
이 글은 Programming in Scala 4/e의 Chapter 8을 읽고 작성한 글입니다.
프로그램이 커질수록 관리가 가능한 작은 조각으로 나눌 수 있어야 한다.
스칼라는 이렇게 코드를 분리하여 함수를 만들 때 Java에 존재하지 않는 함수 정의 방법을 몇 가지 제공한다.
메서드 method
함수를 정의하는 가장 흔한 방법은 특정 객체의 멤버로 함수를 만드는 것이다. 객체의 멤버인 함수를 메서드라고 부른다. 다음과 같은 예시 코드를 살펴보자.
import scala.io.Source
object LongLines {
def processFile(filename:String, width:Int) = {
val source = Source.fromFile(filename)
for(line <- source.getLines()){
processLine(filename, width, line)
}
}
private def processLine(filename:String, width:Int, line:String) = {
if(line.length > width)
println(filename + ": "+line.trim)
}
}위의 코드에는 processFile과 processLine이라는 메서드가 있다. 위와 같은 메서드들은 앞 장에서 공부한 내용과 같다. 그럼 다른 함수의 형태에는 무엇이 있을까?
지역 함수
위의 예시에서는 object 내부에 2개의 메서드가 존재하는 형태였다. 위의 예시에서 알 수 있있듯, 다수의 작은 함수로 프로그램을 나누어야 한다는 함수형 프로그래밍의 중요한 설계 원칙을 알 수 있다.
위와 같은 코드는 인터프리터에서는 큰 문제가 되지 않지만, 재사용을 위해 함수를 클래스와 오브젝트로 패키징하려면, 클래스를 사용하는 측에 대해 도우미 함수들을 감추는 것이 좋다.
Java에서는 주로 private method를 사용하고, 위의 예시에서 보듯 스칼라에서도 private method를 사용하는 것이 유효하다. 하지만, 스칼라에서는 함수 안에 함수를 정의할 수 있다. 즉, 지역 변수와 마찬가지로, 함수 안에 정의한 지역 함수도 그 지역변수를 감싸고 있는 블록 내에서만 접근할 수 있다.
def processFile(filename:String, width:Int) = {
def processLine(filename:String, width:Int, line:String) = {
if(line.length > width)
println(filename + ": "+line.trim)
}
val source = Source.fromeFile(filename)
for(linen <- source.getLine()) {
processLine(filename, width, line)
}
}아까 위의 method 예제 코드에서 private method를 지역 함수로 나눈 코드이다. 하지만, 지역 함수인 processLine의 스코프는 processFile 내부에서만 살 수 있다. 그리고 조금 더 개선을 할 수 있다.
def processFile(filename:String, width:Int) = {
def processLine(line:String) = {
if(line.length > width)
println(filename + ": "+line.trim)
}
val source = Source.fromeFile(filename)
for(linen <- source.getLine()) {
processLine(filename, width, line)
}
}processLine이 지역 함수이므로 filename과 width가 파라미터로 들어오므로 굳이 지역 함수에서 파라미터로 filename과 width를 받을 필요가 없다.
따라서 바깥 함수의 인자를 사용하는 것은 스칼라에서 제공하는 일반적인 중첩을 보여주는 좋은 예이다.
1급 계층 함수(first-class function)
스칼라는 1급 계층 함수를 제공한다. 1급 계층 함수란 함수를 정의하고 호출할 뿐만 아니라, 이름 없이 리터럴로 표기해 값처럼 주고 받을 수 있는 함수를 뜻한다.
함수 리터럴은 클래스로 컴파일하는데, 해당 클래스를 실행 시점에 컴파일 하면, 함숫값(function value)이 된다.
함수 리터럴은 소스 코드에 존재하는 반면, 함숫값은 실행 시점에 객체로 존재한다는 차이점이 있다.
