🌿 트랜잭션
🔎 트랜잭션이란 ?
트랜잭션(Transacation)은 데이터베이스의 상태를 변화시키는 하나의 논리적인 작업 단위이다.
트랜잭션은 여러 개의 작업을 하나의 논리적인 단위로 묶어서 반영과 복구를 조정하기 위해 사용한다. 따라서 데이터의 부정합이 일어났을 경우, 롤백(rollback)하여 이를 방지할 수 있다.
🔎 트랜잭션 vs Lock
트랜잭션은 데이터의 정합성을 보장하기 위한 기능이고, Lock은 동시성을 제어하기 위한 기능이다.
Lock은 여러 커넥션에서 동시에 동일한 자원을 요청할 경우, 순서대로 한 시점에는 하나의 커넥션만 변경할 수 있게 해주는 역할을 한다. 여기서 자원은 레코드나 테이블을 말한다.
이와는 다르게 트랜잭션은 하나의 논리적인 작업 중 몇 개의 쿼리를 있든 관계없이 논리적인 작업이 모두 적용되거나 적용되지 않아야 함을 보장한다.
🔎 트랜잭션의 4가지 특성을 간단하게 말해봐
트랜잭션은 ACID 라는 4가지 특성을 만족해야 한다.
- 원자성 (Atomicity)
: 만약 트랜잭션 중간에 어떠한 문제가 발생한다면, 트랙잭션에 해당하는 어떠한 작업 내용도 수행되어서는 안되며, 아무런 문제가 발생되지 않았을 경우에만 모든 작업이 수행되어야 한다. - 일관성 (Consistency)
: 트랜잭션이 완료된 다음 상태에서도 트랜잭션이 일어나기 전의 상황과 동일하게 데이터의 일관성을 보장해야 한다. - 고립성 (Isolation)
: 각각의 트랜잭션은 서로 간섭없이 독립적으로 수행되어야 한다. - 지속성 (Durability)
: 트랜잭션이 정상적으로 종료된 다음에는 영구적으로 데이터베이스에 작업 결과가 저장되어야 한다.
🔎 트랜잭션을 사용할 때 주의할 점
트랜잭션은 꼭 필요한 최소의 코드에만 적용하는 것이 좋다.
즉, 트랜잭션의 범위를 최소화하는 것이다. 일반적으로 데이터베이스 커넥션은 개수가 제한적이다. 만약 각 단위 프로그램이 커넥션을 소유하는 시간이 길어진다면, 사용 가능한 여유 커넥션의 수는 줄어들게 된다. 이때 각 단위 프로그램에서 커넥션을 가져가기 위해 대기해야 하는 상황이 발생할 수 있다. 따라서 위 문제를 방지하기 위해 최소의 코드에만 트랜잭션을 적용하는 것이 좋다.
🌿 교착상태
🔎 교착상태란 ?
교착상태란 두 개 이상의 트랜잭션이 특정 자원(행 또는 테이블)의 잠금(Lock)을 획득한 채 다른 트랜잭션이 소유하고 있는 자원을 요구하며 무한정 기다리는 현상을 말한다.
🔎 교착상태 발생의 필요충분 4가지 조건 말해봐
교착상태가 발생하기 위해서는 다음의 4가지 조건이 충족되어야 한다.
- 상호배제 : 한 번에 한 개의 프로세스만이 공유 자원을 사용할 수 있다.
- 점유와 대기 : 프로세스가 할당된 자원을 가진 상태에서 다른 자원을 기다린다.
- 비선점 : 다른 프로세스에 할당된 자원은 사용이 끝날 때까지 강제로 뺏을 수 없다.
- 순환 대기 : 공유 자원과 공유 자원을 사용하기 위해 대기하는 프로세스들이 원형을 이루면서 대기한다. 각 프로세스는 순환적으로 앞/뒤에 있는 프로세스가 요구하는 자원을 가지고 있다.
🔎 교착 상태의 빈도를 낮추는 방법 설명해봐
- 트랜잭션을 자주 커밋한다.
- 정해진 순서로 테이블에 접근한다.
- 읽기 잠금 획득 (SELECT ~ FOR UPDATE)의 사용을 피한다.
- 한 테이블의 복수 행을 복수의 연결에서 순서 없이 갱신하면 교착상태가 발생하기 쉽다. 이 경우에는 테이블 단위의 잠금을 획득해 갱신을 직렬화 하면 동시성은 떨어지지만 교착상태를 회피할 수 있다.
🌿 정규화
🔎 정규화란 ?
정규화는 데이터의 중복을 줄이고, 데이터의 일관성과 무결성을 보장하기 위한 프로세스이다.
정규화를 통해 데이터베이스의 성능을 최적화하고, 데이터 중복으로 인한 데이터 불일치 문제를 예방한다.
🔎 정규화 목적 말해봐라
가장 큰 목표는 테이블 간 중복된 데이터를 허용하지 않는 것이다.
- 데이터의 중복을 없애면서 불필요한 데이터를 최소화시킨다.
- 데이터의 무결성을 지키고, 이상 현상을 방지한다.
