🌿 스택 & 큐
🔎 Stack 란 ?
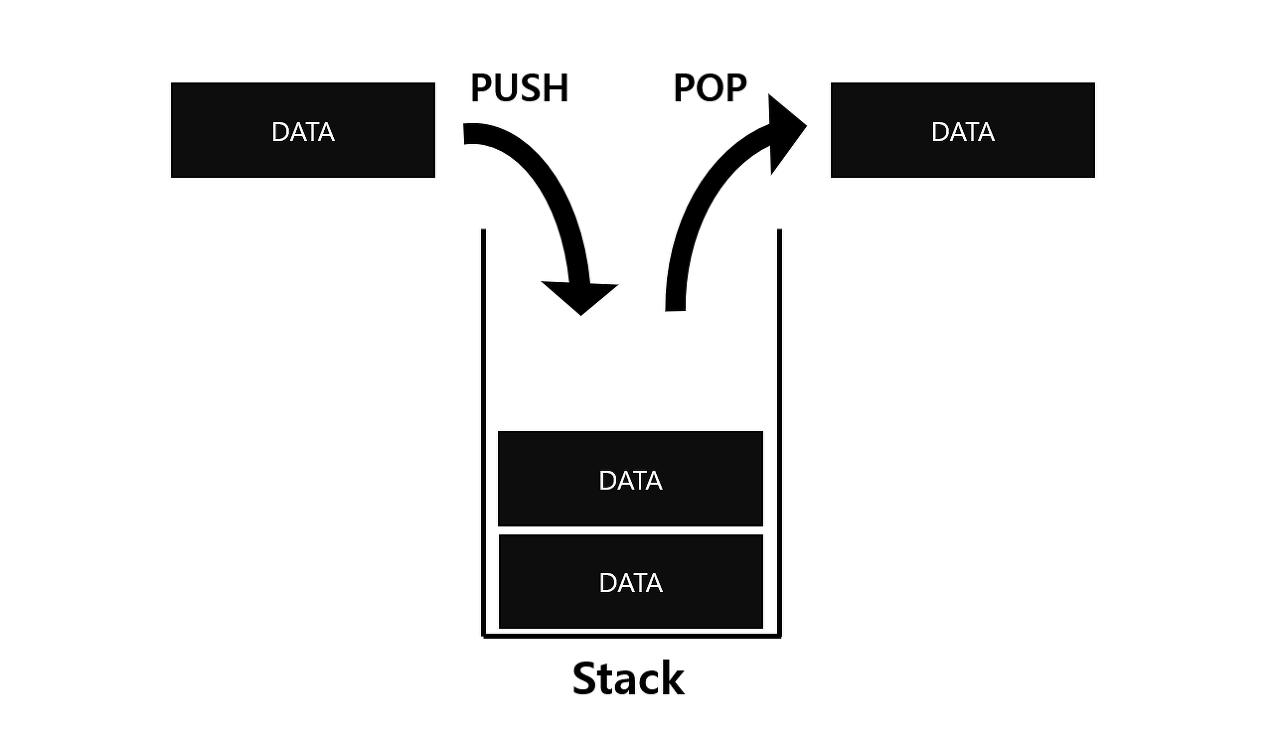
스택(Stack)은 LIFO(Last-In First-Out)으로 후입선출 구조를 가진다.
- 만약 스택이 비어있을 때 자료를 꺼내려고 시도하면 스택 언더플로우가 발생하고 반대로, 스택이 꽉 차 있을 때 자료를 넣으려고 하면 스택 오버플로우가 발생한다.
- 주로 함수의 콜 스택, 문자열 역순 출력, 연산자 후위표기법 등에 쓰인다.
push()로 데이터를 삽입하고,pop()으로 데이터 최상위 값을 삭제한다.
🔎 Queue 란 ?
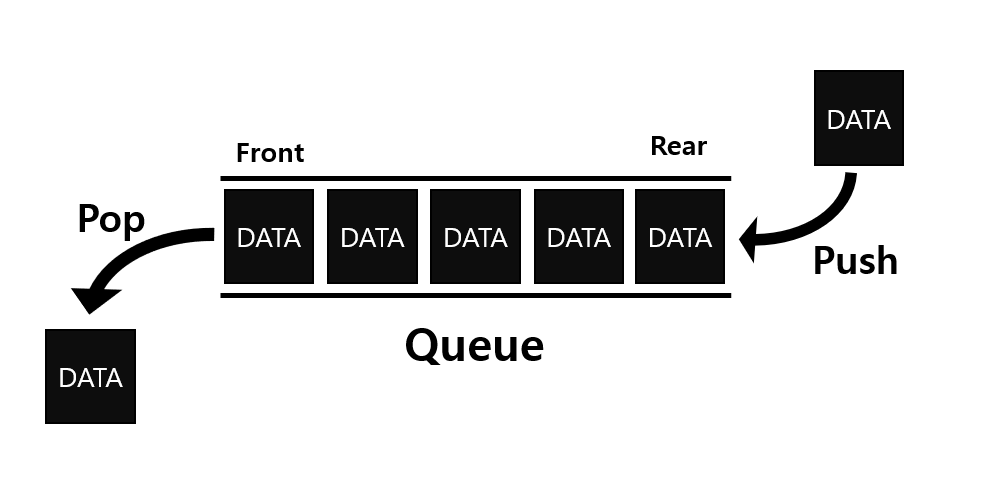
큐(Queue)는 FIFO(First-In First-Out)으로 선입선출 구조를 가진다.
