들어가기
프로젝트를 진행하며 쿼리를 직접 사용하거나, JPA를 사용하여 특히 페이징 쿼리 같은 빈번히 발생하는 쿼리에 대해 최적화를 하고싶은 생각이 들었습니다. 하지만 구체적으로 쿼리를 최적화 하는 방법을 몰랐기 때문에 학습했습니다.
쿼리를 테스트하고 최적화하는 방법에 대해 학습해 보려고 합니다. 일단 먼저 테스트,최적화 방법을 학습하고, 더 나아가 JPA를 활용한 쿼리 성능 향상을 학습해 보려합니다.
빠른 쿼리를 위한 체크리스트
어플리케이션과 DB 간의 리소스가 상당히 크다면 서비스의 품질은 낮아지고 유저의 만족도는 떨어질 것입니다.
필자도 여러 필터링을 처리하면서 데이터가 많아짐에 따라 처리 속도의 한계를 경험했고 이를 개선 할수 있는
다양한 방법의 최적화가 있겠지만 간단하게 몇 가지 정도 일반적인 방법을 소개할 예정입니다.
* 사용 금지
쿼리를 최적화하는 가장 쉬운 방법은 필요한 칼럼만을 조회하는 것입니다. 아스타리스크(*)를 사용하여 필요하지 않은 컬럼을 조회하는 리소스를 범할 필요는 없습니다.
LIKE사용 시 와일드카드 문자열(%)을 String 앞부분에는 배치하지 않는 것이 좋습니다.
"vlaue LIKE %" LIKE 연산자를 사용하고 검색 문자열의 첫 번째 문자에 와일드카드 문자(% 또는 )가 있는 경우 SQL Optimizer는 쿼리를 실행할 때 강제로 Full Table Scan을 활용합니다.
이말은 즉 Like 검색시 와일드 카드가 시작 부분에 잇는 경우 인덱스를 활용하지 않고 따라서 모든 레코드 검색하므로 검색 속도가 느립니다.
SELECT * FROM TABLE
WHERE VarcharDataColumn LIKE '%TEST%'이 쿼리는 실제 우리가 생성한 컬럼의 인덱스가 무시되고 클러스터형 인덱스 스캔(기본적으로 테이블 스캔)을 수행해야 한다는 것을 알 수 있습니다.
SELECT * FROM TABLE
WHERE VarcharDataColumn LIKE 'TEST%'첫 번째 쿼리와 다르게 뒤에 써줄경우에 우리가 생성한 인덱스를 사용하고 스캔이 아닌 검색을 수행합니다.

실제 위 두쿼리의 성능 차이입니다.
SELECT * FROM TABLE
WHERE VarcharDataColumn value IN (...), value = "..."다른 방법의 조건 절입니다. 이 방법 역시 첫 번째 보다는 효과적입니다.
정리 하자면 같은 결과를 낼 때에 첫 번째 방법 보다는 다른 형태의 2,3 번 째의 조건절이 더 효과적인 것을 알 수 있습니다.
SELECT DISTINCT, UNION DISTINCT와 같은 중복 값을 제거하는 연산은 자제합니다.
중복값을 제거하는 연산은 시간이 많이 걸리는 연산입니다.
만약 불가피하다면 DISTINCT 연산을 대체하거나,
테이블의 크기를 줄이는 방법을 고민합니다. 대체 방법으로는 EXISTS, GROUP BY를 써서 대체하는 방법이 있습니다.
EXISTS 와 IN
- Exists
서브쿼리가 반환하는 결과 값이 있는지를 조사한다.
단지 반환된 행이 있는지 없는지만 보고 값이 있으면 참 없으면 거짓을 반환한다.
- IN
집합 내부에 값이 존재하는지 여부 확인한다.
실제로 존재하는 데이터의 값을 비교하기 때문에 Exists보다 속도가 느린경우가 있다.
UNION에는 중복 값을 제거하는 기능이 존재하므로 DISTINCT와 함께 사용할 필요가 없습니다.
WHERE절에 가급적이면 별도의 연산을 걸지 않을 것
WHERE FLOOR(v.value/2) = 2 이 쿼리는 value의 값 자체를 변화하여 조건을 설정 하며
이 쿼리의 경우 Full Table Scan을 하면서 모든 Cell 값을 탐색하고, 수식을 건 뒤, 조건 충족 여부를 판단해야 합니다. 시간 복잡도 O(n)
WHERE v.value BETWEEN 4 AND 5 ETWEEN 구문, AND
SELECT column_name(s)
FROM table_name
WHERE column_name BETWEEN value1 AND value2;
value 값의 범위를 기준으로 조건을 가집니다. BETWEEN절을 활용하여 인덱스를 효율적으로 활용할 가능성이 높습니다.인덱스를 그대로 활용할 경우 모든 필드를 탐색할 필요없어 O(log n) 을가집니다.
같은 조건이라면 GROUP BY 연산 시에는 가급적 HAVING보다는 WHERE 절을 사용하는 것이 좋습니다.
- 쿼리에는 FROM, WHERE, GROUP BY, HAVING, SELECT, ORDER BY 절과 같은 구문을 실행하는데 순서가 존재합니다.

논리적 sql문 실행은 이와같이 WHERE절은 HAVING 절보다 먼저 실행됩니다.
