VPC
VPC 피어링
- 서로 다른 지역 서로 다른 계정의 VPC를 하나의 VPC 처럼 연결
- VPC CIDR가 겹치면 안된다.
- VPC 피어링은 두 VPC 간에 발생하고 전이되지 않는다.
즉, 서로 통신하려는 각 VPC에는 VPC 피어링이 활성화되어 있어야 한다.
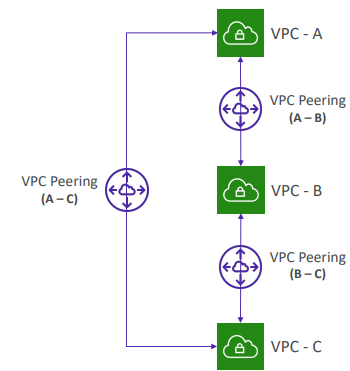
- A-B, B-C가 피어링으로 연결되어 있어도 A-C가 통신하려면 A-C간 피어링 연결을 활성화해야 한다.
- VPC가 서로 쌍을 이루고 있더라도 서로 다른 VPC의 EC2 인스턴스가 서로 통신할 수 있도록 각 VPC 서브넷의 모든 라우팅 테이블을 업데이트해야 한다.
==> A VPC와 B VPC를 피어링 연결 후 각 라우팅 테이블을 연결 시켜준다.
ex: <A 라우팅 테이블 수정>
Destination: B VPC CIDR, Target: 생성한 Peering Connection선택
<B 라우팅 테이블 수정>
Destination: A VPC CIDR, Target: 생성한 Peering Connection선택
VPC 피어링 - 알아두면 좋은 점
- 한 계정 A에서 계정 B로 VPC를 연결하려면 지역을 넘나들 수도 있다.
이 상황은 계정 내에서 발생할 수도 있지만 여러 계정 간에도 발생할 수 있다. - 보안 그룹에서 다른 보안 그룹을 참조할 수 있다.
동일한 지역의 계정 전체에서 피어링된 VPC의 보안 그룹을 참조하는 것도 가능하다.
이는 소스에 IP로 지정하지 않아도 되어 유용하다.
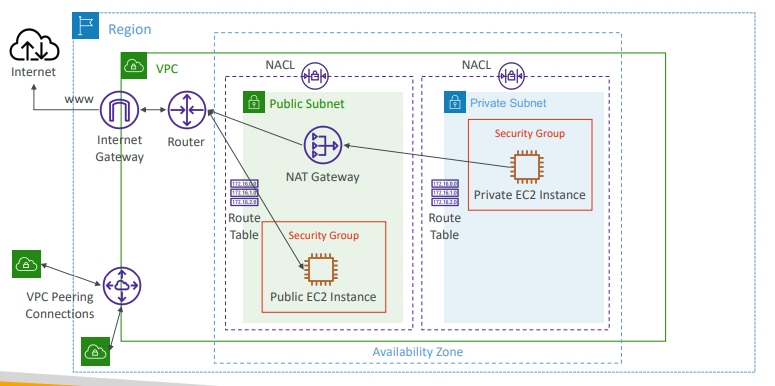
- VPC 피어링을 추가해 VPC를 다른 VPC에 연결 가능
VPC 엔드포인트
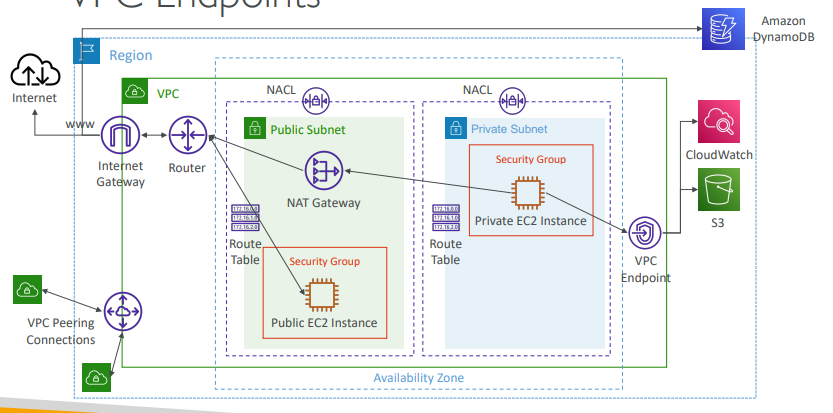
- AWS에서 서비스를 이용할때 퍼블릭 액세스가 가능한데 이는 NAT GW나 IGW를 통해 액세스하는 것이다.
- S3나 CloudWatch같은 서비스를 이용할 때는 인터넷을 경유하지 않고 프라이빗 액세스를 원할 수도 있다.
