[NLP] TermDiffuSum: A Term-guided Diffusion Model for Extractive Summarization of Legal Documents
Paper Review
https://aclanthology.org/2025.coling-main.216.pdf
0. Abstract
- 법률 문서의 핵심 문장을 자동으로 추출하여 간결한 요약을 생성하는 추출 요약(extractive summarization)
- 최근에는 확산 모델(diffusion model)을 활용한 요약 방식이 주목받고 있지만, 기존 모델들은 법률 문서에 자주 등장하는 전문 법률 용어를 충분히 반영하지 못하는 한계가 있었음
⇒ TermDiffuSum
- Well-designed multifactor fusion noise weighting schedule을 이용: 법률 용어를 diffusion model에 통합함
- Diffusion 과정 중 법률 용어의 농도(concentration)가 높은 문장에 더 높은 attention 가중치를 할당
- Diffusion 과정에서 생성된 후보 요약문들(candidates summaries)과 실제 요약문(reference summaries) 간의 관계를 기반으로, 보다 관련성 높은 요약문을 선택하도록 모델을 정제하기 위해 Re-ranking loss function을 활용함
- 자체 구축한 법률 요약 데이터셋에서 기존 모델보다 ROUGE - 1/2/L 스코어가 향상되었음
- 뉴스 및 소셜 미디어 도메인의 공개 데이터셋에서도 우수한 성능을 보여 모델의 확장성과 일반화 가능성을 입증함
1. Introduction
- 법률 문서 요약의 motivation: 법률 문서에는 수많은 사건 세부사항(case details)이 기록되어 있어서 원하는 핵심 정보를 빠르게 찾기 어려움
- Automatic text summarization
- Abstractive summarization (생성 요약)
🙁 예상치 못한 어휘를 생성할 수 있음 - potentially risky summaries
🙁 ChatGPT 같은 LLMs의 hallucination 문제
- Extractive summarization (추출 요약)
😊 법률 문서 요약은 높은 정확도를 요구함 - 문서에서 직접 핵심 문장을 추출
- Abstractive summarization (생성 요약)
- 법률 도메인의 특성
- 법률 문서는 수많은 법률 용어를 포함하며, 해당 용어들이 법률 요약의 핵심 정보를 구성함
- 기존의 diffusion models를 법률 문서 요약에 그대로 적용할 경우 법률 용어에 대한 이해가 불충분하여 생성된 요약이 실무적 요구사항을 충족하기 어려움
- Specific contributions
- 법률 문서의 추출형 요약을 위한 용어 기반 diffusion model 제안
