들어가기
Evnet Queue와 SlackAlert에 이어 다음과 해결해야 할 리스트가 남았습니다.
- Post 하나 저장할 때마다 기존에 존재하는 Post인지 DB에 질의해 확인하고 있는데 비효율적인가?
- Post Insert를 Bulk Insert로 바꾸기
- Schedule 효율적으로 바꾸기
이번 시간에는 Bulk Insert, Schedule 중점으로 기존 PostCollectService 클래스에 너무 많은 역할이 부여됐다는 생각이 들어 이를 분리하고, 기존 Schedule의 역할과 스레드의 기능적 측면을 리팩토링하고자 합니다. 추가로 Post의 Insert를 한 번에 하나를 Insert 하는 것이 아닌 BulkInsert 전용 Queue와 Event를 만들어 여러 개를 Insert 하려고 합니다.
개선하기(역할 분리, 의존성 제거)
먼저 현재 PostCollectService 입니다. 현재 collectPosts 메서드의 @Scheduled을 통해
모든 Post를 저장하는 작업, 알림을 보내는 작업을 모두 처리하고 있습니다. 일단 Post 작업과 Alert 작업을 분리가 필요하다는 생각이 듭니다. AlertFacadeService의 의존을 제거가 필요해 보입니다.
또한 Post 작업과 알림 작업이 특정 시간마다 스케줄 할 때 스케줄링을 분리할 필요가 있다는 생각이 듭니다.
스케줄링 분리와 AlertFacadeService 의존을 제거해 봅시다.
@Slf4j
@AllArgsConstructor
@Service
public class PostCollectService {
private static final int TEN_MINUTE = 600_000;
private final RssPostParser postParser;
private final SubscribeEntityJpaRepository subscribeEntityJpaRepository;
private final PostEntityJpaRepository postEntityJpaRepository;
private final SubscribeEventPublisher publisher;
private final AlertFacadeService alertFacadeService;
@Scheduled(fixedDelay = TEN_MINUTE)
public void collectPosts() {
List<SubscribeEntity> subscribes = subscribeEntityJpaRepository.findAll();
for (SubscribeEntity subscribe : subscribes) {
processPostCollectionAsync(subscribe);
}
//TODO 스케줄 작업이 끝나면 알림 envet작업이 발생한다. 큐에 담긴 이벤트를 발행한다.
alertFacadeService.alert();
}
/**
* 구독한 블로그의 RSS에서 게시글들을 읽어서 DB에 저장한다.<br> 비동기 처리되어 있으며 블로그 하나당 하나의 스레드에서 동작한다.
*
* @param subscribe 구독한 블로그
*/
private void processPostCollectionAsync(SubscribeEntity subscribe) {
CompletableFuture<Map<String, String>> futurePosts = CompletableFuture.supplyAsync(() ->
postParser.parseRssDocuments(subscribe.getUrl())
.map(resource -> {
updateSubscribeTitle(resource, subscribe);
return savePosts(resource, subscribe);
})
.orElse(new HashMap<>()));
if (!futurePosts.join().isEmpty()) {
SubscribeEvent event = new SubscribeEvent(subscribe.getId(),
Collections.unmodifiableMap(futurePosts.join()));
publisher.publish(event);
}
}
----생략----
//TODO: 글이 새로 추가되면 슬랙에 보낼URL을 기억한다.
private Map<String, String> savePosts(RssSubscribeResource subscribeResource,
SubscribeEntity subscribe) {
----생략----
if (postMap.containsKey(itemResource.guid())) {
post = postMap.get(itemResource.guid());
post.updateBy(itemResource);
} else {
post = PostEntity.from(itemResource, subscribe);
postUrlMap.put(post.getGuid(), post.getTitle());
}
postEntityJpaRepository.save(post);
}
return postUrlMap;
}
----생략----
}스케줄, 스레드 풀
먼저 Post 수집과 알림 역할을 분리해야 합니다. Post를 크롤링 해오는 작업은 서버가 지속되는 한 계속 스케줄링 되어야 하는 작업이고 알림 또한 Event 큐에 담겨져 있으면 사용자에게 알림을 보내야 합니다. 멀티 스레딩과 스레드 풀에 대해 간단히 알아보겠습니다.
프로세스 하나에 여러개의 쓰레드를 띄워 작업을 병렬로 처리하는 방법을 멀티 쓰레딩이라고 한다. 멀티 쓰레딩 환경에서는 각각의 쓰레드가 프로세스의 코드, 데이터, 힙 영역을 공유하므로 메모리가 절약된다. 또한, 쓰레드를 생성하는 것은 프로세스를 보다 생성 비용이 저렴하다.
