1. Kafka가 필요한 이유
일반적인 서버 구조는 이렇게 생겼습니다.
사용자 요청 → 서버 → DB / Redis 저장 / 조회트래픽이 적을 때는 문제없지만, 트래픽이 갑자기 폭증하면 세 가지 근본적인 문제가 터집니다.
문제 1 — 서버가 모든 요청을 "즉시" 처리해야 함
서버가 감당할 수 있는 처리량을 초과하면 그대로 장애가 납니다. 버티는 척 하다가 한 번에 터지는 구조입니다.
문제 2 — DB / Redis의 동시 처리 한계
아래 상황들은 트래픽이 한 번에 쏟아지는 대표적인 케이스입니다.
- 대규모 세일 오픈
- 인기 상품 재입고
- 쇼핑몰 메인 배너 클릭 급증
이때 DB가 감당할 수 있는 동시 요청 수를 초과하면 병목(Bottleneck) 이 발생합니다.
문제 3 — 사용자 행동 데이터는 실시간으로 폭발적으로 쌓임
페이지 조회, 상품 클릭, 장바구니 추가, 구매, 스크롤... 이 모든 이벤트를 서버가 즉시 처리하는 방식은 부담이 클 수밖에 없습니다.
2. Kafka의 핵심 가치 3가지
Kafka는 폭주하는 요청을 잠시 쌓아두는 큰 버퍼 역할을 합니다.
요청은 일단 Kafka에 넣고 끝내고, 무거운 작업은 나중에 천천히 처리한다!
✅ 버퍼(Buffer) 역할 → API 서버가 죽지 않음
Kafka 없이:
사용자 요청 → 서버 → DB/Redis (즉시 처리 강제)Kafka 있을 때:
Step 1. 요청 받음 → Kafka에 보내고 바로 끝냄 → 응답 빠름
Step 2. 처리할 준비가 됨 → Kafka에 있는 요청 꺼냄 → 요청 처리실제 처리는 Consumer가 나중에 하기 때문에, API 서버는 무거운 일을 하지 않습니다. 트래픽이 10배 와도 버틸 수 있습니다.
✅ 비동기 처리 → 데이터 유실 없음
Kafka가 이벤트를 저장하고 있기 때문에:
- Redis가 잠시 느려도
- DB가 잠깐 막혀도
- 서버가 재배포되어도
→ 이벤트는 Kafka에 안전하게 남아 있고, Consumer가 복구 후 이어서 처리합니다.
💡 Kafka는 메시지가 안전하게 처리되었다고 확인(ack)을 받아야만 다음 메시지를 읽습니다. 처리된 메시지는 즉시 삭제되지 않고, 설정된 보관 기간(retention)에 따라 삭제됩니다.
✅ 파티션 기반 병렬 처리 → 처리량 폭발적 증가