🔎 정규화 이상의 종류를 말해봐라
정규화를 거치지 않아 데이터베이스 내에 데이터들이 불필요하게 중복되어 릴레이션 조작 시 예기치 못하게 발생하는 이상 현상을 말한다.
- 이상 종류는 삽입 / 삭제 / 갱신 이 있다.
[삽입 이상]
- 데이터를 삽입할 때 의도와 상관없이 원하지 않는 값도 함께 삽입되는 현상
[삭제 이상]
- 한 튜플을 삭제할 때 의도와 상관없는 값도 함께 삭제되는 현상
[갱신 이상]
- 튜플에 있는 속성 값을 갱신할 때 일부 튜플의 정보만 갱신되어 정보에 모순이 생기는 현상
🔎 정규화 단계에 대해 설명해봐라
여러 단계가 있지만, 대체적으로 1~3단계 정규화까지의 과정을 거친다.
- 제 1정규화(1NF) : 도메인은 오직 원자값만을 포함한다.
- 제 2정규화(2NF) : 기본키가 아닌 모든 속성이 기본키에 대해 완전 함수적 종속을 만족한다.
- 제 3정규화(3NF) : 기본키가 아닌 모든 속성이 기본키에 대해 이행적 함수 종속 관계를 만족하지 않는다.
- BCNF : 모든 결정자는 후보키어야 한다.
🔎 정규화 장점에 대해 말해봐라
- 데이터베이스 변경 시 이상 현상을 해결할 수 있다.
- 데이터 일관성과 무결성을 보장할 수 있다.
- 검색 및 조인 연산의 성능을 개선할 수 있다.
- 데이터베이스의 유연성이 향상된다.
🔎 정규화 단점에 대해 말해봐라
- 테이블 분해로 인한 조인 작업이 증가한다.
- 불필요한 분해로 인한 성능 저하를 발생시킬 수 있다.
- 복잡도가 증가할 수 있다.
- 불필요한 쿼리 실행으로 인한 부하가 발생할 수 있다.
🔎 정규화 단점에 대한 대응책은 ?
많은 조인 작업의 증가를 해결하기 위해 반정규화를 적용하는 전략이 등장했다.
- 반정규화는 정규화된 엔티티, 속성, 관계를 시스템의 성능 향상 및 개발과 운영의 단순화를 위해 중복 통합, 분리 등을 수행하는 데이터 모델링 기법이다.
🔎 반정규화의 대상은 ?
- 정규화에 충실하여 종속성, 활용성은 향상되었지만, 수행속도가 느려진 경우
- 테이블에 대량 데이터가 있고 대량의 범위를 자주 처리하는 경우
- 테이블에 지나치게 조인을 많이 사용하게 되어 데이터를 조회하는 것이 기술적으로 어려운 경우
🔎 반정규화에서 주의할 점은 ?
- 반정규화를 과도하게 적용하다 보면 데이터의 무결성이 깨질 수 있다.
- 삽입/수정/삭제의 질의문에 대한 응답 시간이 늦어질 수 있다.
🤔 반정규화 시 삽입/수정/삭제 성능이 왜 낮아질까 ?
🅰️ 정규화를 수행하게 되면 중복을 제거하고, 이상현상을 제거해 정규화를 수행하지 않았을 때보다 삽입/수정/삭제가 빨라지게 된다. 반면, 반정규화를 하게 되면 이상 현상이 일어날 수 있기 때문에 정규화를 했을 때보다 성능이 낮아질 수 있다.
🌿 Join
🔎 Join의 정의와 종류에 대해 간단하게 설명해줘
Join 은 두 개 이상의 테이블이나 데이터베이스를 연결하여 데이터를 검색하는 방법이다.
두 개 이상의 테이블에서
Inner Join: 교집합만을 추출한다.Left Join: from에 해당하는 부분을 추출한다.Outer Join: 모든 테이블에 해당하는 부분을 추출한다.
🔎 Inner Join과 Outer Join 의 정의와 어떻게 사용되는지 설명해봐
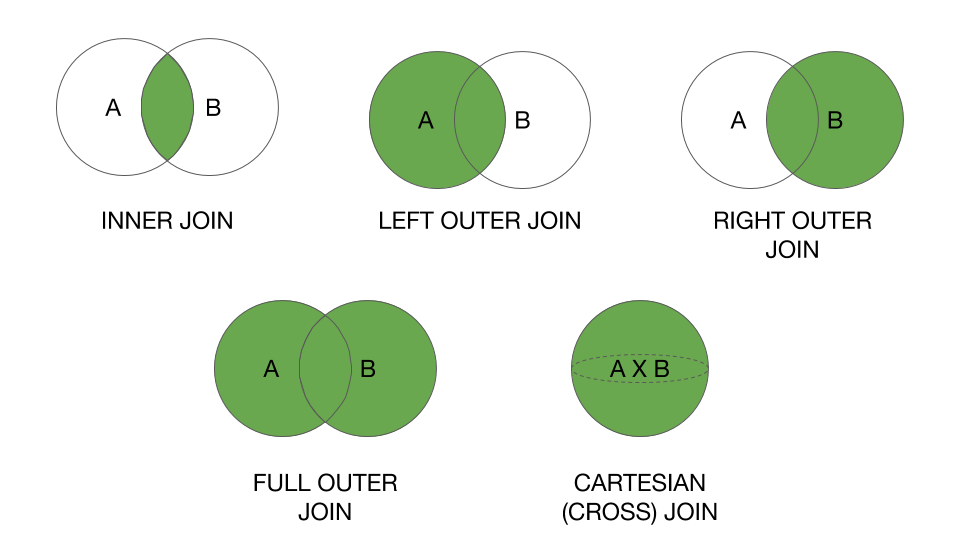
Inner Join 은 두 개 이상의 테이블 간의 공통된 값을 기준으로 조인하는 방식이다.
