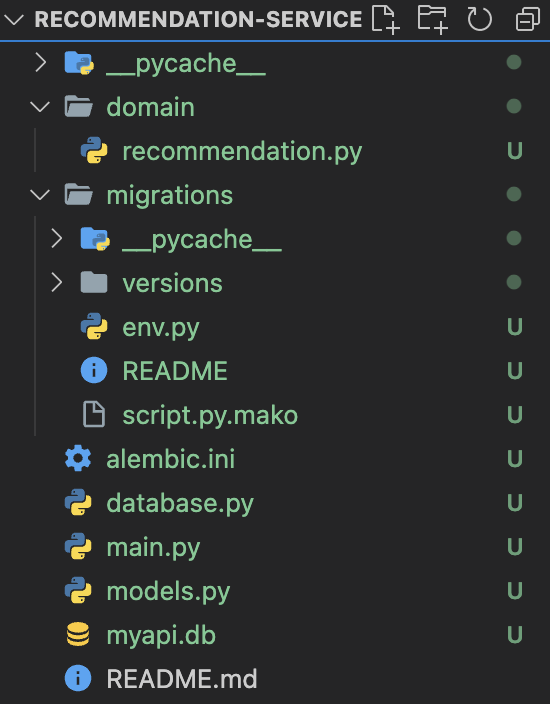
database.py
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
SQLALCHEMY_DATABASE_URL = "sqlite:///./recommendation.db"
engine = create_engine(
SQLALCHEMY_DATABASE_URL, connect_args={"check_same_thread": False}
)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base = declarative_base()- SQLALCHEMY_DATABASE_URL: database 접속 주소
- mongodb:///./recommendation.db는 mongodb 데이터베이스의 파일을 의미하며 프로젝트 루트 디렉터리에 저장한다는 의미이다.
- create_engine: 컨넥션 풀을 생성.
컨넥션 풀이란 데이터베이스에 접속하는 객체를 일정 갯수만큼 만들어 놓고 돌려가며 사용하는 것을 말한다. (컨넥션 풀은 데이터 베이스에 접속하는 세션수를 제어하고, 또 세션 접속에 소요되는 시간을 줄이고자 하는 용도로 사용한다.)
- SessionLocal: 데이터베이스에 접속하기 위해 필요한 클래스이다.
- autocommit=False로 설정하면 데이터를 변경했을때 commit 이라는 사인을 주어야만 실제 저장이 된다.
- 만약 autocommit=True로 설정할 경우에는 commit이라는 사인이 없어도 즉시 데이터베이스에 변경사항이 적용된다.
- autocommit=False -> rollback 가능
- autocommit=True -> rollback 불가능
- 앵간해선 autocommit=False로 하자!
📌 모델만들기
내가 진행중인 프로젝트는 사용자의 해시태그를 기반으로 추천을 받고 해당 결과를 리턴하면 된다. 따라서 일단은 해시태그 모델만 생각해서 구성하겠다.
🔍 모델 속성 구상하기
해시태그 모델 속성
| 속성명 | 설명 |
|---|---|
| hashtag_id | 해시태그의 id값 |
| member_id | 해시태그 작성자의 id값 |
| content | 해시태그 내용 |
| created_at | 생성일시 |
| updated_at | 수정일시 |
🔍 해시태그 모델 생성하기
위에서 구성한 속성을 바탕으로 models.py 파일에 해시태그 모델인 Hashtag 클래스를 작성한다.
from sqlalchemy import Column, Integer, String, Text, DateTime, ForeignKey
from sqlalchemy.orm import relationship
from database import Base
class Hashtag(Base):
__tablename__ = "hashtag"
hashtag_id = Column(Integer, primary_key=True)
member_id = Column(Integer, nullable=False) # 외부 DB와 연결
content = Column(Text, nullable=True)
created_at = Column(DateTime, nullable=False)
updated_at = Column(DateTime, nullable=False)- Hashtag 같은 모델 클래스는 앞서 database.py에서 정의한 Base 클래스를 상속하여 만들어야 한다.