Kafka는 메시지를 Partition 단위로 나눠 여러 Consumer가 동시에 처리할 수 있게 합니다.
파티션 3개 → 동시에 3개 작업 가능
파티션 10개 → 동시에 10개 작업 가능직렬 처리에서 병렬 처리로 전환되는 것만으로 처리량이 몇 배씩 올라갑니다.
3. Kafka 핵심 구성 요소
전체 흐름
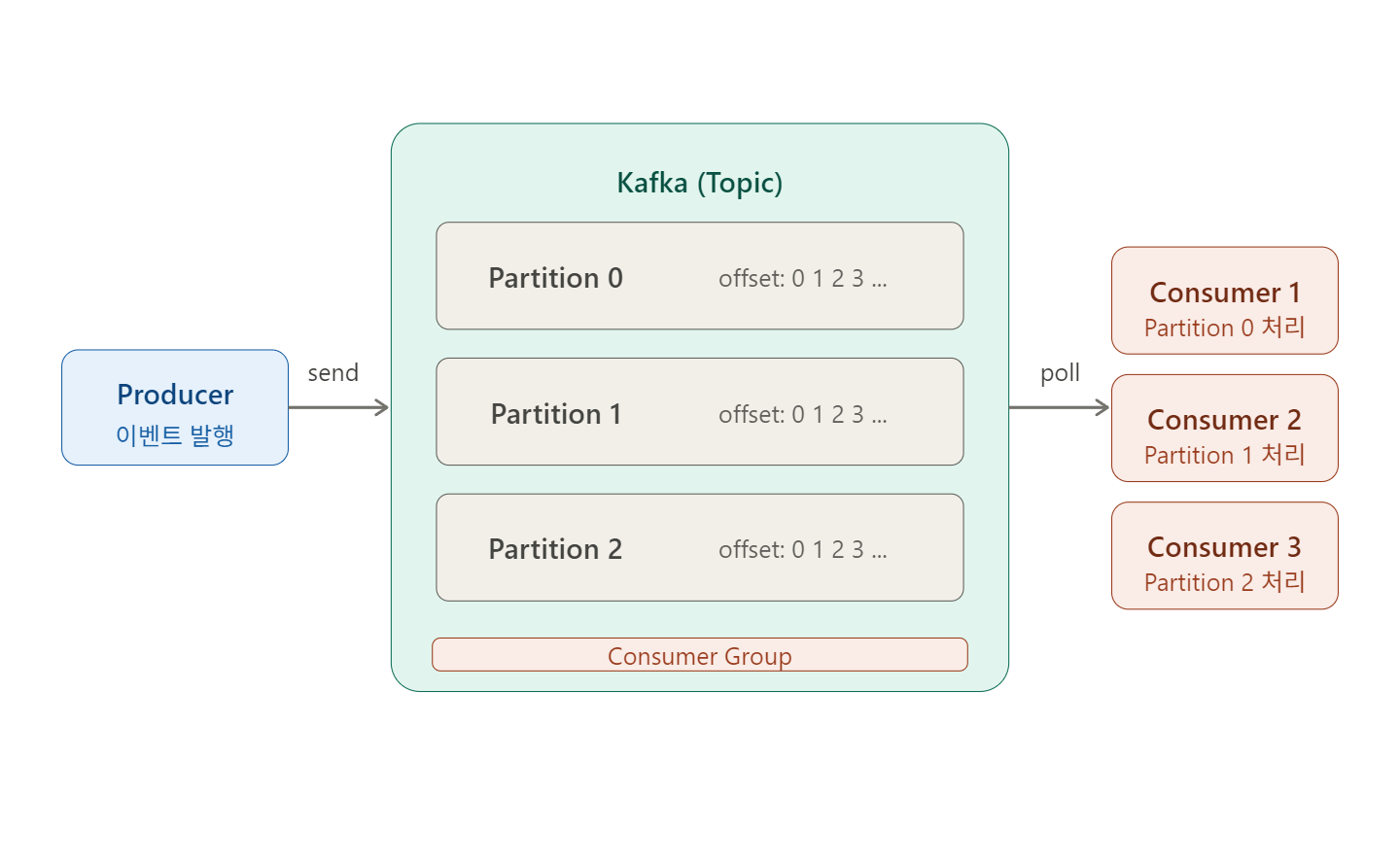
Producer — 이벤트를 보내는 주체
API 서버가 Producer 역할을 합니다. 이벤트를 생성해서 특정 Topic에 전달합니다.
예시:
- 카테고리 클릭 이벤트 전송
- 장바구니 추가 이벤트 전송
Topic — 메시지를 분류하는 폴더
같은 종류의 메시지를 모아두는 단위입니다.
예시:
order-created(주문 확정)order-cancelled(주문 취소)refund-completed(환불 완료)
Partition — 병렬 처리의 핵심 단위
Topic을 여러 칸으로 나눈 것이 Partition입니다.
| 상황 | 결과 |
|---|---|
| 파티션 1개 | 일하는 사람이 1명 |
| 파티션 3개 | 일하는 사람이 3명 |
| 파티션 10개 | 일하는 사람이 10명 |
파티션의 핵심 특징:
- 하나의 파티션은 한 시점에 오직 하나의 Consumer만 처리 가능
- 파티션은 늘릴 수는 있지만, 줄일 수는 없음
- 실무에서는 처음부터 많이 만들기보다 운영하면서 필요 시 증설
Consumer Group — 일하는 팀
여러 Consumer를 팀으로 묶어 파티션을 나눠 처리합니다.
가장 효율적인 구성: 파티션 수 = Consumer 수
| 구성 | 결과 |
|---|---|
| 파티션 3개, Consumer 3개 | 각 Consumer가 파티션 1개씩 담당 (최적) |
| 파티션 3개, Consumer 2개 | Consumer 한 명이 2개 파티션 담당 |
| 파티션 3개, Consumer 1개 | 한 명이 모두 처리 (병렬 효과 없음) |
| 파티션 3개, Consumer 4개 | Consumer 1명이 놀게 됨 |
Offset — 어디까지 읽었는지 기록하는 책갈피
Consumer는 Offset을 보고 어디까지 읽었는지 기억합니다.
