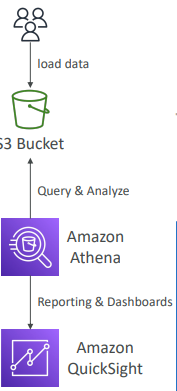
1. Amazon Athena
Athena: S3 버킷에 저장된 데이터를 분석할때 사용하는 서버리스 쿼리서비스
- 데이터를 분석하기 위해서 표준 SQL을 통해 파일을 쿼리해야한다.
- Athena는 SQL 언어를 사용하는 Presto 엔진에 빌드된다.
- 사용자가 S3 버킷에 데이터를 로드하거나, 본인 자신의 S3 버킷에 데이터를 로드하면 Athena 서비스를 사용해 이동하지 않고 S3에서 데이터를 쿼리하고 분석할 수 있다.
- CSV,JSON,ORC,Avro,Parquet 등 다양한 형식 지원
- 비용: 스캔된 데이터의 TB당 5달러
- 서버리스기 떄문에 DB를 프로비저닝 할 필요가 없다.
- Athena는 Amazon QuickSight 도구와 함께 사용하는 것이 일반적이다.
Amazon QuickSight를 통해 보고서와 대시보드를 생성한다.
QuickSight는 S3 버킷에 연결된 Athena 다음에 배치된다.
- 사용 사례
- 임시 쿼리 수행
- 비즈니스 인텔리전스 분석 및 보고
- AWS 서비스에서 발생하는 모든 로그를 쿼리하고 분석
ex) VPC 흐름 로그, 로드 밸런서 로그, CloudTrail 추적
- Athena 성능 향상
- 비용을 지불할 때 스캔된 데이터의 TB당 가격을 지불하므로 데이터를 적게 스캔할 유형의 데이터를 사용하는 것
열 기반 데이터 유형을 사용하면 필요한 열만 스캔하므로 비용을 절감할 수 있다.
Athena에 권장하는 형식: Apache Parquet, ORC
파일을 Apache Parquet나 ORC형식으로 가져오려면 Glue같은 서비스를 사용해야함.
- 비용을 지불할 때 스캔된 데이터의 TB당 가격을 지불하므로 데이터를 적게 스캔할 유형의 데이터를 사용하는 것
- 더 적은 데이터를 스캔해야 하므로 데이터를 압축해 더 적게 검색해야 한다.
bzip2, gzip, lz4, snappy, zlip, zstd등
- 더 적은 데이터를 스캔해야 하므로 데이터를 압축해 더 적게 검색해야 한다.
- 특정 열을 항상 쿼리한다면 데이터 세트를 분할한다.
S3 버킷에 있는 전체 경로를 슬래시로 분할

각 슬래시에 다른 열 이름을 붙여 열별로 특정 값을 저장하는 것
즉, S3에 있는 데이터를 정리하고 분할하는 것
데이터를 쿼리할 때 S3의 어떤 폴더(경로)로 데이터를 스캔할지 정확히 알 수 있다.
- 특정 열을 항상 쿼리한다면 데이터 세트를 분할한다.
- 큰 파일을 사용해 오버헤드를 최소화
S3에 작은 파일이 너무 많으면 성능이 떨어진다.
파일이 클수록 스캔과 검색이 쉬워 128MB 이상의 파일을 사용해야 한다.
- 큰 파일을 사용해 오버헤드를 최소화
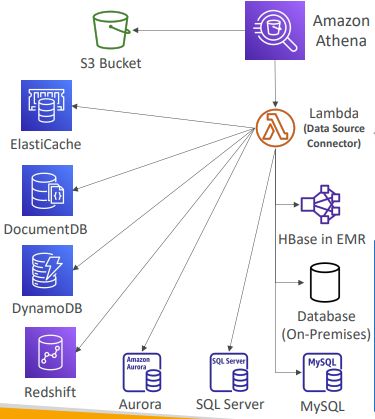
- Athena 연합 쿼리
- S3말고 어떤 곳의 데이터도 쿼리할 수 있다.
- 관계형 데이터베이스
- 비관계형 데이터베이스
- 객체
- 사용자 지정 데이터 원본 - AWS나 온프레미스에서의 사용
데이터 원본 커넥터를 사용해 Athena 사용
데이터 원본 커넥터는 Lambda 함수로 다른 서비스에서 연합 쿼리를 실행
- CloudWatch Logs
- DynamoDB
- RDS
등에서 실행하고 매우 강력하다. - Athena 연합 쿼리는 S3 뿐 아니라 모든 온프레미스 데이터베이스를 쿼리할 수 있고, 쿼리를 조인하거나 경쟁할 수 있다.
