Aurora(중요)
작동 방식에 대한 전반적인 이해가 중요
-
Aurora는 AWS 고유의 기술이다.
Aurora DB에 호환 가능한 드라이버는 Postgres와 MySQL과 호환되도록 만들었으며, 클라우드에 최적화되어 있고 여러 최적화를 통해 RDS의 MySQL보다 5배 높은 성능과 Postgres보다 3배 높은 성능과 개선점을 제공. -
Aurora의 스토리지, 장단점
- 공유 볼륨은 자동으로 확장된다.
10G ~ 128TB까지 자동 확장 - 읽기 전용 복제본을 15개까지 둘 수 있다.
MySQL = 5개
Aurora = 15개
+ 복제 속도도 더 빠르다. - 장애조치가 즉각적이다.
다중 AZ나 MySQL RDS보다 더 빠르다. - 기본적으로 클라우드 네이티브이므로 가용성이 높다.
- (단점) 비용은 RDS에 비해 약 20% 높다.
그러나 스케일링 측면에서는 더 효율적이다.
오히려 비용을 절감할 수 있음.
- 공유 볼륨은 자동으로 확장된다.
높은 가용성과 읽기 스케일링
실제 상호작용 대상은 스토리지가 아님.
아마존에서 설계한 방식이며 이해를 돕기위한 설명이다.
- 높은 가용성
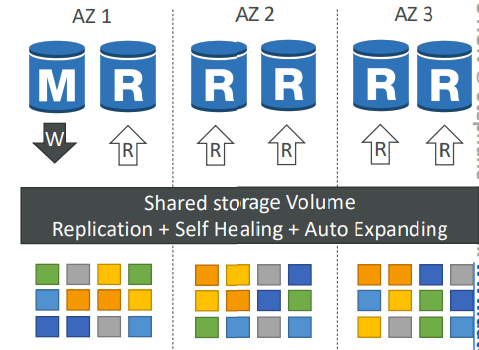
- 세 AZ에 걸쳐 무언가 기록할 때마다 6개의 사본을 저장한다.
스트라이프 형식으로 저장
쓰기에는 6개 사본중 4개만 있으면 된다.
읽기에는 6개 사본중 3개만 있으면 된다. - 자가 복구 과정
일부 데이터에 문제가 생기면 백엔드에서 P2P 복제를 통해 자가복구 진행 - 단일 볼륨에 의존하지 않고 수 백 개의 볼륨을 사용
-> 리스크를 크게 감소 - RDS의 다중AZ와 유사하다.
쓰기를 받는 인스턴스는 하나 -> Aurora에도 마스터가 있고 마스터에서 쓰기를 받는다.
마스터가 작동하지 않으면 평균 30초 이내로 장애조치 시작. - 마스터 외에 읽기 전용 복제본을 15개 둘 수 있다.
복제본을 많이 두고 읽기 워크로드를 스케일링할 수 있다.
-> 마스터에 문제가 생기면 읽기 전용 복제본중 하나가 마스터로 대체
이 복제본들은 리전 간 복제를 지원한다.
- 세 AZ에 걸쳐 무언가 기록할 때마다 6개의 사본을 저장한다.
=> 마스터는 하나이고 복제본을 15개생성 가능하며 스토리지가 복제된다.
=> 작은 블록 단위로 자가 복구하고 확장한다.
Aurora DB Cluster
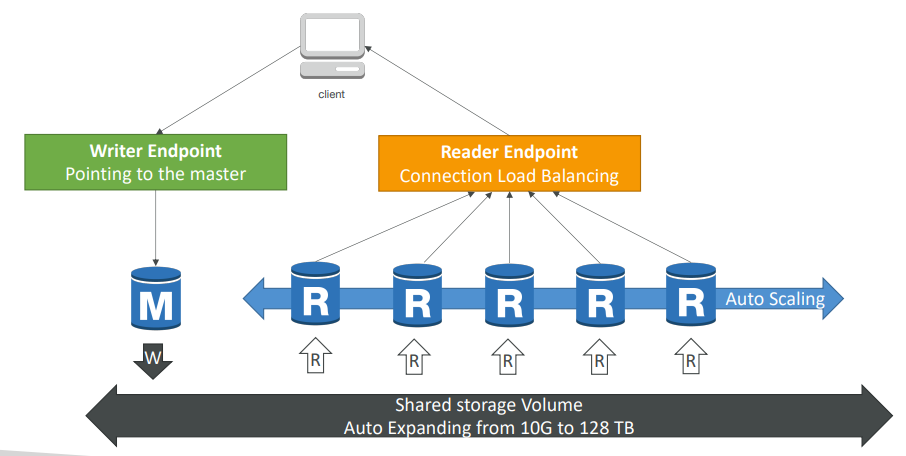
- 작동 방식
공유 스토리지는 10GB ~ 128TB까지 자동 확장되고, 스토리지에 쓰기는 마스터 볼륨에만 쓸 수 있다.
