전력망을 둘로 나누기
문1) n개의 송전탑이 전선을 통해 하나의 트리 형태로 연결되어 있습니다. 당신은 이 전선들 중 하나를 끊어서 현재의 전력망 네트워크를 2개로 분할하려고 합니다. 이때, 두 전력망이 갖게 되는 송전탑의 개수를 최대한 비슷하게 맞추고자 합니다.
송전탑의 개수 n, 그리고 전선 정보 wires가 매개변수로 주어집니다. 전선들 중 하나를 끊어서 송전탑 개수가 가능한 비슷하도록 두 전력망으로 나누었을 때, 두 전력망이 가지고 있는 송전탑 개수의 차이(절대값)를 return 하도록 solution 함수를 완성해주세요.
제한사항
- n은 2 이상 100 이하인 자연수입니다.
- wires는 길이가 n-1인 정수형 2차원 배열입니다.
- wires의 각 원소는 [v1, v2] 2개의 자연수로 이루어져 있으며, 이는 전력망의 v1번 송전탑과 v2번 송전탑이 전선으로 연결되어 있다는 것을 의미합니다.
- 1 ≤ v1 < v2 ≤ n 입니다.
- 전력망 네트워크가 하나의 트리 형태가 아닌 경우는 입력으로 주어지지 않습니다.
입출력 예
| n | wires | result |
|---|---|---|
| 9 | [[1,3],[2,3],[3,4],[4,5],[4,6],[4,7],[7,8],[7,9]] | 3 |
| 4 | [[1,2],[2,3],[3,4]] | 0 |
| 7 | [[1,2],[2,7],[3,7],[3,4],[4,5],[6,7]] | 1 |
입출력 예 설명
입출력 예 #1
다음 그림은 주어진 입력을 해결하는 방법 중 하나를 나타낸 것입니다.
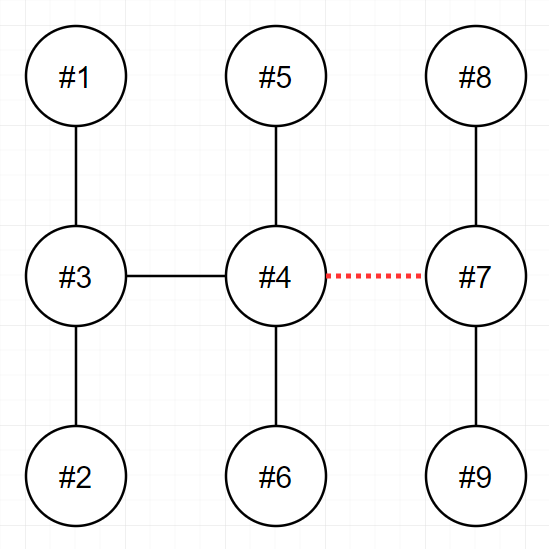
- 4번과 7번을 연결하는 전선을 끊으면 두 전력망은 각 6개와 3개의 송전탑을 가지며, 이보다 더 비슷한 개수로 전력망을 나눌 수 없습니다.
- 또 다른 방법으로는 3번과 4번을 연결하는 전선을 끊어도 최선의 정답을 도출할 수 있습니다.
입출력 예 #2
다음 그림은 주어진 입력을 해결하는 방법을 나타낸 것입니다.

- 2번과 3번을 연결하는 전선을 끊으면 두 전력망이 모두 2개의 송전탑을 가지게 되며, 이 방법이 최선입니다.
입출력 예 #3
다음 그림은 주어진 입력을 해결하는 방법을 나타낸 것입니다.

- 3번과 7번을 연결하는 전선을 끊으면 두 전력망이 각각 4개와 3개의 송전탑을 가지게 되며, 이 방법이 최선입니다.
나의 풀이
List를 사용한 방법
package programmers;
import java.util.ArrayList;
import java.util.List;
public class SplitThePowerGridInTwo {
static List<Integer>[] adjList;
static boolean[] visited;
public static int solution(int n, int[][] wires) {
int answer = Integer.MAX_VALUE;
adjList = new ArrayList[n+1];
for(int i = 1; i <= n; i++) {
adjList[i] = new ArrayList<>();
}
for (int[] wire : wires) {
int start = wire[0];
int end = wire[1];
adjList[start].add(end);
adjList[end].add(start);
}
printAdjList();
for (int i = 0; i < wires.length; i++) {
visited = new boolean[n+1];
int start = wires[i][0];
int end = wires[i][1];
adjList[start].remove((Integer)end);
adjList[end].remove((Integer)start);
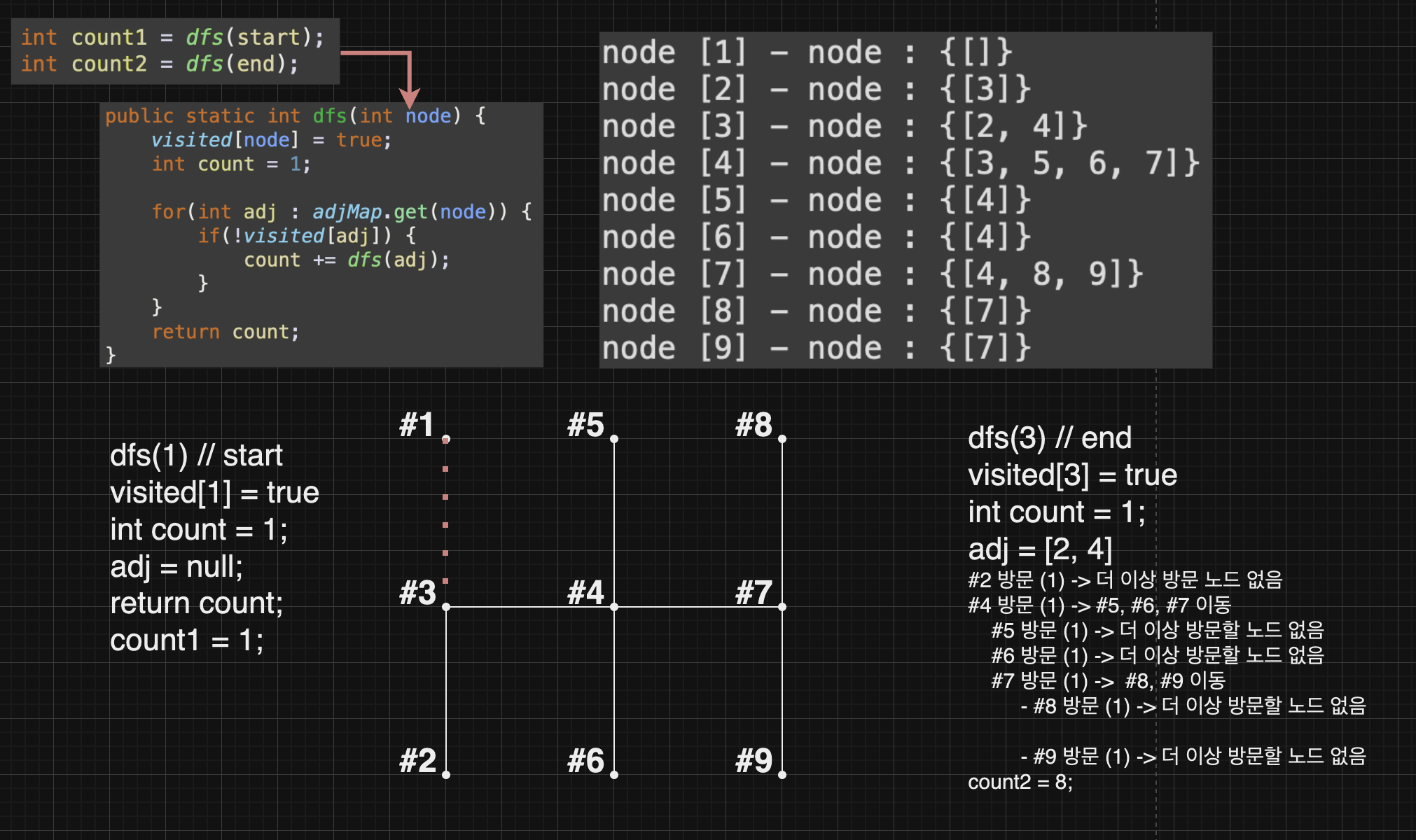
int count1 = dfs(start);
int count2 = dfs(end);
answer = Math.min(answer, Math.abs(count1 - count2));
adjList[start].add(end);
adjList[end].add(start);
}
System.out.println(answer);
return answer;
}
public static int dfs(int node) {
visited[node] = true;
int count = 1;
for(int adj : adjList[node]) {
if(!visited[adj]) {
count += dfs(adj);
}
}
return count;
}
public static void printAdjList() {
for (int i = 1; i < adjList.length; i++) {
System.out.print("Node " + i + ": ");
for (int adj : adjList[i]) {
System.out.print(adj + " ");
}
System.out.println();
}
}
public static void main(String[] args) {
int[][] wires = {{1,3},{2,3},{3,4},{4,5},{4,6},{4,7},{7,8},{7,9}};
solution(9, wires);
}
}
Map을 사용한 방법
package programmers;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class SplitThePowerGridInTwo {
static Map<Integer, List<Integer>> adjMap ;
static boolean[] visited;
public static int solution(int n, int[][] wires) {
int answer = Integer.MAX_VALUE;
adjMap = new HashMap<>();
for(int i = 1; i <= n; i++) {
adjMap.put(i, new ArrayList<>());
}
for (int[] wire : wires) {
int start = wire[0];
int end = wire[1];
adjMap.get(start).add(end);