- Multifactor fusion noise weighting schedule : 법률 용어 감지 능력 향상
- Re-ranking module : 후보 요약문와 참조 요약문(ground truth) 간의 관계를 활용하여 더 관련성 높은 요약문을 식별하도록 함
2. Related Work
DiffuSum
- Diffusion models을 추출 요약(extractive summarization)에 처음으로 적용한 연구
- 단어를 하나씩 생성하는 방식이 아니라, 요약 문장 표현(summary representations)을 직접 생성한 후, 문장 표현 간의 유사도를 기반으로 문장을 선택함
- 문장 표현 학습을 위해 대조 학습 기반 문장 인코딩 모듈(contrastive sentence encoding module)을 도입하여 전반적인 성능을 향상시킴
TermDiffuSum의 차별점:
(1) 법률 문서의 추출 요약에 diffusion model을 적용하고, 법률 용어를 활용한 문장 수준의 노이즈 스케줄(sentence-level noise schedule)을 설계함
(2) Re-ranking 모듈을 도입하여, 후보 요약문들의 참조 요약문(ground truth)과의 alignment를 평가함으로써 보다 관련성 높은 요약을 식별하는 능력을 향상시킴
Supervised Extractive Summarization
- Extractive Summarization
: 문서에서 직접 요약문 추출 → 더 높은 정확도와 일관성 보장 - Supervised methods
- 기존 방법 : 각 문장의 중요도를 개별적으로 평가하여 추출 여부를 결정하는 sequence labeling 방식을 사용함. 문장들 간의 관계는 무시됨
(i.e. Sentence-level: 각 문장을 독립적으로 평가) - TermDiffuSum : diffusion model을 이용해 문장 간 관계를 효과적으로 모델링함
(i.e. Summary-level: 여러 후보 요약문들을 생성하고, 원문과의 의미적 유사도를 기반으로 최적의 요약 선택)
- 기존 방법 : 각 문장의 중요도를 개별적으로 평가하여 추출 여부를 결정하는 sequence labeling 방식을 사용함. 문장들 간의 관계는 무시됨
3. Model
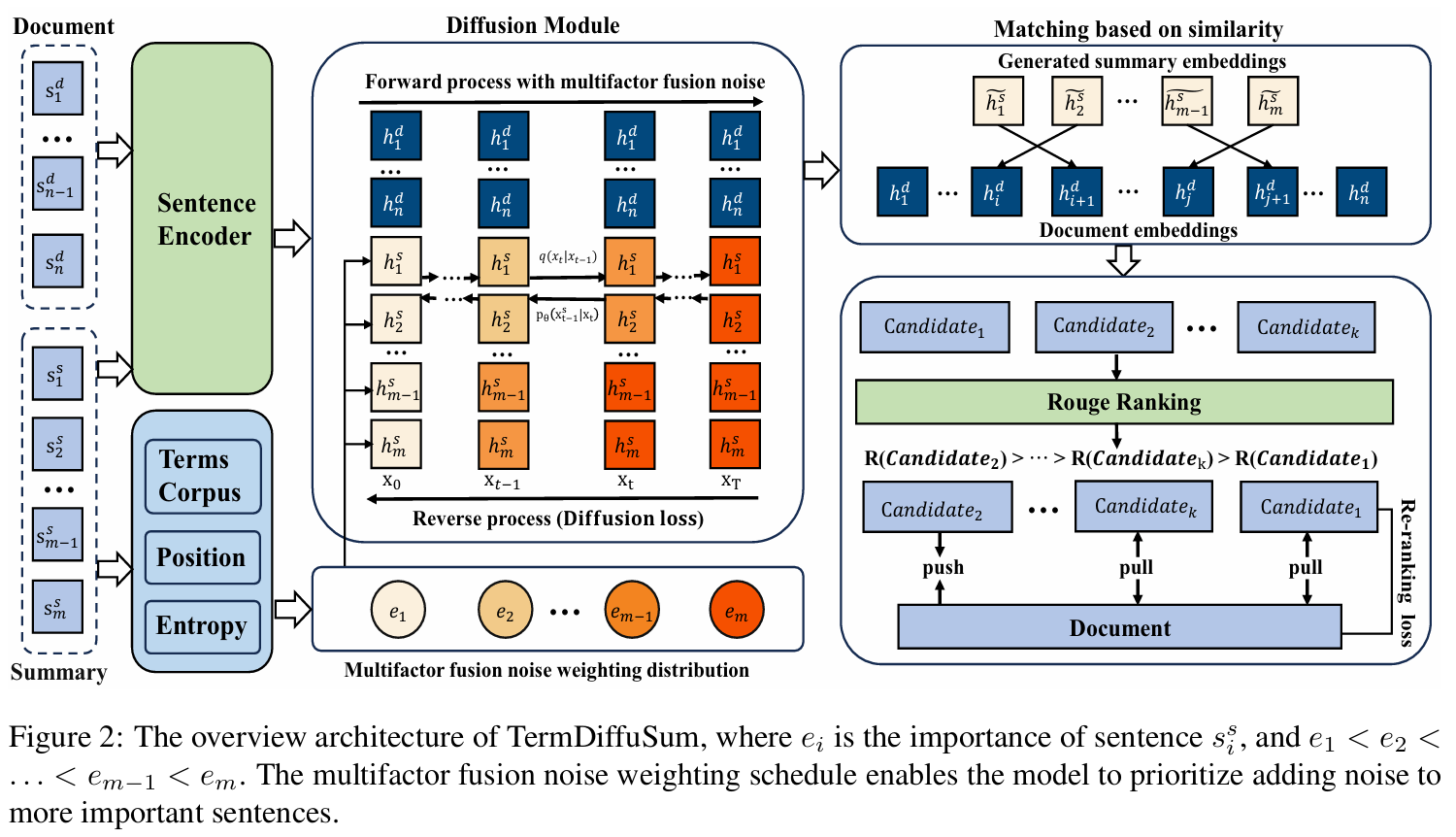
TermDiffuSum = Diffusion module + Re-ranking module
Diffusion module : 타깃 요약문에 대한 임베딩 생성
Re-ranking module : 위의 임베딩으로부터 후보 요약문들을 생성 & 후보 요약문을 평가해 re-ranking loss 구축
3-1. Problem Definition
<목표> 주어진 법률 문서 에 대해 핵심 내용을 담은 요약문 를 생성하는 것
➕ 법률 문서 요약은 문서의 내용을 정확하게 표현하는 것이 중요함!