이때 VPC 엔드포인트를 사용하면 인터넷을 거치지 않고 액세스 가능하다.
프라이빗 AWS 네트워크만 거쳐 바로 해당 서비스에 액세스한다. - VPC Endpoints (AWS PrivateLink)
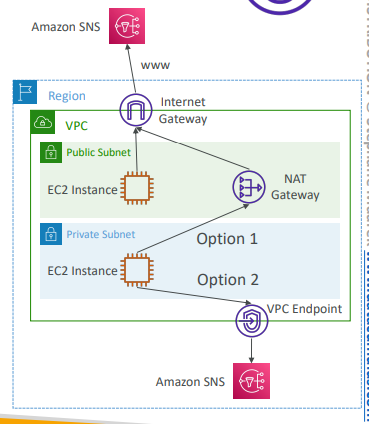
- SNS 서비스에 3가지 방법으로 엑세스 가능.
- Private Subnet EC2 Instance -> NAT GW -> IGW -> SNS
- Public Subnet EC2 InstanceIGW -> SNS
- Private Subnet EC2 Instance -> VPC Endpoint -> SNS
- 모든 AWS 서비스는 퍼블릭에 노출되어 있고 퍼블릭 URL을 갖는다.
- VPC 엔드포인트를 사용하면 퍼블릭 인터넷을 거치지않고 프라이빗 네트워크를 사용.
- VPC 엔드포인트는 중복과 수평 확장이 가능하다.
- IGW,NAT GW없이 AWS 서비스에 액세스 가능하게 함
- 문제 해결
VPC에서 DNS 설정 해석이나 라우팅 테이블을 확인해 트러블슈팅한다.
VPC 엔드포인트 유형
- 인터페이스 엔드포인트(PrivateLink)
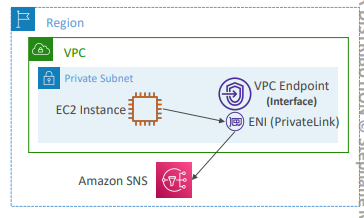
- 진입점으로 ENI(VPC의 Private IP)를 프로비저닝
- ENI가 있기때문에 반드시 보안 그룹을 연결해야 한다.
- 대부분의 AWS 서비스를 지원한다.
- 요금: 시간 단위 + 처리되는 GB 단위
- 게이트웨이 엔드포인트
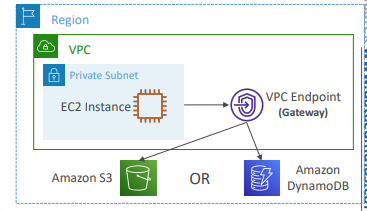
- GW를 프로비저닝
- GW는 반드시 라우팅 테이블의 대상이 되어야 한다.
IP 주소를 사용하거나 보안 그룹을 사용하지 않고 라우팅 테이블의 대상이 되는 것. - GW 엔드포인트의 대상
- S3
- DynamoDB - 요금: 무료
그렇다면 S3나 DynamoDB에서 어떤 타입을 써야 하는가
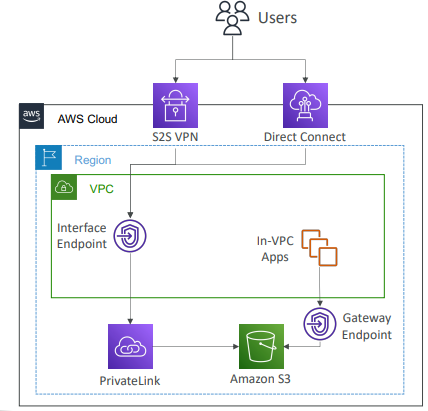
- 게이트웨이 엔드포인트가 대체적으로 유리하다.
무료이기도 하고, 라우팅 테이블만 수정하면 되기 때문 - 인터페이스 엔드포인트를 사용하는 경우
- 온프레미스에서 액세스해야 경우
EX)
- 온프레미스에 있는 데이터 센터에 프라이빗으로 액세스해야 하는 경우 Site-to-Site VPC이나 직접 연결 방법을 사용
- 다른 VPC에 연결할 때 인터페이스 엔드포인트 유형을 사용.
VPC 엔드포인트 실습
# VPC 엔드포인트 실습 과정
* 현재 라우팅 테이블 설정을 하지 않은 상태
1. 퍼블릭 인스턴스를 생성(bastion)
2. private 서브넷에 인스턴스 생성
3. 생성한 인스턴스에 IAM역할 부여(S3접근)
2-1 역할 생성
IAM > 서비스: EC2 , 정책: AmazonS3ReadOnlyAccess > 생성
3. bastion을 통해 private에 있는 인스턴스에 접속
4. 명령어 실행
=====================
$ aws s3 ls
=====================
실행 안되는것을 확인
5. 엔트 포인트 생성하기
VPC > 엔드포인트 > Services: S3 검색 후 Gateway 타입 선택 , VPC, 라우팅 테이블 선택 > 생성
6. 다시 들어가서 'aws s3 ls' 실행해보기
* 여기서 CLI 설정을 해줘야 한다.