adjMap.get(end).add(start);
}
for (int i = 0; i < wires.length; i++) {
visited = new boolean[n+1];
int start = wires[i][0];
int end = wires[i][1];
adjMap.get(start).remove((Integer) end);
adjMap.get(end).remove((Integer) start);
int count1 = dfs(start);
int count2 = dfs(end);
answer = Math.min(answer, Math.abs(count1 - count2));
adjMap.get(start).add(end);
adjMap.get(end).add(start);
}
return answer;
}
public static int dfs(int node) {
visited[node] = true;
int count = 1;
for(int adj : adjMap.get(node)) {
if(!visited[adj]) {
count += dfs(adj);
}
}
return count;
}
public static void main(String[] args) {
int[][] wires = {{1,3},{2,3},{3,4},{4,5},{4,6},{4,7},{7,8},{7,9}};
solution(9, wires);
}
}
나의 생각
이 문제를 dfs(Depth First Search)로 풀 수 있겠다라는 생각을 한 것은 전력소(node), 연결(edge)와 같은 단어와 그래프 탐색을 해야한다는 점에서 아이디어를 얻었다.
이 문제에서 DFS를 적용할 수 있는 힌트는 다음과 같다.
hint
1. 연결 그래프 : 문제에서 주어진 전력망은 연결 그래프로 간주될 수 있다. 이는 그래프 내의
모든 노드가 서로 직,간접적으로 연결되어 있다는 것을 의미한다.
2. 트리 구조 : 전력망은 사이클이 없는 연결 그래프. 즉, 트리 구조를 형성한다.
트리에서 임의의 두 노드를 연결하는 경로가 단 하나만 존재한다.
3. 엣지 제거 : 문제의 목표는 두 개의 부분으로 나누는 것이므로, 그래프의 엣지 하나를
제거하면 트리가 두 개의 분리된 서브트리로 나누게 됨
4. 서브트리의 노드 수 계산 : 각 서브트리의 노드 수를 계산하려면, 하나의 노드에서
시작하여 연결된 모든 노드를 방문하며 카운트하는 과정이 필요함
이는 DFS를 사용하여 효과적으로 수행할 수 있음접근법
1. 그래프 구축 : 주어진 전력망을 그래프로 모델링함. 노드와 엣지를 표현할 자료 구조 필요
-> List<Integer> [] adjList ;
-> Map<Integer, List<Integer>> adjMap;
2. 가능한 분할 탐색 : 모든 전선(엣지)에 대하여, 그 전선을 제거한 후 두개의 서브트리가
형성되느지 확인, 이는 두 서브트리로 그래프가 분할되었음을 의미함
3. 서브트리 크기 계산 : 각 서브트리에 대해 DFS를 실행하여 서브트리의 크기를 계산
4. 최소 차이 계산 : 모든 가능한 분할에 대해 두 서브트리의 크기 차이를 계산하고
가장 작은 차이를 찾음
5. 복원 및 반복 : 한 전선을 제거하고 계산을 마친 후, 그래프를 원래 상태로 복원하고 다음
전선에 대해 반복함주요 로직
int answer = Integer.MAX_VALUE; //최소값을 찾는 문제이므로 Integer로 표현가능한 최대 값으로 설정
adjMap = new HashMap<>(); // 현재 adjMap은 글로벌 멤버 변수로 선언만 된 상태
// 따라서 객체를 생성 및 초기화를 해주어야함
for(int i = 1; i <= n; i++) { // adjMap은 value값이 List형태로 존재하기때문
adjMap.put(i, new ArrayList<>()); // key에 해당하는 리스트 객체를 생성 및 초기화 해주어야함
}
for (int[] wire : wires) { // 매개변수로 주어진 wire(edge)를 순환
int start = wire[0];
int end = wire[1];
adjMap.get(start).add(end);
adjMap.get(end).add(start);
}
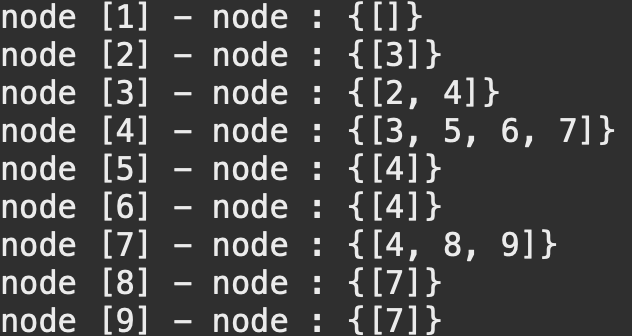
adjMap에 저장된 key, value 형태
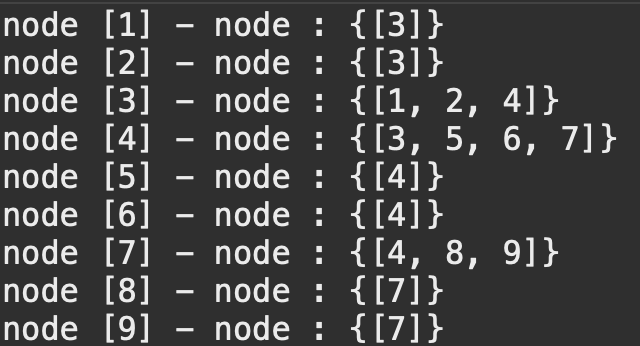
연결된 노드 제거하기
start : 1 ⌿ end : 3
for (int i = 0; i < wires.length; i++) {
visited = new boolean[n+1];
int start = wires[i][0]; // 1
int end = wires[i][1]; // 3
adjMap.get(start).remove((Integer) end); // adjMap key : 1에 해당하는 value(3)을 제거
adjMap.get(end).remove((Integer) start); // adjMap key : 3에 해당하는 value(1)을 제거
int count1 = dfs(start);
int count2 = dfs(end);
answer = Math.min(answer, Math.abs(count1 - count2));
adjMap.get(start).add(end);
adjMap.get(end).add(start);
}
list.remove(end)(✕) 👉🏻list.remove((Integer)end)(❍)
remove()안에 명시적 형변환을 하는 이유
remove(int index) - 인덱스에 잇는 요소를 제거
remove(Object o) - 주어진 객체를 찾아 제거
여기서 end는 int 타입이므로, remove(int index) 메서드가 호출되어 인덱스로 해석되고,
결과적으로 예상치 못한 요소가 제거될 수 있음. 우리가 원하는 것은 특정 값 end를 가진 객체를
제거하는 것이므로 Integer 객체로 명시적으로 변환함으로써 remove(Object o) 메서드를
호출하도록 해야함start : 1 , end : 3 일때의 로직



따라서 모든 start , end 점을 dfs() 하여 최소값을 찾는다.
