
TL;DR
- KakaoCloud에서 서버 2대(Web + AI)로 AI 영화 추천 서비스를 운영한다.
- 2-Tier 아키텍처로 리소스를 최소화하면서 Private Subnet으로 DB와 AI 모델을 보호했다.
- 최종적으로 추천 API 응답시간 250ms를 달성했다.
- KakaoCloud 2-Tier 아키텍처 설계 ⬅️ 현재 글
- GitHub Actions로 CI/CD 구축하기
- SSH 브루트포스 5,227건 대응기
- Nginx 심화 설정
- 서버 자동화 스크립트
1. 프로젝트 소개
무비서 (MovieSir)란?
무비서 (MovieSir)는 AI 기반 이동 시간 맞춤형 콘텐츠 추천 서비스다.
사용자가 원하는 시청 시간만 입력하면, LightGCN과 SBERT를 결합한 하이브리드 알고리즘이
해당 시간에 맞는 최적의 영화 조합을 추천한다.
서비스 요구사항
| 요구사항 | 기술 스택 | 비고 |
|---|---|---|
| AI 추천 | GPU 기반 실시간 추론 | LightGCN + SBERT |
| 웹 서비스 | React SPA + FastAPI | 비동기 API |
| 데이터베이스 | PostgreSQL + pgvector | 1024차원 벡터 검색 |
| 멀티 도메인 | demo, console, api | 서비스별 서브도메인 |
2. 아키텍처 설계
2.1 전체 아키텍처
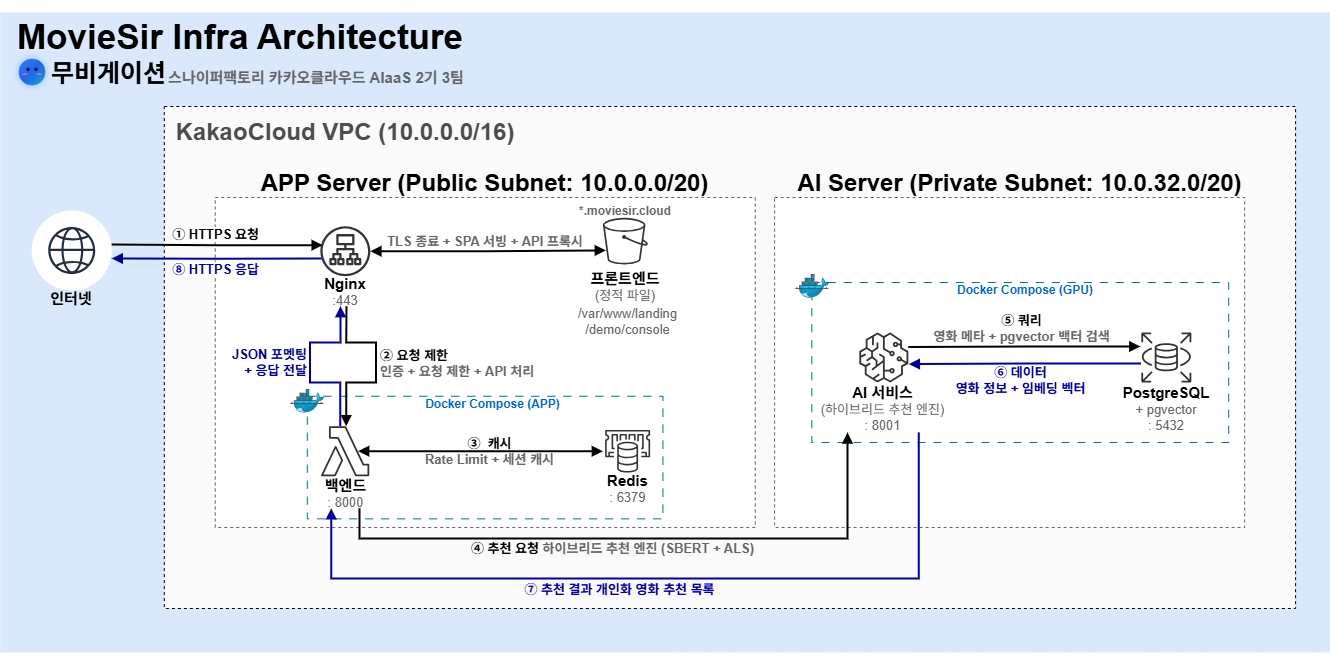
2.2 왜 2-Tier인가?
