
이 글은 Programming in Scala 4/e Chapter.16을 읽고 작성한 글입니다.
스칼라 프로그램에서 가장 많이 사용하는 데이터 구조는 아마도 리스트일 것이다.
16장에서는 이러한 리스트의 일반적인 연산을 공부한 다음 중요한 설계 원칙에 대해 알아 볼 것이다.
리스트 리터럴
우리는 앞쪽에서 공부를 하며 여러 예제에서 원소들이 명확한 리스트는 밑과 같이 선언한다는 것을 알고 있다.
val alphabetList = List('a', 'b', 'c')
val emptyList = List()
val fruit = List("apple", "pineapple", "orange")
val diag3 = List(
List(1,2,3),
List(4,5,6),
List(7,8,9)
)위와 같이 리스트 선언 방식은 배열과 같다. 하지만, 배열과 리스트에는 중요한 차이가 있다.
1. 리스트는 변경 불가능하다. 즉, 리스트를 할당문으로 변경할 수 없다.
2. 리스트 구조는 재귀적( = 연결 리스트 linked list)이지만 배열은 평면적이다.
리스트 타입
배열과 마찬가지로 리스트 역시 같은 타입들의 원소로 이루어 진다. 즉, 원소 타입이 T인 리스트의 타입을 List[T]으로 명시할 수 있다.
val alphabetList:List[Char] = List('a', 'b', 'c')
val emptyList:List[Nothing] = List()
val fruit:List[String] = List("apple", "pineapple", "orange")
val diag3:List[List[Int]] = List(
List(1,2,3),
List(4,5,6),
List(7,8,9)
)같은 타입들만이 원소로 들어있으므로 위와 같이 명시할 수 있다.
스칼라 리스트 타입은 공변적(covariant)이다. 즉, S가 T의 서브타입이면, List[S]도 List[T]의 서브타입이라는 뜻이다. 예를 들어, List[String]은 List[Object]의 서브타입이다. 문자열인 String은 객체이고 모든 객체는 Object의 서브타입이므로 위가 성립하는 것이다.
리스트 생성
모든 리스트는 빌딩 블록인 Nil과 ::(콘즈 cons) 2가지로 만들 수 있다.
Nil은 빈 리스트이며, 중위 연산자 ::는 리스트 앞에 원소를 추가한다.
val fruits = "apple" :: ("pineapple" :: ("orange" :: Nil) )
val alphabetList = 'a' :: ( 'b' :: ('c' :: Nil) )
val emptyList = Nil위의 예시를 위와 같이 나타낼 수 있다. 또한, 소괄호를 없앨 수 있다.
val fruits = "apple" :: "pineapple" :: "orange" :: Nil과 같이 표시할 수 있다.
리스트 기본 연산
리스트의 모든 연산은 다음 세가지를 가지고 있다.
1. head : 리스트의 첫 번째 원소를 반환 [비어 있지 않은 리스트에서 유효]
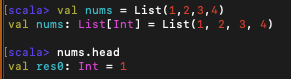
-
tail : 첫 번째 원소를 제외한 나머지 원소로 이루어진 리스트 [비어 있지 않은 리스트에서 유효]
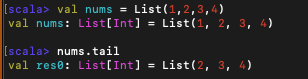
-
isEmpty : 리스트가 비어 있다면 true 반환
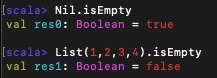
리스트 패턴
리스트에 패턴 매치를 사용해 각 부분으로 나눌 수 있다. 리스트 패턴은 리스트 표현식과 일대일 대응된다.
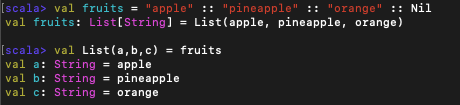
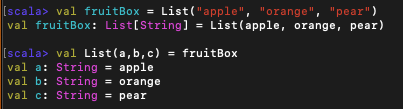
위의 예시들에서 List(a,b,c)는 크기가 3인 리스트와 매치되며, 3개의 원소가 차례로 a,b,c 패턴 변수에 들어간다.
List 클래스의 1차 메서드
어떤 메서드가 함수를 인자로 받지 않는다면, 즉 고차함수가 아니라면 그 메서드를 1차 메서드(first-order method)라고 부른다.
1. :::
위에서 리스트 앞에 원소를 삽입하는 콘즈인 ::와 비슷한 연산자이지만, :::의 두 인자를 리스트이다.
xs ::: ys위의 명령어는 xs라는 리스트의 모든 원소 뒤에 ys의 모든 원소가 따라오는 새로운 리스트이다.