방금 그 곡
문2) 라디오를 자주 듣는 네오는 라디오에서 방금 나왔던 음악이 무슨 음악인지 궁금해질 때가 많다. 그럴 때 네오는 다음 포털의 '방금그곡' 서비스를 이용하곤 한다. 방금그곡에서는 TV, 라디오 등에서 나온 음악에 관해 제목 등의 정보를 제공하는 서비스이다.
네오는 자신이 기억한 멜로디를 가지고 방금그곡을 이용해 음악을 찾는다. 그런데 라디오 방송에서는 한 음악을 반복해서 재생할 때도 있어서 네오가 기억하고 있는 멜로디는 음악 끝부분과 처음 부분이 이어서 재생된 멜로디일 수도 있다. 반대로, 한 음악을 중간에 끊을 경우 원본 음악에는 네오가 기억한 멜로디가 들어있다 해도 그 곡이 네오가 들은 곡이 아닐 수도 있다. 그렇기 때문에 네오는 기억한 멜로디를 재생 시간과 제공된 악보를 직접 보면서 비교하려고 한다. 다음과 같은 가정을 할 때 네오가 찾으려는 음악의 제목을 구하여라.
- 방금그곡 서비스에서는 음악 제목, 재생이 시작되고 끝난 시각, 악보를 제공한다.
- 네오가 기억한 멜로디와 악보에 사용되는 음은 C, C#, D, D#, E, F, F#, G, G#, A, A#, B 12개이다.
- 각 음은 1분에 1개씩 재생된다. 음악은 반드시 처음부터 재생되며 음악 길이보다 재생된 시간이 길 때는 음악이 끊김 없이 처음부터 반복해서 재생된다. 음악 길이보다 재생된 시간이 짧을 때는 처음부터 재생 시간만큼만 재생된다.
- 음악이 00:00를 넘겨서까지 재생되는 일은 없다.
- 조건이 일치하는 음악이 여러 개일 때에는 라디오에서 재생된 시간이 제일 긴 음악 제목을 반환한다. 재생된 시간도 같을 경우 먼저 입력된 음악 제목을 반환한다.
- 조건이 일치하는 음악이 없을 때에는 “(None)”을 반환한다.
입력 형식
입력으로 네오가 기억한 멜로디를 담은 문자열 m과 방송된 곡의 정보를 담고 있는 배열 musicinfos가 주어진다.
- m은 음 1개 이상 1439개 이하로 구성되어 있다.
- musicinfos는 100개 이하의 곡 정보를 담고 있는 배열로, 각각의 곡 정보는 음악이 시작한 시각, 끝난 시각, 음악 제목, 악보 정보가 ','로 구분된 문자열이다.
- 음악의 시작 시각과 끝난 시각은 24시간 HH:MM 형식이다.
- 음악 제목은 ',' 이외의 출력 가능한 문자로 표현된 길이 1 이상 64 이하의 문자열이다.
- 악보 정보는 음 1개 이상 1439개 이하로 구성되어 있다.
출력 형식
조건과 일치하는 음악 제목을 출력한다.
입출력 예
| m | musicinfos | answer |
|---|---|---|
| "ABCDEFG" | ["12:00,12:14,HELLO,CDEFGAB", "13:00,13:05,WORLD,ABCDEF"] | "HELLO" |
| "CC#BCC#BCC#BCC#B" | ["03:00,03:30,FOO,CC#B", "04:00,04:08,BAR,CC#BCC#BCC#B"] | "FOO" |
| "ABC" | ["12:00,12:14,HELLO,C#DEFGAB", "13:00,13:05,WORLD,ABCDEF"] | "WORLD" |
나의 풀이
package programmers;
import java.time.Duration;
import java.time.LocalTime;
public class ThatSongJustNow {
public static String solution(String m, String[] musicinfos) {
String answer = "(None)";
int maxDuration = 0;
m = m.replaceAll("A#", "a")
.replaceAll("B#", "b")
.replaceAll("C#", "c")
.replaceAll("D#", "d")
.replaceAll("E#", "e")
.replaceAll("F#", "f")
.replaceAll("G#", "g");
for(String info : musicinfos) {
String[] parts = info.split(",");
LocalTime startTime = LocalTime.parse(parts[0]);
LocalTime endTime = LocalTime.parse(parts[1]);
Duration duration = Duration.between(startTime, endTime);
int playTime = (int)duration.toMinutes();
String sheetMusic = parts[3].replaceAll("A#", "a")
.replaceAll("B#", "b")
.replaceAll("C#", "c")
.replaceAll("D#", "d")
.replaceAll("E#", "e")
.replaceAll("F#", "f")
.replaceAll("G#", "g");
StringBuilder fullSheetMusic = new StringBuilder();
for(int i = 0; i < playTime; i++) {
fullSheetMusic.append(sheetMusic.charAt(i % sheetMusic.length()));
}
if (fullSheetMusic.toString().contains(m) && playTime > maxDuration) {
answer = parts[2];
maxDuration = playTime;
}
}
System.out.println(answer);
return answer;
}
public static void main(String[] args) {
String[] musicinfos = {"12:00,12:14,HELLO,CDEFGAB", "13:00,13:05,WORLD,ABCDEF"};
solution("ABCDEFG", musicinfos);
}
}
나의 생각
문제를 읽으면서 중요한 점을 짚어보았다.
네오가 기억한 melody = {C, C#, D, D#, E, F, F#, G, G#, A, A#, B};
재생 시간 playTime
조건이 일치하는 음악이 여러 개일 경우 재생된 시간이 제일 긴 음악 제목을 반환
재생된 시간도 같을 경우 먼저 입력된 음악 제목을 반환
조건이 일치하는 음악이 없을 때는 "(None)"을 반환
- 이때 매개변수로 주어지는 네오의 멜로디 (
m)에서#문자가 포함되면 소문자 알파벳으로 임의로 치환
m = m.replaceAll("A#", "a")
.replaceAll("B#", "b")
.replaceAll("C#", "c")
.replaceAll("D#", "d")
.replaceAll("E#", "e")
.replaceAll("F#", "f")
.replaceAll("G#", "g");정확하게 변환하자면 A#,C#,D#,F#,G# 만 변환해도 상관은 없음


playTime은 어떻게 체크할 것인가??

문자열 musicinfos에서 첫번째, 두번째에 존재하는 값이 시간이며, 이 두 값의 차이가 playTime이 된다.
