
학습목표
- 파이썬에서 다룰 수 있는
CSV,웹,XML,JSON네 가지 데이터 타입에 대해 공부CSV파일 포맷은 어떠한 프로그래밍 언어든 데이터를 다루는 분야에서 가장 기본이 되는 타입형태엑셀의 텍스트 데이터 형태와 유사하며, 매우 중요한 데이터 타입으로 파이썬으로핸들링하는 것에 익숙해지는 것이 필요웹은 우리 세상에서 가장 많은 정보를 제공하고 가장 많은 시간을 사용하고 있는 공간으로, 현재 매일 쓰고 있는 웹에서 가장 많은 정보를 얻고 있음.
- 이번 챕터에서 우리는 이 정보를
어떻게 자동으로 확보할 것인지에 대해서 공부하고, 먼저 기본적인 웹을 표현하는 가장 기본적인 언어인HTML에 대해서 공부- HTML은 웹에서 나타나는 정보의 표현 방법 중 가장 대표적인 방법으로 거의 모든 정보를 HTML 분석으로 얻을 수 있음.
- 다음으로 그 HTML을 분석하기 위해 대표적인 방법인
정규표현식(regex)에 대해서 공부하며,
정규표현식은 텍스트 데이터 분석에 있어 가장 대표적인 분석 방법으로, HTML외에도 다양한 유형의 텍스트에서특정 정보를 뽑아내는데 사용
- 마지막으로 데이터를 저장하는 다양한 포멧중 하나인
