
JDBC는 Java Database Connectivity의 약자이며, JPA는 Java Persistent API의 약자이다. JDBC의 이름에서 알 수 있듯, DB와 연관이 있다는 것을 알 수 있다. 그리고 JPA 역시 P가 가리키는 영속성(Persistent)라는 단어에서 JPA 역시 DB와 연관된 기술인 것을 알 수 있다. 그렇다면 두 기술의 차이점은 무엇일까?
❓ 영속성 (Persistence)
데이터를 생성한 프로그램이 종료되더라도 생성된 데이터가 사리지지 않는 특성을 뜻한다.
영속성을 갖지 않는 데이터는 단지 메모리에서만 존재하므로 프로그램이 종료되면 모두 사라진다. 그러므로 파일 시스템, 관계형 데이터베이스 혹은 객체 데이터베이스 등을 활용하여 데이터를 영구적으로 저장하여영속성을 부여한다.
1. JDBC (Java Database Connectivity)
JDBC는 Java Database Connectivity의 약자로, DB에 접근할 수 있도록 Java에서 제공하는 API이다. JDBC는 주로 Persistence Layer를 구현하기 위해 사용된다.
❓ Persistence Layer
프로그램 아키텍쳐에서 데이터를 생성한 프로그램이 종료되더라도 사라지지 않도록영속성을 부여하기 위해 존재하는 Layer
모든 Java Data Access 기술들을 JDBC를 기본적으로 사용하고 있고, 현재 사용되는 Java Data Access 기술들은 순수하게 JDBC만 사용했을 때의 단점들을 보완한 형식이다.
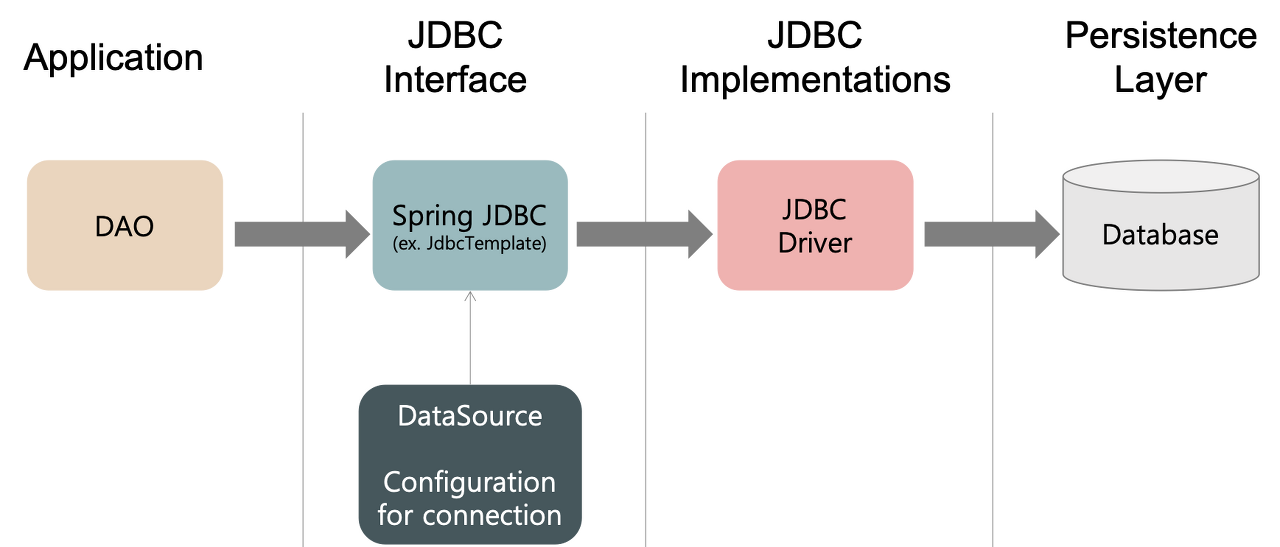
위 그림은 JDBC의 동작 방식을 시각화한 표이다.
JDBC를 사용하여 DB를 연결할때의 코드는 밑과 같다.