Java에선 LocalTime, Duration 클래스가 존재하며, 이를 사용하면 내가 원하는 값으로 표현이 가능하다.
String[] parts = info.split(",");
LocalTime startTime = LocalTime.parse(parts[0]);
LocalTime endTime = LocalTime.parse(parts[1]);
Duration duration = Duration.between(startTime, endTime);
int playTime = (int)duration.toMinutes(); 12:14 - 12:00 = 14(분)

따라서 내가 원하는 playTime을 구할 수 있다.
- playTime의 길이만큼
melody와 악보정보sheet를 반복하여 이 두 값을 비교한다.
이때, 악보정보sheet와melody를 비교하여 일치하는 정보가 많은 곳을 제목으로 반환한다.
String sheetMusic = parts[3].replaceAll("A#", "a")
.replaceAll("B#", "b")
.replaceAll("C#", "c")
.replaceAll("D#", "d")
.replaceAll("E#", "e")
.replaceAll("F#", "f")
.replaceAll("G#", "g");
StringBuilder fullSheetMusic = new StringBuilder();
for(int i = 0; i < playTime; i++) {
fullSheetMusic.append(sheetMusic.charAt(i % sheetMusic.length()));
}
if (fullSheetMusic.toString().contains(m) && playTime > maxDuration) {
answer = parts[2];
maxDuration = playTime;
}악보 정보 sheet도 #을 검출하여 소문자로 변환한다.
악보 정보 sheet의 길이가 CDEFGAB(7), playTime 14라면
CDEFGABCDEFGAB // playTime만큼 악보를 반복해야한다.
만약, 악보 정보 sheet의 길이가 CDEFGAB(7), playTime이 5라면
CDEFG를 기억하고, 나머지 정보는 짜른다.
이를 위해서 악보의 값을 반복할 수 있도록 로직을 구성해야한다.
for(int i = 0; i < playTime; i++) {
fullSheetMusic.append(sheetMusic.charAt(i % sheetMusic.length()));
}i % sheetMusic.length() 를 쓰면 배열 크기 14 안에 sheetMusic의 문자를 반복하여 넣을 수 있다.
- 가지고 있는 악보 정보와 네오가 가지고 있는 melody를 비교 & 재생 시간이 긴 것을 판별하여 answer 반환
if (fullSheetMusic.toString().contains(m) && playTime > maxDuration) {
answer = parts[2];
maxDuration = playTime;
}
위 그림을 보면 1번 값이 일치함을 알 수 있다.
1. CDEFGABCDEFGAB
ABCDEFG (일치)
2. ABCDEF
ABCDEFG (불일치)
만약 1,2번 값이 둘 다 일치할 경우 playTime을 비교하여 시간이 긴 값을 반환한다.배달
문3) N개의 마을로 이루어진 나라가 있습니다. 이 나라의 각 마을에는 1부터 N까지의 번호가 각각 하나씩 부여되어 있습니다. 각 마을은 양방향으로 통행할 수 있는 도로로 연결되어 있는데, 서로 다른 마을 간에 이동할 때는 이 도로를 지나야 합니다. 도로를 지날 때 걸리는 시간은 도로별로 다릅니다. 현재 1번 마을에 있는 음식점에서 각 마을로 음식 배달을 하려고 합니다. 각 마을로부터 음식 주문을 받으려고 하는데, N개의 마을 중에서 K 시간 이하로 배달이 가능한 마을에서만 주문을 받으려고 합니다. 다음은 N = 5, K = 3인 경우의 예시입니다.

위 그림에서 1번 마을에 있는 음식점은 [1, 2, 4, 5] 번 마을까지는 3 이하의 시간에 배달할 수 있습니다. 그러나 3번 마을까지는 3시간 이내로 배달할 수 있는 경로가 없으므로 3번 마을에서는 주문을 받지 않습니다. 따라서 1번 마을에 있는 음식점이 배달 주문을 받을 수 있는 마을은 4개가 됩니다.
마을의 개수 N, 각 마을을 연결하는 도로의 정보 road, 음식 배달이 가능한 시간 K가 매개변수로 주어질 때, 음식 주문을 받을 수 있는 마을의 개수를 return 하도록 solution 함수를 완성해주세요.
제한사항
- 마을의 개수 N은 1 이상 50 이하의 자연수입니다.
- road의 길이(도로 정보의 개수)는 1 이상 2,000 이하입니다.
- road의 각 원소는 마을을 연결하고 있는 각 도로의 정보를 나타냅니다.
- road는 길이가 3인 배열이며, 순서대로 (a, b, c)를 나타냅니다.
- a, b(1 ≤ a, b ≤ N, a != b)는 도로가 연결하는 두 마을의 번호이며, c(1 ≤ c ≤ 10,000, c는 자연수)는 도로를 지나는데 걸리는 시간입니다.
- 두 마을 a, b를 연결하는 도로는 여러 개가 있을 수 있습니다.
- 한 도로의 정보가 여러 번 중복해서 주어지지 않습니다.
- K는 음식 배달이 가능한 시간을 나타내며, 1 이상 500,000 이하입니다.
- 임의의 두 마을간에 항상 이동 가능한 경로가 존재합니다.
- 1번 마을에 있는 음식점이 K 이하의 시간에 배달이 가능한 마을의 개수를 return 하면 됩니다.
입출력 예
| N | road | K | result |
|---|---|---|---|
| 5 | [[1,2,1],[2,3,3],[5,2,2],[1,4,2],[5,3,1],[5,4,2]] | 3 | 4 |
| 6 | [[1,2,1],[1,3,2],[2,3,2],[3,4,3],[3,5,2],[3,5,3],[5,6,1]] | 4 | 4 |
입출력 예 설명
입출력 예 #2
주어진 마을과 도로의 모양은 아래 그림과 같습니다.

1번 마을에서 배달에 4시간 이하가 걸리는 마을은 [1, 2, 3, 5] 4개이므로 4를 return 합니다.
