파이썬 알고리즘 인터뷰라는 책의 4장에 대한 개념을 정리해보자.
링크들
-
자료구조 시각화 사이트 : https://visualgo.net/en
-
리트코드 : https://leetcode.com/
-
노션 링크: https://marshy-abacus-5a4.notion.site/2-1-14-1-20-115bd0da395c4e04b7d0804d9e67af39
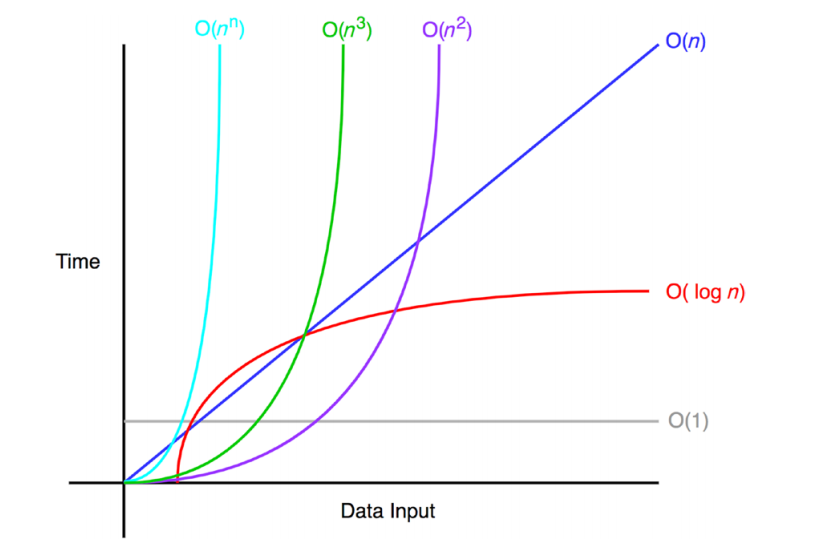
빅오(big-O)
big-0
💡 빅오(Big-O)란 입력값이 무한대로 향할 때, **함수의 상한을 설명하는 수학적 표기 방법**, 점근적 실행 시간을 표기하는 방법 중 하나즉 입력값이 무한대로 향할 때 함수의 실행 시간의 추이를 의미하는 것으로
이 부분에 왜 관심을 갖냐면 입력의 크기가 충분히 클 때 알고리즘의 효율성에 따라 수행 시간이 크게 차이가 날 수 있기에 위 부분에 관심을 가지게 된다.
→ 큰 입력값에 대한 처리가 효율적이여야하므로 알고리즘에 대해서 잘 이해하고 적용해야한다.
점근적 실행시간 == 시간 복잡도 이고 시간 복잡도는 알고리즘 수행에 있어 거리는 시간을 설명하는 계산 복잡도이다. 그런데 계산 복잡도를 표기하는 방법 중 하나가 big-O 인 것이다.
big-O로 시간 복잡도를 표현할 때는 최고차항만 표시한다. → 크기가 작은 것은 다 비슷비슷하다 관심이 없다.
big-O의 표기 방법
big-O의 표기방법은 다음과 같다.
1. O(1)
입력값이 아무리 크더라도 실행 시간은 일정한 최고의 알고리즘이다.
하지만 상수 시간이더라도 상수값이 엄청 크디면 사실상 일정한 시간의 의미가 없으며
해당하는 알고리즘은 Hash 테이블의 조회 및 삽입이 이에 해당한다.
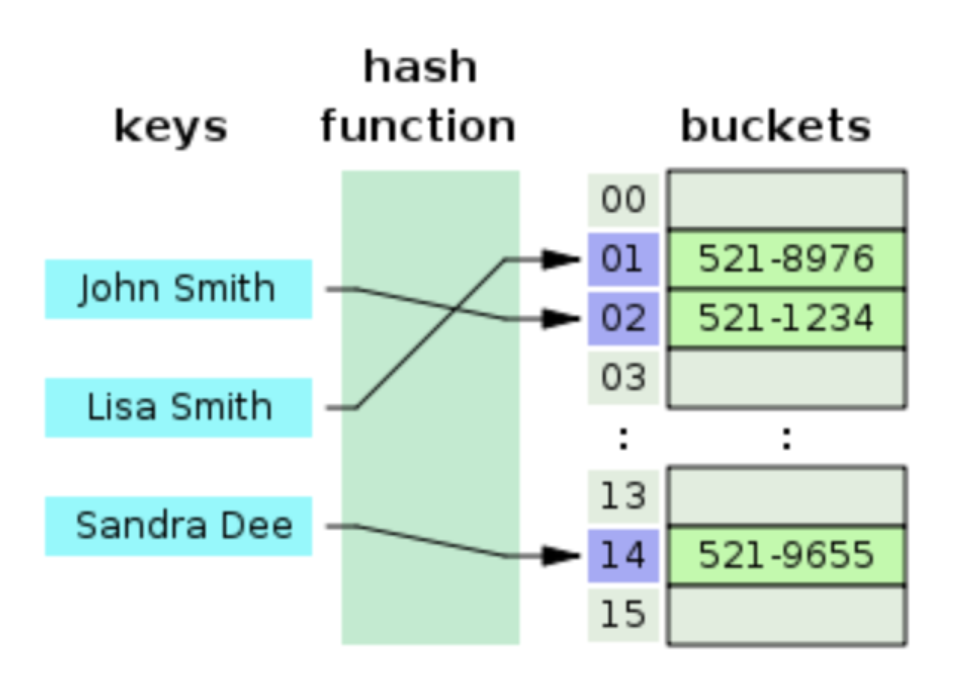
💡 해시 테이블, 리스트의 길이와 상관 없이 결과를 보게 되는 연산들Hash 테이블이란?
💡 **(key, Value)로 데이터를 저장하는 자료구조** 중 하나로 데이터를 빠르게 검색할 수 있다.빠른 이유는?
→ 내부적으로 배열(버킷)을 사용하여 데이터를 저장하기 때문이다.
→→ 버킷이란?
해시 테이블은 각각의 Key 값에 해시 함수를 적용하여 배열의 고유한 index를 생성하고 이 index를 활용하여 값을 저장하거나 검색하게 된다.
여기서 실제 값이 저장되는 장소를 버킷 혹은 슬롯이라고 부른다.
파이썬에서는 딕셔너리(Dictionary) 타입이 해쉬 테이블과 같은 구조입니다.
캐시를 구현할 때 주로 사용
→ 왜? : 캐시 구현 시 중복 확인이 쉽기 때문에 사용함!
→→ 중복확인이 왜 쉬워?: 해시를 하고 나면 각 객체가 숫자로 나오기 때문에 같은 객체인지 다른 객체인지 비교가 가능하고 같은 숫자라면 같은 객체라고 인식하기 때문에
즉, hash 값으로만 비교가 가능하고 한 번의 비교연산만이 필요하므로 중복확인이 쉽다.