CLI 리전은 기본값으로 us-east-1로 설정되어 있어 변경해야함
==================
$ aws s3 ls --region <해당 리전>
==================VPC Flow Logs
- 인터페이스로 들어오는 IP 트래픽 정보를 얻을 수 있다.
- VPC 수준이나 서브넷 수준, ENI 수준의 정보를 포착
- VPC Flow를 통해 VPC에서 일어나는 연결 문제를 모니터링하고 해결하는 데 유용
- 이 흐름 로그를 S3, CloudWatch, Kinesis Data Firehose에 전송 가능
ELB, RDS, ElastiCache, Redshift, WorkSpaces, NAT GW, Transit Gateway ... 등 AWS의 관리형 인터페이스에도 전송 가능 - VPC Flow Logs Syntax

- 버전, 인터페이스 ID, 소스 주소, 대상 주소, 소스 포트, 대상 포트, 프로토콜, 패킷, 바이트 수, 시작, 끝, 액션, 로그 상태 순
- srcaddr & dstaddr: 문제가 있는 IP 식별에 도움을 준다.
어떤 IP가 반복적으로 거부되는 걸 보면 그 IP에 문제가 있을 수 있다.
- srcport & dstport: 문제가 있는 포트를 식별하는데 도움을 준다.
- Action: ACCEPT/REJECT, 보안 그룹 또는 NACL 수준에서 성공/실패 여부를 알려준다.
- VPC Flow Logs를 이용해 사용 패턴을 분석하거나 악의적인 행동이나 포트 스캔 등을 탐지 - VPC Flow를 쿼리하는 방법
- Athena를 S3에 사용하는 방법
- CloudWatch Logs Insights로 스트리밍 분석
VPC Flow를 이용해 보안그룹과 NACL 문제를 해결 예시
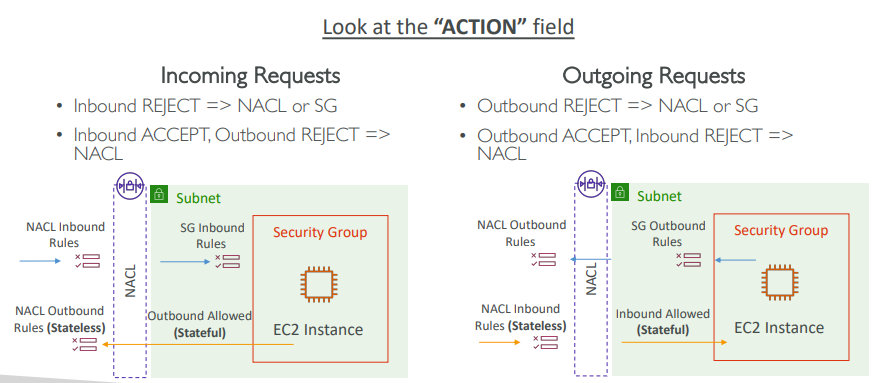
- ACTION 필드를 확인해 NACL과 서브넷에 유입되는 통상적인 요청을 살펴본다.
- (왼) 만약 인바운드 REJECT가 되면 외부에서 EC2 인스턴스로 유입되는 요청이 거부 된것이다.
이 사진에서 보면 NACL이 요청을 거부하거나 보안 그룹이 요청을 거부한다는 것이다. - 인바운드 ACCEPT, 아웃바운드 REJECT라면 NACL의 문제라는 뜻이다.
NACL은 무상태이기 때문 - (오) 만약 아웃바운드 REJECT라면 NACL이나 보안 그룹에 문제가 있는것.
- 아웃바운드 ACCETP, 인바운드 REJECT면 NACL의 문제
- (왼) 만약 인바운드 REJECT가 되면 외부에서 EC2 인스턴스로 유입되는 요청이 거부 된것이다.
VPC Flow의 아키텍처
1)

- Flow Logs가 CloudWatch Logs로 갈 수 있다.
- CloudWatch Contributor Insights를 이용해 VPC나 원하는 것에 대한 네트워크에 가장 많이 기여하는 상위 10개 IP 주소를 확인할 수 있다.
2)

- Flow Logs를 사용해 CloudWatch Logs로 전송한다.
