추천 배치 설계와 성능 테스트 (feat. JPA IDENTITY 한계 극복)
아이북조아 프로젝트에서 추천 도서를 추출하는 배치 처리를 담당하였다.
먼저 추천하는 도서의 조건은 다음과 같다:
- 추천 도서는 아이(Child)의 성향(Trait)과 도서 MBTI 를 비교하여 각 요소 점수가 (-5 ~ +5) 에 해당하는 도서를 말한다.
- 사용자별 추천 도서는 20권 이하이며 중복 도서는 없다.배치 과정 알아보기
배치 처리는 아래와 같이 진행된다:
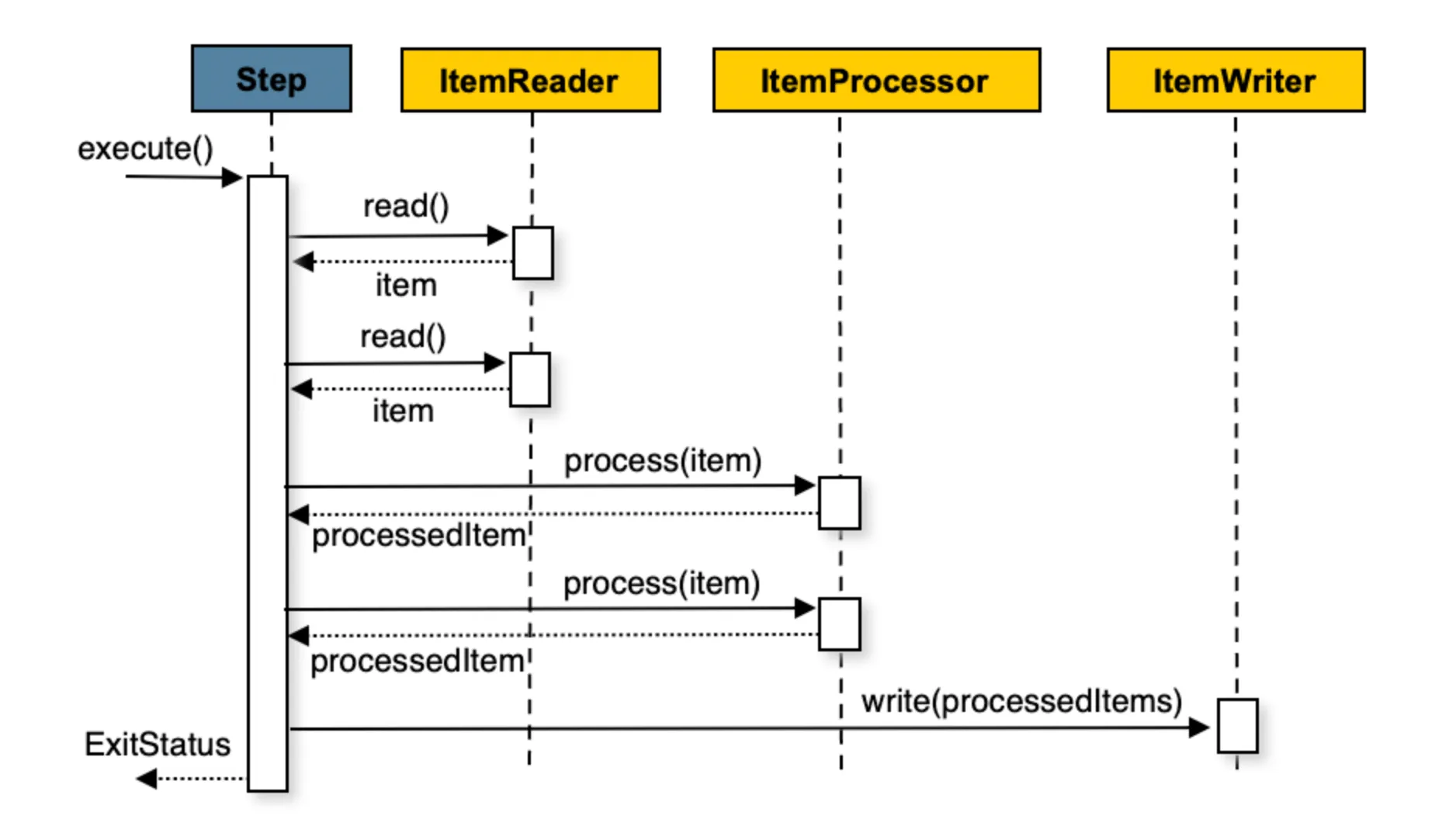
Reader: 청크(chunk) 크기 만큼 데이터를 가져온다.Processor: 데이터를 가공/필터링한다.Writer: 청크 단위 만큼 한번에 작업을 수행한다.