예시:
(Key, Value)가 ("John Smith", "521-1234")인 데이터를 크기가 16인 해시 테이블에 저장하는과정?
(1) index = hash_function("John Smith") % 16 연산을 통해 index 값을 계산한다.
(2) array[index] = "521-1234" 로 전화번호를 저장하게 된다.
이러한 구조로 데이터를 저장하면 Key값으로 데이터를 찾을 때 해시 함수를 1번만 수행하면 되므로 매우 빠르게 데이터를 저장/삭제/조회할 수 있다. 해시테이블의 평균 시간복잡도는
O(1)이다.해시 테이블에 사용되는 대표적인 해시 함수 4가지:
Division Method: 나눗셈을 이용하는 방법으로 입력값을 테이블의 크기로 나누어 계산한다.( 주소 = 입력값 % 테이블의 크기) 테이블의 크기를 소수로 정하고 2의 제곱수와 먼 값을 사용해야 효과가 좋다고 알려져 있다.Digit Folding:각 Key의 문자열을 ASCII 코드로 바꾸고 값을 합한 데이터를 테이블 내의 주소로 사용하는 방법이다.Multiplication Method: 숫자로 된 Key값 K와 0과 1사이의 실수 A, 보통 2의 제곱수인 m을 사용하여 다음과 같은 계산을 해준다. h(k)=(kAmod1) × mUniveral Hashing: 다수의 해시함수를 만들어 집합 H에 넣어두고, 무작위로 해시함수를 선택해 해시값을 만드는 기법이다.
# Hash Table class HashTable: def __init__(self, table_size): self.size = table_size self.hash_table = [0 for a in range(self.size)] def getKey(self, data): self.key = ord(data[0]) return self.key def hashFunction(self, key): return key % self.size def getAddress(self, key): myKey = self.getKey(key) hash_address = self.**hashFunction**(myKey) return hash_address def save(self, key, value): hash_address = self.getAddress(key) self.hash_table[hash_address] = value def read(self, key): hash_address = self.getAddress(key) return self.hash_table[hash_address] def delete(self, key): hash_address = self.getAddress(key) if self.hash_table[hash_address] != 0: self.hash_table[hash_address] = 0 return True else: return False #Test Code h_table = HashTable(8) h_table.save('a', '1111') h_table.save('b', '3333') h_table.save('c', '5555') h_table.save('d', '8888') print(h_table.hash_table) print(h_table.read('d')) h_table.delete('d') print(h_table.hash_table)
그러면 O(n)이 되는 경우는 언제일까? key 값이 같아진다면?
해시 충돌
해시 함수가 서로 다른 두 개의 입력값에 대해 동일한 출력값을 출력하면 발생하는 사건입니다. 해시 함수가 무한한 가짓수의 입력값을 받아 유한한 가짓수의 출력값을 생성하는 경우, 비둘기집 원리에 의해 해시 충돌은 항상 존재합니다.
해시 충돌 해결 방법
Open Addressing(개방 주소법)
해시 충돌이 일어나면 다른 버킷에 데이터를 저장하는 방식입니다.
1) 선형 탐색(Linear probing)은 해시 충돌 시 다음 버킷에 검색하는 해시를 저장하는 것이며
2) 제곱 탐색(Quadratic probing)은 해시 충돌시 제곱만큼 건너뛴 버킷에 데이터를 저장하는 방법이며
3) 이중 해시(Double hashing)는 해시 충돌시 다른 해시 함수를 한번 더 적용한 결과에 저장하는 것입니다.
- 테이블에 저장되는 값 : [original_hash_key, value]
선형 탐색 (Linear Probing)
- h(k), h(k) + 1, h(k) + 2, … 순서로 검사하여 처음으로 빈 슬롯에 저장 테이블의 끝에 도달하면 다시 처음으로 circular하게 돌아감
- search하는 경우에는 순차적으로 찾을때 까지 검색하다가 빈 슬롯이 나오면 종료
- Linear probing의 단점
- primary cluster : 키에 의해서 채워진 연속된 슬롯들을 의미
- 이런 cluster가 생성되면 이 cluster는 점점 더 커지는 경향이 생김
- 검색시간이 클러스터의 길이에 비례하게 되므로 바람직하지 않다.
- Quadratic probing
- 충돌 발생시 h(k), h(k) + 1^2, h(k) + 2^2, h(k) + 3^2, … 순서로 시도
- Double hashing
- 서로 다른 두 해시 함수 h1과 h2를 이용하여
- h(k, i) = (h1(k) + i*h2(k)) mod m
- 제곱 탐색(Quadratic Probing)
- 충돌 발생시 h(k), h(k) + 1^2, h(k) + 2^2, h(k) + 3^2, … 순서로 시도
- 이중 해시 (Double hashing)
- 서로 다른 두 해시 함수 h1과 h2를 이용한다.
- 키 값에 따라서 해시 값이 달라진다.
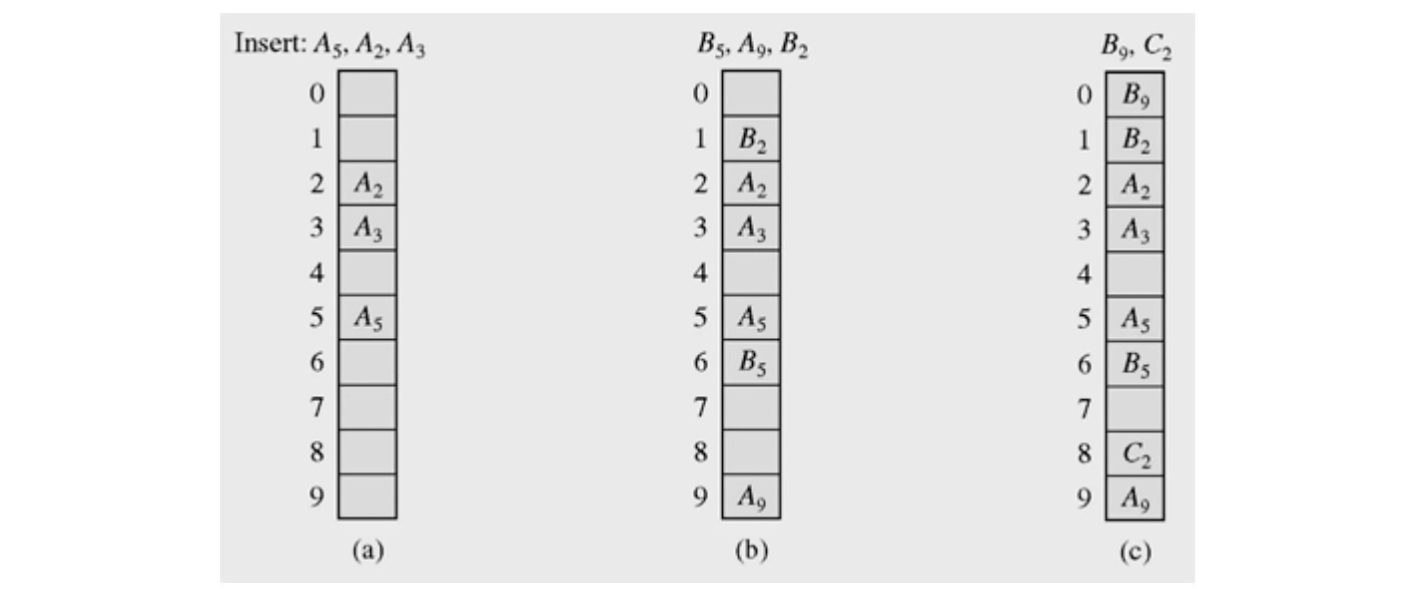
키의 삭제
- 단순히 키를 삭제할 경우 문제가 발생한다.