쓰레드 풀이란 쓰레드를 미리 생성하고, 작업 요청이 발생할 때마다 미리 생성된 쓰레드로 해당 작업을 처리하는 방식을 의미한다. 이때, 작업이 끝난 쓰레드는 종료되지 않으며 다음 작업 요청이 들어올때까지 대기한다.
“한 스레드에게 그 일만 하도록 책임을 할당하자” 각 각 스케줄 작업을 스레드풀에 있는 한 스레드에게만 책임을 맡기고 다른 스레드들은 효율적으로 써보고자 합니다.
먼저 schedule만을 하는 서비스, 설정 클래스를 만들어 줍니다. Post, Alert를 스케줄링할 메서드를 만들어줍니다.
스케줄링 작업을 위한 3개의 스레드가 있는 스레드 풀이 구성합니다.
Count를 3개로 지정해줬는데요 역할은 이러합니다.
- Bulk Insert 스케줄
- Post Collect 스케줄
- Slack Alert 스케줄
@Configuration
public class SchedulerConfig {
private static final int THREADS_COUNT = 3;
@Bean
public ThreadPoolTaskScheduler threadPoolTaskScheduler() {
ThreadPoolTaskScheduler threadPoolTaskScheduler = new ThreadPoolTaskScheduler();
threadPoolTaskScheduler.setPoolSize(THREADS_COUNT);
return threadPoolTaskScheduler;
}
}Bulk Insert
지금 구조상 블로그에 있는 글을 한 번에 하나를 Insert하는 구조를 극복하고자 직접 Bulk Insert 하기 위한 Event Queue를 만들어 Post가 일정량 쌓이면 Schedule마다 한 번에 Insert 하도록 합니다.
물론 Event, Event Listener, Event Publisher도 만들어줍니다.
결과
두 개의 @Scheduled을 통해 기존 Post를 수집하는 스케줄링을 따로 분리한 후 PostCollectService에는 파서에 의한 결괏값과 publisher.publish(post); 를 통해 Bulk Insert Queue에 담길 이벤트(Post)를 처리합니다. PostCollectService 에는 이제 pulibc한 메서드는processPostCollectionAsync 밖에 남지 않습니다. 이메서드 또한 CompletableFuture 를 반환하는 형식으로 변경했습니다.
즉 PostCollectService 에서는 Bulk Insert Queue에 들어갈 Post 엔티티 push와 사용자에게 보낼 새로 갱신된 글의 고유id, 제목을 CompletableFuture<*Map*<String, String> 형태로 보내는 기능만 하게 됩니다.
- 스케줄링 분리와 AlertFacadeService 의존을 제거 또한 성공했습니다.
@Slf4j
@AllArgsConstructor
@Service
public class PostCollectService {
// private static final int TEN_MINUTE = 600_000;
private final RssPostParser postParser;
private final SubscribeEntityJpaRepository subscribeEntityJpaRepository;
private final PostEntityJpaRepository postEntityJpaRepository;
private final PostBulkInsertQueue bulkInsertQueue;
private final PostBulkInsertPublisher publisher;
/**
* 구독한 블로그의 RSS에서 게시글들을 읽어서 DB에 저장한다.<br> 비동기 처리되어 있으며 블로그 하나당 하나의 스레드에서 동작한다.
*
* @param subscribe 구독한 블로그
* @return
*/
public CompletableFuture<Map<String, String>> processPostCollectionAsync(
SubscribeEntity subscribe) {
return CompletableFuture.supplyAsync(
() -> postParser.parseRssDocuments(subscribe.getUrl())
.map(resource -> {
updateSubscribeTitle(resource, subscribe);
return savePosts(resource, subscribe);
}).orElse(new HashMap<>()));
}
----------생략----------
//TODO: 글이 새로 추가되면 슬랙에 보낼URL을 기억한다.
private Map<String, String> savePosts(RssSubscribeResource subscribeResource,
SubscribeEntity subscribe) {
----------생략----------
publisher.publish(post);
}
return postUrlMap;
}
----- 생략 ---------
}@Scheduled (fixedDelay fixedRate)
이제 스케줄들을 관리하는 Service에 대해 알아보겠습니다. 그전에 @Scheduled에 대해 알아봅니다.
- fixedRate : 마지막 호출이 여전히 실행 중이더라도 Spring이 주기적 간격으로 작업을 실행하도록 만듭니다.