(x:Int) => x + 1위는 함수 리터럴의 예시이다. 함숫값은 객체이므로 원하는 변수에 저장할 수 있다. 동시에 함숫값은 엄연히 함수이기도 하므로 함수를 호출하는 일반적인 방법대로 괄호를 이용해 실행할 수 있다.
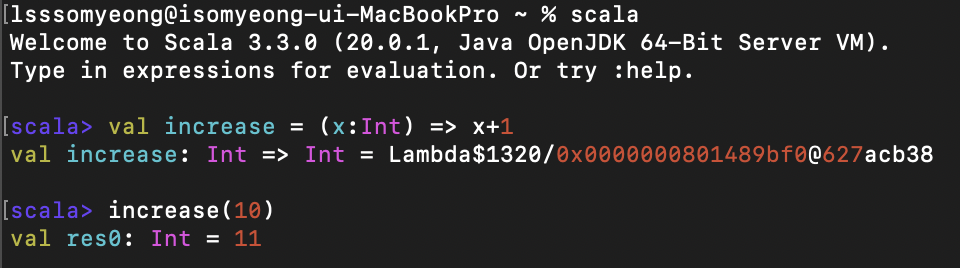
즉, 위와 같이 함수값으로 선언했으면서 함수 호출이 가능한 것이다.
함수 리터럴 역시 본문에 둘 이상의 문장이 필요하다면 일반 메서드 선언 방식과 마찬가지로 중괄호로 감싸서 블록을 만들면 된다.
위치 표시자 문법
함수 리터럴을 더 간결하게 만들기 위해 언더바를 하나 이상의 파라미터에 대한 위치 표시자로 설정할 수 있다.
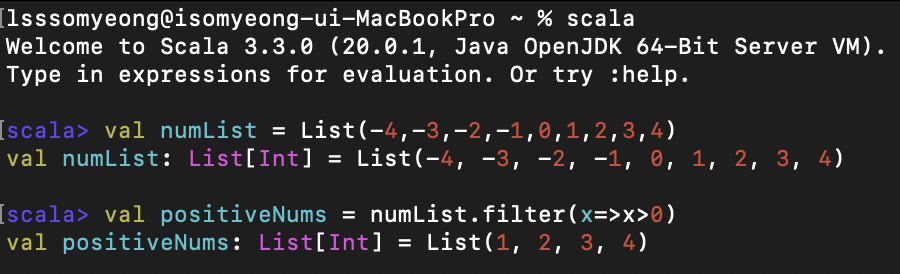
언더바를 사용하지 않은 코드에서는 위와 같이 리스트의 원소를 x로 지정하고 이 x들 중 0초과인 수들을 가져오는 코드인 것이다. 이 코드를 조금 더 간결하게 쓸 순 없을까?

이렇게 언더바를 사용해서 필터링을 걸면 더 간결하게 메서드가 실행된다.
밑줄로 파라미터를 표시하면, 간결하긴 하나 가끔 컴파일러가 인자의 타입 정보를 찾지 못할 경우가 있다.