- 가령 A2, B2, C2 가 순서대로 모두 동일한 해시함수 값을 가져서 linear probing으로 충돌을 해결했을 때, B2를 삭제한 후 C2를 검색하는 경우가 이에 해당한다.
- Linear Probing을 했을 경우 빈 슬롯에 도달하면 검색이 종료되기 때문에 검색에 문제가 생기게 된다. 이 문제를 해결하기 위해서 삭제된 슬롯에 예를 들면 DEL이라는 표시를 해둘 수도 있지만, Dynamic Set을 구현한 해시 테이블의 특성상 삽입, 삭제가 빈번하게 일어나므로 결국 거의 모든 슬롯이 DEL표시로 채워질 수 있다.
- 또한, 곳곳에 DEL 표시가 되어있으면 결국 배열과 같이 모든 슬롯을 검색하게 되므로 Hashing의 장점을 잃게 된다.
- 가장 적절한 해결책은 삭제될 슬롯에 있는 값과 같은 해시 값을 가지는 클러스터의 마지막 슬롯을 삭제될 슬롯으로 가져와서 클러스터의 손상을 막는 방법이다.
Closed Addressing(체이닝 방법)
해시 충돌이 일어나면 키에 해당하는 데이터들을 연결하는 방식입니다. 일반적으로 연결 리스트를 사용하여 각각의 버킷들을 연결리스트로 만들어 충돌이 발생하면 해당 버킷의 리스트에 추가하는 방법입니다.
장점으로는 삭제와 삽입이 간단하다는 것이며 단점으로는 작은 데이터들을 저장할 때 연결 리스트 자체의 오버헤드가 부담되는 것입니다.
출처 :
리스트의 길이와 상관 없이 O(1) 연산들
- 원소 덧붙이기
.append()- 원소 하나를 꺼내기
.pop()위 연산들은 리스트의 길이와 무관하게 빠르게 실행할 수 있는 연산들이다. 리스트의 길이가 아무리 길어도 맨 끝에 요소 하나를 추가하는 것이나 맨 끝 요소 하나를 빼는건 빠르게 할 수 있기 때문이다. 단, 마지막 원소를 덧붙이거나 꺼내는 경우에만 해당한다. 중간에 요소 하나를 추가하거나 빼는건 시간이 오래 걸린다.
출처:


2. O(log n)
💡 **이진탐색 알고리즘에 대한 정의 및 활용 정도**
이제부터는 입력값에 따라 실행 시간이 바뀐다. 하지만 log는 N이 커진다한들 크게 커지는 것이 아니므로 견고한 편이다.
해당하는 알고리즘은 이진탐색이 이에 해당한다.이진탐색 알고리즘이란?
정렬된 리스트의 검색 범위를 줄여나가면서 검색값을 찾는 알고리즘
단점으로는 정렬된 리스트에서만 사용 가능하다는 단점이 있지만 검색이 반복될 때마다 검색 범위가 반으로 줄기 때문에 속도가 빠르다는 장점이 있습니다.
동작 방식의 순서입니다.
- 배열의 중간 값을 가져옵니다.
- 중간 값과 검색 값을 비교합니다.
- 중간 값이 검색 값과 같다면 종료합니다. (mid = key)
- 중간 값보다 검색 값이 크다면 중간값 기준 배열의 오른쪽 구간을 대상으로 탐색합니다. (mid < key)
- 중간 값보다 검색 값이 작다면 중간값 기준 배열의 왼쪽 구간을 대상으로 탐색합니다. (mid > key)
- 값을 찾거나 간격이 비어있을 때까지 반복합니다.
예시)
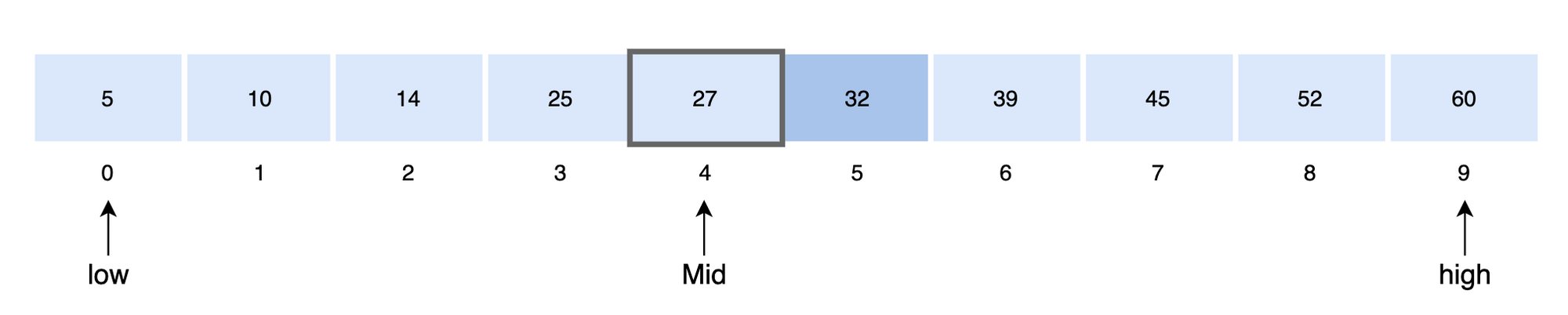
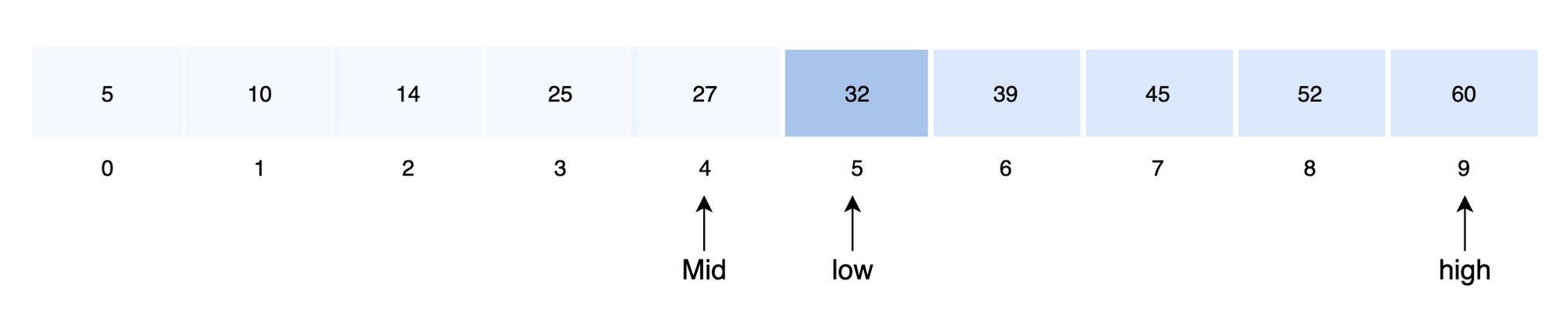
이진 탐색을 사용하여 key = 32값을 찾는 과정을 보도록 하겠습니다.