배치와 관련된 더 자세한 내용은 노션에 자세히 작성해 놓았다.
배치 도메인 용어와 구현방식에 대해 궁금하다면 링크된 페이지를 참고하면 도움이 될 것이다. 😀
기존 배치 처리
JPA Paging vs. JDBC Paging
위 흐름에 맞춰 JDBC 페이징 방식으로 구현하였다.
JPA 페이징이 아닌 JDBC 페이징을 선택한 이유는 배치 처리의 효율성과 안정성 때문이다. JPA는 내부적으로 영속성 컨텍스트를 유지하면서 객체를 관리하기 때문에 대량의 데이터를 배치 처리할 경우 메모리 사용량이 증가하여 OutOfMemoryError 와 같은 문제가 발생할 수 있다. 특히 EntityManager 에 의해 관리되는 객체들이 많아지면 GC에 부담이 가중되어 배치 수행 속도가 떨어질 수 있다.
반면, JDBC 기반 페이징은 단순히 필요한 데이터만 ResultSet 으로 받아오기 때문에 불필요한 객체 생성을 최소화할 수 있다. 특히 영속성 컨텍스트를 사용하지 않음으로써 메모리 부담을 JPA보다 현저히 낮다. 이는 곧 대량의 데이터를 처리할 때 안정적인 성능을 보장할 수 있다.
더불어 배치 환경에서는 쿼리 튜닝과 병렬 처리 전략도 중요한데, JDBC 는 인덱스를 활용한 최적화와 조건 분기 처리, 데이터 파티셔닝 등 특정 조건에 따라 데이터를 처리할 수 있고, 리소스를 효율적으로 할당할 수 있다.
성능 비교
실제로 JPA 기반 페이징과 JDBC 기반 페이징을 비교하기 위해 간단한 배치 처리를 진행해 보자.
요구사항은 재고량이 0인 책은 품절로 처리 이며, 테스트 데이터는 book 1,000개를 갖는다.
(※ 해당 코드는 깃허브에서 확인할 수 있다. 😀)
- JPA Paging

- JDBC Paging

위 내용을 표로 정리하면 다음과 같다:
| 항목 | JDBC 페이징 | JPA 페이징 |
|---|---|---|
| 데이터 전송량 (received ↔️ sent, KB/sec) | 많음 (0.81 ↔️ 0.88) | 적음 (0.25 ↔️ 0.27) |
| Throughput | 높음 (4.3/sec) | 느림 (1.3/sec) |
| 처리 시간 (Average) | 빠름 (233ms) | 느림 (749ms) |
평균 처리 시간과 처리량 비교해 보면, JDBC 는 JPA 보다 약 3배 이상 빠른 속도와 높은 처리량을 보인다.
✅ 배치는 일반적으로 소량의 데이터보다 대량의 데이터를 다루는 작업이 많기 때문에, JPA 페이징보다 JDBC 페이징을 사용하는 것이 더 적합함을 알 수 있다.