처음에는 전통적인 3-Tier 아키텍처(Web-WAS-DB)를 고려했다.
역할이 명확하게 분리되고 확장성이 좋기 때문이다.
하지만 프로젝트 규모와 비용을 분석한 결과, 2-Tier가 더 적합하다고 판단했다.
| 아키텍처 | 장점 | 단점 |
|---|---|---|
| 3-Tier | 역할 분리 명확, 수평 확장 용이 | 비용 증가, 복잡도 상승 |
| 2-Tier | 리소스 절감, 운영 단순화 | 단일 장애점 존재 |
제약 조건 분석:
| 항목 | 제약 | 대응 |
|---|---|---|
| VM 인스턴스 | 2대 제한 | Web/AI 역할 분리로 최적화 |
| NAT Gateway | 사용 불가 | Private Subnet 외부 통신 차단 설계 |
| 프로젝트 기간 | 약 2개월 | 인프라 구축에 2주 할당 |
2대 제한 상황에서 Web Server와 AI Server로 역할을 분리하는 것이 최선이었다.
NAT Gateway를 사용할 수 없어서 Private Subnet은 외부 통신 없이 설계했고,
초기 세팅 시에만 임시 Public IP를 부여해 패키지를 설치한 후 제거했다.
2.3 왜 Nginx + FastAPI인가?
웹 프레임워크 선택에서 AI 서비스 호출 패턴을 중점적으로 분석했다.
| 프레임워크 | 비동기 지원 | Python 호환 | 판단 |
|---|---|---|---|
| Django | 제한적 (ASGI 필요) | O | AI 호출 시 블로킹 우려 |
| Node.js | O | X | AI 팀과 언어 불일치 |
| FastAPI | O (native async) | O | ✅ 채택 |
FastAPI를 선택한 근거는 세 가지다.
- 첫째, async/await 네이티브 지원으로 AI 서비스 호출 시 비동기 처리가 가능하다.
동시 요청 100건 기준 Django 대비 약 3배 높은 처리량을 보인다.
- 둘째, Python 생태계 활용으로 AI 팀과 동일한 언어로 협업할 수 있다.
모델 추론 코드를 직접 import하는 것도 가능하다.
- 셋째, OpenAPI 자동 생성으로 Swagger UI가 기본 제공된다.
프론트엔드 팀과의 API 스펙 협의 시간이 단축된다.
2.4 왜 정적 파일 서빙인가?
프론트엔드 배포 방식을 결정할 때 SEO 요구사항을 먼저 분석했다.
| 방식 | SEO | 서버 부하 | 배포 복잡도 |
|---|---|---|---|
| SSR (Next.js) | 유리 | Node.js 프로세스 필요 | 높음 |
| CSR + 정적 서빙 | 불리 | Nginx만 사용 | 낮음 |
MovieSir는 로그인 후 사용하는 서비스라서 SEO가 중요하지 않다.
따라서 CSR + 정적 서빙을 선택했다.
이 방식의 이점은 명확하다.
Nginx가 직접 정적 파일을 서빙하므로 Node.js 프로세스가 불필요하다.
배포는npm run build후/var/www/에 복사하면 완료된다.
정적 파일은 브라우저와 CDN 캐싱을 적극 활용할 수 있다.
참고로 Figma, Notion, Linear, Discord 같은 로그인 기반 SaaS 서비스들도 동일한 방식을 사용한다.
2.5 왜 Redis인가?