나의 풀이
package programmers;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Comparator;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.PriorityQueue;
public class Delivery {
static Map<Integer, List<int[]>> graph;
static int[] dist;
static boolean[] visited;
public static void dijkstra(int start) {
PriorityQueue<int[]> pq = new PriorityQueue<>(Comparator.comparing(a -> a[1]));
pq.offer(new int[] {start, 0});
Arrays.fill(dist, Integer.MAX_VALUE);
dist[start] = 0;
while(!pq.isEmpty()) {
int[] current = pq.poll();
int currentNode = current[0];
int currentDistance = current[1];
if(dist[currentNode] < currentDistance) continue;
List<int[]> neighbors = graph.getOrDefault(currentNode, new ArrayList<>());
for(int[] neighbor : neighbors) {
int nextNode = neighbor[0];
int nextDistance = currentDistance + neighbor[1];
if (nextDistance < dist[nextNode]) {
dist[nextNode] = nextDistance;
pq.offer(new int[]{nextNode, nextDistance});
}
}
}
}
public static int solution(int N, int[][] road, int K) {
graph = new HashMap<>();
dist = new int[N+1];
for(int[] edge : road) {
int start = edge[0];
int end = edge[1];
int distance = edge[2];
graph.computeIfAbsent(start, k -> new ArrayList<>()).add(new int[] {end, distance});
graph.computeIfAbsent(end, k -> new ArrayList<>()).add(new int[] {start, distance});
}
dijkstra(1);
int answer = 0;
for (int i = 1; i <= N; i++) {
if (dist[i] <= K) answer++;
}
return answer;
}
public static void main(String[] args) {
int[][] road = {{1,2,1},{2,3,3},{5,2,2},{1,4,2},{5,3,1},{5,4,2}};
solution(5, road, 3);
}
}
나의 생각
| 기준 | BFS | DFS | 다익스트라 알고리즘 |
|---|---|---|---|
| 가중치 유무 | 모든 간선의 가중치가 동일(없거나 모두 1) | 가중치 고려하지 않음 | 간선마다 다양한 가중치 존재 |
| 탐색 방식 | 레벨 별 탐색 (가장 가까운 노드부터) | 깊이 우선 (가능한 멀리까지 탐색) | 최소 가중치를 가진 노드를 우선 탐색 |
| 구조 | 큐(Queue) 사용, FIFO 구조 | 스택(Stack) 사용, LIFO 구조 또는 재귀 호출 | 우선순위 큐(Priority Queue) 사용, 최소 거리 노드 우선 |
| 최단 경로 | 가중치가 없는 그래프에서 최단 경로 발견 가능 | 최단 경로 보장 안 함 | 가중치가 있는 그래프에서 최단 경로 발견 가능 |
| 순회 | 레벨별로 모든 노드 순회 | 한 경로를 끝까지 탐색한 후 다른 경로 탐색 | 모든 노드를 거리에 따라 순회 |
| 시간 복잡도 | O(V+E) | O(V+E) | O((V+E)logV) (힙을 사용하는 경우) |
| 공간 복잡도 | O(V) | O(V) (재귀 호출 시에는 O(V)만큼의 함수 호출 스택이 추가됨) | O(V) |
| 사용 예 | 최소 이동 횟수로 모든 지점 방문 필요한 경우 (예: 미로 탐색) | 모든 가능한 경로 탐색 필요한 경우 (예: 퍼즐 문제) | 최소 비용 경로 탐색 필요한 경우 (예: 도로 네트워크에서의 경로 찾기) |
위 로직의 경우 BFS 또는 다익스트라 알고리즘 으로 문제를 해결할 수 있는데, 위 표를 보면 알 수 있듯이, 가중치가 있는 최단 경로같은 경우 다익스트라 알고리즘으로 문제를 해결하는것이 좋다고 생각했다.
- 그래프 (graph) 구축
graph해시맵은 시작점을 key로, 도착점과 거리르 배열로 하는 리스트를 값으로 가진다.road배열의 각 edge를 반복하여graph를 구축한다.- 예 : 마을1에서 시작하는 엣지는
{2,1}과{4,2}이다.
- 다익스트라 알고리즘 초기화
dist배열을 무한대Integer.MAX_VALUE로 설정- 시작점인 마을1의
dist값을 0으로 설정 - 우선순위 큐 (
PriorityQueue)에는 시작점인 마을1과 거리0을 배열로 해서 삽입
- 알고리즘 실행
- 우선순위 큐가 비어있지 않은 동안 다음을 반복
- 현재노드(
currentNode)와 현재 거리(currentDistance)를 큐에서 꺼냄
-graph에서 현재 노드의 이웃을 조회함 - 이웃 노드까지의 새로운 거리 (
nextDistance)를 계산 - 새 거리가 현재
dist배열에 저장된 거리보다 작으면dist배열을 업데이트하고, 이웃 노드와 새 거리를 우선순위 큐에 추가함
- 거리 업데이트
- 예를 들어, 마을1에서 마을2로 가는 경로는 거리가 1이다. 따라서 마을2의
dist[2]는 1이 된다. - 마을2에서 마을3으로 가는 경로는 거리가 3이다. 따라서 마을3의
dist[3]은dist[2] + 3 = 4가 된다. - 마을5에서 마을2로 가는 경로는 거리가 2이다. 만약 마을1에서 마을5를 거쳐 마을2로 가는 거리 (
dist[5] + 2)가 기존의dist[2]보다 작다면,dist[2]를 업데이트함
- 결과 계산
- 다익스트라 알고리즘이 완료되면,
dist배열은 각 마을까지의 최단 거리를 포함하게 된다.
1. 초기화 단계
- 시작할 때 dist[] 배열은 모두 index가 무한대 (Integer.MAX_VALUE)로 설정
- 시작 노드 1에 대해 dist[1] = 0으로 설정
2. 첫 번째 노드에서의 처리 ( currentNode: 1, currentDistance: 0 )
- 마을1에서 출발하여 이웃 마을로의 거리를 업데이트함
- 마을2로의 거리는 1( nextDistance: 1), 따라서 dist[2] = 1로 설정
- 마을4로의 거리는 2( nextDistance: 2), 따라서 dist[4] = 2로 설정
3. 두 번째 노드에서의 처리 ( currentNode: 2, currentDistance: 1)
- 마을2에서 출발하는 경로를 탐색
- 마을3로의 거리는 현재 마을2까지의 거리 1에 마을2에서 마을3까지의 거리 3을 더한 4
(nextDistance: 4), dist[3] = 4로 설정
- 마을5로의 거리는 현재 마을2까지의 거리 1에 마을2에서 마을5까지의 거리 2를 더한 3
(nextDistance: 3), dist[5] = 3로 설정
4. 네 번째 노드에서의 처리 ( currentNode: 4, currentDistance: 2)
- 마을4에서 다른 마을로 가는 경로를 검사함
- 이미 dist[1] = 0이고, 마을4에서 마을1로 돌아가는 경로는 고려할 필요가 없음
- 마을5로 가는 경로 (nextDistance: 4)는 이미 dist[5] = 3으로 더 짧아
업데이트하지 않음
5. 다섯 번째 노드에서의 처리 ( currentNode: 5, currentDistance: 3)
- 마을5에서 마을 2,3,4로 가는 경로를 검사함
- 마을2로의 거리는 dist[2] = 1로 이미 더 짧음
- 마을3으로의 거리(nextDistance: 4)는 dist[3] = 4와 같으므로 업데이트 하지 않음
- 마을4로의 거리 (nextDistance: 5)는 dist[4] = 2로 이미 더 짧아 업데이트 하지 않음
6. 세 번째 노드에서의 처리 ( currentNode: 3, currentDistance: 4)
- 마을3에서 마을2,5로 가는 경로는 이미 dist배열에 더 짧은 경로가 있으므로 업데이트 하지 않음
결과적으로 dist[] 배열은 {무한대, 0,1,4,2,3}이 된다. (배열의 0번 인덱스는 사용하지 않음)리코쳇 로봇
문4) 리코쳇 로봇이라는 보드게임이 있습니다.
이 보드게임은 격자모양 게임판 위에서 말을 움직이는 게임으로, 시작 위치에서 목표 위치까지 최소 몇 번만에 도달할 수 있는지 말하는 게임입니다.
이 게임에서 말의 움직임은 상, 하, 좌, 우 4방향 중 하나를 선택해서 게임판 위의 장애물이나 맨 끝에 부딪힐 때까지 미끄러져 이동하는 것을 한 번의 이동으로 칩니다.
다음은 보드게임판을 나타낸 예시입니다.