마스터에 문제가 생겨 마스터가 바뀔 경우를 대비해 Aurora는 Writer 엔드포인트를 제공한다.
Writer 엔드포인트는 DNS 이름으로 항상 마스터를 가리킨다.
=> 장애 조치 후에도 클라이언트는 라이터 엔드포인트와 상호작용해 올바른 인스턴스로 자동으로 리다이렉트된다.- 다수의 읽기 전용 복제본이 있다.
이 복제본들은 자동 스케일링이 가능하다.(최대 15개)
자동 스케일링을 활성화한 앱은 Reader 엔드포인트를 지원해 연결 로드 밸런싱에 도움을 준다. -> 모든 읽기 전용 복제본과 자동으로 연결
클라이언트가 리더 엔드포인트에 연결될 때마다 읽기 전용 복제본 중 하나로 연결되 로드 밸런싱을 돕는다.(연결 레벨에서 일어남)
- 다수의 읽기 전용 복제본이 있다.
Aurora 기능
- 자동 장애 초기
- 백업 및 복구
- 격리 및 보안
- 산업 규정 준수
- 자동 스케일링을 통한 버튼식 스케일링
- 제로 다운타임 자동 패치 설치
- 고급 모니터링
- 통상 유지 관리
- 백트랙: 어떤 시점의 데이터로 복원하는 기능.(백업에 의존하는것이 아님)
ex) 어제 오후 3시의 상태로 돌아가려고했다가 어제 오후 6시로 돌아가고 싶을때에도 가능.
실습
Aurora DB를 생성하면 리전 클러스터 안에 writer 인스턴스, Reader 인스턴스가 있다.
즉, 쓰고 읽는 인스턴스가 각각 존재하고, 각각 다른 AZ에 있다.
+ 생성한 DB를 누르면 2개의 엔트포인트를 볼 수 있다
+ 각각 리더 엔드포인트와 라이터 엔드포인터이다.
++ 리더엔드포인트-리더인스턴스, 라이터엔드포인트-라이터인스턴스로 연결되 이 엔드포인트로 애플리케이션이 Aurora에 접속한다.
++ 각각 인스턴스를 직접 클릭하면 각각의 전요 엔드포인트도 있다.
리더 클러스터에 리더를 추가할 수 있다.
+ 다른 리전에 복제본을 만들고 싶으면 리전 간 읽기 전용 복제본을 생성할 수 있다.
+ 엔드포인트를 특정 시점으로 복원할 수도 있다.
+ 복제본 자동 스케일링도 추가 가능(중요 기능)
-> 평균 Aurora 복제본 CPU 사용량, 평균 Aurora 복제본 접속 횟수에 기반해 읽기 전용 복제본을 스케일링하는 정책을 만들 수 있다.
-> 정책 적용 스케일링 주기, 최소/최대 개수를 정할 수 있다.
작업 > AWS 리전 추가
글로벌 데이터베이스 기능이 활성화된 Aurora 버전을 선택한 경우에만 가능.
이는 DB 리전을 다른 리전에 추가할 수 있다. -> 글로벌 Aurora를 만들 수 있다.
+ 대형 인스턴스로 변경해야 DB 클러스터에 다른 리전을 추가할 수 있다.
- 확장성 높고, 글로벌 기능을 갖춘 편리한 서버리스 DB = Aurora
고급 기능
- 서버리스
서버리스로 인스턴스를 만들고 싶다면 Serverless v2를 선택하고
Aurora Capacirt unit(ACU)를 설정하면 된다. - '로컬 쓰기 전달' 옵션
쓰기는 읽기 전용 복제본에 적용되어, 쓰기 인스턴스로 자동적으로 전달된다. -> 연결 관리를 더 쉽게 도와준다.