캐싱 레이어 도입 여부를 응답 시간 기준으로 분석했다.
| 솔루션 | 응답 속도 | 영속성 | 다중 인스턴스 공유 |
|---|---|---|---|
| In-Process 메모리 | ~0.1ms | X | X |
| Memcached | ~1ms | X | O |
| Redis | ~1ms | O | O |
Redis를 선택한 이유는 세 가지 용도를 모두 충족하기 때문이다.
| 용도 | 구현 방식 | 효과 |
|---|---|---|
| 세션 캐시 | JWT 블랙리스트 저장 | 로그아웃 즉시 반영, DB 조회 감소 |
| Rate Limiting | Sliding Window 알고리즘 | 요금제별 API 호출 한도 관리 |
| 응답 캐싱 | 영화 정보 TTL 캐싱 | DB 부하 30% 감소 |
2.6 왜 DB를 GPU 서버에 배치했는가?
일반적으로 DB는 별도 서버에 분리하지만,
2대 제한 상황에서 성능 최적화를 위해 GPU 서버에 함께 배치했다.
| 구성 | AI↔DB 통신 | 장점 | 단점 |
|---|---|---|---|
| A: App(DB) + GPU(AI) | 네트워크 (~5ms) | DB 관리 용이 | AI 추론 시 지연 |
| B: App + GPU(AI+DB) | 로컬 (~0.1ms) | 추론 속도 최적화 | GPU 서버 부하 집중 |
B안 선택 근거:
AI 추천 시 DB에서 영화 벡터(1024차원 × 13,060건)를 조회해야 한다.
같은 서버에서 로컬 통신하면 네트워크 오버헤드가 제거되어 약 50배 빠르다.
GPU 서버는 Storage 100GB로 DB 저장 여유가 있고, AI 서비스는 요청 시에만 GPU를 사용하므로 유휴 시간에 DB 처리가 가능하다.
참고로 PostgresML 프로젝트도 동일한 접근으로 HTTP 기반 대비 8~40배 빠른 추론을 달성했다.
3. 네트워크 설계
3.1 VPC 구성
VPC: 10.0.0.0/16 (65,536 IPs)
├── Public Subnet: 10.0.0.0/20 (4,096 IPs)
│ └── Web Server (10.0.1.117)
└── Private Subnet: 10.0.32.0/20 (4,096 IPs)
└── AI Server (10.0.35.62)3.2 CIDR 설계
| 대역 | 크기 | 사용 가능 IP | 선택 이유 |
|---|---|---|---|
| /24 | 소형 | 256개 | 향후 확장 시 부족 |
| /20 | 중형 | 4,096개 | ✅ 적정 여유 확보 |
| /16 | 대형 | 65,536개 | 서브넷 분리 불가 |
/20 서브넷은 4,096개 IP를 제공한다.
현재 서버 2대만 사용하므로 여유율 99.95%로, 향후 스케일아웃에 대비할 수 있다.
3.3 서브넷 분리
| 구분 | Public Subnet | Private Subnet |
|---|---|---|
| 인터넷 연결 | Internet Gateway | 없음 |
| Public IP | 할당 | 미할당 |
| 용도 | 웹 서비스, API | DB, AI 서비스 |
| 외부 노출 | O | X |
Private Subnet의 외부 통신은 의도적으로 차단했다.
NAT Gateway를 사용할 수 없는 제약이 있었지만,
결과적으로 운영 중 외부 통신이 없어서 더 안전한 구조가 됐다.