- fixedDelay : 마지막 실행이 완료되면 다음 실행 시간을 구체적으로 제어합니다.
"fixedRate"를 사용하는 경우 : 메모리 및 스레드 풀의 크기를 초과하지 않을 것으로 예상되는 경우에는 fixedRate가 적합합니다. 들어오는 작업이 빨리 완료되지 않으면 "메모리 부족 예외"가 발생할 수 있습니다. 예약된 작업은 기본적으로 병렬로 실행되지 않습니다. 따라서 fixedRate 를 사용하더라도 이전 작업이 완료 될 때까지 다음 작업이 호출되지 않습니다.
"fixedDelay"를 사용해야 하는 경우 : 실행 중인 모든 작업이 서로 관련되어 있고 이전 작업이 완료될 때까지 기다려야 하는 경우fixedDelay가 적합합니다. fixedDelay 시간을 신중하게 설정하면 실행 중인 스레드가 새 작업이 시작되기 전에 작업을 완료할 수 있는 충분한 시간을 확보할 수 있습니다.
Post를 수집하는 경우는 이전 작업이 완료될 때까지 기다려야 한다고 생각해 Delay로 지정
Bulk Insert는 작업 실행이 독립적이라 생각해 fixedDelay 지정했습니다.
private final PostCollectService postCollectService;
private final SubscribeEventPublisher publisher;
private final PostBulkInsertQueue bulkInsertQueue;
private final PostEntityJpaRepository postEntityJpaRepository;
private final SubscribeService subscribeService;
//TODO post크롤링, 큐에inset, 큐에서 poll한다음 alert 발생을 각각의 스레드를 할당해 실행 하도록한다.
//Post 수집 크롤링
//스케쥴폴에서 스케쥴 전용 스레드를 할당하고
//파서를 이용해 구독당 post를 가져오는건 비동기 병렬 처리
@Scheduled(fixedDelay = 3 * 1000)
public void collectPosts() {
log.info(" scheduling1 with " + Thread.currentThread().getName() + " at time: "
+ LocalDateTime.now());
List<SubscribeEntity> subscribes = subscribeService.findSubscribeList();
for (SubscribeEntity subscribe : subscribes) {
CompletableFuture<Map<String, String>> future = postCollectService.processPostCollectionAsync(
subscribe);
if (!future.join().isEmpty()) {
SubscribeEvent event = new SubscribeEvent(subscribe.getId(),
Collections.unmodifiableMap(future.join()));
publisher.publish(event);
}
}
}
//queue에 bulk inert 10개씩
//TODO: 수정해야함
@Scheduled(fixedRate = 10000)
public void queueBulkInsert() {
log.info(" scheduling2 with" + Thread.currentThread().getName() + " at time: "
+ LocalDateTime.now());
if (bulkInsertQueue.isRemaining() && bulkInsertQueue.size() > 10) {
List<PostEntity> posts = bulkInsertQueue.pollBatch(30);
postEntityJpaRepository.saveAll(posts);
}
}@Async
지금까지 진행하면서 문득 의문이 들었습니다. "두 개의 Scheduled가 서로 다른 스레드로 2개의 예약된 메서드 호출을 동시에 실행할 수 있는가? 즉 병렬적으로 진짜 처리가 되고 있는가? Async가 뭔지 알아봤습니다.
@Async
처음 시도할 때 @Async는 당연히 비동기 기능을 지원한다는 생각이 들어 다음과 같이 사용했는데요.
@Async
@Scheduled(fixedDelay = 3 * 1000)
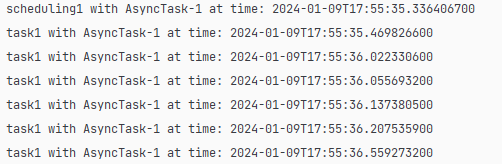
public void collectPosts() {제가 예상한 결과는 제가 위에서 설정했던 쓰레드풀 ex) scheduling1스레드를 실행하며 비동기로 메서드를 실행할 줄 알았습니다. 하지만 전혀 다른 방식으로 실행이 됐습니다.
전에 SchedulerConfig 에서 설정한 MY-SCHEDULER-란 스레드 이름이 나올 줄 알았지만 SimpleAsyncTaskExecutor란 스레드 이름이 나왔습니다.
찾아보니 "스레드를 재사용하지 않습니다" 스레드를 세로 만드는 방식이라 나와있습니다. 그래서 실행할 때마다 숫자가 올라갔는데요.