→ 모델이 문서를 이해하는 데 법률 용어(legal terms, )를 활용할 수 있도록 함
👉
3-2. Diffusion Module
Multifactor Fusion Noise Weighting Schedule
-
요약 문장으로 추출될 확률 = 문장의 중요도에 따라 결정됨
⇒ 노이즈는 문장의 중요도에 따라 달라져야 함
⇒ 문장별로 가중치를 부여하는 multifactor fusion noise weighting schedule
-
중요도가 높은 문장에 더 많은 노이즈를 우선적으로 추가함으로써, 모델이 중요한 문장에 더 집중하도록 함
- <참고> Diffusion model 기본 개념 Diffusion model 설명 (Diffusion model이란? Diffusion model 증명)
- Diffusion model은 데이터를 점점 노이즈로 오염시키는 “forward process”와, 그 노이즈를 점점 복원하는 “reverse process”를 학습
- 이 과정에서 노이즈의 크기나 분포(schedule)는 “모델이 학습 중 어느 부분에 더 신경 쓰게 되는가”를 결정
- Diffusion 모델 학습은 결국 복원 능력(reconstruction ability)을 키우는 과정
- 어떤 부분에 노이즈를 더 주면, 그 부분을 복원하는 데 더 많은 학습 신호(gradient)가 집중됨 따라서 중요한 문장에 더 많은 노이즈를 추가하면, 모델은 그 문장을 복원하려고 더 많이 노력하게 됨
-
Sentence weight ()
-
Word Information Entropy
: 정보 엔트로피가 높을수록, 일반적으로 문장이 더 풍부한 정보를 포함하고 있음을 의미함
→ 문장의 중요도를 평가하기 위한 기준으로 정보 엔트로피 사용
👉 **
: 문장 의 단어 수 / : 번째 단어 / : 단어 의 확률 -
Number of Legal Terms
: 법률 문서는 핵심적인 내용을 반영하는 다수의 법률 용어를 포함하는 경우가 많음
→ 문장의 중요도를 평가하기 위한 기준으로 문장 내 법률 용어의 수 사용
👉
: 문장에 법률 용어가 있으면 1, 없으면 0 / : 문장 내 법률 용어 개수
-
Positional Information
: 일반적으로 문서에서 특정 위치(e.g. 시작, 끝)에 있는 문장이 중간에 있는 문장보다 더 중요
→ 문장 중요도를 평가할 때 위치 정보도 고려
👉
: 문장의 위치 / : 문서 내 최대 문장 위치
-
⇒
(, 본 논문에서는 )
Forward Diffusion
- Forward process 동안 summary sentence representations ()에 가우시안 노이즈 주입됨
(document sentence representations 는 변화 無 - 요약문의 조건,context 역할이므로) - diffusion step 이후 는 완전한 노이즈가 됨
→ 잠재 변수 시퀀스 (series of latent variables) 만들어짐
Reverse Diffusion
- 의 노이즈 분포를 예측함으로써 의 노이즈를 한 겹 벗김
Objective
예측한 요약문 표현과 타깃 요약문 표현 사이 차이를 최소화 하는 것
3-3. Re-ranking Module
- Reverse process를 통해 얻은 예측 요약문 표현 이 주어졌을 때, 각 문장 표현 와 가장 유사한 문장들을 문서 내에서 선택해 후보 요약 문장으로 간주함
- : 요약문 각 문장과 가장 유사한 문서 문장들을 선택한 결과
- : 후보 요약문들 (subset of )
- 후보 요약문들()과 ground-truth 사이 ROUGE 스코어 기준 내림차순 정렬
- Re-ranking loss
,
일 때 성립- Evaluation function : 각 후보 요약문 스코어링하는 함수. 점수 높을수록 문서와의 유사도가 더 높음
- : diffusion으로 복원된 요약문 표현이 문서와의 의미적 일치도(유사도)에 따라 “좋은 요약()과 나쁜 요약()을 구분하도록 학습”하는 데 쓰이는 함수
- Re-ranking Module은 TermDiffuSum이 요약문들의 ROUGE 스코어를 알 수 있도록 함
3-4. Optimization and Prediction
- Optimization
📌 The overall objective function
= (input 문서/ target 요약문 인코딩 모듈의 objective function)
+ (복원된 요약문과 타깃 요약문 표현 간 차이 최소화 위한 objective function)
+ (좋은 요약과 나쁜 요약을 구분하도록 하기 위한 objective function)
- Prediction (Inference) (Reverse process만 사용됨)
- 문서 를 로 인코딩
- One-step Markov transition 수행 : 초기 state() 생성
- step 의 완전한 가우시안 노이즈로부터 개의 노이즈 벡터를 랜덤 샘플링
- 노이징된 summary representation 생성
- Reverse process를 통해 예측된 요약 임베딩 () 얻음
- 각 와 문서 표현 사이 유사도 기준, 를 문서 내에서 가장 유사한 문장에 매핑
→ 최종 요약 문장으로 선택