- 서버가 재시작해도 이어서 읽을 수 있음
- 메시지가 순서대로 안전하게 처리됨
- Consumer Group마다 Offset을 독립적으로 관리하기 때문에, 서로 다른 Consumer Group은 같은 메시지를 처음부터 다시 읽을 수 있음
4. Kafka의 메시지 저장 방식
메시지를 바로 삭제하지 않는다
Kafka는 메시지를 로그 파일(log segments) 형태로 저장합니다. Consumer가 읽어도 즉시 사라지지 않으며, TTL이나 보관 정책(retention)에 따라 자동 삭제됩니다.
이 구조가 Kafka의 두 가지 강점을 만들어냅니다:
1. 높은 내구성 — 장애가 발생해도 메시지가 남아있어 재처리 가능
2. 멀티 Consumer — 여러 Consumer Group이 같은 메시지를 독립적으로 소비 가능
Consumer는 읽은 위치(Offset)만 기억한다
Partition: [msg0] [msg1] [msg2] [msg3] [msg4]
↑
Consumer A의 Offset (여기까지 읽음)Consumer A가 msg2까지 읽었다면, 다음에 재시작해도 msg3부터 이어서 읽습니다.
5. Kafka 클러스터와 고가용성
단일 브로커의 한계
단일 브로커 운영의 문제점은 명확합니다:
| 문제 | 결과 |
|---|---|
| 서버 장애 | Kafka 전체 중단, 서비스 전체 멈춤 |
| 확장 불가 | 트래픽이 늘어도 한 서버가 모두 감당 |
| 데이터 위험 | 디스크 고장 시 메시지 전체 손실 |
| 가용성 없음 | 네트워크 오류나 재부팅만으로도 서비스 중단 |
💡 Kafka 공식 문서에서도 최소 3대의 브로커를 구성할 것을 권장합니다.
Kafka 클러스터 구조
여러 브로커가 하나의 Kafka처럼 동작하는 구조입니다.
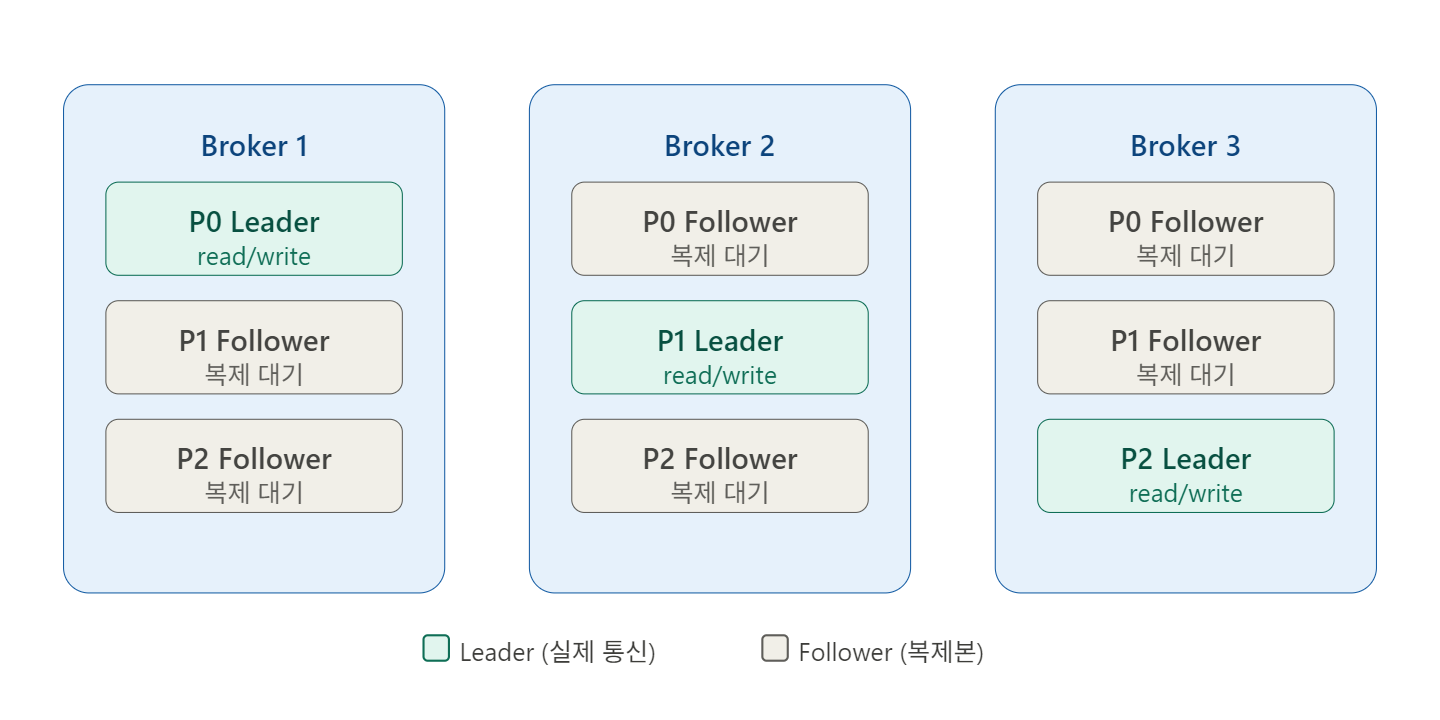
Leader / Follower 역할
Leader:
- Producer와 Consumer가 실제로 통신하는 대상
- 모든 read/write 작업을 처리
- 장애 발생 시 새로운 Leader가 자동으로 선출됨
Follower:
- Leader의 데이터를 그대로 복제
- Leader 장애 시 자동으로 Leader로 승격 (Failover)
- 장애 복구 후 Leader 데이터를 다시 동기화
복제의 장점:
- 브로커 1대가 장애가 나도 Topic이 사라지지 않음
- Producer와 Consumer는 계속 정상 동작
- 데이터 안전성이 크게 향상
6. Controller와 KRaft
Controller의 역할
Kafka 클러스터를 운영하려면 다음을 관리하는 중앙 두뇌가 필요합니다:
- 어떤 브로커가 살아있는지 확인
- 각 파티션의 Leader가 누구인지 관리