- 먼저 배열의 가운데를 결정합니다.
mid = low + (high - low) / 2
low = 0 , high = 9 (min, max 함수 활용)
- 중앙 값과 검색 값을 비교합니다.
A [4] < key 이므로 배열의 오른쪽 구간을 검색 범위로 정합니다.
low = mid + 1
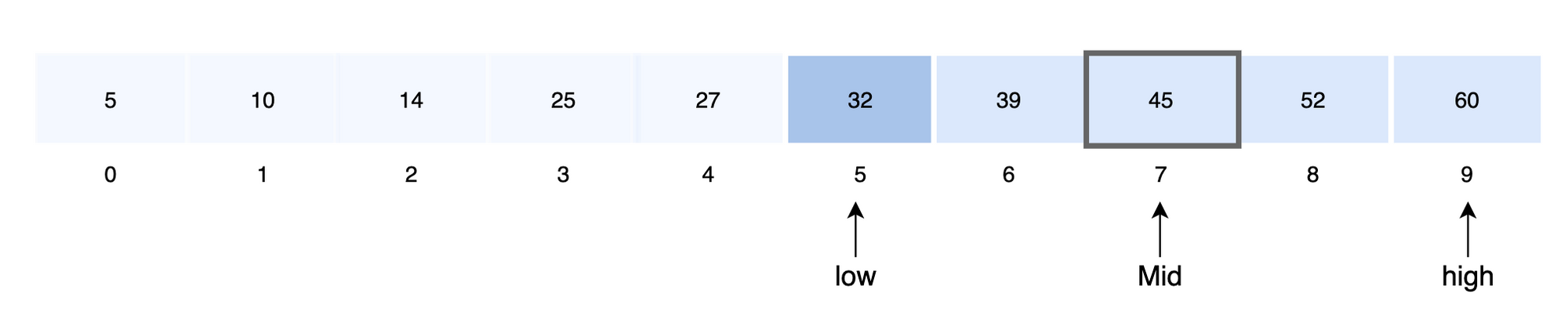
- 중앙 값을 결정합니다.
mid = 5+ (9-5)/2
- 중앙 값과 검색 값을 비교합니다.
A [7] > key 이므로 배열의 왼쪽 구간을 탐색 범위로 정합니다.
high = mid -1
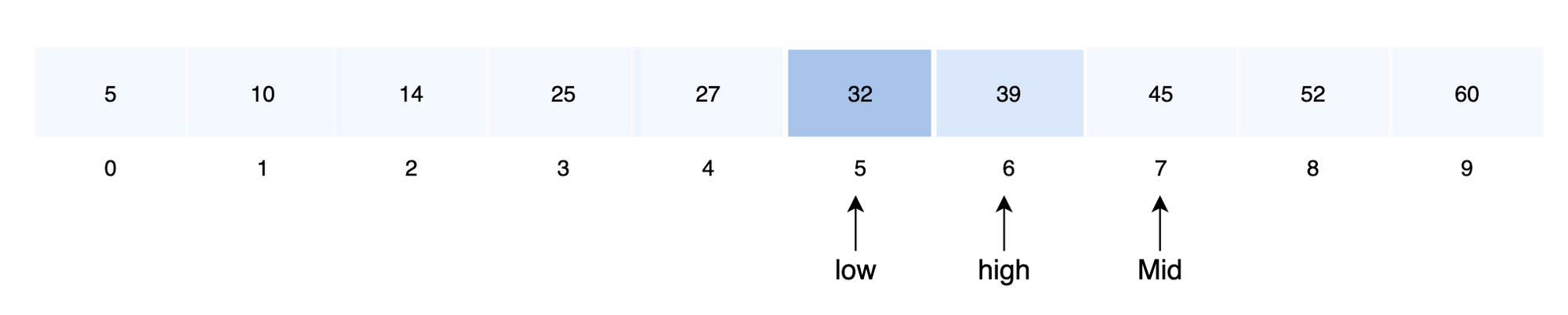
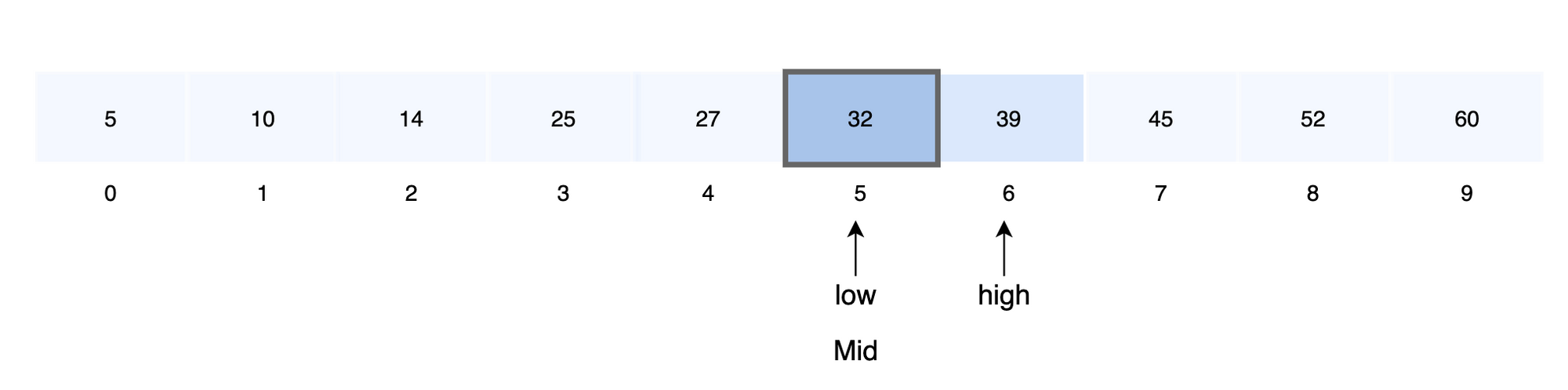
- 중앙 값을 결정합니다.
mid = 5 + (6-5)/2
- 중앙 값과 검색 값을 비교합니다.