XML(eXtensible Markup Languages)과JSON(JavaScript Object Notation)에 대해서 공부.
- XML 프로그래밍 언어에서 데이터를 저장하고 불러오는 전통적인 파일포맷은 흔히
레거시 시스템(오래전에 구축된 시스템)에서raw파일을 저장하는 대표적인 포맷JSON은 이와 달리모바일이 활발히 사용되면서 사용되기 시작하는 저장 포맷으로 웹에서 많이 사용되는JavaScript의 문법을 활용하여 저장하는 포맷
1. Comma Separate Value
- CSV,
필드를쉼표(,)로 구분한텍스트 파일- 엑셀 양식의 데이터를 프로그램에 상관없이 쓰기 위한 데이터 형식이라고 생각하면 쉬움
탭(TSV),빈칸(SSV)등으로구분해서 만들기도 함- 통칭하여 character-separated values (CSV) 부름
- 엑셀에서는 “다른 이름 저장” 기능으로 사용 가능
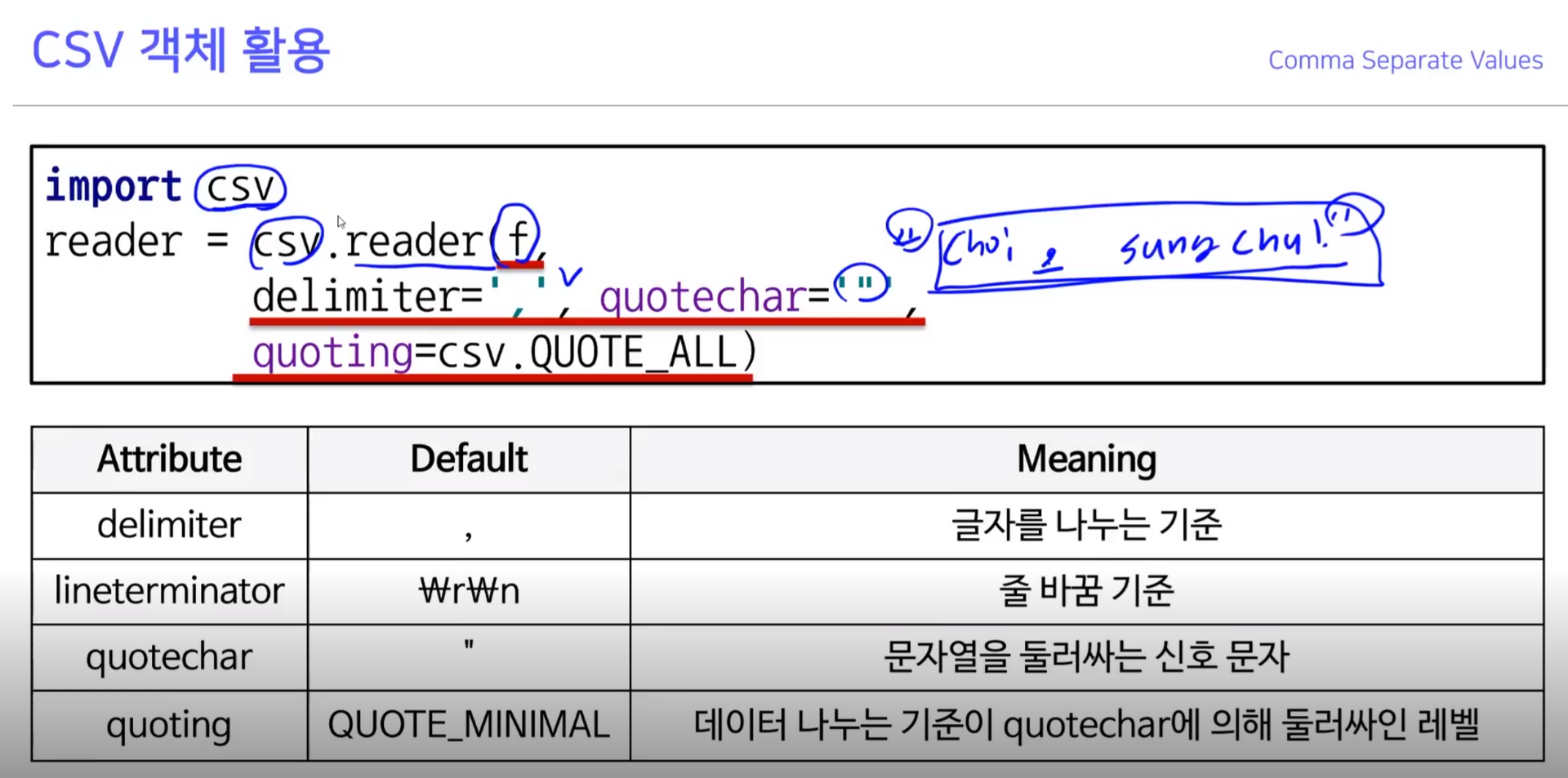
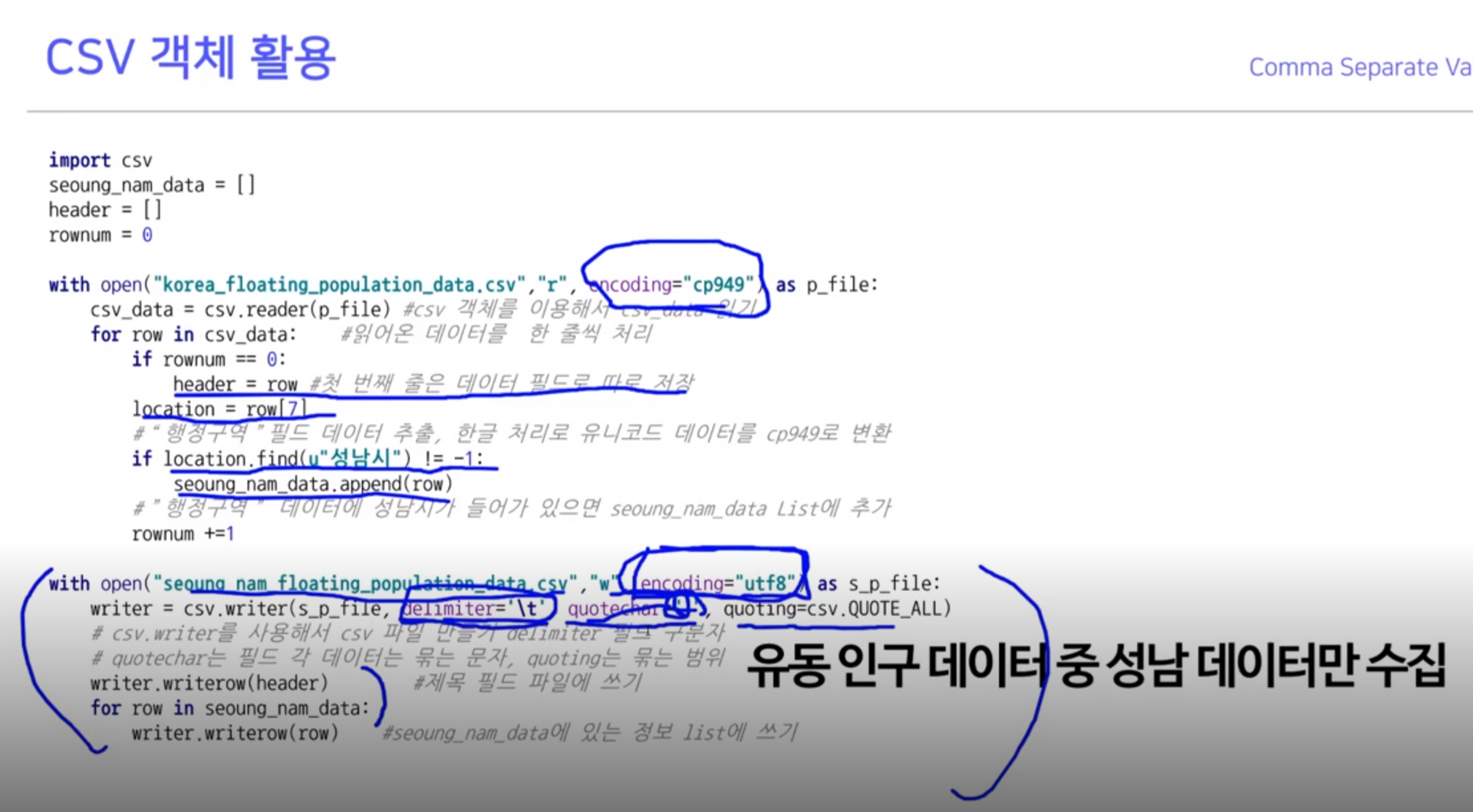
1-1. CSV 객체 활용
quotechar: ‘”’ 기준 하나의 필드로 보겠다