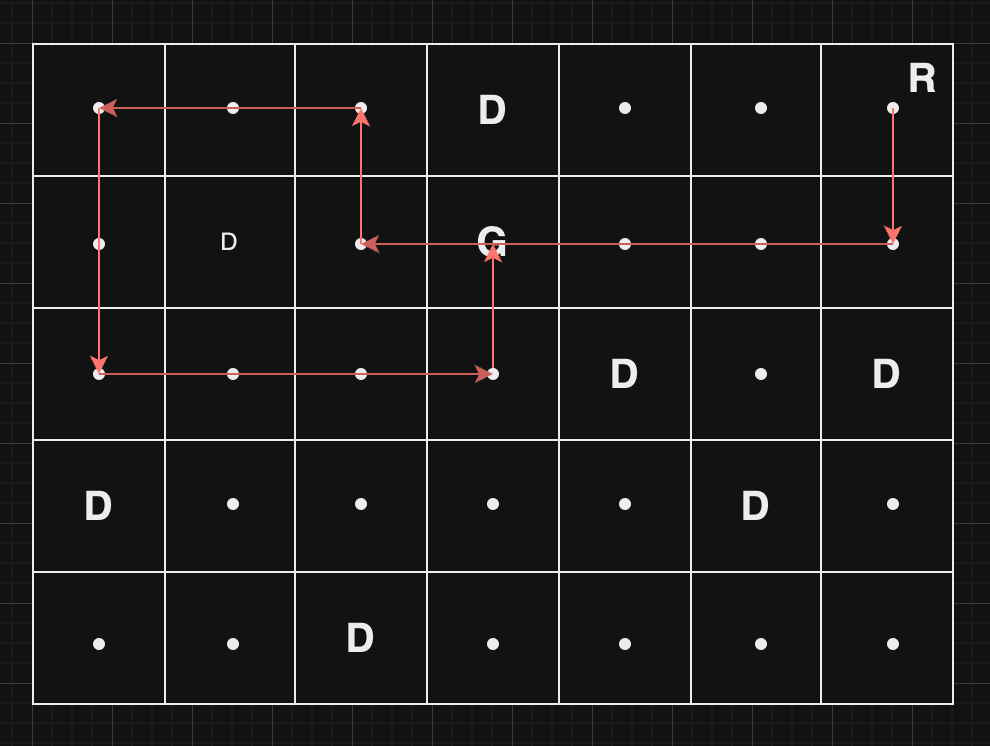
...D..R
.D.G...
....D.D
D....D.
..D....여기서 "."은 빈 공간을, "R"은 로봇의 처음 위치를, "D"는 장애물의 위치를, "G"는 목표지점을 나타냅니다.
위 예시에서는 "R" 위치에서 아래, 왼쪽, 위, 왼쪽, 아래, 오른쪽, 위 순서로 움직이면 7번 만에 "G" 위치에 멈춰 설 수 있으며, 이것이 최소 움직임 중 하나입니다.
게임판의 상태를 나타내는 문자열 배열 board가 주어졌을 때, 말이 목표위치에 도달하는데 최소 몇 번 이동해야 하는지 return 하는 solution함수를 완성하세요. 만약 목표위치에 도달할 수 없다면 -1을 return 해주세요.
제한 사항
- 3 ≤ board의 길이 ≤ 100
- 3 ≤ board의 원소의 길이 ≤ 100
- board의 원소의 길이는 모두 동일합니다.
- 문자열은 ".", "D", "R", "G"로만 구성되어 있으며 각각 빈 공간, 장애물, 로봇의 처음 위치, 목표 지점을 나타냅니다.
- "R"과 "G"는 한 번씩 등장합니다.
입출력 예
| board | result |
|---|---|
["...D..R", ".D.G...", "....D.D", "D....D.", "..D...."] | 7 |
[".D.R", "....", ".G..", "...D"] | -1 |
입출력 예 설명
입출력 예 #1
입출력 예 #2
.D.R
....
.G..
...D- "R" 위치에 있는 말을 어떻게 움직여도 "G" 에 도달시킬 수 없습니다.
- 따라서 -1을 return 합니다.
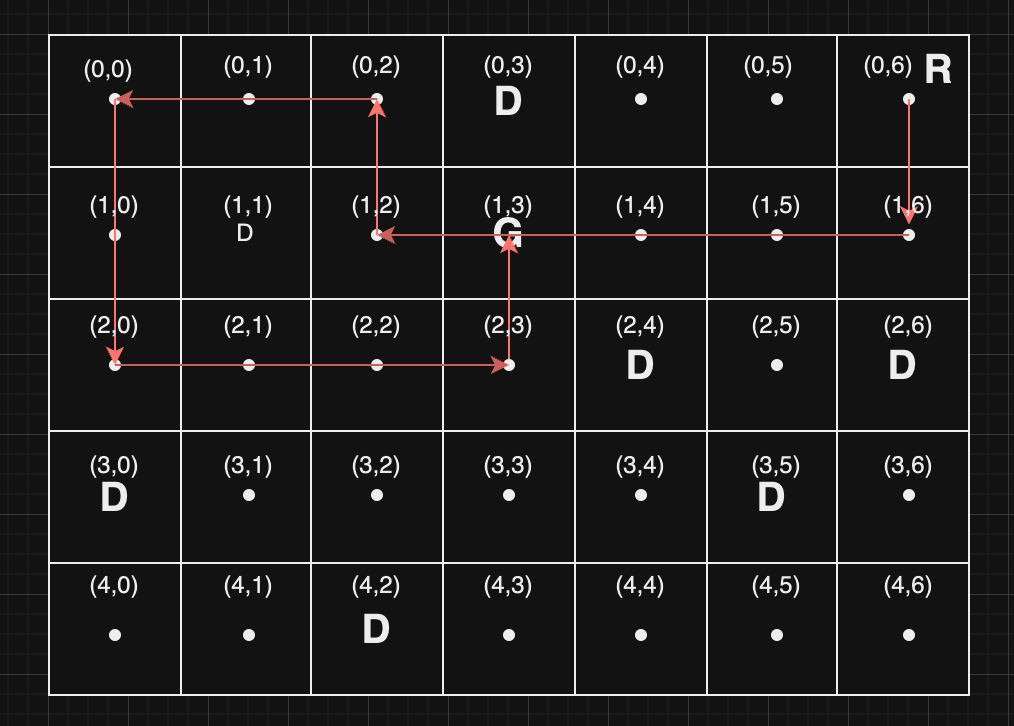
나의 풀이
package programmers;
import java.util.LinkedList;
import java.util.Queue;
public class RicochetRobot {
static int N,M;
static char[][] map;
static int[][] DIRS = {{-1,0},{1,0},{0,-1},{0,1}};
static boolean[][] visited;
static int[] start;
static int[] end;
static class Node {
int x, y, moves;
public Node(int x, int y, int moves) {
this.x = x;
this.y = y;
this.moves = moves;
}
}
public static int bfs(Node start) {
Queue<Node> queue = new LinkedList<>();
queue.add(start);
visited[start.x][start.y] = true;
while(!queue.isEmpty()) {
Node node = queue.poll();
if(node.x == end[0] && node.y == end[1]) {
return node.moves;
}
for(int[] dir : DIRS) {
int coorX = node.x;
int coorY = node.y;
int moves = node.moves;
boolean moved = false;
while (canMove(coorX + dir[0], coorY + dir[1])) {
moved = true;
coorX += dir[0];
coorY += dir[1];
}
if (moved && !visited[coorX][coorY]) {
visited[coorX][coorY] = true;
queue.add(new Node(coorX, coorY, moves + 1));
}
}
}
return -1;
}
public static boolean canMove(int x, int y) {
return x >= 0 && y >= 0 && x < N && y < M && map[x][y] != 'D';
}
public static int solution(String[] board) {
N = board.length;
M = board[0].length();
map = new char[N][M];
visited = new boolean[N][M];
start = new int[2];
end = new int[2];
for (int i = 0; i < N; i++) {
map[i] = board[i].toCharArray();
for (int j = 0; j < M; j++) {
if (map[i][j] == 'R') {
start = new int[] {i, j};
}else if (map[i][j] == 'G') {
end = new int[] {i, j};
}
}
}
int answer = bfs(new Node(start[0], start[1], 0));
System.out.println(answer);
return answer;
}
public static void main(String[] args) {
String[] board = {"...D..R", ".D.G...", "....D.D", "D....D.", "..D...."};
solution(board);
}
}
나의 생각
처음 작성한 로직
import java.util.Arrays;
import java.util.LinkedList;
import java.util.Queue;
public class RicochetRobot {
static int N,M;
static char[][] map;