A [5] = key 이므로 탐색을 종료합니다.
def binary_search(arr,value): first, last = 0, len(arr) while first <= last: mid = (first+last) // 2 if arr[mid] == value: return mid if arr[mid] > value: last = mid - 1 else first = mid + 1 arr = [1,2,3,4,5,6,7,8,9,10] #정렬된 리스트 result_index = binary_search(arr,6) #6에 해당하는 인덱스 값을 찾아라 print(result_index , arr[result_index]) # 5 6출처:
[Python] 이분/이진 탐색 (Binary Search)
python의 이진 탐색 모듈 : bisect
import bisect mylist = [1, 2, 3, 7, 9, 11, 33] print(bisect.bisect(mylist, 3)) # 3 ## 결과값이 index로 2가 나오는 것이 아닌 3이 나온다. # 결과값이 n이 위치한 index의 오른쪽 값을 나타낸다. #bisect 안에 bisect출처:
3. O(n)
💡 정렬되지 않은 리스트에서 최대 최솟값을 찾는 경우 (입력값을 한 번 이상 살펴보는경우)
입력값만큼 실행 시간에 영향을 받고, 이를 선형 시간 알고리즘이라고 부른다.
정렬되지 않은 리스트에서 최댓값, 최솟값을 찾는 경우가 해당하며
모든 입력값을 한 번 이상을 살펴보아야한다.선형 탐색
선형 시간 알고리즘이란?
코드의 수행시간이 입력의 크기에 정비례하는 코드로 대게 우리가 찾을 수 있는 알고리즘 중 가장 좋은 알고리즘인 경우가 많다.(입력 전체를 한번은 확인해야 한다.)
소요 시간 : O(n)
리스트의 길이에 비례하는 시간이 소요됩니다.
# 배열(=array)안에 찾고자 하는 특정 항목(=value)이 있으면 그 index값을 return, 없다면 -1을 return def linear_search(value, array): for i, item in enumerate(array): if item == value: return i return -1 value = 1 array = [5,4,3,2,1,0] linear_search(value, array) # 결과: 4 #선형 탐색은 최악의 경우 O(n)의 시간 복잡도를 갖는다. #특정 항목이 끝에 위치해 있거나, 배열에 존재하지 않을 경우 #모든 항목을 다 검사해야만 하기 때문이다. #리스트의 index()함수가 실제로 이 알고리즘을 사용하고 있다. array_1 = [3,4,5,6,7,8] print(array_1.index(3)) print(array_1.index(4)) print(array_1.index(7))출처: https://juhee-maeng.tistory.com/49
리스트의 길이가 길면 오래 걸리는 연산으로 대표적으로
원소 삽입( .insert(3,4))와 원소 삭제(.del())이 존재한다.
O(n)만큼의 시간이 걸린다.
append와 insert의 차이점
index 번호를 input 값에 넣어줘서 중간에 들어가게 한다.
4. O(n log n)
💡 **합병 정렬은?**
합병 정렬을 비롯한 대부분의 효율 좋은 정렬 알고리즘이 이에 해당하며
적어도 모든 수에 대해 한 번 이상은 비교해야하는 비교 기반의 정렬 알고리즘이다.
정렬에 있어서 이보다 빠를 수는 없으며 입력값이 최선(가장 좋을) 경우 비교를 하지 않고 O(n)이 될 수 있으며 Timsort가 이런 로직을 가지고 있다.합병 정렬
많은 정렬들 중 하나인 병합정렬은 무엇일까? 병합정렬은 비교 기반 알고리즘으로 전체 원소를 하나의 단위로 분할한 후에 분할한 원소를 다시 병합하는정렬 방식을 말한다. 병합정렬은 합병정렬, 머지정렬이라 부르기도 한다.
병합정렬의 단계를 '분할, 정복, 결합' 3가지로 나누어 볼 수 있다.분할 단계에서는 입력된 배열을 같은 크기의 2개의 부분 배열로 분할한다. 정복 단계에서는 부분 배열을 정렬한다. 여기서 부분 배열의 크기가 충분히 작지 않다면 순환 호출을 이용하여 다시 분할 정복법을 적용해준다. 결합 단계에서는 정렬된 부분 배열을 하나의 배열로 결합한다.
합병 정렬 장단점
병합정렬은 정렬시 추가적인 공간을 사용함으로써 같은 값을 가지는 원소의 상대적인 순서를 유지하는 안정정렬이라는 장점이 있다. 하지만 만약 레코드를 배열로 구성하면 임시 배열이 필요하고 레코드들의 크기가 큰 경우에는 이동 횟수가 많으므로 매우 큰 시간적 낭비를 초래한다. 그러나 만약 레코드를 연결 리스트로 구성하여 합병 정렬할 경우 링크 인덱스만 변경되므로 데이터의 이동은 무시할 수 있을만큼 작아진다. 크기가 큰 레코드를 정렬할 경우에 연결리스트를 사용한다면 병합정렬은 모든 정렬 중 가장 효율적일 수 있다.
Linked list?
여러개의 node를 연결함으로써 데이터로 표현이 가능하다.
필요한만큼 메모리를 동적 할당 받아서 만들기 때문에 오버플로우나 공간 낭비가 발생하지 않는다.
python에서 사용하는 List의 기본적인 구조는 Linked List로 파이썬에서 배열이 없는 이유는 Linked List를 기본적으로 지원하기 때문이다.
배열(Array)과의 비교
인덱스 번호와 그에 대응하는 값으로 이루어진 자료구조인
배열과 구분 해 볼 수 있습니다.데이터 엑세스 속도는 배열이 리스트보다 빠릅니다. 배열은 인덱스만 있으면 O(1)에 가능하나, 리스트는 최소 한 번은 순회를 거쳐야 하기 때문에 O(n)이 걸립니다.
데이터 삽입과 삭제 속도의 경우 리스트가 배열보다 우위에 있습니다. 리스트는 어느 곳에 삽입하던지 O(n)에 가능합니다. 반면 배열은 중간에 데이터를 삽입 삭제할 경우 기존 데이터들을 이동시켜야 하며, 처음에 지정한 크기를 넘을 경우 새롭게 메모리를 할당 해야 합니다.