- 위와 같이 오류가 있을 때, 읽을 때
cp949로 읽겠다고 지정- 성남시 앞의 u는 유니코드의 약자로, ‘성남시’가 적혀져 있다면 append

1-2. Web
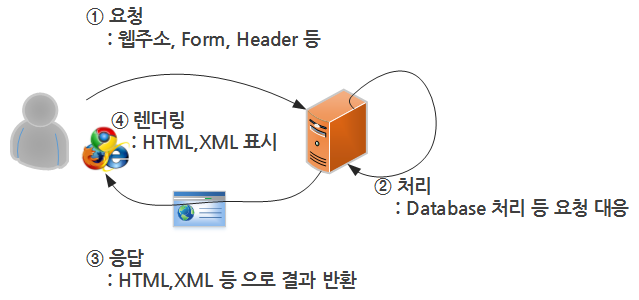
- World Wide Web(WWW), 줄여서 웹이라고 부름
- 우리가 늘 쓰는 인터넷 공간의 정식 명칭
- 팀 버너스리에 의해 1989년 처음 제안되었으며, 원래는 물리학자들간 정보 교환을 위해 사용됨
- 데이터 송수신을 위한 HTTP 프로토콜 사용, 데이터를 표시하기 위해 HTML 형식을 사용
1-3. HTML(Hyper Text Markup Language)
- 웹 상의 정보를 구조적으로 표현하기 위한 언어
- 제목, 단락, 링크 등 요소 표시를 위해
Tag <>를 사용- 모든 요소들은
꺾쇠 괄호 안에 둘러 쌓여 있음 Hello, World #제목 요소, 값은 Hello, World- 모든 HTML은
트리 모양의 포함관계를 가짐- 일반적으로 웹 페이지의 HTML 소스파일은 컴퓨터가 다운로드 받은 후 웹 브라우저가 해석/표시
1-4. 왜 웹을 알아야 하는가?
