
📝 오늘 한 것
-
빅오 표기법 / 선형 검색 / 이진 검색 / 버블 정렬 / 선택 정렬 / 삽입 정렬 / 해시 테이블 / 해시 함수 / 추상적 자료 구조(ADT)
-
자바스크립트 강의 복습 및 정리
📖 학습 자료
-
노마드 코더 유튜브 '알고리즘.데이터구조 with Nico' 3 ~ 7편
-
드림코딩 유튜브 '자바스크립트 기초 강의' 1 ~ 8편
📚 배운 것
1. 알고리즘
- 작업을 수행하기 위해 거쳐야 할 단계들
- 시간 복잡도 개념이 존재함 (단계가 적을수록 성능이 좋다)
1) 빅오 표기법(Big-O nation)
- 빅오 표기법은
알고리즘의 시간 복잡도를 표기하는 방법이다.- 알고리즘의 스피드는 시간이 아니라
완료까지 걸리는 단계의 수로 표현된다.- 빅오 표기법에서 상수와 같은 숫자들은 모두 1이 된다.
- 빅오 표기법이 모든 알고리즘을 완벽히 설명하지는 못한다.
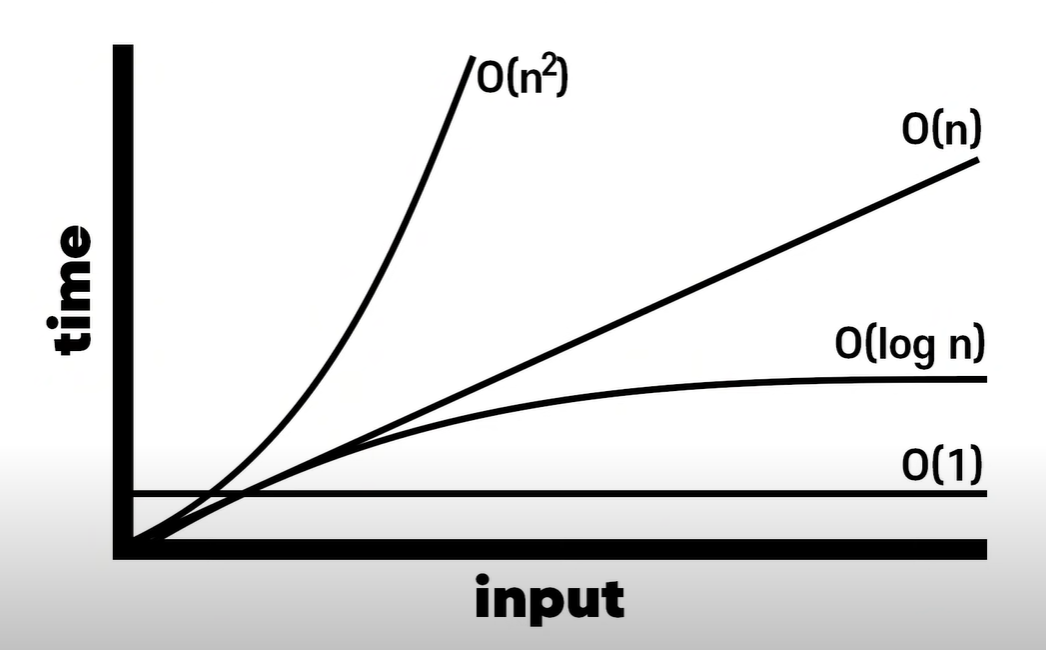
(1) O(N): 선형 시간
-
인풋의 크기가 N이라면, N 단계가 요구됨을 의미한다.
-
배열의 각 아이템을 모두 프린트하는 함수가 있다고 치자. 알고리즘의 시간 복잡도는 O(N)이다. 같은 작업을 2번 반복하더라도 알고리즘의 시간 복잡도는 O(2N)이 아니라 O(N)이다.