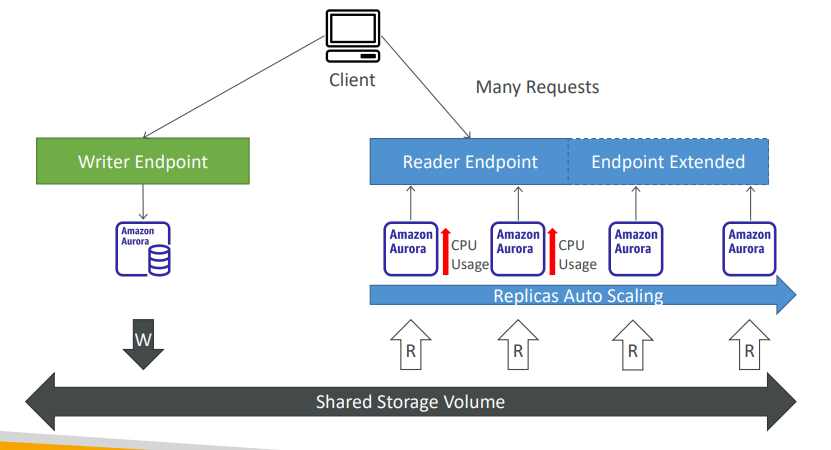
- Aurora Replicas - Auto Scaling
마스터 볼륨이 쓰기 엔드포인트를 받고 읽기전용이 읽기 엔드포인트를 받을때 읽기 트래픽이 많을떄 CPU의 사용량이 증가해 자동으로 읽기 전용 복제본을 추가할 것이다. 읽기 엔드포인트는 새로운 리플리카 확장에 사용될 것이고, 새로운 리플리카들은 트래픽을 받기 시작하면 CPU 사용량이 전체적으로 줄어들 것.
- 사용자 지정 엔드포인트
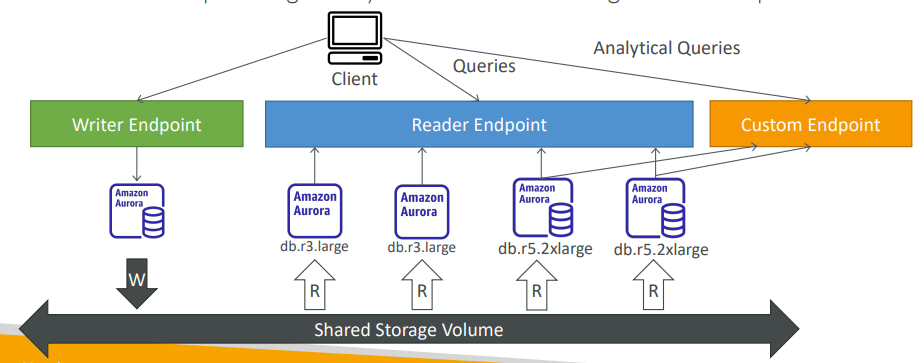
위 그림과 같이 두 종류의 복제본이 있다 가정해보자
어떤 읽기 전용 복제본보다 큰 복제본도 있는 상태이다.- 왜 이렇게 구성했을까?
Aurora 인스턴스의 부분집합을 사용자 지정 엔드포인트로 정의하기 위해서이다.
용량이 큰 복제본에 사용자 지정 엔드포인트를 정의하면 분석적 쿼리를 담당하게해 더 효율적인 구성을 짤 수 있다.
이렇게 사용자 지정 엔드포인트를 정의하면 리더 엔드포인트는 사용되지 않는다.(사라지는것은 아님)
-> 각각의 업무마다 사용자 지정 엔드포인트를 만들어줘야 한다.
- 왜 이렇게 구성했을까?
- 서버리스
- 서버리스는 자동화된 DB 인스턴스화 및 실제 사용량에 따른 오토 스케일링을 제공
- 간헐적이고 예측 불가능한 업무량에 대응하는 것을 도와준다.
-> 즉, capacity planning을 할 필요가 없다.
활용하고 있는 Aurora마다 초당 비용 지불 하는 것이 효율적이다.
