
문제 설명
이번 포스팅은 백준 2493번: 탑 문제 풀이에 대한 기록입니다.
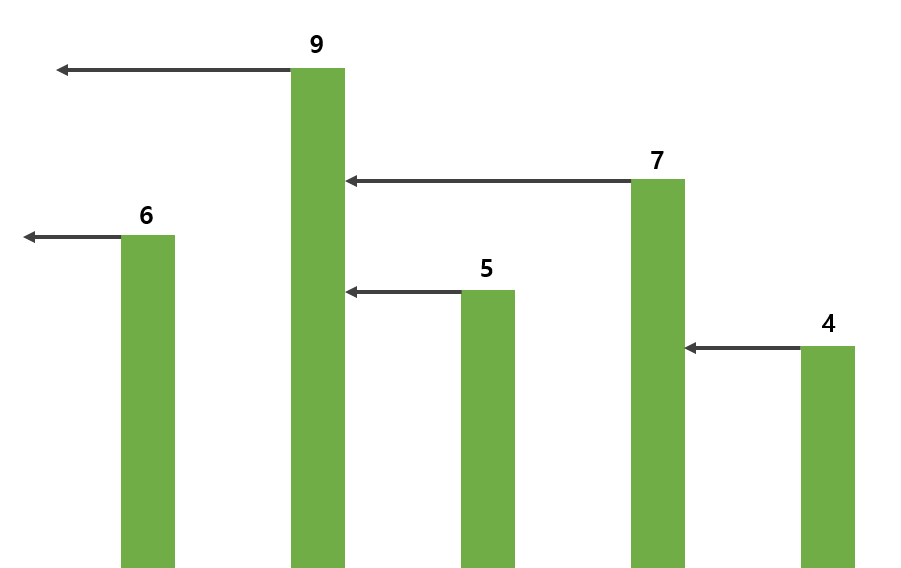
문제를 간단히 요약하자면, "N개의 탑의 높이가 저장된 배열에서, 자신보다 왼쪽에 있는 탑 중에서 자신보다 크거나 같은 가장 가까운 탑을 찾아내는 문제" 입니다.
풀이
1. 그냥 단순하게 차례로 찾아나가면 안될까?
문제를 접했을 때, 가장 단순하게 생각할 수 있는 방법은
"모든 탑들에 대해서 자신보다 높이가 크거나 같은 탑을 만날 때까지 하나씩 쭉 비교하다가 멈추는 것을 반복" 일 것입니다.
그러나 이 방법이 통하면 난이도가 골드V 일 리가 없겠죠?
위에서 말한 방법대로라면, 만약 500,000개의 탑들이 높이가 1~500,000까지 차례대로 커지는 경우에는 비교 횟수가 대충 계산해도 약 1천억 이상이 되어 시간초과가 발생할 것입니다.
2. stack을 이용하여 불필요한 비교 줄이기
stack을 이용하면 반복되는 불필요한 비교를 줄일 수 있습니다.
맨 오른쪽 끝 탑에서부터 시작!
1) stack이 비어있지 않다면, 현재 탐색 중인 탑과 stack의 top을 비교하여
( 현재 탑 >= stack의 top ) 이면 pop하기
2) stack이 비거나, 그렇지 않은 탑이 나올 때까지 1)을 반복
3) 위 과정이 끝나면 현재 탑을 push하고 다음 탑으로
위 방법을 사용하게 되면,
특정 탑에서 자신보다 높은 탑을 만날 때까지 지나가야 하는 작은 탑과의 비교를 줄임으로써 불필요한 비교 연산을 생략할 수 있습니다.
ex) 10 6 1 2 3 4 5 9
i) 9를 차례로 모두 비교해 나간다면, 9의 비교횟수 총 7회
ii) stack을 활용하면, 9의 비교횟수 총 3회
- 5를 stack에 push할 때 5와 비교
- 6을 stack에 push할 때 6과 비교
- 9를 stack에서 pop할 때 10과 비교
이는 위 예시의 일부 다른 탑들에게도 동일하게 적용됩니다.
데이터의 크기가 더 커질수록 두 방법 간의 비교횟수 차이는 더 커질 것입니다.
위 방법을 코드로 작성하면 다음과 같습니다.
from sys import stdin
N = int(stdin.readline())
towers = list(map(int, stdin.readline().split()))
stk = []
answers = ['0'] * N
for i in range(N-1, -1, -1):
while stk and towers[i] >= stk[-1][1]:
answers[stk.pop()[0]] = str(i+1) # 수신하는 탑 번호 기록
stk.append((i, towers[i]))
print(" ".join(answers))stack에 (탑의 index, 높이)를 tuple 형태로 저장하여
위에서 설명한 방식으로 반복하면서, 자신의 신호를 수신하는 탑(자신보다 높은 탑)을 만나면 answers 배열 내 자신의 index에 해당 탑의 index를 기록합니다.
그럼 문제 해결!
후기
이번 문제는 다른 문제들에 비해 "이 솔루션이 왜 더 빠르고 이걸 어떻게 설명할까?" 를 파악하는 것이 왜인지 유난히 어려워서 포스팅하는데 오랜 시간이 걸렸습니다.
현재 내용이 완전히 만족스럽지는 않기 때문에 좀 더 공부해서 나중에 한번 더 살펴볼 필요가 있을 것 같습니다.
어찌됐든 누군가에게 도움이 됐기를 바라며..
결과 코드
from sys import stdin
N = int(stdin.readline())
towers = list(map(int, stdin.readline().split()))
stk = []
answers = ['0'] * N
for i in range(N-1, -1, -1):
while stk and towers[i] >= stk[-1][1]:
answers[stk.pop()[0]] = str(i+1) # 수신하는 탑 번호 기록
stk.append((i, towers[i]))
print(" ".join(answers))