- 정보의 보고, 많은 데이터들이 웹을 통해 공유됨
환율정보 : https://finance.naver.com/
날씨정보 : http://goo.gl/nwi8WE
미국 특허정보 : http://bit.ly/3pxFkjb- HTML도 일종의 프로그램, 페이지 생성 규칙이 있음 :
규칙을 분석하여데이터의 추출이 가능- 추출된 데이터를 바탕으로 다양한 분석이 가능
2. 정규식 (regular expression)
- 정규 표현식,
regexp또는regex등으로 불림- 복잡한 문자열 패턴을 정의하는 문자 표현 공식
- 특정한 규칙을 가진 문자열의 집합을 추출
010-0000-0000 ^\d{3}\-\d{4}\-\d{4}$ IPV4 : 203.252.101.40 ^\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}$
자막파일을 정규식으로 찾는 예시 (ctrl + h)
2-1. 정규식 for HTML Parsing
- 주민등록번호, 전화번호, 도서 ISBN 등 형식이 있는 문자열을 원본 문자열로부터 추출
- HTML 역시
tag를 사용한 일정한 형식이 존재하여 정규식으로 추출이 용이- 관련자료: http://www.nextree.co.kr/p4327/
- 문법 자체는 매우 방대, 스스로 찾아서 하는 공부 필요
- 필요한 것들은 인터넷 검색을 통해 찾을 수 있음
- 기본적인 것을 공부 한 후 넓게 적용하는 것이 중요

2-2. 정규식 연습장 활용하기
- 정규식연습장(http://www.regexr.com/) 으로 이동
- 테스트하고 싶은 문서를 Text 란에 삽입
- 정규식을 사용해서 찾아보기
2-3. 정규식 기본 문법
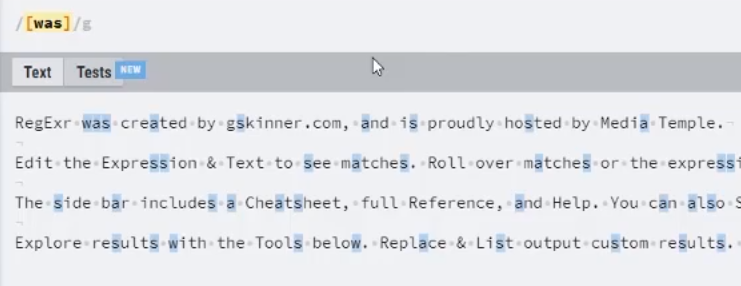
- 문자 클래스 [ ]: [ 와 ] 사이의 문자들과 매치라는 의미
예) [abc] ← 해당 글자가 a, b, c중 하나가 있다. “a”, “before”, “deep” , “dud”, “sunset”
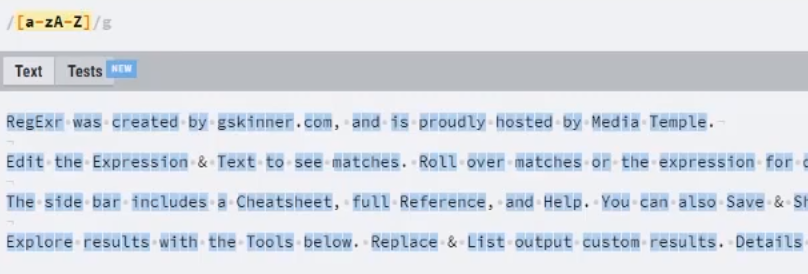
“-“를 사용 범위를 지정할 수 있음
예) [a-zA-z] – 알파벳 전체, [0-9] – 숫자 전체
2-4. 정규식 기본 문법 – 메타 문자
- 정규식 표현을 위해 원래 의미 X,
다른 용도로 사용되는 문자
. ^ $ * + ? { } [ ] \ | ( ).은 전체를 다 잡아주고,*은 반복할 수 있음- 줄바꿈 문자인 \n를 제외한 모든 문자와 매치 a[.]b
- 앞에 있는 글자를 반복해서 나올 수 있음
tomor*ow tomorrow tomoow tomorrrrow- 앞에 있는 글자를 최소 1회 이상 반복
- 정규식 표현을 위해 원래 의미 X, 다른 용도로 사용되는 문자
. ^ $ * + ? { } [ ] \ | ( )
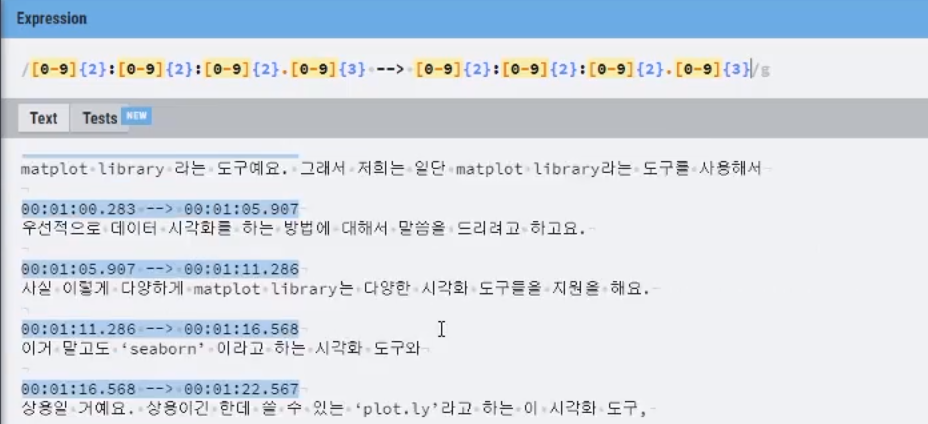
{m.n}- 반복 횟수를 지정 {1,} , {0,} {1,3}
203.252.101.40 [0-9]{1,3} \d{1,3}
?- 반복 횟수가 1회 01[01]?-[0-9]{4}-[0-9]{4}
|- or (0|1){3}^- not
2-5. 정규식 추출 연습