(2) O(1): 상수 시간
-
인풋의 크기와 상관없이, 동일한 수의 단계가 요구됨을 의미한다. -
배열의 첫 번째 요소를 프린트하는 함수를 1번 수행한다고 치자. 이 경우 배열의 아이템이 몇 개든 상관없이 작업에 필요한 단계는 항상 한 번이다. 알고리즘의 시간 복잡도는 O(1)이다.
한편, 배열의 첫 번째 요소를 프린트하는 함수를 10번 반복한다고 치자. 이 경우 배열의 아이템이 몇 개든 상관없이 작업에 필요한 단계는 항상 10번이다. 마찬가지로 알고리즘의 시간 복잡도는 O(1)이다.
(3) O(N^2): 2차 시간
-
인풋의 크기가 N이라면, N^2 단계가 요구됨을 의미한다.
-
중첩 반복이 있을 때 발생한다. 루프 안의 루프에서 함수를 실행하는 경우이다. -
2차 시간 말고도 지수 시간이 존재한다.
(4) O(log N): 로그 시간
-
인풋의 크기가 N이라면, 밑이 2인 log N 단계가 요구됨을 의미한다.
-
밑이 2인 로그이다. 어떤 숫자(진수)를 2로 몇 번을 나눠야 1이 나올지 계산한 값과 일맥상통한다. 즉, 배열의 총 길이를 절반씩 몇 번을 나눠야 목표 값을 찾을 수 있을까를 의미한다.
-
정렬된 배열에만 이용할 수 있는
이진 검색 알고리즘의 경우에 해당한다.
2) 검색 알고리즘 (Search Algorithm)
(1) 선형 검색 알고리즘(Linear Search Algorithm)
-
특정 요소를 찾기 위해 인덱스 0부터 순서대로 하나씩 확인해봐야 한다. 최악의 경우, 배열의 처음부터 끝까지 확인해도 찾는 값이 없을 수 있다.
-
배열이 커질수록(배열의 길이가 길어질수록) 시간이 오래 걸린다.(수행해야 하는 단계가 많아진다)
-
선형 시간 복잡도(Linear Time Complexity)
인풋이 많을수록 수행하는 시간이 선형적으로 증가한다
(2) 이진 검색 알고리즘(Binary Search Algorithm)
- 특정한 자료 구조인
정렬된 배열에서만 사용이 가능하다.
💡 정렬된 배열
- 아이템을 추가하는 게 오래 걸리는 대신, 빠르게 아이템을 검색할 수 있다
- 정렬이 안된 배열에서 아이템을 추가할 때는, 공간이 남아 있기만 하면 그냥 맨 뒤에 추가하면 한다.
- 정렬된 배열에서 아이템을 추가할 때는, 인덱스 0부터 추가할 아이템과 기존 아이템들을 비교해 추가할 아이템보다 큰 아이템을 찾은 후, 그 아이템 이후의 아이템들을 뒤로 밀어낸 후에, 만들어진 공간에 아이템을 추가해야 한다.
-
배열의 중앙에 있는 아이템이 찾고 싶은 목표 아이템보다 큰지 작은지를 비교한다. 만약 목표보다 크다면(작다면) 배열의 중앙을 기준으로 왼쪽으로(오른쪽으로) 이동해 또 그 중앙에 있는 아이템이 목표 아이템보다 큰지 작은지를 비교한다. 이 작업을 반복해 목표 아이템을 찾는다.
-
1만 개의 요소를 가진 배열의 경우, 요소를 검색하는 데 선형 검색 알고리즘을 이용한다면 최악의 경우 1만 개의 단계를 거쳐야 한다. 그러나, 이진 검색 알고리즘을 이용한다면 최악의 경우에도 14개의 단계 안에 해결이 가능하다.
이처럼 이진 검색 알고리즘을 이용하면 인풋이 증가하더라도 작업을 수행하는 데 필요한 단계는 훨씬 조금 증가한다. 따라서, 이진 검색 알고리즘은 거대한 배열을 다룰 때 효과적이다.
-
다만, 이를 이용하기 위해선 먼저 배열을 정렬하는 작업에서 시간이 오래 걸린다. 이 상충관계를 고려하여 검색을 많이 해야 한다면 먼저 배열을 정렬하기를 선택할 수 있다.