기존 배치 구현
요구사항에 맞춰서 배치 처리의 흐름을 다음과 같이 계획했다:
1. 청크 크기만큼 자녀ID 를 가져온다.
2. 자녀의 가장 최근의 성향을 추출하여 4가지 요소의 점수를 추출한다.
3. 요소별 점수의 (-5 ~ +5)에 점수를 갖는 도서를 리스트에 담는다.
4. 리스트에 담은 도서(= 추천 도서)를 일괄 저장한다.
Data & Chunk Size
- Child 5,000
- Book 100,000
- Chunk Size 100
Reader: 자녀ID 가져오기
@Bean
@StepScope
public JdbcPagingItemReader<Long> recommendBookItemReader() {
return new JdbcPagingItemReaderBuilder<Long>()
.name("recommendBookReader")
.dataSource(dataSource)
.selectClause("SELECT child_id")
.fromClause("FROM child")
.sortKeys(Collections.singletonMap("child_id", Order.ASCENDING))
.rowMapper((rs, rowNum) -> rs.getLong("child_id"))
.build();
}Processor: 자녀 MBTI로 추천 도서 범위에 해당하는 도서 추출
@Bean
@StepScope
public ItemProcessor<Long, List<RecBook>> recommendBookItemProcessor() {
return childId -> {
Optional<MbtiHistory> mbtiHistory = mbtiHistoryRepository.findTopByChild_ChildIdOrderByCreatedAtDesc(childId);
List<ChildTraits> childTraits = childTraitsRepository.findLatestTraitsByHistoryId(mbtiHistory.get().getHistoryId());
if (childTraits.isEmpty()) {
throw NotFoundException.entityNotFound("아이성향");
}
int[] childTraitScore = new int[4];
for (int i = 0; i < 4; i++) {
childTraitScore[i] = childTraits.get(i).getTraitScore();
}
Set<Book> recBooks = new HashSet<>();
for (int i = 0; i < 4; i++) {
int minScore = Math.max(0, childTraitScore[i] - 5);
int maxScore = Math.min(100, childTraitScore[i] + 5);
List<Book> books = bookTraitsRepository.findBooksByTraitScoreBetween(minScore, maxScore, PageRequest.of(0, 15));
recBooks.addAll(books);
}
Optional<Child> child = childRepository.findById(childId);
return recBooks.stream()
.limit(20)
.map(book -> RecBook.builder()
.child(child.get())
.book(book)
.build())
.collect(Collectors.toList());
};
}Writer: 추천 도서 목록 일괄 저장
@Bean
public ItemWriter<List<RecBook>> recommendBookWriter() {
return recBooks -> {
for (List<RecBook> recBook : recBooks) {
recBookRepository.saveAll(recBook);
}
};
}배치 성능 테스트
JMeter 를 이용해 아래와 같이 환경 설정한 후 테스트를 진행했다.
그 결과 10만 건의 처리가 1시간 11분이나 소요되는 문제가 발생했다.

원인 분석 & 해결방안
배치 처리에서 발생하는 병목 지점을 확인하기 위해 쿼리문을 분석했고 그 과정에서 해답을 얻을 수 있었다.
원인1. Processor 에서 발생하는 지연
병목 구간을 확인하기 위해 ChunkListener 를 implements 하는 리스너를 만들어 청크 사이즈 단위로 각 구간의 총 처리 시간을 측정하였다. 그 결과 Processor > Writer > Reader 순으로 시간이 소요되었으며, 특히 Processor 구간에서 가장 많은 처리 시간이 발생하는 것을 확인할 수 있었다.

이유는 Processor 내부에 지나치게 많은 조회 쿼리가 발생했기 때문이다.
1. MBTI 히스토리 조회
2. 해당 히스토리의 성향 점수 조회
3. 성향 점수에 대해 각 도서 목록 조회 x 4
4. 자녀 정보 조회즉, 자녀 1명당 최소 7건 이상의 DB 호출이 발생하게 된다. 특히 for 문 안에서 성향 점수별 도서 목록을 조회하는 쿼리가 4번 반복되면서 총 쿼리 호출 횟수와 네트워크 IO가 급격히 증가하면서 병목이 발생한 것이다!