병합정렬의 사용
병합정렬은 Linked List의 정렬이 필요할 때 유용하게 사용된다고 한다. LinkedList 는 삽입 및 삭제 연산에 있어, 유용하지만 접근 연산에 있어서는 유용하지 않다고 한다. 배열의 경우에는 인덱스를 통해 접근하기 때문에 시간복잡도가 O(1)이지만, LinkedList는 Head 부터 탐색해야 하기 때문에 시간 복잡도가 O(n)이다. 그래서 임의적인 접근에서는 오버헤드가 증가하게된다. 이러한 이유로 Linked List는 순차적인 접근과 같은 병합정렬을 사용하는 것이 유용하다.
→ 그냥 조회할 때는 LinkedList가 별로지만 병합정렬을 할 때는 좋다.
출처:
[ 알고리즘 공부 ] 합병 정렬(Merge Sort) 알고리즘 - 분할 정복 알고리즘(python, 파이썬)
Timsort
Timsort란 파이썬에 기본으로 탑재된 sort() 함수의 알고리즘으로 최고 O(n)의 시간 복잡도를 갖고 다양한 데이터에 적합한 정렬 알고리즘이다.
최상의 경우는 O(n)이고 공간 복잡도는 n이다.
Timsort는 두 가지 정렬 알고리즘을 섞은 것인데
Insertion과 Merge이다.Insertion sort는 왼쪽에서부터 하나하나씩 비교해봤을 때 정리를 한 후
정리가 된 것들에 있어서 쭉 정렬을 하는 것이다.
출처:

5. O(n^2)
💡 버블 정렬이란?
버블 정렬 같은 비효율적 정렬 알고리즘이 이에 해당버블 정렬
서로 인접한 두 원소를 검사하여 정렬하는 알고리즘
인접한 2개의 레코드를 비교하여 크기가 순서대로 되어 있지 않으면 서로 교환한다.
선택 정렬과 기본 개념이 유사하다.버블 정렬은 첫 번째 자료와 두 번째 자료를, 두 번째 자료와 세 번째 자료를, 세 번째와 네 번째를, … 이런 식으로 (마지막-1)번째 자료와 마지막 자료를 비교하여 교환하면서 자료를 정렬한다.
1회전을 수행하고 나면 가장 큰 자료가 맨 뒤로 이동하므로 2회전에서는 맨 끝에 있는 자료는 정렬에서 제외되고, 2회전을 수행하고 나면 끝에서 두 번째 자료까지는 정렬에서 제외된다. 이렇게 정렬을 1회전 수행할 때마다 정렬에서 제외되는 데이터가 하나씩 늘어난다.
출처:

6. O(2^n)
💡 재귀로 계산 알고리즘
피보나치 수열을 재귀로 계산하는 알고리즘이 이에 해당하며 n^2 < 2^n에 해당한다.피보나치 수열을 재귀로 계산
ex) 몇 번째 피보나치 수는 몇인가?에 대한 질문으로
피보나치 수를 표현하는 식으로 아래와 같이 정의할 수 있다.
F(1) = F(2) = 1
F(n) = F(n-1) + F(n-2)
그리고 0번째 항부터 시작할 경우는 아래와 같이 정의할 수 있다.
F(0) = 0, F(1) = 1
F(n) = F(n-1) + F(n-2)
#fibonacii for loop function (반복문 함수) # 변수 정의 count = 0 # 계산 카운트 fibo = 7 # fibonacci 7번째 값 # 함수 정의 def fibo_for(n): global count _cur, _next = 0, 1 for i in range(n): count += 1 print(f'for loop[{i}] _cur: {_cur}, _next: {_next}, count: {count}') _cur, _next = _next, _cur + _next return _cur # 결과 출력 print('-'*10+f'\nfibo_rec({fibo}): {fibo_for(fibo)} 계산에 활용된 반복 횟수는 {count}번입니다.\n'+'-'*10) print()
7. O(n!)
각 도시를 방문하고 돌아오는 가장 짧은 경로를 찾는 외판원 문제(Traveling Salesman Problem {TSP})를 브루트 포스로 풀이할 때 이에 해당함.
💡 TSPTSP 브루트 포스
외판원 순회(TSP: Traveling Salesperson Problem)란 도시들이 있고 특정 도시에서 도시로 이동할 때 드는 비용이 주어졌을 때 불특정한 도시에서 출발해서 모든 도시를 돌고 다시 출발 도시로 돌아왔을 때 드는 최소 비용을 구하는 문제입니다.
각 도시간에 이동하는데 드는 비용은 행렬 W[i][j]형태로 주어진다. W[i][j]는 도시 i에서 도시 j로 가기 위한 비용을 나타낸다. 비용은 대칭적이지 않다. 즉, W[i][j] 는 W[j][i]와 다를 수 있다. 모든 도시간의 비용은 양의 정수이다. W[i][i]는 항상 0이다. 경우에 따라서 도시 i에서 도시 j로 갈 수 없는 경우도 있으며 이럴 경우 W[i][j]=0이라고 하자.
N과 비용 행렬이 주어졌을 때, 가장 적은 비용을 들이는 외판원의 순회 여행 경로를 구하는 프로그램을 작성하시오.
import sys from itertools import permutations input = sys.stdin.readline n = int(input()) matrix = [list(map(int,input().split())) for _ in range(n)] answer = 10000000 for i in permutations(range(1,n),n-1): num_list = [*i] # 처음과 끝에 1번 도시를 넣는다 num_list = [0] + num_list + [0] sub = 0 # for else 구문을 사용하여 경로가 없을 때를 제외한다 for j in range(n) : cost = matrix[num_list[j]-1][num_list[j+1]-1] if cost == 0 : break else : sub += cost # 이미 sub가 answer 이상이면 반복문을 멈춘다 if sub > answer : break else: if answer > sub: answer = sub print(answer)
💡 **빅오의 공간 복잡도와 시간 복잡도의 관계?**
빅오는 시간 복잡도 외에도 공간 복잡도를 표현하는데도 많이 쓰인다.
알고리즘은 흔히 ‘시간과 공간을 space-time tradeoff 관계’ 라는 말을 많이 쓰인다.
→ 수행 시간이 짧으면 공간을 많이 차지하고 수행시간이 길면 공간을 적게 차지한다.
또한 빅오는 상한을 의미하며
하한을 나타내는 빅오메가,
평균을 나타내는 빅세타가 존재하는데
기업에서는 보통 빅세타와 빅오를 합쳐서 단순화하여 표현하는데 이는 최대 시간을 계산하는 빅오로 표현하는 방법이 틀리지 않기 때문에 이렇게 작성한다.
퀵 정렬을 예로 들어보자.
input = [1,4,3,7,8,6,5] 일 때,
퀵 정렬의 Lomuto Partition (피벗을 정할 때 가장 우측을 택하는 가장 단순한 피벗 선택 방식)퀵 정렬 Lomuto Partition?