@Override
public Member save(Member member) {
String sql = "insert into member(name) values(?)";
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
try {
conn = getConnection();
pstmt = conn.prepareStatement(sql,
Statement.RETURN_GENERATED_KEYS);
pstmt.setString(1, member.getName());
pstmt.executeUpdate();
rs = pstmt.getGeneratedKeys();
if (rs.next()) {
member.setId(rs.getLong(1));
} else {
throw new SQLException("id 조회 실패");
}
return member;
} catch (Exception e) {
throw new IllegalStateException(e);
} finally {
close(conn, pstmt, rs); }
}
@Override
public Optional<Member> findById(Long id) {
String sql = "select * from member where id = ?";
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
try {
conn = getConnection();
pstmt = conn.prepareStatement(sql);
pstmt.setLong(1, id);
rs = pstmt.executeQuery();
if(rs.next()) {
Member member = new Member();
member.setId(rs.getLong("id"));
member.setName(rs.getString("name"));
return Optional.of(member);
} else {
return Optional.empty();
}
} catch (Exception e) {
throw new IllegalStateException(e);
} finally {
close(conn, pstmt, rs);
}
}순수하게 JDBC로만 구성된 코드는 반복되는 코드들이 굉장히 많고, try-catch문들과 connection가지 하나의 파일 안에서 해결하므로 중복 코드가 굉장히 많아진다는 단점이 있다.
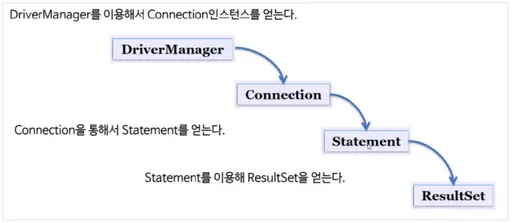
위 그림처럼 쿼리를 실행하기 전과 후에 연결 생성, 명령문, ResultSet 닫기 등과 같은 코드를 작성해야하므로 복잡해 지는 것이다.
순수하게 JDBC를 사용한 것에서 조금 발전한 기술이 Spring JDBC이다. Spring JDBC는 JDBC에서 DriveManager가 하는 일들을 JdbcTemplate에 맡긴다. 따라서 개발자는 메서드에 쿼리를 직접 매핑한다. 이렇게 SQL Query를 직접 작성하여 데이터를 조작하는 것을 SQL Mapper라고 하며, JdbcTemplate은 SQL Mapper 중 하나이다.
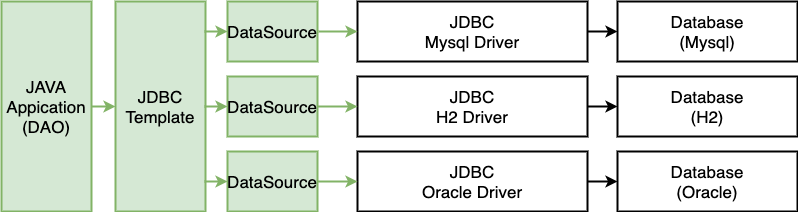
@Override
public Member save(Member member) {
// sql을 직접 짜지 않는 방법
SimpleJdbcInsert jdbcInsert = new SimpleJdbcInsert(jdbcTemplate);
jdbcInsert.withTableName("member").usingGeneratedKeyColumns("id");
Map<String, Object> parameters = new HashMap<>();
parameters.put("name", member.getName());
Number key = jdbcInsert.executeAndReturnKey(new
MapSqlParameterSource(parameters));
member.setId(key.longValue());
return member;
}
@Override
public Optional<Member> findById(Long id) {
List<Member> result = jdbcTemplate.query("select * from member where id = ?", memberRowMapper(), id);
return result.stream().findAny();
}확연하게 순수한 JDBC를 사용했을 때보다 JdbcTemplate을 사용했을 때 코드의 양이 줄어든 것이 보인다.