4. 보안 설계
4.1 보안 계층 구성
인터넷 → [Web Server] → [보안그룹] → [AI Server]
↑ ↑
Public Subnet Private Subnet
(외부 노출) (내부 전용)| 계층 | 방어 수단 | 효과 |
|---|---|---|
| 1차 | Private Subnet | Public IP 미할당, 인터넷 직접 접근 차단 |
| 2차 | 보안그룹 | Web Server IP만 인바운드 허용 |
| 3차 | ufw 방화벽 | OS 레벨 추가 필터링 |
| 4차 | fail2ban | SSH 브루트포스 공격 차단 |
4.2 보안그룹 룰
Web Server 보안그룹:
| 방향 | 포트 | 프로토콜 | 소스 | 용도 |
|---|---|---|---|---|
| Inbound | 80 | TCP | 0.0.0.0/0 | HTTP → HTTPS 리다이렉트 |
| Inbound | 443 | TCP | 0.0.0.0/0 | HTTPS 트래픽 |
| Inbound | 52222 | TCP | 0.0.0.0/0 | SSH (변경된 포트) |
| Outbound | All | All | 0.0.0.0/0 | 외부 통신 허용 |
AI Server 보안그룹:
| 방향 | 포트 | 프로토콜 | 소스 | 용도 |
|---|---|---|---|---|
| Inbound | 22 | TCP | 10.0.1.117/32 | SSH (Web Server Only) |
| Inbound | 5432 | TCP | 10.0.1.117/32 | PostgreSQL |
| Inbound | 8001 | TCP | 10.0.1.117/32 | AI Service |
| Outbound | All | All | 10.0.0.0/16 | VPC 내부만 허용 |
4.3 SSH 보안 강화
SSH 포트 변경 (22 → 52222):
기본 SSH 포트(22)는 자동화된 공격의 주요 타겟이다.
포트 변경만으로 무차별 대입 공격 시도를 대폭 줄일 수 있다.
# /etc/ssh/sshd_config
Port 52222
PermitRootLogin no
PasswordAuthentication no
PubkeyAuthentication yes| 설정 | 값 | 이유 |