- 메트릭 필터를 설정해 SSH 또는 RDP 프로토콜을 검색
- 평소보다 SSH 또는 RDP가 많으면 CloudWatch Alarm을 트리거
- SNS를 통해 경보 생성
3)

- Flow Logs를 사용하고 모든걸 S3 버킷에 전송해 저장
- 이후 Athena를 사용해 SQL로 된 VPC Flow Logs를 분석
- 그리고 QuickSight로 시각화도 가능.
VPC Flow Logs 실습
# VPC > 실습할 VPC 선택 > Flow Logs 목록 선택 > Flow Logs 생성
- name: DemoS3FlowLog
- filter: Accept|Reject|All // 어떤 트래픽이 왜 통과되지 않는지 디버깅 -> 거부형
- 최대 집계 주기: 10분|1분 // 보통은 10분 권장
- 전송 대상: CloudWatch Logs|S3|Kinesis Firehose(same|diff)account // 여기선 S3 선택
- S3 버킷 ARN: 실습에 사용할 ARN
생성
# CloudWatch Logs를 위한 Flow Logs 생성
- name: DemoCWFlowLog
- filter: Accept|Reject|All
- 최대 집계 주기: 10분|1분
- 전송 대상: CloudWatch Logs|S3|Kinesis Firehose(same|diff)account // 여기선 CloudWatch 선택
- 대상 로그 그룹: CloudWatch Logs > 로그 > 로그 그룹 > 로그 그룹 생성 >
이름: VPCFlowLgos
- 보관 기간: 1일 > 생성 후 선택
IAM 역할: IAM > 역할 생성 > 커스텀 신뢰정책 선택 >
=================
"Principal": {
"Service":"vpc-flow-logs.amazonaws.com"
}
=================
> 권한 정책: CloudWatchLogsFullAccess 선택 > 이름: flowlogsRole 생성 후 선택
생성
# 이제 이 로그들을 보고 어떤 IP가 접속 시도했는지 보고 NACL 수준에서 차단등의 작업을 할 수 있다.
# S3와 Athena를 사용해 분석하기
## 쿼리 위치 지정
Athena > 설정 > 관리 > 결과를 저장할 S3 버킷 지정 (ex: s3://<버킷 이름>/athena > 저장
# 구글에 aws vpc logs athena 검색 후 튜토리얼에서 구문 복사
=============
CREATE EXTERNAL TABLE IF NOT EXISTS `vpc_flow_logs` (
version int,
account_id string,
interface_id string,
srcaddr string,
dstaddr string,
srcport int,
dstport int,
protocol bigint,
packets bigint,
bytes bigint,
start bigint,
`end` bigint,
action string,
log_status string,
vpc_id string,
subnet_id string,
instance_id string,
tcp_flags int,
type string,
pkt_srcaddr string,
pkt_dstaddr string,
region string,
az_id string,
sublocation_type string,
sublocation_id string,
pkt_src_aws_service string,
pkt_dst_aws_service string,
flow_direction string,
traffic_path int
)
PARTITIONED BY (`date` date)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ' '
LOCATION 's3://DOC-EXAMPLE-BUCKET/prefix/AWSLogs/{account_id}/vpcflowlogs/{region_code}/'
TBLPROPERTIES ("skip.header.line.count"="1");
=============
를 쿼리에 넣고 S3 부분을 해당하는 S3 버킷 URI로 수정 후 구문 실행
이후 테이블 생성되는지 확인
# 튜토리얼에 아래에 있는 구문 찾아 실행
==============
ALTER TABLE vpc_flow_logs
ADD PARTITION (`date`='YYYY-MM-dd')
LOCATION 's3://DOC-EXAMPLE-BUCKET/prefix/AWSLogs/{account_id}/vpcflowlogs/{region_code}/YYYY/MM/dd';
==============
ADD PARTITION에 ('date'='2024-08-19')로 변경 -> 번거롭다면 Glue를 사용하면 자동으로 할 수 있다.
S3 버킷의 YYYY/MM/dd 까지 들어간 후 URI 복사해 LOCATION에 붙여 넣은 후 실행
# select를 사용해 로그를 쿼리하기
============
SELECT *
FROM vpc_flow_logs
WHERE date = DATE('2020-05-04')
LIMIT 100;
SELECT day_of_week(date) AS
day,
date,
interface_id,
srcaddr,
action,
protocol
FROM vpc_flow_logs
WHERE action = 'REJECT' AND protocol = 6
LIMIT 100;
SELECT SUM(packets) AS
packetcount,
dstaddr
FROM vpc_flow_logs
WHERE dstport = 443 AND date > current_date - interval '7' day
GROUP BY dstaddr
ORDER BY packetcount DESC
LIMIT 10;
등등...
============
배치 분석할 때 아주 유용하다.
# 리소스 삭제 (중요)