- 두 테이블에서 일치하는 행만을 결과로 반환한다.
SELECT 컬럼
FROM 테이블A
INNER
JOIN 테이블B
ON 조인 조건Outer Join 은 Inner Join과 다르게 조인 조건을 만족하지 않는 행도 결과로 반환하는 방식이다.
- 특정 테이블의 모든 행을 결과에 포함시키고, 다른 테이블과 조인할 때 조건을 만족하지 않는 경우에는 NULL 값으로 채워진다.
✅ Outer Join은 세가지 유형으로 나뉜다.
Left Outer Join(= Left Join): 왼쪽 테이블의 모든 행을 결과에 포함Right Outer Join(= Right Join): 오른쪽 테이블의 모든 행을 결과에 포함Full Outer Join(= Full Join): 양쪽 테이블의 모든 행을 결과에 포함
SELECT 컬럼
FROM 테이블A
LEFT/RIGHT/FULL
JOIN 테이블B
ON 조인 조건🌿 인덱스
🔎 인덱스란 ?
인덱스는 데이터베이스에서 데이터를 빠르게 검색하고 접근하기 위해 사용되는 자료 구조이다.
- 레코드 검색 시 전체 검색이 아닌 인덱스로 검색하여 빠른 검색이 가능해 진다.
🔎 언제 인덱스를 만드는 게 좋을까 ?
WHWER,JOIN문에서 자주 사용되는 컬럼- 데이터의 중복도가 적은 컬럼
- 외래키가 사용되는 열
🔎 인덱스를 사용하는 이유는 ?
일반적으로 데이터베이스는 테이블에 대한 쿼리 작업을 수행할 때 전체 데이터를 순차적으로 검색하는 선형 검색 방식을 사용한다. 하지만 데이터베이스가 크고 복잡해지면 이러한 선형 검색은 많은 리소스를 요구하게 된다.
→ 이러한 문제를 해결하기 위해 인덱스를 사용한다.
🔎 인덱스의 장단점
✅ 장점
- 테이블의 검색 및 정렬 속도를 향상한다.
- 고유성 제약 조건을 적용하고 데이터의 일관성과 무결성을 유지한다.
✅ 단점
- 여러 사용자가 한 페이지에 동시에 수정할 수 있는 병행성이 줄어든다.
- DML에 취약하기 때문에, 데이터를
INSERT/DELETE/UPDATE시 성능이 감소한다.
🔎 인덱스를 생성하는 데 B-Tree를 사용하는 이유
각 노드가 여러 개의 key를 갖고, 자식 노드들 사이에 키 값 범위를 나누어 저장하는 구조를 가지고 있어, 트리의 높이를 최소화하면서 빠른 검색과 삽입/삭제 연산에 효율적이다.
- "O(1) 로 접근할 수 있는 Hash Table 이 더 효율적이다" 라고 생각할 수 있지만, 등호 연산이 아닌 부등호 연산의 경우에 문제가 발생한다.
→ 동등 연산에 특화된 Hash Table 은 데이터베이스의 자료구조로 적합하지 않다.
🔎 클러스터형 인덱스 vs 넌클러스터형 인덱스 에 대해 설명해줘
클러스터형 인덱스는 테이블의 정렬된 형태로 저장하는 방식이다.
- 테이블당 하나의 클러스터형 인덱스만 가질 수 있다.
- 주로 테이블의 기본키(PK) 에 대해 생성된다.
- 데이터베이스 내에서 물리적인 데이터 순서와 인덱스 순서가 일치하므로, 데이터를 검색할 때 빠른 응답 시간을 제공한다.
- 클러스터형 인덱스의 생성은 데이터의 물리적인 재정렬이 필요하기 때문에,
INSERT/DELETE/UPDATE시 오버헤드가 발생할 수 있다.
넌클러스터형 인덱스는 별도의 인덱스 구조를 생성하여 테이블과 별개로 관리하는 방식이다.
- 테이블당 여러 개의 넌클러스터형 인덱스를 가질 수 있다.
- 주로 테이블의 비기본키(NON-PK) 열에 대해 생성된다.
- 데이터의 논리적인 순서를 유지하지 않지만, 데이터의
INSERT/DELETE/UPDATE시 시 오버헤드가 적다.