3) 정렬 알고리즘(Sorting Algorithm)
1) 버블 정렬(Bubble Sort)
-
배열의 2개의 아이템을 비교한 후 왼쪽이 오른쪽보다 크면 아이템을 교환한다. 큰 아이템이 오른쪽에서 더 큰 아이템을 만나면 교환을 멈춘다. 계속해서 더 큰 아이템은 그 다음 아이템과 비교한다.
결국 가장 큰 아이템이 맨 뒤로 이동한 후에 한 싸이클이 끝난다. 정렬된 마지막 아이템을 제외하고 같은 과정을 반복한다.
-
N-1, N-2, N-3...번의 비교를 하고, 최악의 경우에 모든 싸이클마다 모든 아이템을 교환해야 한다.
따라서, 버블 정렬의 시간 복잡도는
O(N^2)이다.
2) 선택 정렬(Selection Sort)
-
전체 배열의 아이템 중 크기가 가장 작은 아이템을 찾아 그 위치(인덱스)를 변수에 저장한다. 이를 이용해 배열의 첫 번째 아이템과 크기가 가장 작은 아이템의 위치를 바꿔준다.
결국 가장 작은 아이템이 맨 앞으로 이동한 후에 한 싸이클이 끝난다. 이미 정렬된 첫 번째 아이템을 제외하고 정렬되지 않은 그 다음 아이템부터 같은 과정을 반복한다.
-
버블 정렬과 마찬가지로 N-1, N-2, N-3...번의 비교를 하지만, 버블 정렬과 달리 최악의 경우에도 모든 싸이클마다 모든 아이템을 교환하지는 않는다. 선택 정렬은 매 싸이클마다 가장 크기가 작은 아이템을 찾아 한 번씩만 교환하기 때문이다. 따라서, 선택 정렬이 버블 정렬보다 빠르다.
그러나, 선택 정렬의 시간 복잡도 또한
O(N^2)이다.
3) 삽입 정렬 (Insertion Sort)
-
먼저, 인덱스 1에 위치한 아이템을 변수에 저장한다. 인덱스 1에 위치한 아이템보다 인덱스 0에 위치한 아이템의 크기가 크면, 인덱스 0에 위치한 아이템을 인덱스 1로 보낸다. 왼쪽에 더 이상 비교할 아이템이 없으므로 변수에 저장해놓은 아이템을 인덱스 0에 삽입한다.
그 후, 인덱스 2에 위치한 아이템을 변수에 저장한다. 인덱스 2에 위치한 아이템과 인덱스 1에 위치한 아이템을 비교해, 인덱스 2에 위치한 아이템보다 인덱스 1에 위치한 아이템의 크기가 크면, 인덱스 1에 위치한 아이템을 인덱스 2로 보낸다. 다시 인덱스 2에 위치한 아이템과 인덱스 0에 위치한 아이템을 비교해, 인덱스 2에 위치한 아이템보다 인덱스 0에 위치한 아이템의 크기가 크면, 인덱스 0에 위치한 아이템을 인덱스 1로 보낸다.
그 다음 인덱스들에 위치한 아이템들도 같은 과정을 반복한다. 즉, 기준이 되는 수와 왼쪽 수들을 비교해, 기준이 되는 수가 왼쪽 끝에 다다르거나 기준이 되는 수보다 작은 수가 나올 때까지, 비교와 교환을 계속한다.
-
삽입 정렬은 선택 정렬보다 빠르다. 선택 정렬은 모든 아이템을 스캔하는 반면(최솟값을 찾기 위해 모든 수를 스캔한다.),
삽입 정렬은 필요한 아이템만 스캔하기 때문이다.(기준이 되는 수보다 작은 수가 나오면 스캔을 멈춘다.)그러나, 삽입 정렬의 시간 복잡도 또한
O(N^2)이다.
💡 위 3가지 알고리즘은 제각각 그 퍼포먼스는 다르지만, 모두 같은 Big-O를 가지고 있다. 이는 최악의 시나리오를 중심으로 판단한 결과이다.