해결방안1. Chunk Size 조절
결론부터 말하면, 이 방안은 사용자 데이터가 더 많아질 때 고려하기로 했다.
청크사이즈를 설정할 때 몇 가지 기준을 정했다.
1️⃣ 처리 속도
- 청크가 너무 크면 트랜잭션 시간이 길어서 롤백 비용이 커질 수 있다.
- 반대로 너무 작으면 커밋 횟수가 많아져 오버헤드가 발생할 수 있다.
2️⃣ 메모리 점유율
- 현재 로컬환경으로 실행하기 때문에 메모리 여유가 없다.
- 지나치게 큰 청크 사이즈는 OutOfMemoryError 를 유발할 수 있다.
이 기준에 따라 청크 사이즈별 쿼리 건수를 계산하면 다음과 같다:
| chunk size | 계산 | 예상 쿼리 건수 |
|---|---|---|
| 10 | 5,000 / 10 | 500 |
| 100 | 5,000 / 100 | 50 |
| 1000 | 5,000 / 1,000 | 5 |
표에서 확인할 수 있듯이, 청크 사이즈가 10이면 500번의 쿼리가 발생해 처리 속도가 늦어지고, 반대로 1,000으로 설정한다면 트랜잭션 횟수가 5번으로 줄어 효율은 높아지겠지만 트랜잭션 당 처리 데이터량이 많아지면서 메모리 사용량이 증가할 수 있다.
✅ 따라서 현 개발 환경에서 가장 적절한 처리 속도와 메모리 안정성을 확보할 수 있는 100으로 설정하는 것이 적합하다고 판단했다.
해결방안2. 구조 설계 변경
결국 위 코드의 가장 큰 문제는 Processor 구간에서 자녀마다 반복적으로 DB를 호출한다는 점이다. 따라서 IO를 줄일 수 있는 구조로 개선하여 설계하면 병목 현상을 줄일 수 있을 거라 판단하고 다음과 같이 구조를 변경하였다.
Reader: 자녀ID, 성향점수 4개를 추출Processor: 성향 점수 범위별 도서 20권 추출Writer: 추천 도서 일괄 저장
✅ 위와 같이 구조를 재설계하여 테스트하였더니 기존 시간보다 25분 단축시킨 결과를 얻을 수 있었다.

✅ 더불어 Processor 병목 현상도 개선할 수 있었다.

원인2. Writer 에서 발생하는 지연
Processor 로부터 전달받은 리스트를 일괄 저장하기 위해 saveAll() 을 사용하였다. saveAll 은 내부적으로 @Transactional 로 묶어서 한번만 실행되기 때문에 데이터 정합성과 롤백 처리에 유리하다. 실제로 save() 와 saveAll() 의 구조를 보면 알 수 있다.

그러나 saveAll() 은 결국 내부에서 각 엔티티에 대해 save() 를 반복 호출하는 것이기 때문에, 대량의 데이터를 삽입할 때에는 처리 속도에서 병목을 발생시킬 수 있다. 특히, JPA IDENTITY 전략 중 AUTO_INCREMENT 을 사용한다면 영속성 컨텍스트가 flush 되는 시점마다 insert 쿼리가 즉시 실행되기 때문에 bulk insert 가 불가능하다.

해결방안1. JPA 전략 변경
이를 해결하기 위해 가장 먼저 떠올린 방법은 JPA ID 생성 전략을 변경하는 것이었다. TABLE 이나 SEQUENCE 로 바꾼다면 영속성 컨텍스트에 엔티티를 쌓아두었다가 한 번에 flush 하는 batch insert 가 가능해 진다. 하지만 다음과 같은 이유로 이 방안은 적용하지 않기로 결정했다.