- __tablename__ 은 모델에 의해 관리되는 테이블의 이름을 뜻한다.
- Hashtag 모델은 고유 번호(hashtag_id), 작성자의 id(member_id), 내용(content), 작성일시(created_at), 수정일시(updated_at) 속성으로 구성했으며, 각 속성은 Column으로 생성했다.
- Column() 괄호 안의 첫 번째 인수는 데이터 타입을 의미한다. 데이터 타입은 속성에 저장할 데이터의 종류를 결정한다.
- Integer는 고유 번호와 같은 숫자값에 사용
- String은 제목처럼 글자 수가 제한된 텍스트에 사용
- 글 내용처럼 글자 수를 제한할 수 없는 텍스트는 Text를 사용
- 작성일시는 날짜 타입인 DateTime을 사용
📌 모델을 이용해 테이블 자동으로 생성하기
모델을 구상하고 생성했으므로 SQLAlchemy의 alembic을 이용해 데이터베이스 테이블을 생성해 보자.
alembic은 SQLAlchemy로 작성한 모델을 기반으로 데이터베이스를 쉽게 관리할 수 있게 도와주는 도구이다. 예를들어 models.py 파일에 작성한 모델을 이용하여 테이블을 생성하고 변경할수 있다.
🔍 alembic 설치
pip install alembic
🔍 alembic 초기화
alembic이 잘 설치되었다면 이제 alembic 초기화 작업을 진행해야 한다.
참고로 이 단계부터는 꼭!! FAST API 코드를 작성하는 폴더에서 실행 해야 한다.
alembic init migrations- 이렇게하면 현재 내가 있는 파일 디렉토리 안에 migrations 파일과 alembic.ini 파일이 생성된다.
- migrations 디렉터리: alembic 도구를 사용할 때 생성되는 리비전 파일들을 저장하는 용도
- alembic.ini 파일: alembic의 환경설정 파일
리비전 파일이란?
alembic을 이용해서 테이블을 생성 또는 변경할 때마다 생성되는 작업 파일(migrations 디렉터리에 저장된다.)
alembic.ini
(... 생략 ...)
sqlalchemy.url = sqlite:///./recommendation.db
(... 생략 ...)migrations/env.py
(... 생략 ...)
import models
(... 생략 ...)
# add your model's MetaData object here
# for 'autogenerate' support
# from myapp import mymodel
# target_metadata = mymodel.Base.metadata
target_metadata = models.Base.metadata
(... 생략 ...)🔍 리비전 파일 생성
alembic revision --autogenerat
- 이렇게 되면 migrations/versions 디렉터리에 fed28bf52b05_.py와 같은 리비전 파일이 생성된다.
- 리비전(revision)이란 생성된 fed28bf52b05.py 파일에서 .py 확장자를 제외한 fed28bf52b05와 같은 버전 번호를 가리킨다.
- 리비전은 alembic revision --autogenerate 명령을 수행할 때 무작위로 만들어진다.
- 리비전 파일에는 테이블을 생성 또는 변경하는 실행문들이 들어 있다.
🔍 리비전 파일 실행
alembic upgrade head이 과정에서 데이터베이스에 모델에 정의한 question과 answer라는 이름의 테이블이 생성된다. 지금까지 잘 따라왔다면 projects/myapi 디렉터리에 recommendation.db 파일이 생성되었을 것이다. recommendation.db가 바로 SQLite 데이터베이스의 데이터 파일이다
그런데!!!!!!!!!! 몽고디비는 SQLAlchemy를 안쓴다. 삽질 끝까지 열심히하고 ㅠㅜ 결국 ,,, 다시 글을 써야겠다. 아무튼. SQLite는 이런 방식으로 하면 된다.
.jpeg)