2. 자료 구조
1. 해시 테이블(Hash Table)
- 해시 테이블은 이미 수많은 프로그래밍 언어에 내장되어 있다.
- JavaScript의 Object, Python의 Dictionary, GO의 Map 등이 이에 해당한다.
1) 배열 VS 해시 테이블
ex) 메뉴들 가운데 피자의 가격을 알고 싶은 경우
(1) 배열
menu = [
{ name: 'coffee', price: 10 },
{ name: 'burger', price: 15 },
{ name: 'tea', price: 5 },
{ name: 'pizza', price: 10 },
{ name: 'juice', price: 5 }
];-
위 배열에서 피자 가격을 알고 싶다면, 선형 검색을 해야 한다.
-
이 경우, 시간 복잡도는 O(N)이다.
(2) 해시 테이블
- 해시 테이블은
키-값(key-value)시스템을 이용해 자료를 정리한다.
menu = {
coffee: 10,
burger: 15,
tea: 5,
pizza: 10,
juice: 5
};-
해시 테이블에서 피자의 가격을 알고 싶다면, 피자를 key로 하여, 해시 테이블이 그 value로 제공한 피자의 가격을 찾으면 된다.
-
이 경우,
시간 복잡도는 O(1)이다. -
얼마나 긴 메뉴판이든, 피자의 가격을 찾을 때는 항상 1개의 단계를 필요로 하기 때문이다. 다른 메뉴의 가격을 찾을 때도 마찬가지이다.
2) 특정 요소가 배열에 있는지 확인하는 법
ex) 국가들 = ['한국', '미국', '영국', ... ]
'태국'이 해당 리스트에 있는지 확인하고 싶다면?
- 국가 이름을 key로 하고, value를 true로 하는 해시 테이블을 만든다.
국가들 = {
'한국': true,
'미국': true,
'영국': true,
⋮
};-
이 경우,
시간 복잡도는 O(1)이다. -
국가가 얼마나 많든, 태국이 해당 리스트에 있는지 확인하기 위해서는 항상 1개의 단계를 필요로 하기 때문이다. 다른 국가를 확인할 때도 마찬가지이다.
console.log(국가들['한국']); // true
console.log(국가들['태국']); // undefined3) 해시 함수 (Hash Function)
[자료구조 알고리즘] 해쉬테이블(Hash Table)에 대해 알아보고 구현하기 참고
(1) 해시 테이블이 배열보다 빠른 이유
- 배열에서는 값에 접근하기 위해 인덱스를 이용한다. 그렇다면 똑같이 배열 구조를 가지는 해시 테이블이 배열보다 빠른 이유는 무엇일까? 이는 바로 해시 함수(Hash Function) 때문이다.
💡 해시 테이블의 작동 원리
HashFunc(key) → HashCode → Index → Value
검색하고자 하는 key 값을 입력해, 해시 함수를 통해 돌려 받은 해시 코드를, 배열의 인덱스로 환산해, value에 접근할 수 있다.
-
key 값은 문자열, 숫자, 파일 데이터 모두 가능하다. -
해시 함수는 특정한 규칙(해시 함수의 알고리즘)을 이용하여, 입력받은 key 값이 얼마나 큰지와 상관없이, 항상 동일한 key에 대하여 동일한해시 코드를 생성해준다. 이때, 해시 함수를 이용해 만든 해시 코드는 정수이다. -
배열의 공간은 고정된 길이만큼 미리 만들어 놓는다. 해시 코드를 배열의 길이로 나머지 환산을 함으로써 배열의
인덱스로 환산한다. 그 key 값에 해당하는value를 각 배열의 인덱스 공간에 나눠 담게 된다. -
따라서, 해시 테이블의 검색 속도는 매우 빠르다.
왜냐하면
key를 해싱해 만든 해시 코드 자체가 배열의 인덱스로 사용되므로따로 검색 자체를 할 필요가 없이해시 코드를 이용해 바로 데이터의 위치에 직접 접근할 수 있기 때문이다.