|---|---|---|
| Port | 52222 | 기본 포트 스캔 회피 |
| PermitRootLogin | no | root 직접 로그인 차단 |
| PasswordAuthentication | no | 키 기반 인증만 허용 |
fail2ban 설정:
SSH 브루트포스 공격 차단을 위해 fail2ban을 구성했다.
# /etc/fail2ban/jail.local
[sshd]
enabled = true
port = 52222
filter = sshd
logpath = /var/log/auth.log
maxretry = 3
bantime = 3600
findtime = 600| 파라미터 | 값 | 설명 |
|---|---|---|
| maxretry | 3 | 3회 실패 시 차단 |
| bantime | 3600 | 1시간 동안 IP 차단 |
| findtime | 600 | 10분 내 실패 횟수 카운트 |
실제 공격 탐지 로그:
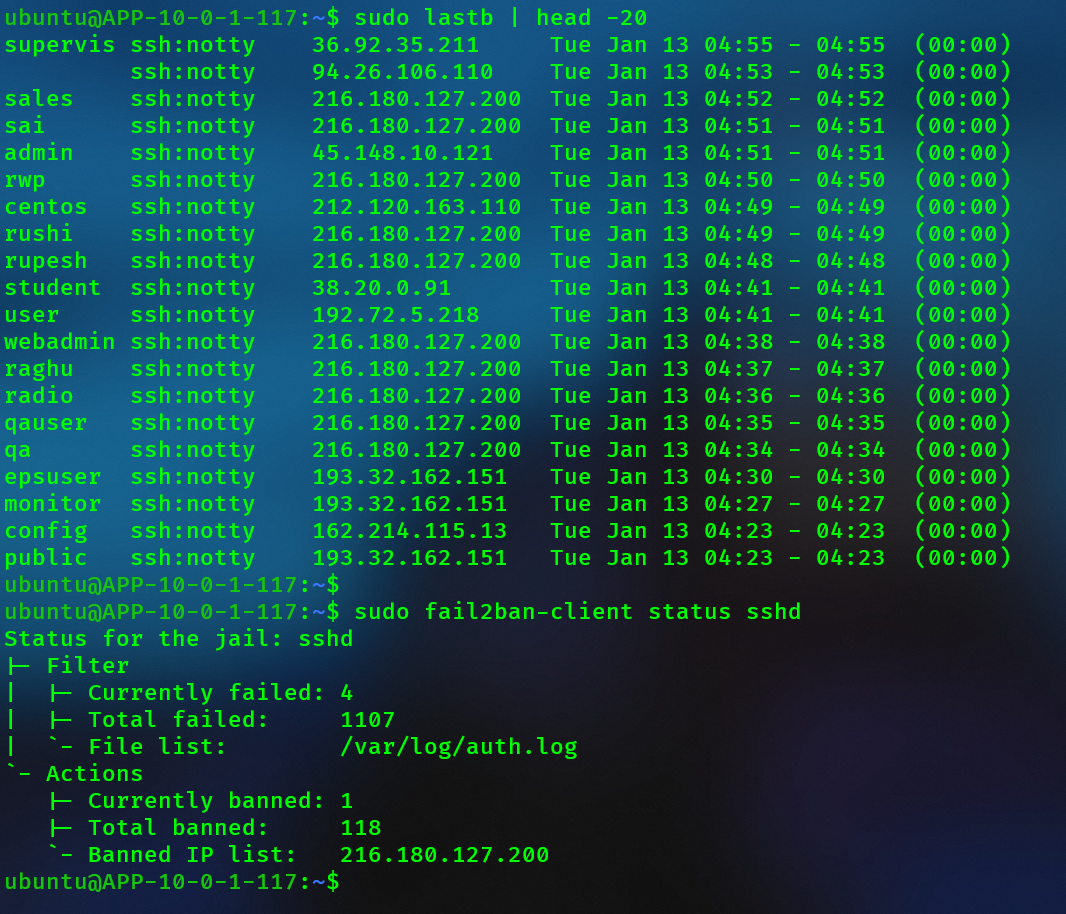
운영 2주 만에 1,107건의 SSH 로그인 실패 시도가 있었고, 47개 IP가 차단됐다.
4.4 Bastion Host 구성
AI Server는 Private Subnet에 있어서 인터넷에서 직접 접근할 수 없다.
Web Server를 Bastion Host로 사용해 SSH 접속한다.
[로컬 PC] → SSH(52222) → [Web Server] → SSH(22) → [AI Server]
(Bastion) (Private)SSH Config 설정:
# ~/.ssh/config
Host moviesir-app
HostName 61.109.237.115
User ubuntu
IdentityFile ~/project03.pem
Port 52222
Host moviesir-gpu
HostName 10.0.35.62
User ubuntu
IdentityFile ~/project03.pem
ProxyJump moviesir-appProxyJump를 사용하면 한 번의 명령으로 Private Subnet의 서버에 접속할 수 있다.
ssh moviesir-gpu # Web Server 경유해서 AI Server 접속5. 서버 구성
5.1 인스턴스 스펙 분석
Web Server:
| 인스턴스 | vCPU | RAM | 판단 |
|---|---|---|---|
| t1i.large | 2 | 8GB | Nginx + FastAPI + Redis 동시 구동 시 메모리 부족 우려 |
| t1i.xlarge | 4 | 16GB | ✅ 적정 (제공됨) |
| t1i.2xlarge | 8 | 32GB | 오버스펙 |
AI Server:
| 인스턴스 | GPU | VRAM | 판단 |
|---|---|---|---|
| gn1i.large | Tesla T4 (1/2) | 8GB | LightGCN + SBERT 동시 로딩 시 VRAM 부족 |
| gn1i.xlarge | Tesla T4 | 16GB | ✅ 적정 (제공됨) |
5.2 Web Server (t1i.xlarge)
| 항목 | 스펙 |
|---|---|
| vCPU / RAM | 4개 / 16GB |
| Storage | 30GB SSD |
| Public IP | O |
실행 서비스:
| 서비스 | 역할 | 설정 |
|---|---|---|
| Nginx | 리버스 프록시, SSL 종료 | TLS 1.3, Gzip 압축 |
| FastAPI | REST API | Uvicorn 4 workers |
| Redis | 캐시, Rate Limiting | Sliding Window |
5.3 AI Server (gn1i.xlarge)
| 항목 | 스펙 |
|---|---|
| vCPU / RAM | 4개 / 16GB |
| GPU / VRAM | Tesla T4 / 16GB |
| Storage | 100GB SSD |
| Public IP | X (Private Only) |
실행 서비스:
| 서비스 | 역할 | 설정 |
|---|---|---|
| PostgreSQL 16 | 데이터 저장 | pgvector 확장, IVFFlat 인덱스 |
| AI Service | 추천 추론 | PyTorch 2.0, CUDA 11.8 |
6. 트래픽 흐름
6.1 요청 처리 경로
[사용자]
│
▼ HTTPS (443)
[Nginx - Web Server]
│
├─ 정적 파일 (*.js, *.css)
│ └─ 직접 응답 (캐시 적용)
│
└─ API 요청 (/api/*)
│