위와 같이 2개의 리스트의 모든 원소를 연결함을 알 수 있다. 또한, 여러 개의 리스트를 연결할 수 있다.
xs ::: ys ::: zs위와 같은 형태도 가능하다.
2. length
length 메서드는 다른 언어에서의 length와 마찬가지로 리스트의 길이를 계산한다.
xs.length위의 명령어는 리스트 xs의 길이를 계산하는 것이다.
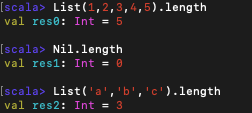
위와 같이 빈 리스트인 Nil에 대해 실행해도 잘 리턴되는 것을 알 수 있다.
3. init, last
init은 위쪽에서 알아보았던 tail과 반대되는 것으로, 마지막 원소를 제외하고 모든 원소드를 리턴하는 메서드이며,
last는 head와 유사하게 마지막 원소만 리턴하는 메서드이다.
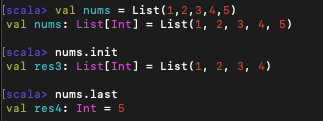
이 메서드들은 head와 tail과 마찬가지로 빈 리스트에 대해 호출하면 예외가 발생한다.
4. reverse
reverse 역시 다른 언어에 있는 메서드와 마찬가지로 리스트를 뒤집는 메서드이다.
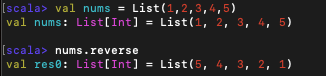
5. drop, take, splitAt
(1) drop, take
drop과 take 연산은 리스트에서 임의의 접두사나 접미사를 반환하는 메서드로, tail과 init을 일반화한 것이다.
xs take n위의 명령어는 xs 리스트의 처음부터 n번째 원소까지를 반환하는 메서드이다.
xs drop n반면 drop 연산은 첫 번째에서 n번째 원소를 제외하고 반환하는 메서드이다.
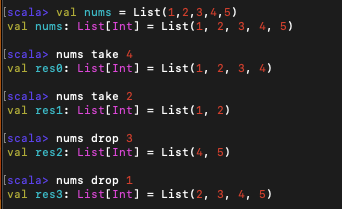
위와 같이 사용할 수 있다. take의 여집합이 drop이라고 생각하면 편할 것이다.
(2) splitAt
xs split n위의 메서드는 (xs take n, xs drop n)과 같다. 즉, 주어진 인덱스 위치에서 리스트를 분할하여 두 리스트가 들어있는 순서쌍(튜플)을 반환한다.
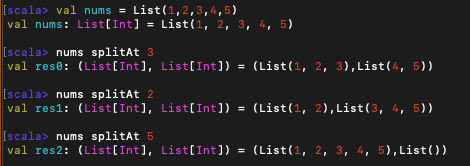
위와 같이 튜플로 두 리스트를 반환한다.
6. flatten
flatten 메서드는 2차원 리스트를 원자로 받아 하나의 1차원 리스트로 만드는 것이다.
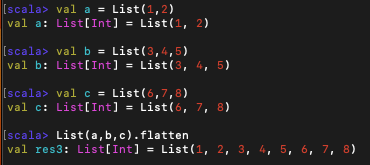
위의 2차원 리스트에 flatten을 실행한 결과이다. 2차원 리스트 내부에 있는 1차원 리스트들 원소 순서대로 묶어 1차원 리스트를 리턴한다.
즉, 2차원 리스트를 인자로 받아 1차원 리스트로 펼쳐주는 역할을 한다.
7. zip, unzip
두 메서드는 두 리스트를 인자로 받아서 순서쌍 리스트를 만드는 것이다.
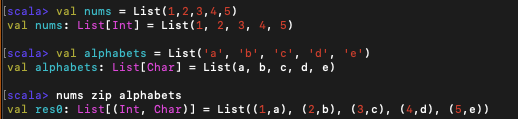
위와 같이 nums와 alphabets 두 개 리스트의 원소들을 각각 짝 지어서 튜플 리스트로 리턴되는 것이 보인다.
만약 두 리스트의 길이가 다르면 어떻게 될까?
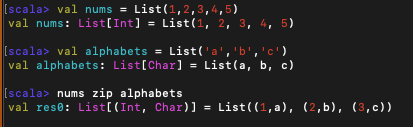
길이 짧은 쪽에 맞추어 길이가 긴 쪽의 원소는 버린다.
주로 인덱스와 묶는 것이 효과적이므로 zipWithIndex를 사용하여 모든 원소와 그 위치를 묶는 방식으로 사용한다.
unzip은 리스트의 튜플로 바꿔준다.
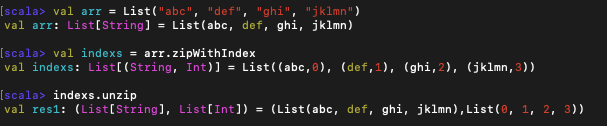
튜플을 원소로 하는 리스트로 되어있지만,unzip을 사용하니 리스트를 원소로 하는 튜플로 복원되었다.
8. toString, mkString
toString은 표준 문자열을 반환한다.

위와 같이 리스트를 표준화한 문자열을 반환하는 것을 알 수 있다.
반면 mkString을 사용하면 조금 더 우리가 편하게 사용할 수 있는 String을 사용할 수 있다.
xs mkString(pre, sep, post)형태로 선언을 하는데, 총 4개의 인자가 필요하다.
xs는 문자열로 반환할 리스트이다. 반면, pre는 리스트를 출력하기 전 출력할 문자열이며, sep는 원소와 원소 사이에 출력할 분리 문자열이며, 맨 마지막에 출력할 접미사 문자열 post가 있다.

즉, 위의 예시의 경우 "hi!"라는 문자열을 리스트 원소들 출력 전 해당 문자열을 먼저 출력한다. 그리고 리스트 원소들 사이에 공백 없이 출력을 하고 싶어 빈 문자열을 사이사이에 집어넣는다. 그리고 리스트 이후에 "!"를 출력하도록 한 것이다.
여러 리스트 함께 처리하기
우리는 위쪽에서 zip 메서드를 사용해 2개의 리스트를 묶은 것을 알 수 있다. 이렇게 여러 개의 리스트를 묶고 해당 리스트를 한꺼번에 처리는 어떤 방식으로 할까?
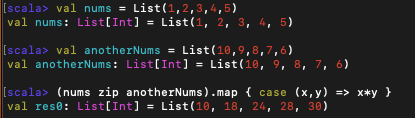
이렇게 zip 메서드를 사용하여 여러 리스트를 함께 처리할 수 있다.
📚 Reference
- Programming in Scala 4/e - Chapter. 16 List