(2) 해시 충돌(Hash Collision)
-
해시 함수가 입력받은 key를 이용해 배열의 여러 공간에 value를 얼마나 골고루 잘 분배하느냐가
해시 함수 알고리즘의 성능을 결정한다. -
해시 함수의 알고리즘이 좋지 않으면, 같은 공간에 데이터가 여러 개 들어가게 되어
해시 충돌(Hash Collision)이 발생한다. -
해시 충돌이 일어나는 경우
① 다른 keys → 같은 Hashcode
해시 함수는 서로 다른 key 값임에도 동일한 해시 코드를 만들기도 한다. key 값은 문자열이 올 수 있기 때문에 그 가지 수가 무한한 데 반해, 해시 코드는 정수 개수만큼밖에 없기 때문이다.
② 다른 HashCode → 같은 index
한편, 해시 함수가 서로 다른 key 값에 대해 서로 다른 해시 코드를 만들었음에도, 해시 코드를 인덱스로 환산하는 과정에서, value가 같은 공간에 배정받기도 한다. 배열의 공간이 한정되어 있기 때문이다.
-
이를 해결하기 위해
연결 리스트(Linked List)를 이용할 수 있다. key 값과 그 value로 구성된 데이터들을 하나의 배열 공간에 담는 것이다. -
그 안의 값을 찾으려면
선형 검색해야 하므로, 최악의 경우 해시 테이블의시간 복잡도는 O(N)이 될 수도 있다.
2. 추상적 자료 구조(Abstract Data Type)
추상적 자료 구조(ADT)란 자료 구조의 방법이 코드로 정의되어 있지 않고, 그 자료 구조의행동 양식만 정의되어 있는자료 구조를 말한다.- 행동 양식만 이해하면, 다른 자료 구조에 직접 적용해 사용할 수 있다.
- 스택(Stack)과 큐(Queue)는 다른 알고리즘에도 쓰인다.
[TIL] 211007 2.이론 공부 필기(원 노트) 참고
1) 스택(Stack)
LIFO(Last In, First Out)
새로운 요소는 스택(Stack)의 맨 위에 추가되고, 삭제도 맨 위에서부터 할 수 있다.
ex) 웹 브라우저의 뒤로 가기 버튼 클릭(웹 페이지 히스토리 스택의 맨 위 페이지를 가져간다), ctrl+z 눌러서 문서 내용 되돌리기
2) 큐(Queue)
FIFO(Fisrt In, Fisrt Out)
새로운 요소는 큐(Queue)의 맨 뒤에 추가되고, 삭제는 맨 앞에서부터 할 수 있다.
ex) 이메일 전달, 푸시 알림 기능, 쇼핑몰에서 주문을 처리하는 방식(선착순)
3. 자바스크립트 강의 복습
드림코딩 유튜브 자바스크립트 기초 강의 (1 ~ 9편) 복습 완료. 아래에는 지금은 알지만 당시에 이해가 안됐던 부분들이나 당시에 이해했어도 한번 더 정리하고 싶은 내용을 적었다.
불과 한 달 전쯤만 해도 고작 20분여짜리 강의들을 이해하기 위해 노력하고 블로그에 글로 정리하는 데까지 반나절 이상이 걸렸었는데 지금 2배속으로 다시 보면서 당시 이해가 안됐던 부분들까지 술술 이해가 되니까 신기하다. 지금 어렵게 느껴지는 부분들도 언젠가 그럴 날이 오겠지..?
1) async VS defer
(1) head 안에 <script src="main.js"></script>라고 쓰는 경우
브라우저가 HTML 파일을 파싱하는 초반에 이 구문을 만나면 파싱을 멈추고 main.js 파일을 다운 및 실행한다. 그 후에 HTML 파일의 남은 파싱을 끝낸다. 이 경우, main.js 파일의 크기가 크다면 사용자가 브라우저 화면을 보는 게 늦어질 수 있다. 또한, 자바스크립트가 동적으로 돔 요소를 받아와야 하는 경우 아직 HTML에 해당 요소가 정의되어 있지 않아 문제가 생길 수 있다.