퀵 정렬(quick sort) 알고리즘의 개념 요약
‘찰스 앤터니 리처드 호어(Charles Antony Richard Hoare)’가 개발한 정렬 알고리즘
퀵 정렬은 불안정 정렬 에 속하며, 다른 원소와의 비교만으로 정렬을 수행하는 비교 정렬 에 속한다.
분할 정복 알고리즘의 하나로, 평균적으로 매우 빠른 수행 속도를 자랑하는 정렬 방법
합병 정렬(merge sort)과 달리 퀵 정렬은 리스트를 비균등하게 분할한다.
분할 정복(divide and conquer) 방법
문제를 작은 2개의 문제로 분리하고 각각을 해결한 다음, 결과를 모아서 원래의 문제를 해결하는 전략이다.
분할 정복 방법은 대개 순환 호출을 이용하여 구현한다.
과정 설명
리스트 안에 있는 한 요소를 선택한다. 이렇게 고른 원소를 피벗(pivot) 이라고 한다.
피벗을 기준으로 피벗보다 작은 요소들은 모두 피벗의 왼쪽으로 옮겨지고 피벗보다 큰 요소들은 모두 피벗의 오른쪽으로 옮겨진다. (피벗을 중심으로 왼쪽: 피벗보다 작은 요소들, 오른쪽: 피벗보다 큰 요소들)
피벗을 제외한 왼쪽 리스트와 오른쪽 리스트를 다시 정렬한다.
분할된 부분 리스트에 대하여 순환 호출 을 이용하여 정렬을 반복한다.
부분 리스트에서도 다시 피벗을 정하고 피벗을 기준으로 2개의 부분 리스트로 나누는 과정을 반복한다.
부분 리스트들이 더 이상 분할이 불가능할 때까지 반복한다.
리스트의 크기가 0이나 1이 될 때까지 반복한다.
퀵 정렬(quick sort) 알고리즘의 구체적인 개념
하나의 리스트를 피벗(pivot)을 기준으로 두 개의 비균등한 크기로 분할하고 분할된 부분 리스트를 정렬한 다음, 두 개의 정렬된 부분 리스트를 합하여 전체가 정렬된 리스트가 되게 하는 방법이다.
퀵 정렬은 다음의 단계들로 이루어진다.
분할(Divide): 입력 배열을 피벗을 기준으로 비균등하게 2개의 부분 배열(피벗을 중심으로 왼쪽: 피벗보다 작은 요소들, 오른쪽: 피벗보다 큰 요소들)로 분할한다.
정복(Conquer): 부분 배열을 정렬한다. 부분 배열의 크기가 충분히 작지 않으면 순환 호출 을 이용하여 다시 분할 정복 방법을 적용한다.
결합(Combine): 정렬된 부분 배열들을 하나의 배열에 합병한다.
순환 호출이 한번 진행될 때마다 최소한 하나의 원소(피벗)는 최종적으로 위치가 정해지므로, 이 알고리즘은 반드시 끝난다는 것을 보장할 수 있다.퀵 정렬(quick sort) 알고리즘의 예제
배열에 5, 3, 8, 4, 9, 1, 6, 2, 7이 저장되어 있다고 가정하고 자료를 오름차순으로 정렬해 보자.
퀵 정렬에서 피벗을 기준으로 두 개의 리스트로 나누는 과정(c언어 코드의 partition 함수의 내용)피벗 값을 입력 리스트의 첫 번째 데이터로 하자. (다른 임의의 값이어도 상관없다.)
2개의 인덱스 변수(low, high)를 이용해서 리스트를 두 개의 부분 리스트로 나눈다.1회전: 피벗이 5인 경우,
low는 왼쪽에서 오른쪽으로 탐색해가다가 피벗보다 큰 데이터(8)을 찾으면 멈춘다.
high는 오른쪽에서 왼쪽으로 탐색해가다가 피벗보다 작은 데이터(2)를 찾으면 멈춘다.
low와 high가 가리키는 두 데이터를 서로 교환한다.
이 탐색-교환 과정은 low와 high가 엇갈릴 때까지 반복한다.2회전: 피벗(1회전의 왼쪽 부분리스트의 첫 번째 데이터)이 1인 경우,
위와 동일한 방법으로 반복한다.3회전: 피벗(1회전의 오른쪽 부분리스트의 첫 번째 데이터)이 9인 경우,
위와 동일한 방법으로 반복한다.출처 : https://gmlwjd9405.github.io/2018/05/10/algorithm-quick-sort.html
분할 상환 분석
💡 나오게 된 배경: 시간 또는 메모리 분석하는 알고리즘의 복잡도를 계산할 때, 최악의 경우만 살펴보는 것은 비관적이라는 이유로 분할 상환 분석이 나타나게 되었다.함수의 동작을 설명할 때 중요한 분석 방법 중 하나로 대표적 예시로는 ‘동적 배열’을 들 수 있는데,
동적 배열에서 더블링이 일어나는 일은 어쩌다 한 번뿐이지만, 이로 인해 ‘아이템 삽입 시간 복잡도는 O(n^2)이다’ 라고 말하는 것이 정확하지 않기 때문에 이러한 경우를 ‘분할 상환’ 또는 ‘상각’이라고 표현하는, 최악의 겨우를 여러번에 걸쳐 골고루 나눠주는 형태로 알고리즘의 시간 복잡도를 계산할 수 있다????
동적 배열 및 동적 배열 더블링
아직 작성을 못함 이 부분 더 작성해여해
3가지 분석 방식이 있지만 결과값은 똑같다.
총계 방식: O(n) / N → 빅 세터 느낌
회계 방식:
잠재 비용 방식:
링크:
병렬화
💡 병렬화의 중요성!일부 알고리즘은 병렬화로 실행 속도를 높힐 수 있다.
최근 딥러닝의 인기와 함께 병렬화가 큰 주목을 받고 있으며 GPU는 병렬 연산을 위한 대표적인 장치로
각각의 코어는 CPU보다 훨씬 더 느리지만 GPU의 코어는 수천개로 구성되어 있어 수십개에 불가한 CPU보다 훨씬 더 많은 연산을 동시에 수행할 수 있다.
즉 GPU는 CPU보다 같은 시간 대비 더 많은 연산을 진행할 수 있다.
알고리즘 자체의 시간 복잡도 외에도 병렬화가 가능한지가 알고리즘의 우수성을 평가하는 매우 중요한 척도 중 하나가 되었다.
프로세스, 쓰레드(deadlock 걸리는 4가지)
python에서는 어떻게 쓰지?
