1)스파크 작업과 단계
1. 스파크 데이터프레임 API 분류
- 변형(Transformations): 데이터를 처리하고 변환하는 명령어.
- 좁은 의존성 변형(Narrow Dependency transformations): 각 데이터 파티션에서 독립적으로 병렬 실행 가능. 예시:
select(),filter() - 넓은 의존성 변형(Wide Dependency transformations): 키에 따라 데이터를 그룹화한 후 변형 적용 필요. 예시:
groupBy(),join()
- 좁은 의존성 변형(Narrow Dependency transformations): 각 데이터 파티션에서 독립적으로 병렬 실행 가능. 예시:
- 작업(Actions): 작업을 트리거하여 데이터프레임을 디스크에 저장하거나, 변형을 계산하고 결과를 수집함. 예시:
read(),write(),collect()
2. 스파크 코드 블록과 작업
- 각 작업(
action)은 스파크에서 별도의 작업을 트리거하며, 코드 블록의 시작과 끝을 정의함. - 작업 사이의 코드 블록은 하나의 스파크 작업으로 처리됨.
3. Job, Stage,Task
-
job:
- job에는 여러개의 transform이 생성될 수 있음
- action당 하나의 job생성
- spark 엔진은 transforms작업들을 최적화하고 logical plan을 세움
- Wide Dependency transformations을 기준으로 여러개의 stage로 분리
-
Stage:
- 각 단계는 독립적으로 실행되며, 이전 단계의 출력이 다음 단계의 입력으로 사용됨.
- 데이터는 단계 간
Shuffle/Sort를 통해
이동하며, 이는 클러스터 내에서 비용이 많이 드는 작업임.
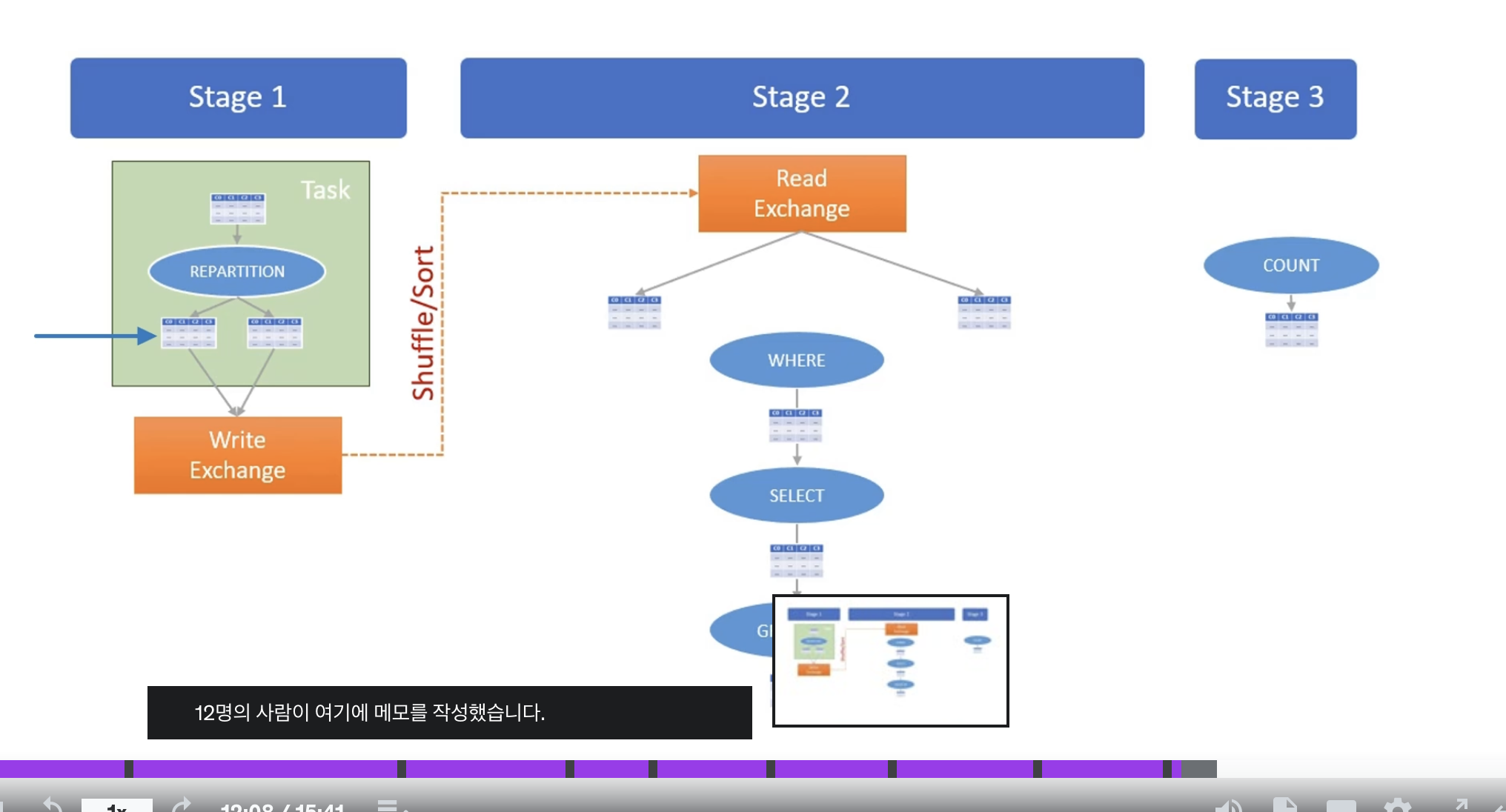
-
Task:
스파크 작업의 가장 작은 실행 단위로, 각 실행자(executor)에 의해 수행됨. -
작업은 여러 태스크로 나뉘어 각 실행자의 슬롯에서 병렬로 처리되며,
collect()와 같은 작업은 모든 태스크의 결과를 드라이버로
반환하여 집계함.