- SEQUENCE 전략은 오라클DB 전용으로, MySQL 은 지원하지 않음.
- TABLE 전략은 별도의 테이블을 ID값을 관리해야 하는 번거로움 + 운영 중인 테이블과 별도로 관리하는 복잡성 발생.
- 프로젝트 기한이 얼마남지 않은 시점에서 전략을 바꾸는 것은 적합하지 않다고 판단.
해결방안2. 임시 테이블 생성
두 번째로 고려한 방법은 임시 테이블을 두는 것이다. JDBC batch insert 방식으로 임시테이블에 먼저 적재한 뒤, INSERT INTO SELECT 쿼리로 메인 테이블에 데이터를 한 번에 INSERT 하는 구조이다. 결과적으로 이 방식을 최종 선택하게 되었는데, 그 이유는 다음과 같다.
- JPA IDENTITY 전략을 유지하면서 대량 데이터를 빠르게 삽입할 수 있다는 점
- Batch insert 가 가능해지면서 네트워크 IO와 트랜잭션 수를 줄여 처리 성능을 개선한다는 점
임시 테이블을 적용한 코드는 다음과 같다:
@Bean
public ItemWriter<List<RecBook>> recommendBookWriter() {
return new ItemWriter<List<RecBook>>() {
@Override
public void write(Chunk<? extends List<RecBook>> chunk) throws Exception {
LocalDateTime now = LocalDateTime.now();
// 1. 임시 테이블에 삽입할 파라미터 리스트 생성
List<SqlParameterSource> batchParams = chunk.getItems().stream()
.flatMap(List::stream)
.map(recBook -> new MapSqlParameterSource()
.addValue("child_id", recBook.getChild().getChildId())
.addValue("book_id", recBook.getBook().getBookId())
.addValue("created_at", now)
.addValue("modified_at", now))
.collect(Collectors.toList());
// 2. 임시 테이블에 데이터 배치 삽입
String dropTempTable = "DROP TABLE IF EXISTS temp_rec_book";
String createTempTable = """
CREATE TABLE temp_rec_book (
child_id BIGINT NOT NULL,
book_id BIGINT NOT NULL,
created_at TIMESTAMP NOT NULL,
modified_at TIMESTAMP NOT NULL,
PRIMARY KEY (child_id, book_id)
) ENGINE=InnoDB
""";
namedParameterJdbcTemplate.getJdbcTemplate().execute(dropTempTable);
namedParameterJdbcTemplate.getJdbcTemplate().execute(createTempTable);
String tempInsertQuery = """
INSERT INTO temp_rec_book (child_id, book_id, created_at, modified_at)
VALUES (:child_id, :book_id, :created_at, :modified_at)
""";
namedParameterJdbcTemplate.batchUpdate(tempInsertQuery, batchParams.toArray(new SqlParameterSource[0]));
// 3. 중복 데이터에 대해 rec_book 테이블을 UPDATE
String updateQuery = """
UPDATE rec_book AS r
JOIN temp_rec_book AS t
ON r.child_id = t.child_id AND r.book_id = t.book_id
SET r.modified_at = t.modified_at
""";
namedParameterJdbcTemplate.getJdbcTemplate().execute(updateQuery);
// 4. 새 데이터에 대해 rec_book 테이블에 INSERT
String insertQuery = """
INSERT INTO rec_book (child_id, book_id, created_at, modified_at)
SELECT t.child_id, t.book_id, t.created_at, t.modified_at
FROM temp_rec_book t
LEFT JOIN rec_book r
ON t.child_id = r.child_id AND t.book_id = r.book_id
WHERE r.child_id IS NULL
""";
namedParameterJdbcTemplate.getJdbcTemplate().execute(insertQuery);
}
};
}✅ 테스트 결과 1시간 → 45분 → 17분으로 약 72%의 처리 시간 단축 효과를 확인할 수 있었다.

