1. spark 작업환경 구성
- 별도의 환경 구성을 위해 anaconda에 pyspark 가상환경 생성
- java,hadoop(witutils),spark 등을 로컬에 설치하고 환경변수 설정
- 가상환경에서 필요한 패키지 설치(pyspark,findspark,jupyter notebook...등등)
2. spark-standalone cluster에 대해서
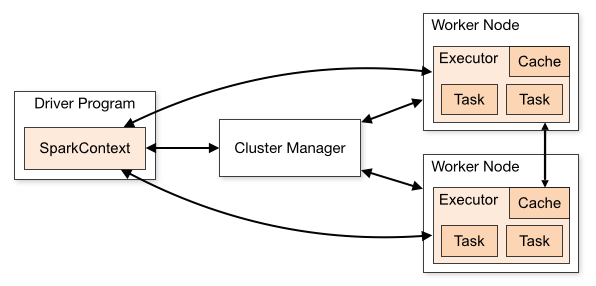
스파크는 위 이미지같이 여러개의 worker node가 있고 driver가 worker들을 관리하며 job을 worker에 할당하고 모니터링한다.
worker안에는 executor가 있고 이 executor들이 task들을 수행한다.
standalone 클러스터는 마스터-워커 아키텍처 기반으로 동작하는 것을 말하고, 보통 로컬에서 개발,테스트를 목적으로 간단하게 구축하여 사용하는 용도이다.
3. standalone cluster 구축
방법2. shell 여러개로 직접 노드 띄우기
내가 사용한 방법이다.spark/bin폴더로 이동 후 master,worker순서대로 아래 명령어를 실행시키면 된다.
node 실행
-
master node 실행
spark-class.cmd org.apache.spark.deploy.master.Master -
worker node 실행
spark-class.cmd org.apache.spark.deploy.worker.Worker spark://192.168.0.16:7077 -m 3g -c 3
사용가능한 나의 local 자원은 메모리 10g, core 8개다.
메모리는 14g 사용가능하긴한데, spark의 드라이버가 사용해야할 정도를 남겨두어야한다고 해서 10g만 worker로 할당했다.
리소스 최적화를 위한 삽질
가지고 있는 자원이 10g,8 cores이다보니 worker를 많이 두자니 worker별 배정되는 자원이 너무 작아 out of memory가 난다. 그렇다고 하나의 worker로 spark job을 돌리자니 spark을 쓰는 의미가 없었다.
나는 4g 용량의 json파일을 rdbms 테이블로 단순히 변환하는 작업을 해야하는데, 내가 처리할 json파일을 dataframe화 하면 spark에서 자동으로 35개의 partitions로 나누어주었다.(보통 128mb당 1partition으로 계산한다고 한다.) 35개의 파티션을 몇개의 worker노드에 어떻게 자원을 분배해야 효과적으로 병렬처리를 할 수 있을지 여러번의 튜닝과 실험을 해봤다.
최종적으로 아래와 같이 worker노드를 구성하였다.
-worker node: 3개
-worker당 memory:3g,3g,4g (총 10g)
-worker 당 core 배정 갯수: 2,2,3
여기까지 하고 localhost:8080 로 spark UI에 접속하여 내가 설정한대로 master,worker노드가 잘 실행되고 있는지 확인한다.
방법2.
spark설정 폴더에 있는 spark-env.sh 쉘스크립트에서 포트,worker 갯수,core,메모리를 할당한다
$SPARK_HOME/sbin에서 start-master.sh 명령어로 master,worker 노드를 띄운다.
이게 더 간단한 방법인거 같은데, 난 sbin에서 명령어가 계속 안먹길래 방법1. 로 진행했다.