(2) body 끝에 <script src="main.js"></script>라고 쓰는 경우
브라우저가 HTML 파일 파싱을 끝낸 후에야 main.js 파일을 받고 실행한다. 이 경우, 웹 사이트가 자바스크립트에 의존적이라면 HTML이 미리 받아져도 화면이 정상적으로 보이지 않을 수 있다.
(3) head 안에 <script src="main.js" async></script>라고 쓰는 경우
브라우저가 HTML 파일을 파싱하는 초반에 이 구문을 만나면 main.js 파일과 병렬적으로 다운을 진행한다. 자바스크립트가 먼저 받아지면 HTML 파싱을 멈추고 자바스크립트를 실행한다. 이 경우에도, (1)의 경우보단 덜하지만 사용자가 브라우저 화면을 보는 게 늦어질 수 있고, 자바스크립트가 동적으로 돔 요소를 받아와야 하는 경우 문제가 생길 수 있다.
(4) head 안에 <script src="main.js" defer></script>라고 쓰는 경우
브라우저가 HTML 파일을 파싱하는 초반에 이 구문을 만나면 main.js 파일과 병렬적으로 다운을 진행한다. 자바스크립트가 먼저 받아져도 HTML 파싱은 멈추지 않고, HTML이 다 받아지면 그때 이미 다운이 완료되어 있는 자바스크립트를 실행한다. 가장 효율적이고 안전한 방법이다.
💡 다수의 script를 다운받는 경우
- async : HTML에 정의된 script 순서와 상관없이, 먼저 다운로드 완료된 js 파일부터 실행한다.
defer: HTML을 파싱하는 동안 모든 js 파일을 미리 받아놓은 후 HTML이 다 받아지면 그때HTML에 정의된 script 순서에 따라실행한다.
2) 동등 비교
console.log(0 == false); // true
console.log(0 === false); // false
console.log(null == undefined); // true (주의!)
console.log(null === undefined); // false3) 기본 매개변수
매개변수에 값이 전달되지 않았을 때, 기본으로 출력될 매개변수를 설정할 수 있다.
function showMessage(message, from = 'human') {
console.log(`${message} by ${from}`);
}
showMessage('Hi!'); // Hi by human4) 나머지 매개변수
매개변수를 배열 형태로 전달할 수 있다
function printAll (...args) {
for (let i = 0; i < args.length; i++) {
console.log(args[i]); // 1 2 3
}
for (const arg of args) {
console.log(arg); // 1 2 3
}
args.forEach((arg) => console.log(arg)); // 1 2 3
}
printAll(1, 2, 3); // 이때, 배열 args = [1, 2, 3]5) early return, early exit
field.addEventListener('click', () => {
if (!started) {
return;
}
// started가 true인 경우에 실행할 내용을 쭉 적어준다
});6) 접근자 프로퍼티
class User {
constructor (firstName, lastName, age) {
this.firstName = firstName;
this.lastName = lastName;
this.age = age; // 💡
}
get age() {
return this.age; // 💡
}
set age(value) {
this.age = value < 0 ? '나이는 음수가 될 수 없음' : value; // 💡
}
}
const user1 = new User('Syong', 'Lee', -1);
console.log(user1.age); // 콜 스택 초과 오류가 뜸get 키워드를 이용해 값을 받아오고, set 키워드를 이용해 값을 설정할 수 있다.
age()라는 getter를 정의해두면, this.age는 바로 메모리의 값을 읽어오는 게 아니라 getter를 호출한다.
age()라는 setter를 정의해두면, = age; 를 통해 바로 메모리의 값을 읽어오는 게 아니라 setter를 호출한다.
따라서, 위처럼 코드를 작성하면 setter에 전달된 value를 this.age에 할당할 때 다시 setter를 호출하게 된다. (생성자 함수 안의 this.age = age; 코드 때문이다.) 결국 setter가 끊임없이 호출되면서 콜 스택(Call Stack) 초과라는 오류가 뜨게 된다.