- Failover 시 새로운 Leader 선출
- Topic, Partition 등 메타데이터 관리
Zookeeper 방식 (Kafka 2.x까지)
과거에는 이 Controller 역할을 외부 시스템인 Zookeeper가 담당했습니다.
[Zookeeper] ←→ [Kafka Cluster]
(메타데이터) (메시지 처리)Zookeeper 구조의 문제점:
1. Kafka + Zookeeper, 두 시스템을 따로 운영해야 해서 운영 복잡도 증가
2. Zookeeper 장애 시 Kafka도 직접적인 영향을 받음
3. 고동시성 환경에서 Zookeeper가 메타데이터 업데이트 병목이 될 수 있음
KRaft 방식 (Kafka 3.x부터)
Kafka가 Raft 합의 알고리즘을 이용해 메타데이터를 자체적으로 관리합니다.
[Kafka Cluster]
(메시지 처리 + 메타데이터 관리 통합)KRaft의 장점:
- 외부 의존성(Zookeeper) 완전 제거
- 단일 시스템으로 안정성과 성능을 모두 확보
- 메타데이터 관리 병목 해소
7. Kafka에 대한 흔한 오해
❌ Consumer를 많이 늘리면 무조건 빨라진다?
병렬 처리의 상한선은 파티션 수입니다. Consumer가 파티션보다 많으면 초과분은 그냥 대기합니다.
파티션 3개, Consumer 5개 → Consumer 2명은 놀게 됨❌ Kafka는 DB다?
Kafka는 저장은 하지만 조회용이 아닙니다.
| 목적 | 도구 |
|---|---|
| 빠른 조회 | Redis |
| 저장 / 재처리 / 순서 보장 | Kafka |
❌ Kafka는 이벤트를 실시간 처리한다?
실시간처럼 보이지만, 실제로는 이벤트를 저장했다가 순서대로 소비하는 구조입니다. 즉각 처리가 아니라 안전한 순서 보장이 핵심입니다.
정리
Kafka는 갑자기 트래픽이 폭발해도 데이터를 절대 잃지 않고,
이벤트를 안전하게 모아서,
나중에 여러 Consumer가 병렬로 처리할 수 있게 해줍니다.
| 핵심 개념 | 한 줄 요약 |
|---|---|
| Producer | 이벤트를 Kafka에 보내는 주체 (API 서버) |
| Topic | 메시지를 종류별로 분류하는 폴더 |
| Partition | 병렬 처리를 가능하게 하는 Topic의 분할 단위 |
| Consumer | Kafka에서 메시지를 읽어 처리하는 주체 |
| Consumer Group | 파티션을 나눠 처리하는 Consumer 팀 |
| Offset | 어디까지 읽었는지 기록하는 책갈피 |
| Leader/Follower | 고가용성을 위한 파티션 복제 구조 |
| KRaft | Zookeeper 없이 Kafka가 자체 메타데이터를 관리하는 방식 |