4. 클러스터 관리와 리소스 할당
- executor 여러 슬롯을 포함하며, 드라이버는 이러한 슬롯을 관리하고 필요한 태스크를 할당함.
- executor의 실패나 태스크의 실패는 재시도를 통해 관리되며, 모든 재시도 실패 시 작업은 실패로 마크됨.
이 구조를 통해 스파크는 대규모 데이터를 효율적으로 처리하고, 각 단계의 병렬 처리를 통해 빠른 데이터 처리 속도를 보장합니다
2)Spark SQL Engine과 Query Planning
- Spark는 데이터를 처리하기 위해 Spark SQL과 DataFrame API라는 두 가지 주요 인터페이스를 제공한다.
1. Spark의 주요 API
Spark SQL
- ANSI SQL:2003 표준 준수.
- 표준 SQL 문법으로 데이터를 처리할 수 있음.
DataFrame API
- 함수 기반 API.
- 함수형 프로그래밍 기법을 사용하여 데이터 처리 가능.
- PySpark와 Scala/Java에서 모두 사용 가능.
Dataset API
- Scala와 Java에서만 사용 가능.
- PySpark에서는 지원되지 않음.
- Spark는 DataFrame API 사용을 권장, Dataset 사용은 피하라고 권고.
2. Spark의 코드 처리 방식
- Spark 코드는 작업(Job) 단위로 실행됨.
- SQL 표현식 또는 DataFrame API 코드는 각각 하나의 작업(Job)으로 처리됨.
- 각각의 작업은 논리적 쿼리 플랜(Logical Query Plan)으로 표현되며, Spark SQL 엔진에서 처리됨.
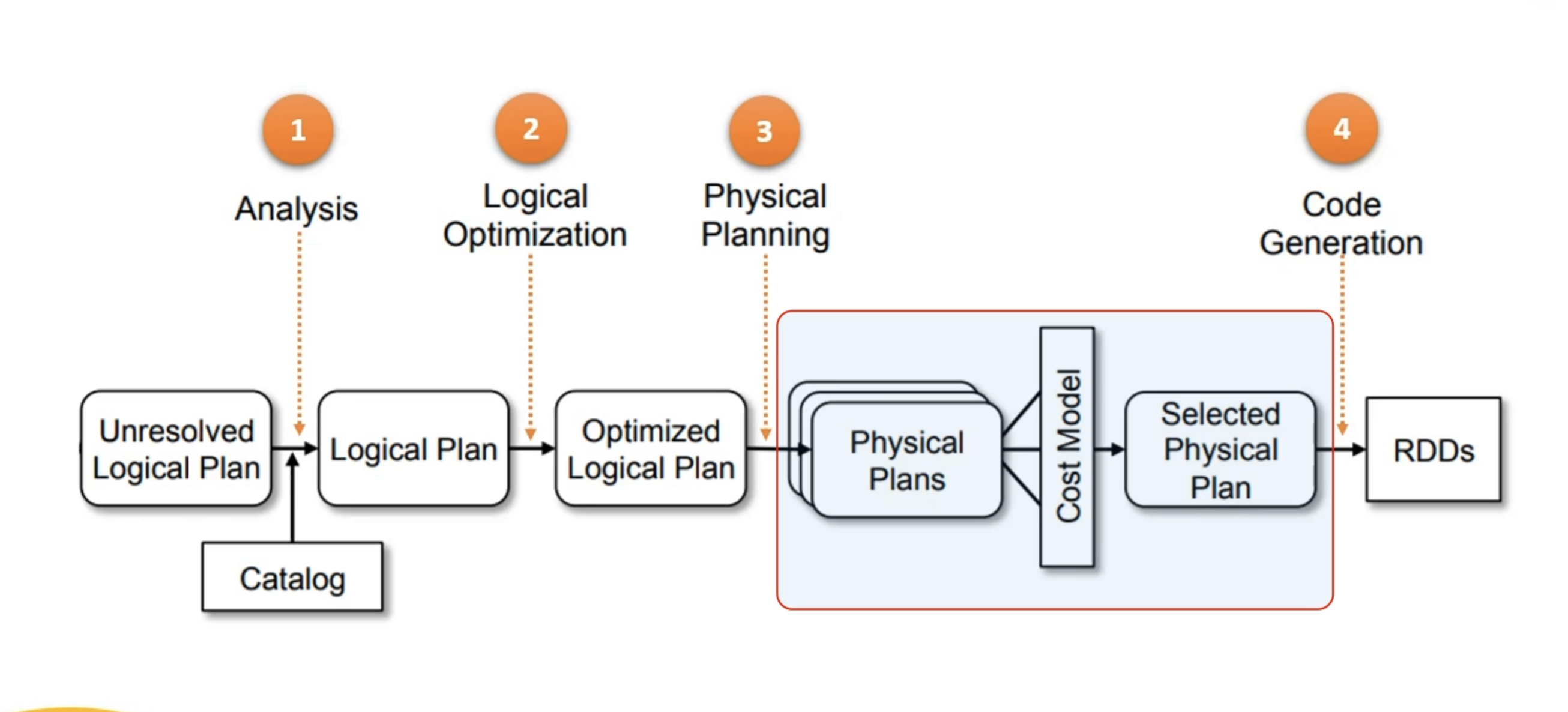
3. Spark SQL 엔진의 처리 단계
1단계: 분석 단계 (Analysis Phase)
- 목적: 코드의 오류 및 잘못된 이름 확인.
- 작업:
- SQL 또는 DataFrame 코드를 파싱.
- 열 이름과 데이터 유형을 카탈로그(Catalog)를 참조하여 확인.