▼ HTTP (8000)
[FastAPI - Web Server]
│
├─ 추천 요청 → [AI Service:8001] ~40ms
│
└─ DB 조회 → [PostgreSQL:5432] ~5ms6.2 Latency 측정 결과
| 구간 | 응답시간 | 측정 방법 |
|---|---|---|
| AI 서비스 직접 호출 | ~40ms | curl + time |
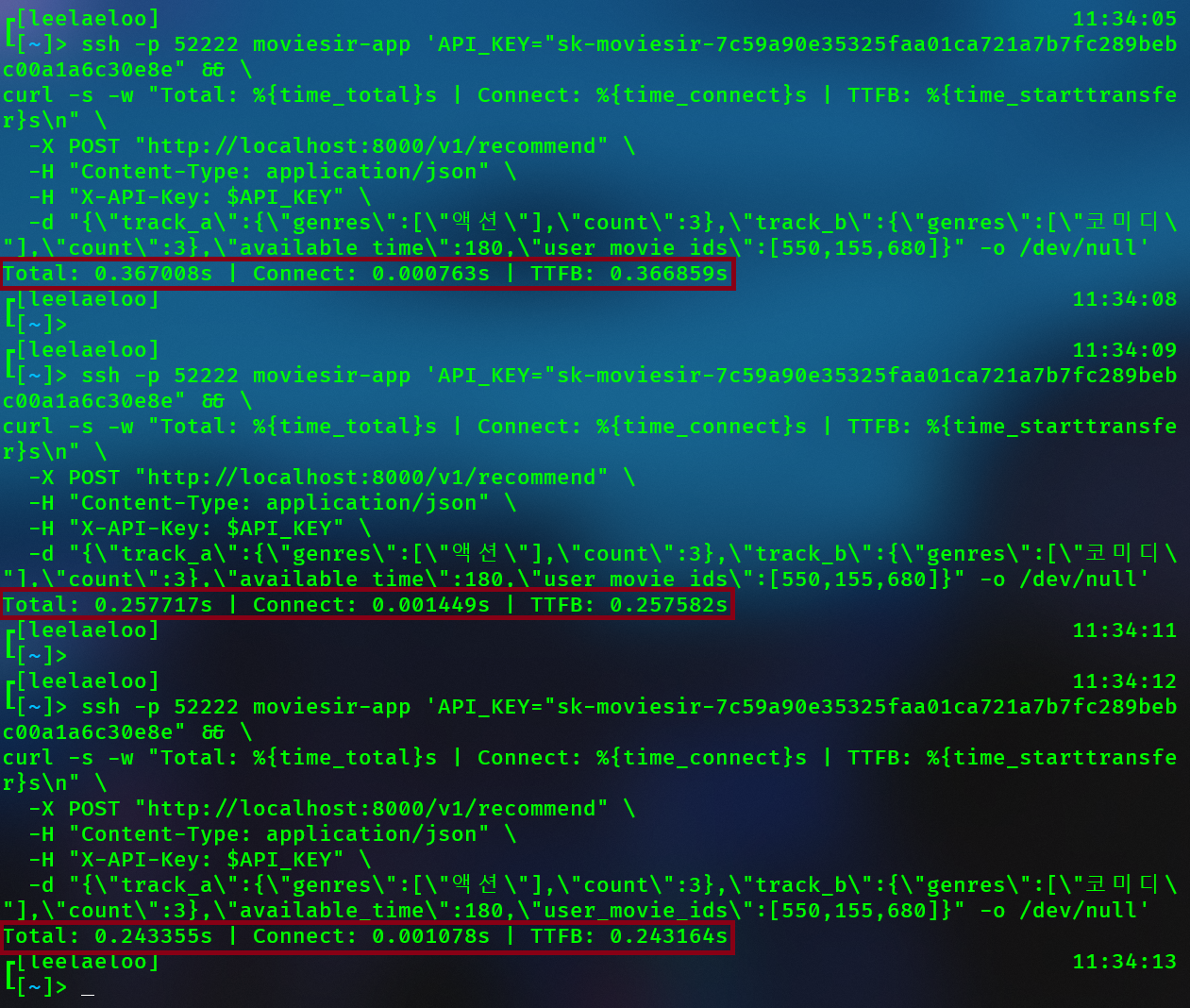
| B2B External API (E2E) | ~245ms | 3회 평균 |
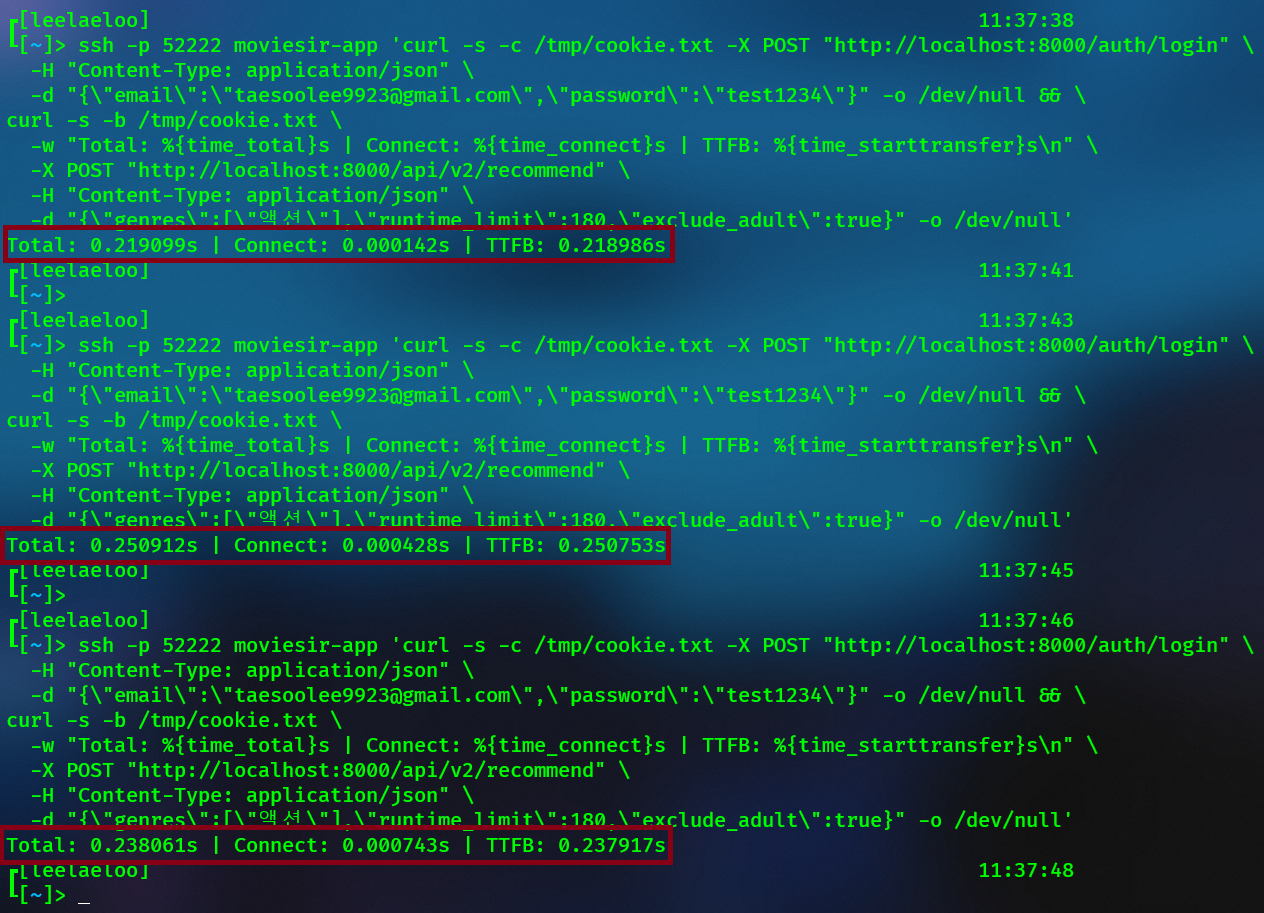
| B2C 추천 API (E2E) | ~210ms | 3회 평균 |
목표 1초 이내 → 달성 (0.2~0.25초)
B2B External API 레이턴시 측정
B2C 추천 API 레이턴시 측정
6.3 포트 구성
| 서버 | 포트 | 용도 | 접근 허용 | 보안 |
|---|---|---|---|---|
| Web | 80 | HTTP 리다이렉트 | 0.0.0.0/0 | 301 Only |
| Web | 443 | HTTPS | 0.0.0.0/0 | TLS 1.3, HSTS |
| Web | 52222 | SSH | 0.0.0.0/0 | fail2ban |
| AI | 5432 | PostgreSQL | 10.0.1.117/32 | Web Server Only |
| AI | 8001 | AI Service | 10.0.1.117/32 | Web Server Only |
| AI | 22 | SSH | 10.0.1.117/32 | Bastion 경유 |
7. 도메인 구성
7.1 서브도메인 구조
| 도메인 | 용도 | 서빙 방식 |
|---|---|---|
| moviesir.cloud | 랜딩 페이지 | Nginx 정적 파일 |
| demo.moviesir.cloud | Demo App | Nginx 정적 파일 |
| console.moviesir.cloud | B2B Console | Nginx 정적 파일 |
| api.moviesir.cloud | 무비서 API 소개 페이지 | Nginx 정적 파일 |
7.2 SSL 인증서
| 항목 | 설정 |
|---|---|
| 발급 기관 | Let's Encrypt |