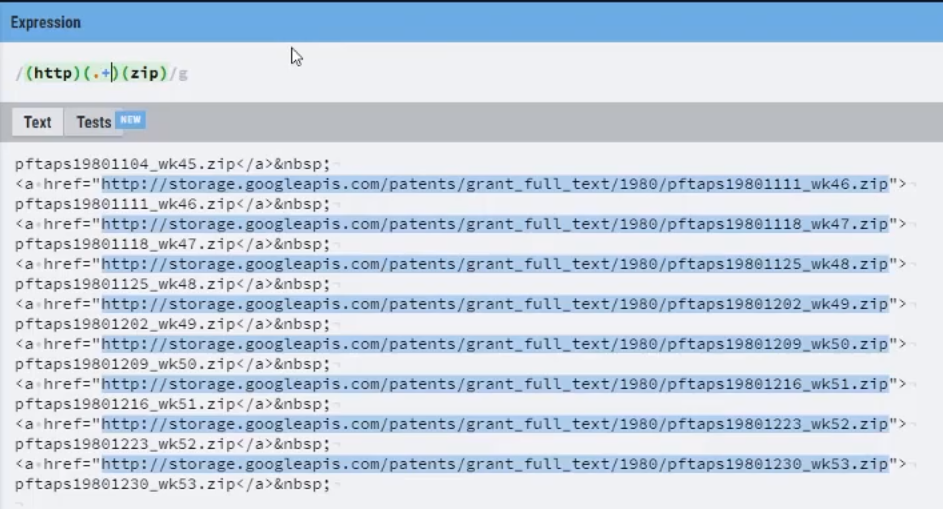
① 정규식 연습장(http://www.regexr.com/) 으로 이동
② 구글 USPTO Bulk Download 데이터 페이지 소스보기 클릭
③ 소스 전체 복사 후 정규식 연습장 페이지에 붙여넣기
④ 상단 Expression 부분을 수정해가며 “Zip”로 끝나는 파일명만 추출
⑤ Expression에 (http)(.+)(zip) 를 입력 →.+는 중간에 무엇이 있어도 상관없다를 의미
http://www.google.com/googlebooks/uspto-patents-grants-text.html
2-6. 정규식 in 파이썬
- re 모듈을 import 하여 사용 :
import re- 함수:
search– 한 개만 찾기,findall– 전체 찾기- 추출된 패턴은
tuple로 반환됨- 연습 - 특정 페이지에서
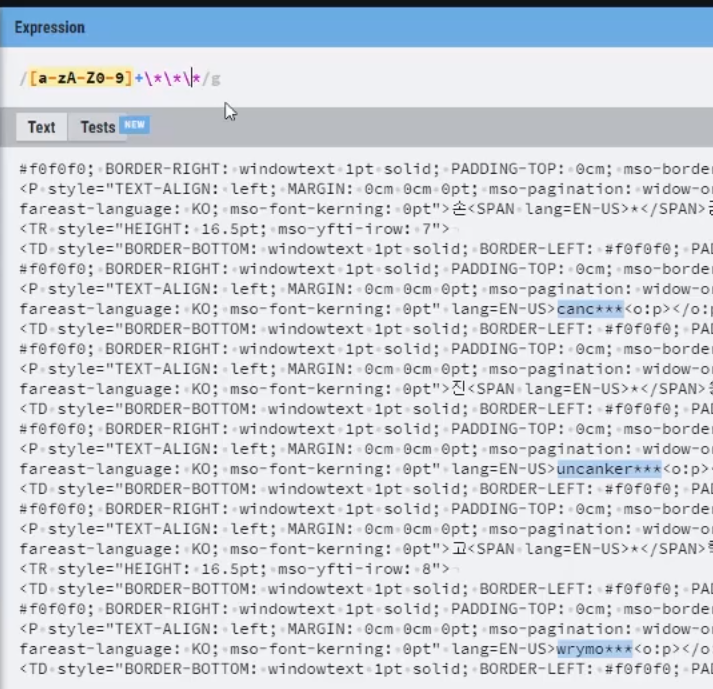
ID만 추출하기 https://bit.ly/3rxQFS4- ID 패턴: [영문대소문자|숫자] 여러 개, 별표로 끝남
"([A-Za-z0-9]+*****)“ 정규식
import re import urllib.request url = "[https://bit.ly/3rxQFS4](https://bit.ly/3rxQFS4)" html = urllib.request.urlopen(url) html_contents = str(html.read()) id_results = re.findall(r"([A-Za-z0-9]+\*\*\*)", html_contents) #findall 전체 찾기, 패턴대로 데이터 찾기 for result in id_results: print (result)import urllib.request # urllib 모듈 호출 import re url = "http://www.google.com/googlebooks/uspto-patents-grants-text.html" #url 값 입력 html = urllib.request.urlopen(url) # url 열기 html_contents = str(html.read().decode("utf8")) # html 파일 읽고, 문자열로 변환 url_list = re.findall(r"(http)(.+)(zip)", html_contents) for url in url_list: print("".join(url)) # 출력된 Tuple 형태 데이터 str으로 join
2-7. 정규식 in 파이썬 for html
① < dl class=“blind”>
< /dl>
(\<dl class=\"blind\">)([\s\S]+?)(\<\/dl>)
< dl class에서 시작해서 / 사이에 아무 글자나 있고 / < /dl> 로 끝내기
(→ 오류나서 "<" 뒤에 공백 넣음, 원래는 지워야 함)
② < dd>
< /dd> 정보를 추출하면 됨
(\< dd>)([\s\S]+?)(\< \/dd>)
< dd> 에서 시작해서 / 사이에 아무 글자나 있고 / < /dl> 로 끝내기
① 를 먼저 찾고 ① 안에 ②를 차례대로 찾으면 됨