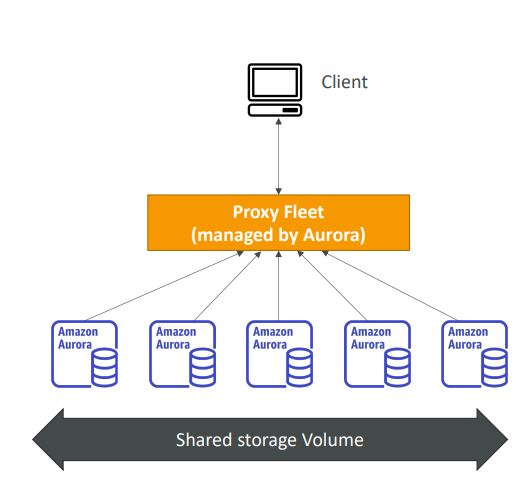
-> 클라이언트가 프록시 플릿(Aurora가 관리)에 연락하면 백엔드에서 Aurora를 생성
업무량에 기반해 서버리스 방식으로 작동해 미리 용량을 준비하지 않아도 된다.
- 글로벌 Aurora
- Aurora 교차 리전 읽기 전용 복제본
재해 복구에 도움이 많이 된다.
실행하기 간단 - 그러나 Aurora 글로벌 DB를 이용을 추천한다
모든 읽기/쓰기를 하는 하나의 기본 리전이 있고, 최대 5개의 보조 읽기 전용 리전을 만들 수 있는데 이는 응답 지연이 1초 이하이다.
또한 보조 리전 당 최대 16개의 읽기 전용 복제본을 사용할 수 있다.
=> 전 세계에서 오는 읽기 업무량에 따른 대기 시간을 줄이는데 도움을 준다.
한 리전에 DB 중단이 일어날 경우 재해 복구를 위해 다른 리전을 진급시키는데 다른 리전으로 들어가 복구하는 시간이 1분 이내이다.
평균적으로 Aurora 글로벌 DB은 한 리전에서 다른 리전으로 데이터를 복제하는 데 1초 이하의 시간이 걸린다(-> 글로벌 Aurora)
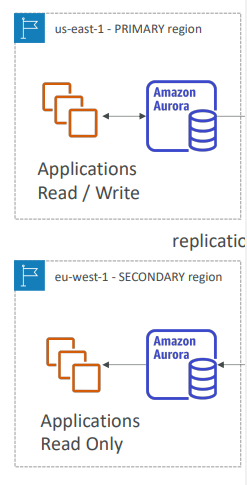
(설명)
기본 리전에는 응용프로그램이 읽기/쓰기를 하는 곳이다.
그리고 다른 리전에 보조 리전을 만든다. 보조 리전은 Aurora의 글로벌 DB와 데이터 복제가 일어나고, 읽기만 가능하다.
만약 기본 리전이 중단되면 보조 리전으로 장애조치를 하고 읽기/쓰기를 할수 있는 Aurora 클러스터로 승격된다.
- Aurora 교차 리전 읽기 전용 복제본
- Aurora 머신러닝
- Aurora는 AWS의 머신러닝 서비스와 통합하기도 한다.
SQL 인터페이스를 통해 응용프로그램에 머신러닝 기반의 예측을 추가할 수 있다. - 지원 서비스
- SageMaker: 어떤 종류의 머신러닝 모델이라도 사용가능하게 해준다.
- Comprehend: 감정 분석을 할 때 사용
- 사용 사례
이상 행위 탐지, 관고 타켓팅, 감정 분석, 상품 추천등 Aurora안에 있다.
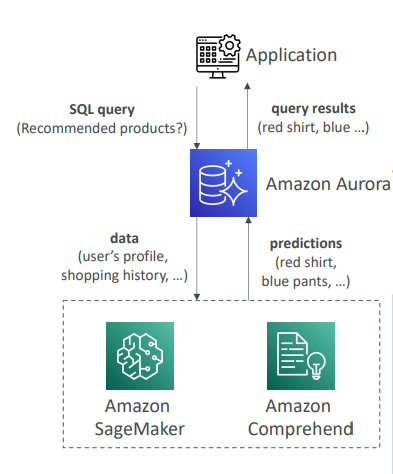
- Aurora는 AWS의 머신러닝 서비스와 통합하기도 한다.