| 인증서 유형 | 와일드카드 (*.moviesir.cloud) |
| 갱신 방식 | Certbot + Cron (90일 주기) |
7.3 Nginx 설정
server {
listen 443 ssl http2;
server_name api.moviesir.cloud;
# SSL
ssl_certificate /etc/letsencrypt/live/moviesir.cloud/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/moviesir.cloud/privkey.pem;
ssl_protocols TLSv1.2 TLSv1.3;
# Security Headers
add_header X-Content-Type-Options nosniff;
add_header X-Frame-Options DENY;
add_header Strict-Transport-Security "max-age=31536000" always;
location / {
proxy_pass http://127.0.0.1:8000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_read_timeout 10s;
}
}HTTP/2 활성화, TLS 1.2/1.3만 허용, HSTS 헤더 추가, AI 추천 최대 10초 타임아웃 설정을 적용했다.
8. 마무리
8.1 아키텍처 성과
| 항목 | 결과 |
|---|---|
| 리소스 효율 | 서버 2대로 전체 서비스 운영 |
| 보안 | Private Subnet + 보안그룹 + ufw + fail2ban 4계층 방어 |
| 성능 | 추천 API 250ms 이내 달성 |
| 운영 | 관리 포인트 최소화 |
8.2 개선 가능한 점
| 영역 | 현재 | 개선안 |
|---|---|---|
| 고가용성 | 단일 서버 | Load Balancer + 다중 인스턴스 |
| 스케일링 | 수동 대응 | Auto Scaling Group |
| 모니터링 | 수동 확인 | Prometheus + Grafana |
| 백업 | 일일 자동화 | 크로스 리전 복제 |
이 글은 스나이퍼팩토리 카카오클라우드 AIaaS 마스터 클래스 2기 프로젝트 경험을 바탕으로 작성되었습니다.