- 쿼리 결과는 사후 분석을 위해 S3 버킷에 저장할 수 있다.
- S3말고 어떤 곳의 데이터도 쿼리할 수 있다.
- athena와 s3 엑세스로그 쿼리는 인터넷에 검색하면 나온다.
Amazon Redshift
Redshift: DB인 동시에 분석 엔진
+ 클라이언트 측 및 서버 측 암호화를 지원
+ 활성 상태가 아닌 애플리케이션 분석 워크로드 구축
- Redshitf는 PostgreSQL기술에 기반해 있지만 온라인 거래 처리에는 사용되지 않는다.
- OLAP 유형의 DB인데, 이는 온라인 분석 처리에 사용된다.
그리고 분석과 데이터 웨어하우징에 사용된다.
다른 모든 데이터 웨어하우스보다 10배 좋은 성능을 가지고 있다.
PB의 데이터로 확대 가능 - Redshift 성능 개선에도 유용
데이터를 열(Columnar) 기반 스토리지로 사용하기 때문
따라서 행 기반과 달리 병렬 쿼리 엔진이 있다. - Redshift는 Redshift 클러스터에 공급한 인스턴스만큼 비용을 지불
- SQL을 사용해 쿼리를 수행 가능.
- Amazon QuickSights나 Tableau 같은 비즈니스 인텔리전스 툴은 모두 Redshift와 통합된다.
- Redshift vs Athena
- Redshift는 S3 로부터 Redshift로 모든 데이터를 로드해야 한다.
Redshift로 로드되었다면 Redshift는 쿼리가 더 빠르다.
또한 Redshift는 훨씬 빠른 join과 통합을 할 수 있다.
Redshift는 인덱스가 있기 때문에 고성능 데이터 웨어하우스를 위해 인덱스를 빌드한다. - S3의 ad hoc(즉석) 쿼리라면 Athena 사용이 더 좋고, 집중적인 데이터 웨어하우징의 경우는 복잡한 쿼리가 많고 조인과 집합 등이 있다면Redshift가 더 좋다.
- Redshift는 S3 로부터 Redshift로 모든 데이터를 로드해야 한다.
- Redshift Cluster
노드 크기를 사전에 공급해야 한다.
비용을 줄이고 싶으면 예약 인스턴스를 사용할 수 있다.- Redshift Cluster 구성
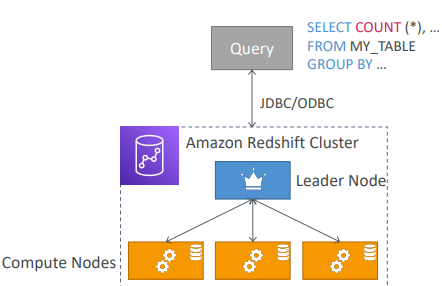
- 리더 노드
쿼리 계획과 결과 집합을 시키는 역할(SQL 형식의 쿼리 제출) - 계산 노드
쿼리를 수행하고 결과를 리더에 전송
- 리더 노드
- Redshift Cluster 구성
Redshift - 스냅샷 & DR
Redshift는 대부분의 클러스터에 대해 단일 AZ이지만 요즘은 특정 클러스터 유형에 대해 다중 AZ모드가 있다.
-> 다중AZ의 경우 피해 복구가 잘 됨
-> 단일AZ의 경우 피해 복구를 위해 스냅샷을 사용해야 함.
- 스냅샵
- 클러스터를 위한 point-in-time 백업이며 S3에 내부적으로 저장되고 증가한다.
- 변화된것만 저장되어 많은 저장 공간이 절약 될것이다.
- 새로운 Redshift 클러스터로 스냅샷을 복구할 수 있다.- 스냅샷의 모드(2가지)
- 수동적 스냅샷
수동적 스냅샷은 사용자가 삭제할 때까지 저장되어 있는다.
- 수동적 스냅샷
- 자동적 스냅샷
매 8시간마다 스냅샷이 찍힘 or
5GB마다 찍히도록 할 수 있음.
자동화된 스냅샷을 위한 저장 기간을 설정 가능
- 자동적 스냅샷
- Redshift의 스냅샷은 자동적으로 복사하도록 구성할 수 있다.
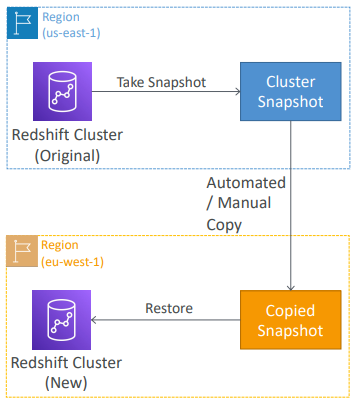
자동/수동의 여부와 상관없이, 해당 클러스터에서 다른 AWS 리전으로 복사 가능해 또 다른 피해 복구 전략을 제공한다.