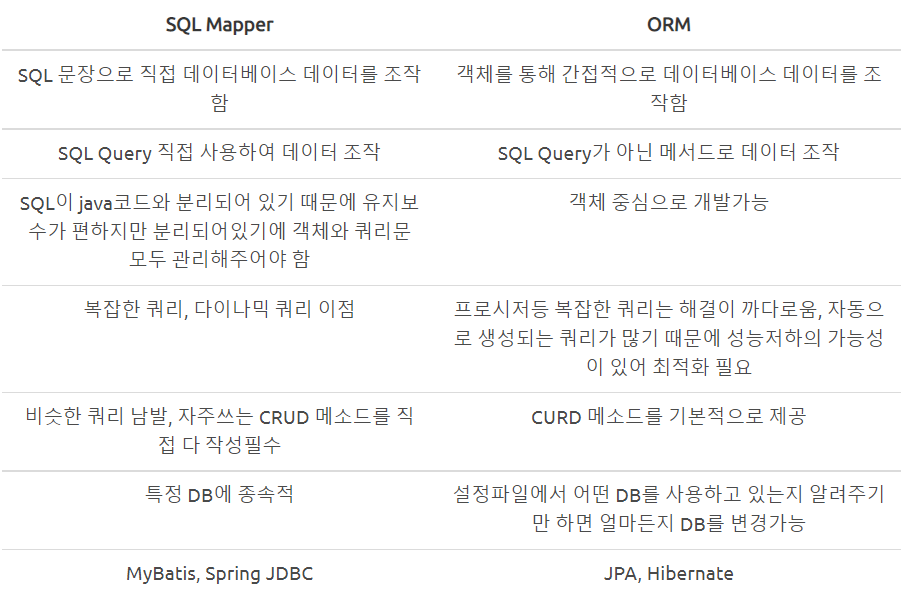
✅ SQL Mapper vs ORM
Spring JDBC를 언급하며 쿼리문을 직접 다루는 것을 SQL Mapper라고 했다. 그리고 SQL Mapper와 항상 같이 나오는 개념은 ORM(Object Relational Mapper)이다. ORM은 직접 데이터를 다루지 않는 것을 말한다. 즉, ORM은 JDBC를 기본으로 해되, SQL 맵핑이 아닌 Object Relational DB를 맵핑하는 방식을 사용하여 개발자가 SQL을 적어줄 필요가 없는 객체 지향적인 Java Data Access 방식이다.
따라서 개발자는 SQL을 작성하지 않는 대신 메서드를 이용하여 데이터를 조작하게 되고, 객체 간의 관계를 바탕으로 ORM이 자동으로 SQL를 생성해준다. ORM의 대표적인 예시가 JPA이다.
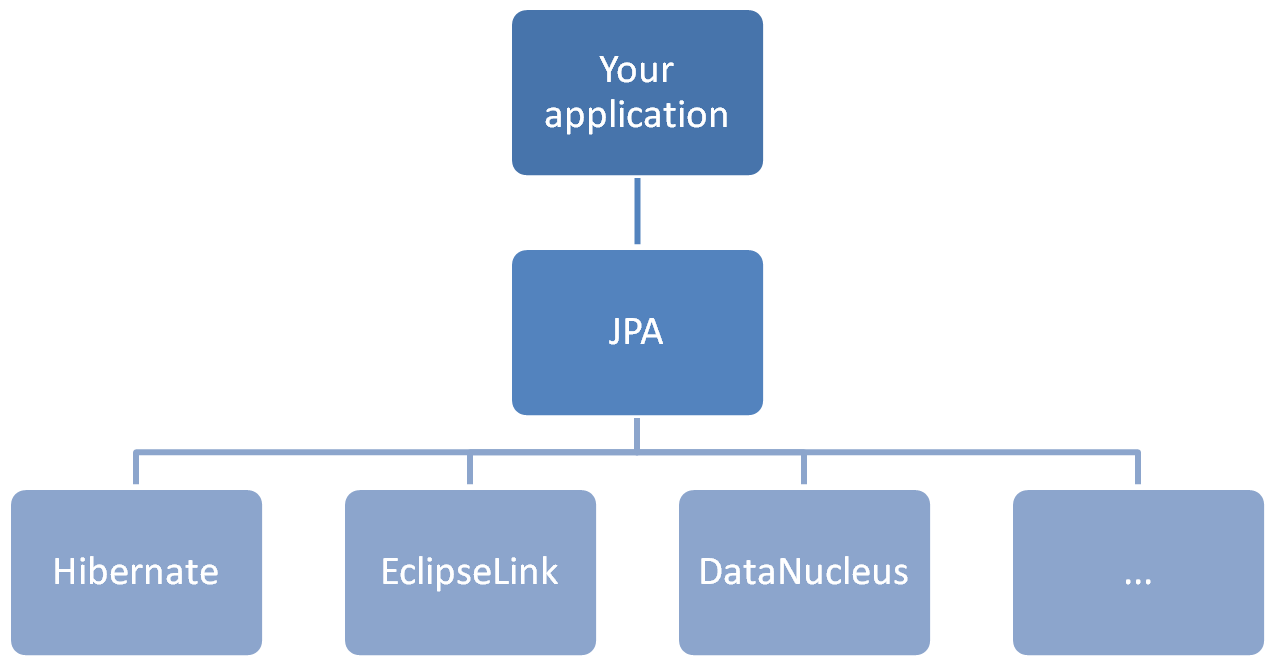
위는 ORM의 구조를 나타낸 것이다. DAO 뒤에 Spring JDBC 대신 JPA가 온다. JPA의 구현체로는 Hibernate, EclipseLink, DataNucleus 등이 있다.