static int[][] DIRS = {{-1,0},{1,0},{0,-1},{0,1}};
static boolean[][] visited;
static int[] start;
public static int bfs(int[] start) {
Queue<int[]> queue = new LinkedList<>();
int x = start[0];
int y = start[1];
queue.add(new int[] {x,y});
visited[x][y] = true;
while(!queue.isEmpty()) {
int[] a = queue.poll();
for(int[] dir : DIRS) {
int coorX = a[0] + dir[0];
int coorY = a[1] + dir[1];
if(coorX >= 0 && coorY >= 0 && coorX < N && coorY < M) {
if(!visited[coorX][coorY] && !(map[coorX][coorY] == 'D')) {
visited[coorX][coorY] = true;
queue.add(new int[] {coorX, coorY});
for(int[] b : queue) {
System.out.println(Arrays.toString(b));
}
}
}
}
System.out.println();
}
return 0;
}
public static int solution(String[] board) {
int answer = 0;
N = board.length;
M = board[0].length();
//System.out.printf("N: %d, M: %d\n",N,M);
map = new char[N][M];
visited = new boolean[N][M];
for(int i = 0; i < N; i++) {
for(int j = 0; j < M; j++) {
map[i][j] = board[i].charAt(j);
}
}
for(int i = 0; i < N; i++) {
for(int j = 0; j < M; j++) {
if(map[i][j] == 'R') {
start = new int[] {i,j};
}
}
}
bfs(start);
return answer;
}
public static void main(String[] args) {
String[] board = {"...D..R", ".D.G...", "....D.D", "D....D.", "..D...."};
solution(board);
}
}광물캐기
문5) 마인은 곡괭이로 광산에서 광석을 캐려고 합니다. 마인은 다이아몬드 곡괭이, 철 곡괭이, 돌 곡괭이를 각각 0개에서 5개까지 가지고 있으며, 곡괭이로 광물을 캘 때는 피로도가 소모됩니다. 각 곡괭이로 광물을 캘 때의 피로도는 아래 표와 같습니다.

예를 들어, 철 곡괭이는 다이아몬드를 캘 때 피로도 5가 소모되며, 철과 돌을 캘때는 피로도가 1씩 소모됩니다. 각 곡괭이는 종류에 상관없이 광물 5개를 캔 후에는 더 이상 사용할 수 없습니다.
마인은 다음과 같은 규칙을 지키면서 최소한의 피로도로 광물을 캐려고 합니다.
- 사용할 수 있는 곡괭이중 아무거나 하나를 선택해 광물을 캡니다.
- 한 번 사용하기 시작한 곡괭이는 사용할 수 없을 때까지 사용합니다.
- 광물은 주어진 순서대로만 캘 수 있습니다.
- 광산에 있는 모든 광물을 캐거나, 더 사용할 곡괭이가 없을 때까지 광물을 캡니다.
즉, 곡괭이를 하나 선택해서 광물 5개를 연속으로 캐고, 다음 곡괭이를 선택해서 광물 5개를 연속으로 캐는 과정을 반복하며, 더 사용할 곡괭이가 없거나 광산에 있는 모든 광물을 캘 때까지 과정을 반복하면 됩니다.
마인이 갖고 있는 곡괭이의 개수를 나타내는 정수 배열 picks와 광물들의 순서를 나타내는 문자열 배열 minerals가 매개변수로 주어질 때, 마인이 작업을 끝내기까지 필요한 최소한의 피로도를 return 하는 solution 함수를 완성해주세요.
제한사항
- picks는 [dia, iron, stone]과 같은 구조로 이루어져 있습니다.
- 0 ≤ dia, iron, stone ≤ 5
- dia는 다이아몬드 곡괭이의 수를 의미합니다.
- iron은 철 곡괭이의 수를 의미합니다.
- stone은 돌 곡괭이의 수를 의미합니다.
- 곡괭이는 최소 1개 이상 가지고 있습니다.
- 5 ≤ minerals의 길이 ≤ 50
- minerals는 다음 3개의 문자열로 이루어져 있으며 각각의 의미는 다음과 같습니다.
- diamond : 다이아몬드
- iron : 철
- stone : 돌
입출력 예
| picks | minerals | result |
|---|---|---|
| [1,3,2] | ["diamond", "diamond", "diamond", "iron", "iron", "diamond", "iron", "stone"] | 12 |
| [0,1,1] | ["diamond", "diamond", "diamond", "diamond", "diamond", "iron", "iron", "iron", "iron", "iron", "diamond"] | 50 |
입출력 예 설명
입출력 예 #1
- 다이아몬드 곡괭이로 앞에 다섯 광물을 캐고 철 곡괭이로 남은 다이아몬드, 철, 돌을 1개씩 캐면 12(1 + 1 + 1 + 1+ 1 + 5 + 1 + 1)의 피로도로 캘 수 있으며 이때가 최소값입니다.
입출력 예 #2
- 철 곡괭이로 다이아몬드 5개를 캐고 돌 곡괭이고 철 5개를 캐면 50의 피로도로 캘 수 있으며, 이때가 최소값입니다.