- 암시적 형 변환을 적용하여 연산을 검증.
- 결과: 완전히 해결된 논리적 플랜 생성.
- 예외:
- 열 이름 불일치.
- 잘못된 함수 호출.
- 형 변환 오류 등이 발생하면 분석 예외가 발생.
2단계: 논리적 최적화 (Logical Optimization)
- 목적: 논리적 플랜에 규칙 기반 최적화 적용.
- 작업:
- 최적화 규칙을 사용하여 논리적 쿼리 플랜을 단순화 및 개선.
- 결과: 최적화된 논리적 플랜 생성.
- 비고: 최적화 규칙의 세부 내용을 알 필요는 없음.
3단계: 물리적 플래닝 (Physical Planning)
- 목적: 논리적 플랜을 실행 가능한 물리적 플랜으로 변환.
- 작업:
- 비용 기반 최적화(Cost-Based Optimization)를 적용.
- 여러 물리적 플랜 생성 후, 각각의 비용을 계산.
- 비용이 가장 낮은 플랜 선택.
- 예시:
- Broadcast Join, Sort Merge Join, Shuffle Hash Join 등 다양한 플랜 생성.
- 각 플랜의 실행 비용 비교 후 최적 플랜 선택.
4단계: 코드 생성 (Code Generation)
- 목적: 최적 물리적 플랜의 실행 코드 생성.
- 작업:
- 물리적 플랜을 기반으로 Java 바이트 코드 생성.
- Spark는 컴파일러처럼 동작하여 실행 속도를 최적화.
- 결과: 최적화된 코드가 생성되어 실행 단계로 넘어감.
4. Spark SQL 엔진의 특징 요약
- 분석(Analysis): 코드의 오류와 이름 확인.
- 논리적 최적화(Logical Optimization): 규칙 기반 최적화 적용.
- 물리적 플래닝(Physical Planning): 비용 기반 최적화로 최적 플랜 선택.
- 코드 생성(Code Generation): 실행 가능한 최적화된 바이트 코드 생성.
대부분의 작업은 DataFrame API로 수행 가능.
PySpark에서는 Dataset API가 제공되지 않으므로 Dataset 관련 사항은 무시 가능.