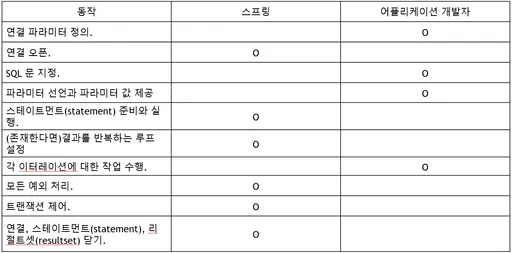
SQL Mapper와 ORM의 차이를 표로 정리하면 밑과 같다.
2. JPA (Java Persistent API)
JPA는 Java ORM 기술에 대한 API 표준 명세로, Java에서 제공하는 API이다. 즉, ORM을 구현하기 위한 표준 인터페이스이다. 이때, JPA는 인터페이스이므로 이를 구현할 수 있는 기술들이 필요하고, 가장 대표적으로는 hibernate가 있다.
JPA를 사용하면 SQL문을 직접 java application 내에서 적을 경우가 적어진다. 따라서 기본적인 CRUD 쿼리를 반복적으로 작성하지 않아도 되며 수정사항이 발생하였을 때 수정해야할 코드가 적다.
하지만, 메서드 호출로 쿼리 실행은 직접 SQL을 호출하는 것보다 성능이 떨어질 수 있다. 거기에, 복잡한 통계 분석 쿼리를 메서드 호출로 처리하는 것은 어려우므로 로직이 복잡하거나 불필요한 쿼리가 발생할 수 있다.
아까 JDBC에서 예시로 사용했던 코드를 JPA로 바꾸면 다음과 같다.
@Override
public Member save(Member member) {
em.persist(member);
return member;
}
@Override
public Optional<Member> findById(Long id) {
Member member = em.find(Member.class, id);
return Optional.ofNullable(member);
}JdbcTemplate을 사용했을 때보다 훨씬 짧고 가독성이 좋아졌다.
게다가 메서드를 통해 Data Access가 가능하므로 객체지향적이다.
(1) JPA의 INSERT
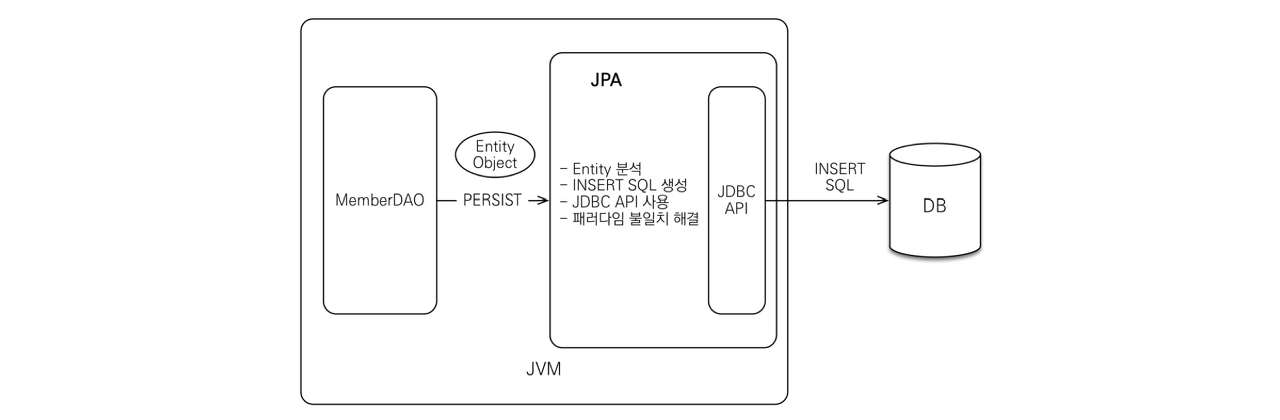
DAO에서 객체를 저장하고 싶을 때 개발자는 JPA에 Member 객체를 넘긴다.