라이브러리 2개: multiproccessing, theading 공부
멀티 프로세싱 라이브러리
pool : 프로세스를 하나의 pool에다가 다 몰아주고 나눠서 일하라는 방식,
종료하는 방법은 close()
쓰레드들을 회수하는 라이브러리 join()
multiproccessing: 하나의 thead에 각각 다른 일을 부여할 수 있다.
start()로 시작하고
join()
thead
processing과 다른 점은 동기화가 진행되지 않는다.
ex) 전역변수에 각각 다른 thead가 접근하면 서로 다른 값 도출
동기화 관련된 공부
1) 크리티컬 섹션
2) 뮤 텍스
3) 세마포어
자료형
파이썬 자료형
파이썬의 자료형과 자료형의 특징을 알아보자.
list와 dictionary에 대해 중점적으로 살펴볼 예정이다.
- 숫자
파이썬에서는 숫자 정수형으로 int만 제공하며 int보다 큰 값은 자동으로 long 타입으로 변경되는 구조가 되었다.
→ 그렇기에 Overflow가 발생하는 일이 사라졌다.bool은 True와 False를 구분하는 논리 자료형이지만 파이썬에서는 내부적으로 1,0으로 처리되는 int의 서브 클래스이다.
즉 object > int > bool 의 카테고리 순이다.
- 임의 정밀도?
무제한의 자릿수를 제공하는 정수형으로 이것은 어떻게 가능한 것일까?
정수의 숫자를 배열로 간주하여 자릿수 단위로 쪼개어 배열 형태로 표현하면 가능하다!
임의 정밀도의 원리와 비스한 문제는 19장 ‘비트 조작’에서 전가산기(FUll Adder)를 응용한 문제를 풀이할 때 다룬다.물론 연산 속도는 느리겠지만 오버플로를 고민할 필요가 없어진다. 잘못된 계산 오류를 방지 가능하다.
자바의 경우 BIgInteger을 별도로 제공한다.
- 매핑
Mapping 타입은 키와 자료형으로 구성된 복합 자료형으로 유일한 내장형 매핑 자료형은 Dictionaray이다. 이후 5장에서 자세하게 설명한다.
- 집합
파이썬의 집합 자료형인 set은 중복된 값을 갖지 않는 자료혀으로 빈 집합은 다음과 같은 형태로 선언한다.
set은 입력 순서가 유지되지 않고 중복된 값이 있을 경우 하나의 값만 유지한다.
빈 집합이 아닌 값이 포함된 집합을 선언할 때는 a = {1,2,3}형태로 진행?? 딕셔너리랑 똑같은데요? → 이 점에 주의해야한다.
구분하는 방법은 쉽다. 딕셔너리는 key : value 형태이지만 집합은 값만 선언하므로 선언의 형태를 보면 금방 타입을 판단할 수 있다. 동일한 방식으로 파이썬 컴파일러는 타입 결정을 자동으로 한다.>>> a = {'a','b','c'} >>> type(a) >>> <class 'set'> >>> a = {'a' : 'A', 'b': 'B', 'c':'C'} >>> type(a) >>> <class 'dict'>
- 시퀀스
시퀀스는 수열과 같은 의미로 어떤 특정 대상의 순서가 있는 나열을 뜻한다.
순서가 있는 나열을 뜻한다.
list라는 시퀀스는 사실상 배열의 역할을 수행하고 시퀀스는 불변과 가변으로 구분되는데
str,tuple,bytes가 불변에 해당한다 → 타입을 변경할 수 없다.a에 처음에는 ‘abc’를 입력하고 그 후에 ‘def’를 넣어준다면 이는 같은 주소에서 새로 되는 것이 아닌 서로 다른 주소로 하나의 변수 a가 지정하는 것이다. 즉 하나의 str 변수에 두 가지를 할당했다면 이는 메모리 어딘가에 남아 있음을 뜻한다.
>>> a = 'abc'
원시타입
C나 JAVA 같은 대표 프로그래밍 언어들은 기본적으로 원시타입을 제공한다.
임의 정밀도와 대척점에 놓인 언어로 원시언어는 메모리에 정확하게 타입 크기만큼의 공간을 할당하고 그 공간을 오로지 값으로 채워 넣는다
만약에 배열이라면 이 그림처럼 물리 메모리에 자료형의 크기만큼 공간을 갖는 요소가 연속된 순서로 배치되는 형태가 된다. (연속적?→ 그냥 다 순서대로 메모리 할당?)
JAVA는 원시타입에 대응되는 클래스 객체를 다음과 같이 지원한다.
Integer a = new Integer(5);
이처럼 원시 타입에 대응되는 객체를 갖고 있으며 원시타입을 객체로 변환하려면 여러가지 작업 수행 가능
(문자 변환, 16진수 변환, 시프팅)과 같은 비트 조작
but 메모리 점유율이 늘어나고 계산 속도가 감소된다.
→ 객체는 편리하고 다양한 기능을 제공하기 위해 일정부분 속도와 공간을 희생하게 됨.
객체
파이썬은 모든 것이 객체이다. 크게 불변 객체와 가변 객체로 구분할 수 있다.
- 불변 객체
변수를 할당한다는 작업은 해당 객체에 참조를 한다는 의미이다.(?)
문자와 숫자는 불변 객체라는 차이점만 있으며 객체라는 것이다.>>> 10 >>> a = 10 >>> b = a >>> a = 11 a와 b는 10이 있는 주소를 가리킨다. >>> b = 11 b가 11을 가리킨다.위 코드를 보았을 때 주소는 모두 동일하다.
→ 그러면 10이 11이 되면 a,b 모두 11이 되는거?
그건 아니다 왜냐하면 문자와 숫자와 tuple는 불변 객체이므로 메모리상 ....????
- 가변 객체
list가 있고 list 안에 다른 변수가 참조하고 있을 떄, 그 변수의 값 또한 변경된다는 이야기이다.is 는 메모리 값을 비교하는 연산자 == 은 값을 비교하는 연산자문법 중 is 와 == 의 차이점
is는 is는 is는 id 값을 비교하는 함수로 객체의 id를 비교하는 것이므로 단순한 값을 비교하는 것이 아닌 정확하게 지목하고 있는 것이 동일한지 묻기 위해서 사용하는 함수이다.if a is None: pass
- 속도
numpy는 c로 만든 모듈로 내부적으로 리스트를 C의 원시 타입으로 처리하기에 처리 속도가 빠르다.이렇게 원시타입이 빠른데 왜 파이썬은 굳이 리스트랑 객체를 사용할까?
5장에서 알려준다.자료구조 vs 자료형 vs 추상 자료형
자료구조 vs 자료형 vs 추상 자료형
컴퓨터 과학에서 자료구조 : 데이터에 효율적 접근 조작하기 위한 데이터의 조직, 관리, 저장 구조를 말한다. → 흔히 이야기하는 자료구조(배열,연결리스트,객체)를 말한다