- 주로 프로세스 처리나 CPU 관리에 많이 사용된다.
- 큐는 스택과 다르게 rear 부분에서 데이터를 삽입하고, front 부분에서 데이터를 삭제한다.
🌿 리스트
🔎 ArrayList의 특징과 그로 인한 장단점 말해봐
ArrayList의 가장 큰 특징은 순차적으로 데이터를 저장한다는 점이다.
- 데이터에 순서가 있기 때문에 0부터 시작하는 index가 존재하며, index를 사용해 특정 요소를 찾고 조작하는 것이 가능하다는 것이 장점이다.
- 하지만 순차적으로 존재하는 데이터의 중간에 요소가 삽입/삭제되는 경우, 그 뒤의 모든 요소들을 한 칸씩 뒤로 밀거나 당겨줘야 하는 단점이 있다.
⇒ 따라서 ArrayList는 정보가 자주 삭제되거나 추가되는 데이터에는 적절치 않다 !
🔎 ArrayList를 적용시키면 좋은 데이터의 예를 들고, 적용하지 않으면 어떻게 되는지 구체적으로 설명해주면 고맙겠어
좋은 예로 주식 차트가 있다.
주식 차트에 대한 데이터는 요소가 중간에 새롭게 추가/삭제되는 정보가 아니며, 날짜별로 주식 가격이 차례대로 저장되어야 하는 데이터이다.
즉, 순서가 굉장히 중요한 데이터이므로 → Array와 같이 순서를 보장해주는 자료구조를 사용하는 것이 좋다.
만약 순서가 없는 자료구조를 사용할 경우, 날짜별 주식 가격을 확인하기 어려우며, 매번 전체 자료를 읽어 들이고 비교해야 하는 번거로움이 발생한다.
🔎 Array와 ArrayList의 차이를 말해봐
- Array는 크기가 고정적이고, ArrayList는 가변적이다.
- Array는 초기화 시 메모리에 할당되어 ArrayList보다 속도가 빠르고, ArrayList는 데이터 추사/삭제 시 메모리를 재할당하기 때문에 속도가 Array보다 느리다.
🔎 Array와 LinkedList의 차이를 장단점과 함께 설명해줘
Array는 연속된 메모리 공간에 존재하고, LinkedList는 메모리 상에서 떨어져 있는 데이터들이 앞/뒤 데이터를 기억하는 형태로 존재한다.
Array는 index로 해당 원소에 접근할 수 있어 찾고자 하는 원소의 인덱스 값을 알고 있으면 O(1)에 해당 원소로 접근할 수 있다.
- 즉 RandomAccess가 가능하기 때문에 속도가 빠르다는 장점이 있다.
- 하지만 삽입/삭제 과정에서 각 원소들을 shift 하는 비용이 발생한다. 이 경우 시간 복잡도는
O(n)이 된다.
이 문제를 해결하기 위해 LinkedList가 등장했다.
- 각 원소들은 자기 자신 다음에 어떤 원소인지만을 기억하고 있기 때문에 이 부분만 다른 값으로 바꿔주면 삽입/삭제를
O(1)로 해결할 있다. - 하지만 원하는 위치에 한번에 접근할 수 없다는 단점이 있다.
✅ 정리하면,
- Array는 검색이 빠르지만, 삽입/삭제가 느리다.
- LinkedList는 삽입/삭제는 빠르지만, 검색이 느리다.
🌿 BFS & DFS
🔎 BFS, DFS 에 대해 설명해봐
BFS(Breadth-First Search) 와 DFS(Depth-First Search) 는 그래프 탐색 알고리즘이다.
→ 이 알고리즘들은 그래프의 노드를 탐색하고 연결된 다른 노드들을 방문하는 방식에 차이가 있다.
✅ BFS
BFS는 너비 우선 탐색 알고리즘이다.
- 현재 노드에서 인접한 노드를 먼저 탐색하고, 그 다음 레벨의 노드를 차례로 방문하는 방식이다.
- BFS 는
큐(Queue)를 사용하여 구현된다. - 최단 경로를 찾거나 그래프 구조를 파악하는 데 유용하다.
✅ DFS
DFS는 깊이 우선 탐색 알고리즘이다.
- 현재 노드에서 가능한 한 깊이 들어가며 탐색하며, 더 이상 탐색할 수 없을 때 되돌아와 다음 가능한 노드를 탐색한다.
- DFS는
스택(Stack)또는재귀 함수를 사용하여 구현된다. - 그래프 구조를 파악하거나 가능한 모든 경로를 탐색하는 데 유용하다.