- 스냅샷의 모드(2가지)
Redshift 데이터 수집 방법(3가지)
- Amazon kinesis Data Firehose
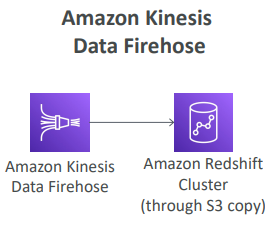
- 다양한 소스에서 데이터를 받는 Firehose가 있고, 이 데이터를 Redshift로 전송한다.
- 그러기 위해 먼저 해당 데이터를 S3 버킷에 작성한 이후 kinesis Data Firehose가 자동적으로 S3 복사 명령을 내려 해당 데이터를 Redshift로 로드할 것이다.
- Amazon kinesis Data Firehose
- S3를 사용한 복사 명령
- 수동으로 사용할 수도 있다.
- 데이터를 S3로 로드한 후 Redshift에서 바로 복사 명령을 내리면 IAM역할을 사용해 S3 버킷에서 Redshift 클러스터로 데이터를 복사한다.
* 복사하는 두 가지 방법
- 1. S3 버킷은 인터넷을 통한 공용이기 때문에 인터넷으로 전달.
- 2. 모든 네트워크가 프라이빗을 유지하고 싶으면 향상된 VPC 라우팅을 허용해 모든 데이터가 VPC를 통해 흐르도록 할 수 있다.
- S3를 사용한 복사 명령
- JDBC 드라이버를 사용해 Redshift 클러스터로 데이터 유입
- 애플리케이션이 Redshift 클러스터에 데이터를 작성해야 하는 EC2 인스턴스가 있는 경우 사용.
- 이 경우는 Redshift에 큰 묶음의 데이터를 작성하는 것이 좋다.
왜냐하면 이 DB 유형에는 한번에 한 행씩 작성하는 것은 매우 비효율적이다.
- JDBC 드라이버를 사용해 Redshift 클러스터로 데이터 유입
Redshift Spectrum
- S3에 데이터가 있고 Redshift를 이용해 분석하고 싶지만 Redshift로 로드하고 싶지 않을 경우 사용.
- 또는 더 많은 처리 능력을 사용하고 싶을 때 사용한다.
- Redshift Spectrum을 이용하면 쿼리를 시작할 수 있는 Redshift 클러스터가 이미 존재해야 한다.
- 쿼리를 시작하면 S3의 데이터로 쿼리를 수행할 수천개의 Redshift Spectrum 노드로 제출된다.
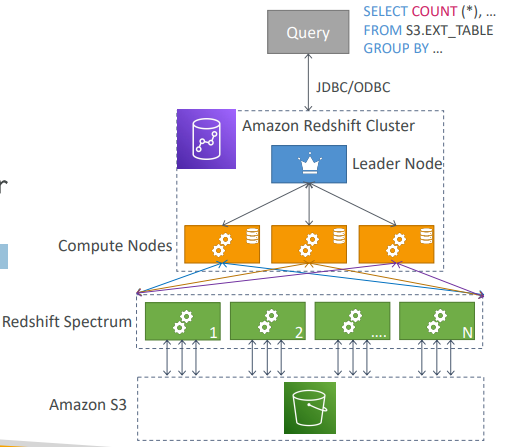
- 한개의 리더 노드와 여러개의 컴퓨팅 노드가 있는 Redshift 클러스터가 있다.
- 분석하고자 하는 데이터는 S3에 저장되넝 있다.
- 이 경우 Redshift 클러스터로 쿼리를 수행시킬 것이다.
쿼리하고자 하는 표가 S3안에 있다.
- 이 경우 Redshift Spectrum이 자동적으로 시작할 것이다.
쿼리가 수천개의 Redshift Spectrum 노드로 제출될 것이다.
- 이 노드들은 S3에서 데이터를 읽고 병합을 수행한다.
- 완료 후에 결과를 다시 Redshift 클러스터로 전송하고, 쿼리를 시작한 곳으로 돌아온다. - Redshift Spectrum 기능은 처음 클러스터에 공급했던 것보다 Redshift의 처리 기능을 더 많이 사용할 수 있게 해준다.
- 그리고 처음에 S3로부터 Redshift로 데이터를 로드하지 않고 사용 할 수 있게 해준다.