GROUP BY id
HAVING v.id > 100;WHERE m.id > 100
GROUP BY id ;그렇기 때문에 HAVING절에서 처리하기 이전에 WHERE절에서 데이터 처리가 잘이뤄진다면 GROUP BY에서 다뤄야 하는 데이터 크기는 작아지기 때문에 효율적인 연산이 가능합니다.
- 참고로 UNION 문은 중복된 열의 존재 유무에 상관없이 열을 선택할 때 중복 검사를 하지만 UNION ALL은 중복검사를 하지 않으므로, UNION 보다는 UNION ALL을 사용하는 것이 빠릅니다.
JOIN에 주의합니다
3개 이상의 테이블을 INNER JOIN 할 때는 크기가 가장큰 테이블을 FROM절에 배치하고, INNE JOIN 절에는 남은 테이블을 작은 순서대로 배치하는 것이 좋습니다.
즉 INNSER JOIN의 최적화 여부가 쿼리속도에 큰 영향을 미칩니다. innser join 과정에서 간단한 경우 대부분의 query planner(쿼리 실행 계획)가 에서 가장 효과적인 순서를 탐색해 inner join 의 순서를 바꾸기 때문입니다.
- 하지만 늘 그렇듯 항상 통용되지지는 않습니다.
쿼리 성능 테스트
크게 3가지 방법으로 테스트,쿼리 정보 분석을 통해 쿼리 실행 계획에 대한 정보, 비용 계획을 알수 있고 성능을 확인 할수 있습니다.
Profiling
SELECT @@Profiling;
결과 값이 1이면 ON, 0이면 OFF 입니다.
SET profiling=1;
쿼리 프로파일링을 다음과 같이 활성화합니다.
그 후 자연스럽게 쿼리를 날린 후
SHOW profiles
를 통해 확인할수 있습니다.
SHOW profile CPU FOR QUERY number;
이명령어를 통해 CPU 사용량을 분석할 수도 있습니다.
Explain
쿼리 명령문을 어떻게 수행할 것인지 실행 계획에 대한 정보를 보여줍니다.
즉 SQL Query문이 어떻게 실행되는지에 정보를 제공합니다.
잠깐 둘의 차이점은?
Profiling 과의 차이점으로는 Explain은 쿼리 실행 계획은 분석하여 쿼리의 최적화에 집중하고, Profiling은 실행 중인 프로그램 또는 쿼리의 성능을 모니터링하여 프로그램이나 쿼리의 실행 시간, CPU 사용량, 메모리 사용량, 디스크 I/O 을 식별하고 최적화를 위한 개선 작업에 활용하는 데 사용됩니다.
Optimizer Trace
Optimizer는 여러 조건들을 통해 쿼리 플랜을 최초 작성하고, 마지막으로 한번 더 정리하는 과정입니다.
인덱스를 걸어줘도 Full Table Scan을 하는 경우가 있는데 이경우 인덱스가 사용되지 않은 이유를 확인 가능합니다.
SHOW VARIABLES LIKE 'optimizer_trace';
SET OPTIMIZER_TRACE = 'enabled=on';
옵티마이저 트레이스의 활성화
- 옵티마이저 트레이스의 사용방법입니다.
- 트레이스 활성화.
- 해석하고 싶은 쿼리 실행
- 트레이스 출력
결국 explain 명령어를 사용한 쿼리 실행 계획도 옵티마이저가 최종적으로 선택한 실행 계획이고, 그 과정에서 최적화 비용 계산, 또는 실행 계획의 비교가 어떻게 일어나는지는 알수 없습니다. 하지만 트레이스에는 이러한 내용이 설명 되어 있습니다. 출력형식은 json입니다.
However, if we consider only the component names, we wind up with:
MariaDB> select * from information_schema.optimizer_trace limit 1\G
*************************** 1. row ***************************
QUERY: select * from table1 where a<100
TRACE:
{
"steps": [
{
"join_preparation": { ... }
},
{
"join_optimization": {
"select_id": 1,
"steps": [
{ "condition_processing": { ... } },
{ "table_dependencies": [ ... ] },
{ "ref_optimizer_key_uses": [ ... ] },
{ "rows_estimation": [
{
"range_analysis": {
"analyzing_range_alternatives" : { ... },
"chosen_range_access_summary": { ... },
},
"selectivity_for_indexes" : { ... },
"selectivity_for_columns" : { ... }
}
]
},
{ "considered_execution_plans": [ ... ] },
{ "attaching_conditions_to_tables": { ... } }
]
}
},
{
"join_execution": { ... }
}
]
}옵티마이저가 어떤 결정을 내렸는지, 어떤 최적화 전략을 사용했는지, 인덱스 선택 과정 등을 상세히 확인할 수 있습니다.
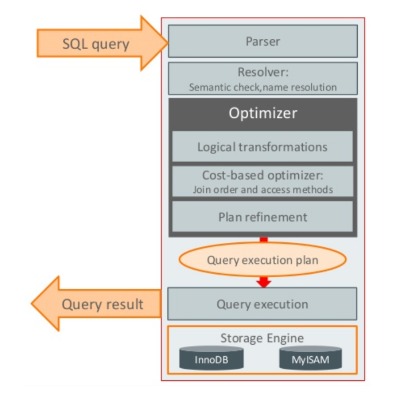
위 그림과 같이 옵티마이저 트레이스 출력을 통해 옵티마이저가 하는 역할을 그대로 확인 가능합니다.
그렇다면 JPA 에서의 쿼리 성능 최적화는?
2편에서 계속..