(→ 오류나서 "<" 뒤에 공백 넣음, 원래는 지워야 함)import urllib.request import re url = "http://finance.naver.com/item/main.nhn?code=005930" html = urllib.request.urlopen(url) html_contents = str(html.read().decode("ms949")) stock_results = re.findall("(\<dl class=\"blind\"\>)([\s\S]+?)(\<\/dl\>)", html_contents) samsung_stock = stock_results[0] # 두 개 tuple 값중 첫번째 패턴 samsung_index = samsung_stock[1] # 세 개의 tuple 값중 두 번째 값 # 하나의 괄호가 tuple index가 됨 index_list= re.findall("(\<dd\>)([\s\S]+?)(\<\/dd\>)", samsung_index) for index in index_list: print (index[1]) # 세 개의 tuple 값중 두 번째 값
3. XML
- 데이터의 구조와 의미를 설명하는
TAG(MarkUp)를 사용하여 표시하는 언어- TAG와 TAG사이에 값이 표시되고, 구조적인 정보를 표현할 수 있음
- HTML과 문법이 비슷, 대표적인 데이터 저장 방식
- 정보의 구조에 대한 정보인 스키마와 DTD 등으로 정보에 대한 정보(메타정보)가 표현되며, 용도에 따라 다양한 형태로 변경가능
- XML은 컴퓨터(예 : PC ↔ 스마트폰)간에 정보를 주고받기 매우 유용한 저장 방식으로 쓰임
3-1. XML 예제
<?xml version="1.0"?> <고양이> <이름>나비</이름> <품종>샴</품종> <나이>6</나이> <중성화>예</중성화> <발톱 제거>아니요</발톱 제거> <등록 번호>Izz138bod</등록 번호> <소유자>이강주</소유자> </고양이>
3-2. XML Parsing in Python
- XML도 HTML과 같이 구조적 markup 언어
- 정규표현식으로 Parsing이 가능함
- 그러나 좀 더 손쉬운 도구들이 개발되어 있음
- 가장 많이 쓰이는 parser인 beautifulsoup으로 파싱
3-3. BeautifulSoup
- HTML, XML등 Markup 언어
Scraping을 위한 대표적인 도구- https://www.crummy.com/software/BeautifulSoup/
- lxml 과 html5lib 과 같은
Parser를 사용함- 속도는 상대적으로 느리나 간편히 사용할 수 있음
3-4. beautifulsoup 모듈 사용
from bs4 import BeautifulSoup
- 모듈 호출
- 객체 생성
soup = BeautifulSoup(books_xml, "lxml")- Tag 찾는 함수 find_all 생성
soup.find_all("author")- find_all: 정규식과 마찬가지로 해당 패턴을 모두 반환
- find(‘invention-title’)
http://goo.gl/aeKMGS, http://goo.gl/lKhFzh 참고
Tag 네임 = title- get_text() : 반환된 패턴의 값 반환 (태그와 태그 사이)
