유데미의 [Apache Spark - Beyond Basics and Cracking Job Interviews] 강의 내용 복습 겸 정리
강의링크
1. Spark와 클러스터
- Apache Spark: 분산 컴퓨팅 플랫폼.
- 모든 Spark 애플리케이션은 분산 애플리케이션.
- 실행 환경:
- 로컬 머신: 개발 및 단위 테스트 용도.
- 프로덕션 클러스터: 최종 실행 환경.
-> 실제 운영에 사용되는 spark 어플리케이션은 보통 클러스터로 구성.
- 클러스터 기술:
- Hadoop YARN
- Kubernetes
(Cluster 기술 중 hadoop yarn,k8s을 90% 이상 사용) - 그 외: Mesos, Spark Standalone
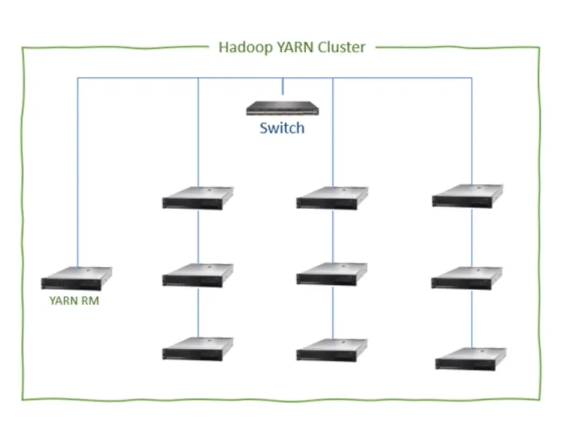
2. 클러스터 개념
- 클러스터: 네트워크로 연결된 물리적 머신(워커 노드)의 집합.
- 예) 10대 머신 × CPU 코어 16개 + RAM 64GB → 총 용량: 160 CPU 코어, 640GB RAM
- 워커 노드: 클러스터를 구성하는 개별 머신.
3. 컨테이너와 YARN RM
- spark-submit 명령으로 클러스터에 애플리케이션 제출.
- YARN 리소스 관리자(Resource Manager, RM):
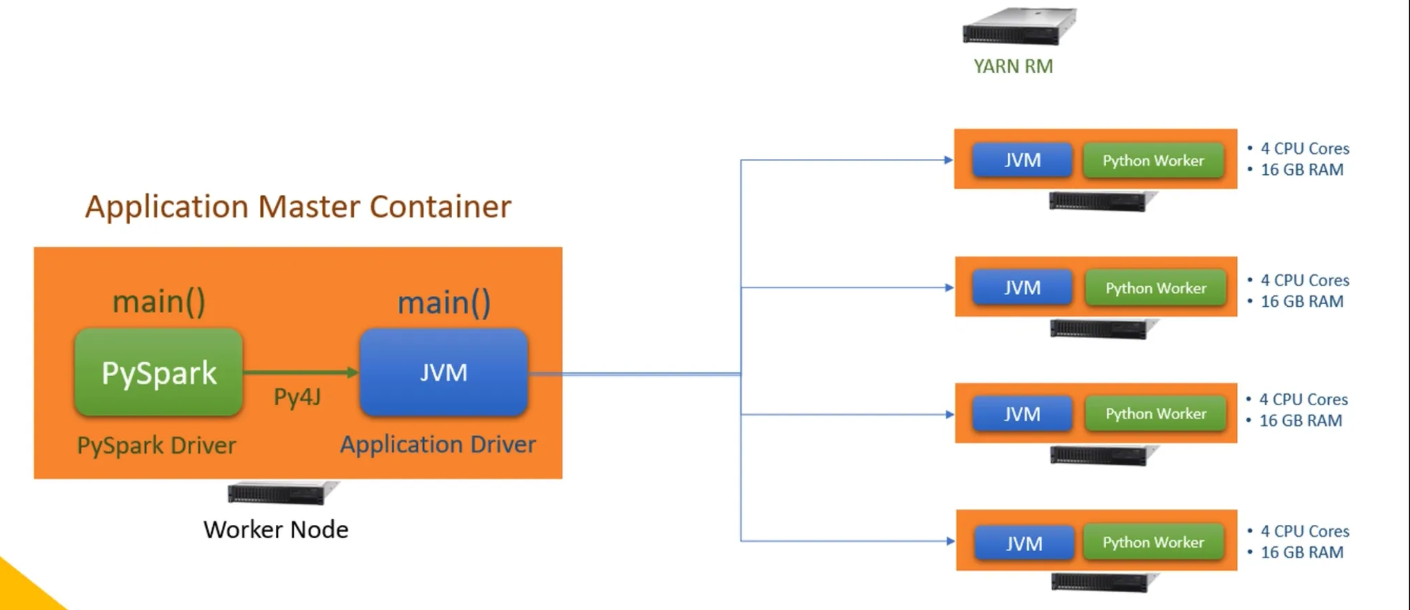
- Application Master Container(AM 컨테이너) 생성.
main()메서드를 AM 컨테이너에서 실행.
- 컨테이너:
- 격리된 실행 환경.
- CPU, 메모리 할당 (예: 4 CPU 코어, 16GB RAM).

4. PySpark vs Scala 애플리케이션
- Spark는 Scala로 작성되고 JVM에서 실행.
- PySpark:
-
Spark를 Python으로 래핑하는 방식으로 제공(py4j connection 통해).
-
Python → Java 래퍼 → Scala 코드 실행.
-
Python에서 JVM 호출은 Py4J로 연결.
-
5. 드라이버와 실행자
- 드라이버:
- 작업 분배 및 실행자 관리.
- 직접 데이터 처리 작업은 하지 않음.
- **AM 컨테이너
에서 실행.
- PySpark 코드: PySpark 드라이버 + JVM 드라이버.
- Scala/Java 코드: JVM 드라이버**만 실행.
- 실행자:
- 데이터 처리 담당.
- 드라이버 요청으로 생성된 실행자 컨테이너에서 실행.
- 각 컨테이너는 JVM 애플리케이션으로 실행.
6. Python Worker
- Python 워커:
- PySpark API 외 Python 코드(UDF, 외부 라이브러리 등) 실행 시 필요.
- Python 워커는 실행자 컨테이너 내부에서 Python 런타임 환경 제공.
- PySpark API만 사용할 경우 Python 워커는 불필요.
7. 실행 구조
- Scala/Java DataFrame API 사용:
- JVM 드라이버 + JVM 실행자.
- PySpark DataFrame API 사용:
- PySpark 드라이버 + JVM 드라이버 + JVM 실행자.
- Python UDF/추가 라이브러리 사용:
- Python 워커 포함 (각 실행자 컨테이너 내 생성).
8. Spark 프로세스 요약
- 드라이버 실행:
- AM 컨테이너 생성 후
main()실행.
- AM 컨테이너 생성 후
- 추가 컨테이너 요청:
- 실행자 컨테이너 생성.
- 작업 분배 및 실행:
- 드라이버 → 실행자 작업 전달.
- 데이터 처리:
- 실행자가 모든 데이터 처리 작업 수행.
9. 주요 용어 정리
- 드라이버: 작업 분배 및 실행자 관리.
- 실행자: 데이터 처리 담당.
- 컨테이너: 격리된 CPU/메모리 환경.
- Python 워커: PySpark 외 Python 코드 실행 시 필요.
