
ORM
= 객체와 관계형 데이터베이스를 매핑하는 도구이다.
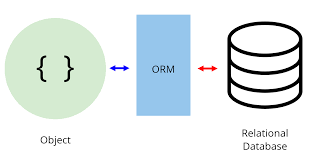
SQL 쿼리가 아닌, 직관적인 코드(메서드)로 데이터를 조작한다.
SELECT *FROM user; -> user.findAll()
SQL 문을 사용하지 않고 객체 지향적 코드를 작성할 수 있어서 코드의 가독성을 높이고 개발자 편의성을 증대할 수 있다.
DB 연동과 관련된 많은 부분을 자동으로 처리해주므로, 개발자는 더 적은 코드를 작성하고 더 높은 수준의 추상화를 얻는다. 개발 친화적이다.
ORM 종류
- 자바의 하이버네이트 (Hibernate) - JPA의 구현체 중 하나이다.
- 파이썬의 장고 (Django)
- 루비의 액티브 레코드(ActiveRecord)
SQL을 써도 되는데 왜 ORM을 쓸까?
SQL을 직접 다룸으로 생기는 문제점은 특정 DB에 종속적으로 사용하기 쉽다는 것이다.
테이블마다 비슷한 CRUD SQL은 DAO 개발이 매우 반복되는 작업을 초래한다.
테이블 필드가 변경될 시 , 이와 관련된 모든 DAO의 SQL문, 객체의 필드 등을 수정해야 한다.
코드 상으로 SQL과 JDBC API를 분리했다 하더라도 논리적으로 강한 의존성을 가지고 있다.
SQL을 직접 작성하면 결국 SQL의 의존적인 개발을 할 수 밖에 없는데,
객체 간의 관계는 사라지고 DB에 대한 처리에 집중하게 된다.
즉, 비즈니스 로직 구현보다 데이터베이스 접근 로직 구현에 집중하며 DB에 항상 의존관계를 가질 수 밖에 없다.
ORM 장점 ?
- 패러다임 불일치 문제 해결
- 생산성
지루하고 반복적인 CRUD 용 SQL을 개발자가 작성하지 않아도 됨 - 데이터 접근 추상화, 벤더 독립성
- 유지 보수
: 필드 추가, 삭제 시 관련된 CRUD 쿼리를 직접 수정하지 않고, 엔티티를 수정하면 된다.
ORM 단점 ?
- 복잡한 쿼리 사용이 어렵다.
하지만 JPA에서는 SQL과 유사한 기술인 JPQL을 지원하고 , SQL 자체 쿼리를 작성할 수 있도록 지원하며 SQL Mapper와도 혼용해서 사용도 가능해서 어느정도 해결 가능하다.
ORM을 사용함으로써...
SQL로부터 분리된 설계 즉, DB에 의존하지 않은 상태에서 개발할 경우,
도메인과 비즈니스 로직 구현에 좀 더 집중할 수 있다.
또한 데이터베이스 서버와 의존 관계를 가지지 않는 구현 단계를 거치면서 더 빠른 구현과 테스트 인 피드백 사이클을 돌 수 있으며 요구 사항 변화에 빠르게 대응할 수 있다는 이점이 있다.
Spring Data - 저장소 종류가 달라도 일관된 데이터 처리 방법을 제공한다.
Spring Data JPA = JPA를 위한 저장소(JpaRepository)와 관련 기능을 제공