그러면 JPA는 Member 엔티티를 분석 후 INSERT SQL 쿼리문을 생성하여 JDBC API를 사용하고 SQL를 DB에 날린다.
(2) JPA의 SELECT(find)
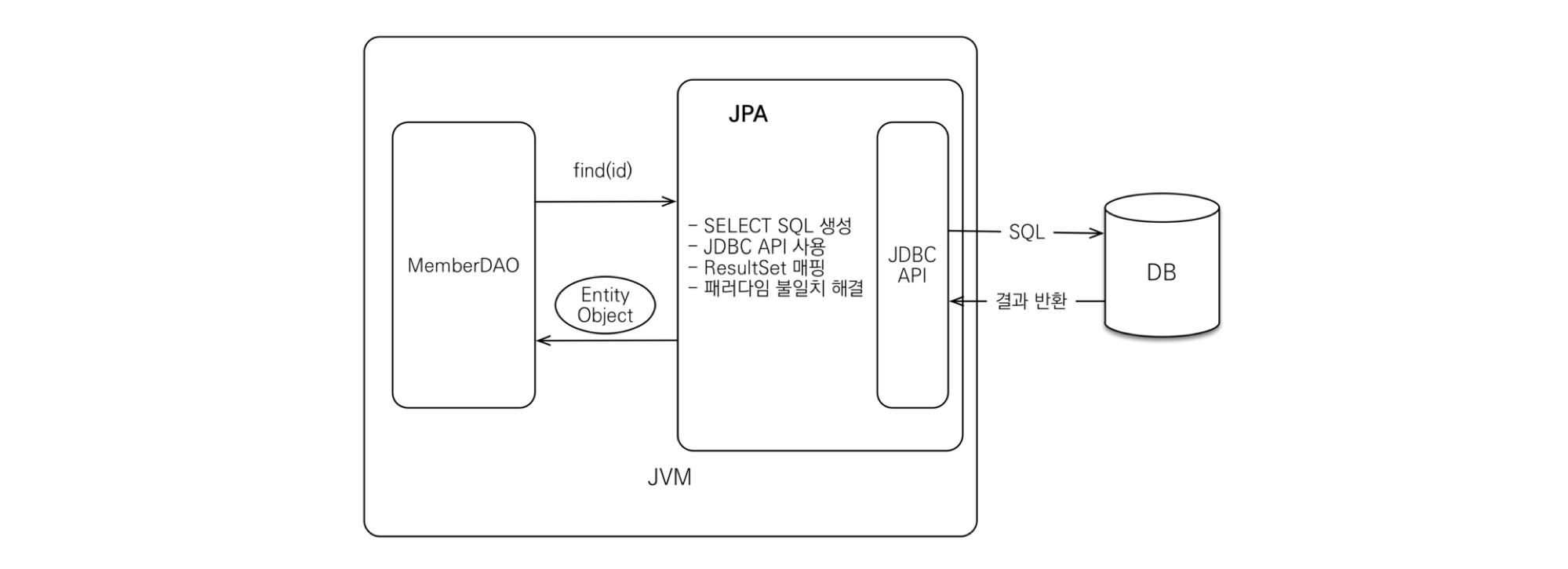
SELECT에 해당하는 조회를 JPA에서는 어떻게 동작할까?
개발자는 DAO에서 조회하려는 데이터의 PK 값을 JPA에 넘긴다. 그러면 JPA는 엔티티 매핑 정보를 바탕으로 적절한 SELECT SQL 쿼리문을 생성한 후, JDBC API를 사용하여 SQL을 DB에 날린다. 그 후 DB에서 받아온 결과(ResultSet)를 객체에 모두 매핑한다.
이때, 쿼리를 JPA가 생성하므로 Object와 RDB간의 패러다임 불일치를 해결할 수 있다.