- Adjustable shoulder device for hard upper torso suit
3-5. beautifulsoup Example
from bs4 import BeautifulSoup with open("books.xml", "r", encoding="utf8") as books_file: books_xml = books_file.read() # File을 String으로 읽어오기 soup = BeautifulSoup(books_xml, "lxml") # lxml Parser를 사용해서 데이터 분석 # author가 들어간 모든 element 추출 for book_info in soup.find_all("author"): print (book_info) print (book_info.get_text())
3-6. beautifulsoup 예제 데이터
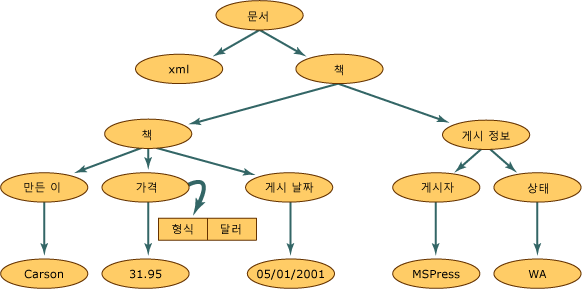
- 미국 특허청 (USPTO) 특허 데이터는 XML로 제공됨
- 해당 데이터중 등록번호 “08621662” 인 “Adjustable shoulder device for hard upper torso suit” 분석
참고: http://www.google.com/patents/US20120260387- XML 데이터를 Beautiful Soup을 통해 데이터 추출
import urllib.request from bs4 import BeautifulSoup with open("US08621662-20140107.XML","r", encoding="utf8") as patent_xml: xml = patent_xml.read() # File을 String으로 읽어오기 soup = BeautifulSoup(xml,"lxml") #lxml parser 호출 #invention-title tag 찾기 invention_title_tag = soup.find("invention-title") print (invention_title_tag.get_text())
- 특허의 출원번호, 출원일, 등록번호, 등록일, 상태, 특허명을 추출
<publication-reference> 등록 관련 정보 <document-id> <country>US</country> <doc-number>08621662</doc-number> 등록번호 <kind>B2</kind> 상태 <date>20140107</date> 등록일자 </document-id> </publication-reference> <application-reference appl-type="utility"> 출원 관련 정보 <document-id> <country>US</country> <doc-number>13175987</doc-number> 출원 번호 <date>20110705</date> 출원일 </document-id> </application-reference>publication_reference_tag = soup.find("publication-reference") p_document_id_tag = publication_reference_tag.find("document-id") p_country = p_document_id_tag.find("country").get_text() p_doc_number = p_document_id_tag.find("doc-number").get_text() p_kind = p_document_id_tag.find("kind").get_text() p_date = p_document_id_tag.find("date").get_text() application_reference_tag = soup.find("application-reference") a_document_id_tag = publication_reference_tag.find("document-id") a_country = p_document_id_tag.find("country").get_text() a_doc_number = p_document_id_tag.find("doc-number").get_text() a_date = p_document_id_tag.find("date").get_text()
3-7. [연습] ipg140107.xml 분석
- ipa110106.xml 파일은 11년 첫째주에 나온 출원 특허를 모은 파일
- 개별 특허들을 나눠서 CSV 형태로 저장 하는 문제
- 개별 특허 시작은 <?xml version="1.0“ 시작함
- 분할된 특허 문서로 부터 특허의 등록번호, 등록일자, 출원 번호, 출원 일자, 상태, 특허 제목을 추출하여 CSV로 만들 것
4. JSON Overview
- JavaScript Object Notation
- 원래 웹 언어인
Java Script의 데이터 객체 표현 방식간결성으로 기계/인간이 모두 이해하기 편함- 데이터 용량이 적고,
Code로의 전환이 쉬움- 이로 인해
XML의 대체제로 많이 활용되고 있음
- Python의 Dict Type과 유사,key:value 쌍으로 데이터 표시

4-1. JSON in Python
- json 모듈을 사용하여 쉽게 parsing 및 저장 가능
- 데이터 저장 및 읽기는 dict type과 상호 호환 가능
- 웹에서 제공하는
API는 대부분 정보 교환 시JSON 활용- 페이스북, 트위터, Github 등 거의 모든 사이트
- 각 사이트 마다
Developer API의 활용법을 찾아 사용
4-2. JSON Read
- JSON 파일의 구조를 확인 → reading → Dict Type처럼 처리
{"employees":[ {"firstName":"John","lastName":"Doe"}, {"firstName":"Anna","lastName":"Smith"}, {"firstName":"Peter","lastName":"Jones"} ]} import json with open("json_example.json","r", encoding="utf8") as f:contents = f.read() json_data = json.loads(contents) print(json_data["employees"])
4-3. JSON Write
- Dict Type으로 데이터 저장 → josn모듈로 Write

세상을 이롭게하는 AI Engineer