✅ INSERT 쿼리도 하나만 날라가는 걸 확인할 수 있다.
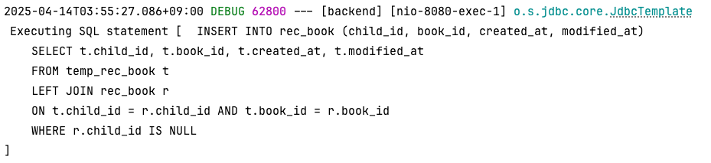
아쉬운 점
- JPA IDIENTIY의 한계는 극복할 수 있었지만 임시 테이블을 생성하고 데이터 삽입하는 과정이 추가되면서 쿼리 수가 증가해 추후 더 많은 데이터를 처리해야 한다면 복잡성이 증가될 것으로 예상된다.
INSERT INTO SELECT쿼리를 통해 데이터를 적재하는 순간 트랜잭션 범위가 커지기 때문에 롤백 발생시 처리 시간이 증가할 수 있다.- JdbcTemplate을 사용하면 네이티브 쿼리를 작성하기 때문에 Type-safe 하지 않다.
해결방안3. EntityQL 사용
EntityQL 은 QueryDSL 과 JPA Entity를 조합해 Type-safe 한 Native SQL을 작성할 수 있는 오픈소스이다.
EntityQL 의 간단한 특징
- TypeSafe 한 쿼리 작성 가능
- JPA Entity 그대로 활용 가능
- Native SQL 수준의 성능과 직관적인 쿼리 작성
- 동적 쿼리
- Query DSL 문법 지원
언제 사용하면 좋을까?
- JPA IDENTITY 전략을 유지하면서 대량의 데이터를 처리해야 할 때
- 복잡한 동적 쿼리 작성이 필요할 때
- JPA의 성능 병목 지점을 피하고 싶을 때
이번 프로젝트에 도입하지 못한 이유
-
Spring Batch 와의 연동 이슈
: EntityQL 은 MyBatis 기반의 SqlSession을 통해 동작하는데, 현재 배치 구조가 JDBC 기반으로 되어 있어 별도의 SqlSessionFactory을 설정해야 한다. -
MyBatis 환경 설정 비용
: 현재 프로젝트는 JPA 환경이라, EntityQL을 위한 별도의 MyBatais Configuration, SqlSessionFactory, Mapper 등을 추가해야 한다.
위 두 개의 제약 사항은 유지보수 복잡성이 증가할 것으로 예상되었다. 따라서 이 방식은 보류하였다.
참고 자료
느낀 점
처음 해보는 배치 처리였기에 어떻게 설계하고 구현해야 할지 감이 안와서 일주일 동안 막막했던 적이 있었다. 특히 청크 단위의 처리구조를 이해하는데 많은 시간을 들였다. 1시간에서 17분으로 단축하기 위한 긴 과정을 통해 쿼리 최적화와 트랜잭션 전략의 중요성을 체감할 수 있었다. 임시테이블 생성 방안은 JPA IDENTITY 한계를 극복했다고 하기보다 우회한 방법이었지만, 실질적인 성능 개선을 이뤘다는 점에서 긍정적인 결과였다. 이번 경험을 통해 다음에는 EntityQL과 같은 새로운 기술도 과감히 도입해보며 더 나은 성능과 구조를 설계해보고 싶다.

안녕하세요! 글 잘 봤습니다. 글이 술술 읽히네요..!
한 가지 궁금점이 생겼는데, JDBC batch insert 방식에서 기존 로우는 업데이트 / 신규 데이터는 인서트를 하기 위해서
임시 테이블을 사용할 수도 있고 MySQL의 ON DUPLICATE KEY UPDATE를 통해 쿼리 하나로 해결할 수도 있을 것으로 보이는데 임시 테이블을 사용하기로 결정하신 이유가 궁금해요!