나의 풀이
풀이1
import java.util.*;
class Solution {
static HashMap<String, Integer> map ;
static int[][] cost;
static String[] minerals;
static int minLen;
public int solution(int[] picks, String[] minerals) {
map = new HashMap<>();
int index = 0;
this.minerals = minerals;
minLen = Integer.MAX_VALUE;
map.put("diamond", index++);
map.put("iron", index++);
map.put("stone",index++);
cost = new int[][]{{1,1,1},{5,1,1},{25,5,1}};
int pickLen = 0;
for(int x : picks)pickLen+=x;
dfs(new int[pickLen], 0, picks);
return minLen;
}
public void dfs(int arr[], int L, int[] picks){
if(L == arr.length){
minLen = Math.min(minLen , getLen(arr));
return;
}
for(int i= 0; i< picks.length; i++){
if(picks[i]>0){
picks[i]--;
arr[L] = i;
dfs(arr, L+1, picks);
picks[i]++;
}
}
}
public int getLen(int[] arr){
int ret = 0;
int mIndex = 0;
for(int x : arr){
int cnt = 5;
while(cnt-- > 0){
if(mIndex == minerals.length)return ret;
ret += cost[x][map.get(minerals[mIndex++])];
}
}
return ret;
}
}
풀이 2
package programmers;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class MineralMining {
static final int[][] fatigueCosts = {
{1, 1, 1},
{5, 1, 1},
{25, 5, 1}
};
static class Mineral {
int diamond, iron, stone;
public Mineral(int diamond, int iron, int stone) {
this.diamond = diamond;
this.iron = iron;
this.stone = stone;
}
}
public static int solution(int[] picks, String[] minerals) {
int totalFatigue = 0;
int size = Arrays.stream(picks).sum();
List<Mineral> fatigueList = new ArrayList<>();
for(int i = 0 ; i < minerals.length; i += 5) {
if(size == 0) {
break;
}
int diamond = 0, iron = 0, stone = 0;
for(int j = i; j < i + 5 && j < minerals.length; j++) {
int mineral = 0;
if(minerals[j].startsWith("i")) {
mineral = 1;
}else if(minerals[j].startsWith("s")) {
mineral = 2;
}
diamond += fatigueCosts[0][mineral];
iron += fatigueCosts[1][mineral];
stone += fatigueCosts[2][mineral];
}
fatigueList.add(new Mineral(diamond, iron, stone));
size--;
}
fatigueList.sort((o1, o2) -> (o2.stone - o1.stone));
for(Mineral mineral : fatigueList) {
int diamond = mineral.diamond;
int iron = mineral.iron;
int stone = mineral.stone;
System.out.printf("dia: %d, iron: %d, stone: %d\n", diamond, iron, stone);
if(picks[0] > 0) {
totalFatigue += diamond;
picks[0]--;
continue;
}
if(picks[1] > 0) {
totalFatigue += iron;
picks[1]--;
continue;
}
if(picks[2] > 0) {
totalFatigue += stone;
picks[2]--;
}
}
System.out.println(totalFatigue);
return totalFatigue;
}
public static void main(String[] args) {
int[] picks = {0, 0, 1};
String[] minerals = {"stone", "stone", "stone", "stone", "stone", "diamond"};
solution(picks, minerals);
}
}
나의 생각
1. 광물을 5개씩 그룹으로 나누어 각 그룹별 피로도를 계산
2. 남아 있는 곡괭이의 수만큼만 그룹을 생성하고, 곡괭이가 부족한 경우 나머지 광물을 무시
3. 생성된 광물 그룹들을 돌 곡괭이로 캐는데 필요한 피로도가 큰 순으로 정렬
4. 정렬된 광물 그룹들을 순회하면서 가장 피로도가 낮은 곡괭이를 사용하여 광물을 캐고, 해당 피로도를 총 피로도에 더함
5. 각 그룹을 처리한 후에 해당 곡괭이의 수를 하나 줄임static final int[][] fatigueCosts = {
{1, 1, 1},
{5, 1, 1},
{25, 5, 1}
};
static class Mineral {
int diamond, iron, stone;
public Mineral(int diamond, int iron, int stone) {
this.diamond = diamond;
this.iron = iron;
this.stone = stone;
}
}fatigueCosts 2차원 배열
- 각 곡괭이 유형별로 광물을 캐는데 소모되는 피로도를 저장
- 배열의 첫 번째 차원은 곡괭이의 종류를 나타냄
- 다이아 곡괭이
0 - 철 곡괭이
1 - 돌 곡괭이
2
- 다이아 곡괭이
- 배열의 두 번째 차원은 광물의 종류를 나타냄
- 다이아몬드
0 - 철
1 - 돌
2
- 다이아몬드
- 예를 들어,
fatigueCosts[1][0]은 철 곡괭이로 다이아몬드를 캘 때 소모되는 피로도는5
Mineral Class
Mineral클래스는 특정 광물 그룹을 캘 때 각 곡괭이 별로 소모되는 총 피로도를 계산하여 저장하는 데 사용diamond,iron,stone필드는 각각 다이아몬드, 철, 돌 광물을 캐는데 필요한 피로도를 나타냄Mineral객체는 생성될 때 특정 광물 그룹에 대한 피로도를 계산하며, 이는fatigueCosts배열을 사용하여 각 곡괭이에 대해 수행- 예를 들어, 다이아몬드 광물 2개, 철 광물 3개를 포함하는 광물 그룹을 나타내는
Mineral객체는 생성자에2,3,0을 전달하여 생성
- 광물을 5개씩 그룹으로 나누어 각 그룹별 피로도를 계산
for (int i = 0; i < minerals.length; i += 5) {
if (size == 0) {
break;
}
int diamond = 0, iron = 0, stone = 0;
for (int j = i; j < i + 5 && j < minerals.length; j++) {
int mineral = 0;
if (minerals[j].startsWith("i")) {
mineral = 1;
} else if (minerals[j].startsWith("s")) {
mineral = 2;
}
diamond += fatigueCosts[0][mineral];
iron += fatigueCosts[1][mineral];
stone += fatigueCosts[2][mineral];
}
fatigueList.add(new Mineral(diamond, iron, stone));
size--;
}- 여기서
fatigueList에 각 광물 그룹의 피로도를 계산한Mineral객체를 추가함

첫 번째 그룹
{"diamond", "diamond", "diamond", "iron", "iron"}
- 첫 번째 그룹을 각각 다이아 곡괭이, 철 곡괭이, 돌 곡괭이로 채광을 하면 소비되는 피로도를
Mineral객체로 받아와fatigueList에 저장
두 번째 그룹
{"diamond", "iron", "stone"}
- 두 번째 그룹을 각각 다이아 곡괭이, 철 곡괭이, 돌 곡괭이로 채광을 하면 소비되는 피로도를
Mineral객체로 받아와fatigueList에 저장
- 남아 있는 곡괭이의 수만큼만 그룹을 생성하고, 곡괭이가 부족한 경우 나머지 광물을 무시
size--;
- 각 광물 그룹을 처리할 때마다 남은 곡괭이 수(size)를 감소시킴, 곡괭이가 부족하면 루프에서 탈출하여 더 이상 광물 그룹을 생성하지 않음
- 생성된 광물 그룹들을 돌 곡괭이로 캐는데 필요한 피로도가 큰 순으로 정렬
fatigueList.sort((o1, o2) -> (o2.stone - o1.stone));
-
그룹별 처리 : 광물 그룹을 . 돌 곡괭이의 피로도가 높은 순으로 정렬하면, 다이아 곡괭이로 처리할때 피로다가 가장 크게 절약될 . 수있는 그룹부터 처리하게 됨. 만약 다이아 곡괭이가 충분하다면, 피로도가 가장 높은 그룹을 먼저 처리하여 다른 곡괭이보다 더 효율적으로 사용할 수 있음
-
피로도 최소화 : 피로도가 가장 높은 그룹을 다이아몬드 곡괭이(피로도 소모가 가장 낮은 곡괭이)로 처리함으로써 전체 작업에 대한 피로도를 최소화. 즉, 가장 피로도가 높은 작업을 가장 효율적인 도구(다이아 곡괭이)로 처리하여, 총 피로도를 줄이는 것
- 정렬된 광물 그룹들을 순회하면서 피로다가 가장 낮은 곡괭이를 사용하여 광물을 캐고, 해당 피로도를 총 피로도에 더함
for (Mineral mineral : fatigueList) { // 곡괭이를 선택할 때는 다이아, 철, 돌 곡괭이 순으로
if (picks[0] > 0) { // picks[0] : 다이아 곡괭이
totalFatigue += mineral.diamond;
picks[0]--;
continue;
}
if (picks[1] > 0) { // picks[1] : 철 곡괭이
totalFatigue += mineral.iron;
picks[1]--;
continue;
}
if (picks[2] > 0) { // picks[2] : 돌 곡괭이
totalFatigue += mineral.stone;
picks[2]--;
}
}
-
fatigueList를 순회하면서 가용한 곡괭이 중 피로도가 가장 낮은 것을 사용하여 광물을 캐고, 사용된 곡괭이의 피로도를totalFatigue에 추가 -
각 그룹을 처리한 후에 해당 곡괭이의 수를 하나 줄임
picks[0]--;
picks[1]--;
picks[2]--;
로직을 처음 시작할 때의 int[] picks = {1,3,2}로 시작
첫 그룹을 다이아 곡괭이로 처리한 이후 int[] picks = {0,3,2}
두 번째 그룹을 철 곡괭이로 처리한 이후 int[] picks = {0,2,2}