제가 원하는 방식은 스케줄의 MY-SCHEDULER 스레드에서 그대로 비동기 작업이 이뤄지거나, 새로운 Task 스레드릉 생성해 이 스레드에서 비동기 작업을 이루고 Return되는 방식으로 하고자 했습니다.
따라서 비동기 메서드를 다른 스프링 빈으로 이동하고 코드를 변경하면 비동기 메서드가 새 스레드에서 실행되는 것을 볼 수 있습니다.
scheduling1 with SimpleAsyncTaskExecutor-1 at time: 2024-01-09T17:58:59.219278800
scheduling1 with SimpleAsyncTaskExecutor-2 at time: 2024-01-09T17:59:02.232229800수정
새 스레드를 생성하지 않기위해서는 @Async를 같은 bean에서 호출하지 않으면 됩니다.
동일한 Spring 빈의 메서드 간 메서드 호출은 @Async와 같은 AOP 기능을 사용할 수 없기 때문입니다.
추가 설명: 같은 클래스에 있는 Scheduled 메서드에서 Async 메서드를 호출 하면 새로운 스레드가 만들어지지 않습니다. 이 기능을 사용하려면 스프링 빈이 2개 있어야 하고 첫 번째 빈의 메서드에서 두 번째 빈의 메서드를 호출해야 합니다. 이렇게 하면 다른 스프링 빈에서 메서드를 호출할 때 메서드 호출이 프록시를 통과하여 호출을 가로채고 문서에 언급된 대로 AOP 기능을 추가할 수 있으므로 AOP 기능을 사용할 수 있습니다.
그래서 다음과 같이 수정했습니다. 추가로 AsyncCofig에서 스레드 설정도 해줬습니다.
@Async("asyncTaskExecutor")
public CompletableFuture<Map<String, String>> processPostCollectionAsync(
SubscribeEntity subscribe) {
log.info(" task1 with " + Thread.currentThread().getName() + " at time: "
+ LocalDateTime.now());
return CompletableFuture.supplyAsync(
() -> postParser.parseRssDocuments(subscribe.getUrl())
.map(resource -> {
updateSubscribeTitle(resource, subscribe);
return savePosts(resource, subscribe);
}).orElse(new HashMap<>()));
} @Scheduled(fixedDelay = 3 * 1000)
public void collectPosts() {
log.info(" scheduling1 with " + Thread.currentThread().getName() + " at time: "
+ LocalDateTime.now());
List<SubscribeEntity> subscribes = subscribeService.findSubscribeList();
for (SubscribeEntity subscribe : subscribes) {
CompletableFuture<Map<String, String>> future = postCollectService.processPostCollectionAsync(
subscribe);
if (!future.join().isEmpty()) {
SubscribeEvent event = new SubscribeEvent(subscribe.getId(),
Collections.unmodifiableMap(future.join()));
publisher.publish(event);
}
}
}
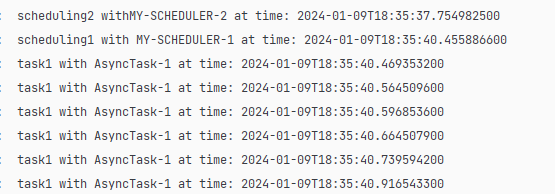
결과는 다음과 같습니다. 두 개의 스케줄이 각 각 스레드에서 실행되며 processPostCollectionAsync가 실행될 때 AsyncTask 스레드가 사용됩니다.
정리
TaskExecutor및 TaskScheduler, @Scheduled, @Async 등 전혀 다른 기능이지만 차이를 정확히 몰라 어려움을 겪었습니다. 생각한 대로 동작하지 않아 많은 어려움이 있었습니다.
마지막으로 정리해 보자면 Scheduler는 특정한 시간에 등록된 작업을 자동으로 실행시키는 것이고, Async는 Spring에서 어노테이션을 제공하여 로직의 비동기 처리를 지원합니다. 스레드 풀에서 적정량의 스레드를 할당해 Scheduler는을 다룰 수 있고 Async 또한 ThreadPoolTaskExecutor를 통해 스레드 설정을 할 수 있습니다. 이런 비동기, 병렬 작업에서는 CompletableFuture를 사용해 계산합니다.
아직까지도 정확히 100퍼센트 이해하지 못한 것 같습니다. 비동기, 멀티스레딩 지식이 필수적이라 언어적 능력 말고도 전반적인 CS능력이 필수적이라는 교훈을 얻은 시간이였습니다.
참고:
Spring @Scheduler parallel running
Deep dive into Spring Schedulers and Async methods
using @Scheduled and @Async together?
Task Execution and Scheduling :: Spring Framework