문제를 해결하기 위해서는 getter와 setter 안의 변수 이름을 다르게 설정해줘야 한다. 보통은 변수 앞에 _를 붙인다.
class User {
constructor (firstName, lastName, age) {
this.firstName = firstName;
this.lastName = lastName;
this.age = age;
}
get age() {
return this._age;
}
set age(value) {
this._age = value < 0 ? '나이는 음수가 될 수 없음' : value;
}
}
const user1 = new User('Syong', 'Lee', -1);
console.log(user1.age); // 나이는 음수가 될 수 없음
console.log(user1._age); // 나이는 음수가 될 수 없음-
User 클래스 안에는 총 3개의 멤버 변수( = 필드 = 전역 변수)가 있다. (firstName, lastName, _age)
-
User 클래스를 이용해 user1이라는 인스턴스 객체를 만들 때, age 값으로 음수를 주면(value < 0) _age의 값은 '나이는 음수가 될 수 없음'이 된다.
-
User 클래스의 멤버 변수는 _age이지만, user1.age라고 호출할 수 있다. setter를 통해 this._age 값을 설정한 후 getter를 통해 this._age를 return 한 값으로, User 클래스 생성자 함수 안의 this.age 값이 설정되기 때문이다.
7) Static: 정적 프로퍼티와 정적 메서드
-
데이터(class 생성자 함수의 인자로 전달하는 값)에 상관없이 공통적으로 쓸 수 있는 값과 메서드 앞에
static이란 키워드를 붙이면, 이들은 class를 통해 생성된 오브젝트와 상관없이 class 자체와 연결된다. -
이를 통해 메모리 사용을 줄일 수 있다. 추후에 타입스크립트에서 많이 사용된다.
class Article {
static publisher = 'LeeSyong';
constructor(articleNumber) {
this.articleNumber = articleNumber;
}
static printPublisher() {
console.log(Article.publisher);
}
}
const article1 = new Article(1);
console.log(article1.publisher); // undefined
console.log(Article.publisher); // LeeSyong
article1.printPublisher(); // not a function 오류
Article.printPublisher(); // LeeSyong8) 상속 & 다양성
super.prop→ 부모 오브젝트의 함수를 호출
class Shape {
constructor(width, height, color) {
this.width = width;
this.height = height;
this.color = color;
}
draw() {
console.log(`${this.color} shape`);
}
getArea() {
return this.width * this.height;
}
}
class Rect extends Shape {} // 상속
const rect = new Rect(3, 4, 'blue');
rect.draw();
console.log(rect.getArea());
class Tri extends Shape {
draw() {
super.draw(); // 부모의 draw() 메서드 호출
console.log('yeah!'); // 재정의
}
getArea() {
return this.width * this.height / 2; // 재정의
}
}
const tri = new Tri(3, 4, 'red');
tri.draw();
console.log(tri.getArea());9) computed property
-
객체 이름['속성 이름'] -
동적으로 key의 value를 받아와야 할 때 이용한다.
const syong = {
name: 'syong',
age: 10
};
function printValue (obj, key) {
console.log(obj[key]);
// console.log(obj.key); → 이렇게 쓰면 undefined가 출력된다
}
printValue(syong, 'age'); // console 창에 10이 출력된다10) in 연산자
해당 객체 안에 해당 key가 있는지 확인해준다
const syong = {
name: 'syong',
age: 10
};
console.log('weight' in syong); // false11) 객체 복제하기(cloning)
const obj1 = {
one: 1,
two: 2
};
// 방법 1
const obj2 = {};
for (key in obj1) {
obj2[key] = obj1[key];
}
// 방법 2
const obj3 = Object.assign({}, obj2);12) 배열 APIs
(1) Array.lastIndexOf()
찾고자 하는 요소를 배열의 맨 끝에서부터 검색하여 요소를 찾으면 그 인덱스를 반환한다.
const arr = ['I', 'my', 'me', 'I', 'mine'];
console.log(arr.indexOf('I')); // 0
console.log(arr.lastIndexOf('I')); // 3
console.log(arr.indexOf('he')); // -1✨ 내일 할 것
-
자바스크립트 강의 복습 마무리 (9편)
-
10편부터 이어서 수강하기