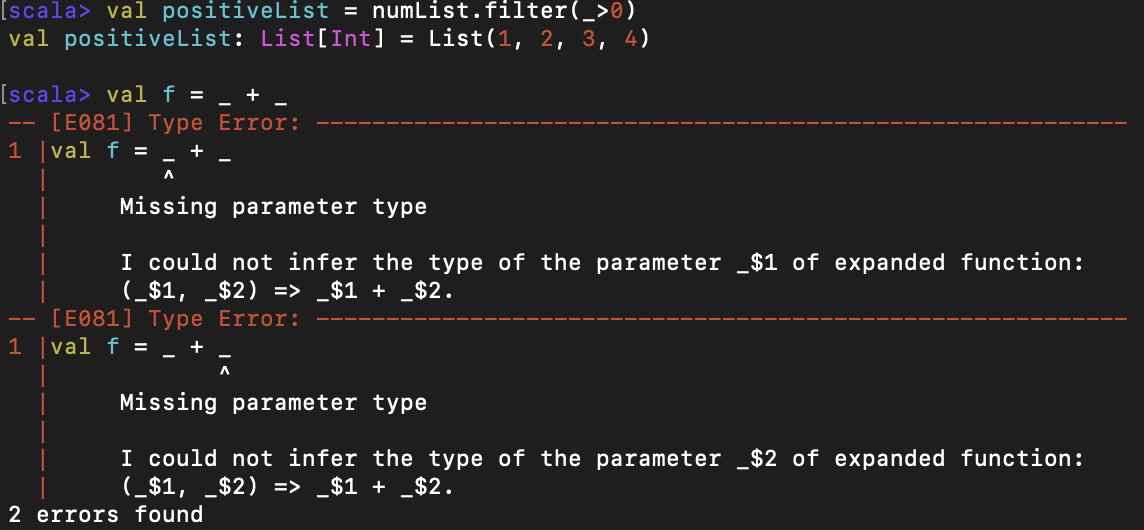
에러 메시지에서 알 수 있듯, 인자 타입 정보를 찾지 못해서 오류가 발생하는 것이다.

따라서 타입을 명시해주면 이를 해결할 수 있다.
클로저
지금까지 진행하며 모든 함수 리터럴 예제는 전달받은 인자만을 참조했다. 하지만, 다른 곳에서 정의한 변수를 참조할 수 있다.
(x:Int) => x + anotherNumber // anotherNumber는 현재 함수 리터럴 스코프에 없다.위에서 anotherNumber는 함수의 관점에서 보면, 함수 리터럴에서 의미를 보유한 것이 아니므로 자유 변수(free variable)다. 대조적으로, x는 함수의 문맥 안에서만 의미 있으므로 바운드 변수(bound variable)이다.
주어진 함수 리터럴부터 실행 시점에 만들어낸 객체인 함숫값을 클로저(closure)라고 부른다. 클로저라는 이름은 함수 리터럴의 본문에 있는 모든 자유 변수에 대한 바인딩을 '포획'해서 자유 변수가 없게 "닫는" 행위에서 따온 말이다.
바인딩(binding)
변수 이름과 스코프 상에서 실제 값 또는 변수 위치 등에 대한 연결
즉, 자유 변수가 없는 함수를 닫힌 코드 조각(closed term)이라고 부르며, 엄밀히 말하면 닫힌 코드 조각은 클로저가 아니다.
(x:Int) => x + 1위의 함수 리터럴은 자유 변수가 존재하지 않는 리터럴이다. 즉, 닫힌 코드 조각이다. 닫힌 코드 조각은 자유 변수를 바인딩할 필요가 없으므로 클로저에 포함되지 않는다.
(x:Int) => x + anotherNumber하지만 위의 함수 리터럴은 자유 변수가 존재하며, 이렇게 자유 변수가 존재하는 리터럴을 열린 코드 조각(open term)이라고 부르며, 바인딩이 필요하므로 클로저인 것이다.
디폴트 인자값
스칼라에서 파라미터의 디폴트값을 지정할 수 있다. 디폴트값을 지정한 파라미터가 있다면, 함수 호출 시 해당 인자를 생략할 수 있다.
def printTime(out: java.io.PrintStream =
Console.out, divisor:Int = 1)
= out.println("time = "+System.currentTimeMillis()/divisor)위의 예시는 out이라는 변수에 아무것도 들어가지 않는다면, Console.out을 default 값으로 넘기며, divisor에 아무것도 없으면 1이 디폴트 값으로 실행되는 것이다.

조금 더 이해하기 쉬운 형태이다. add라는 메서드는 두 수 x와 y를 더하는 메서드이다. x의 디폴트 값은 0이며 y의 디폴트 값은 1이다. 인자가 하나만 들어왔을 때 앞에 파라미터 명을 입력하여 명시해주면 자동으로 디폴트 값을 넣어 계산해주는 것을 알 수 있다.
📚 Reference
- Programming in Scala 4/e - Chapter 8
