개요
회사에서 자주가는 한식부페가 있다.
이 식당은 메뉴가 매일 바뀌고 오전에 인스타 게시물로 공지해주는데
매일 직원중 한명이 확인하여 알려주는데 이를 자동알림으로 공지할수 있으면 재밌을것같아 만들게 되었다.
오늘은 일명 LUNCH_BOT 을 만들 에정이다.
전체 소스는 아래쪽에 있어요
필요 기능
- 해당 가게 인스타에 접근하기
- 가장 최신 게시물을 가져오기
- 내용읽어서 slack으로 알림쏴주기
- 스케줄로 11시정각에 돌리기
자료 조사를 해보니 크롤링 할때 selenium을 쓴다고 한다.
인스타그램 크롤링의 경우에는 장애물이 2가지 장애물이 존재 하는데
1. 로그인
인스타그램에서 데이터를 얻기 위해서는 먼저 로그인 처리가 되어야 한다.
그렇다면 미리 로그인해놓으면 되지 않을까? 했지만 매번 selenium에서 chrome창이 열리는데,
항상 쿠키가 초기화된 창이기 때문에 설정이 저장되지 않는다.

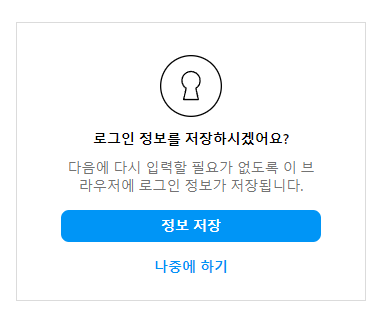
2. 로그인 이후 '로그인정보 저장' modal
로그인 직후 이와 같은 팝업창이 뜨는데 '나중에 하기'를 클릭해줘야 한다.
기능구현
패키지 설치
selenium(셀레니움) 설치가 필요하다.
pip install selenium기본 동작 코드
#selenium
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import time
#01. 웹 열기
dr = webdriver.Chrome()
dr.set_window_size(820, 1000) #브라우저 크기
dr.get('https://www.instagram.com/') #인스타그램 웹 켜기
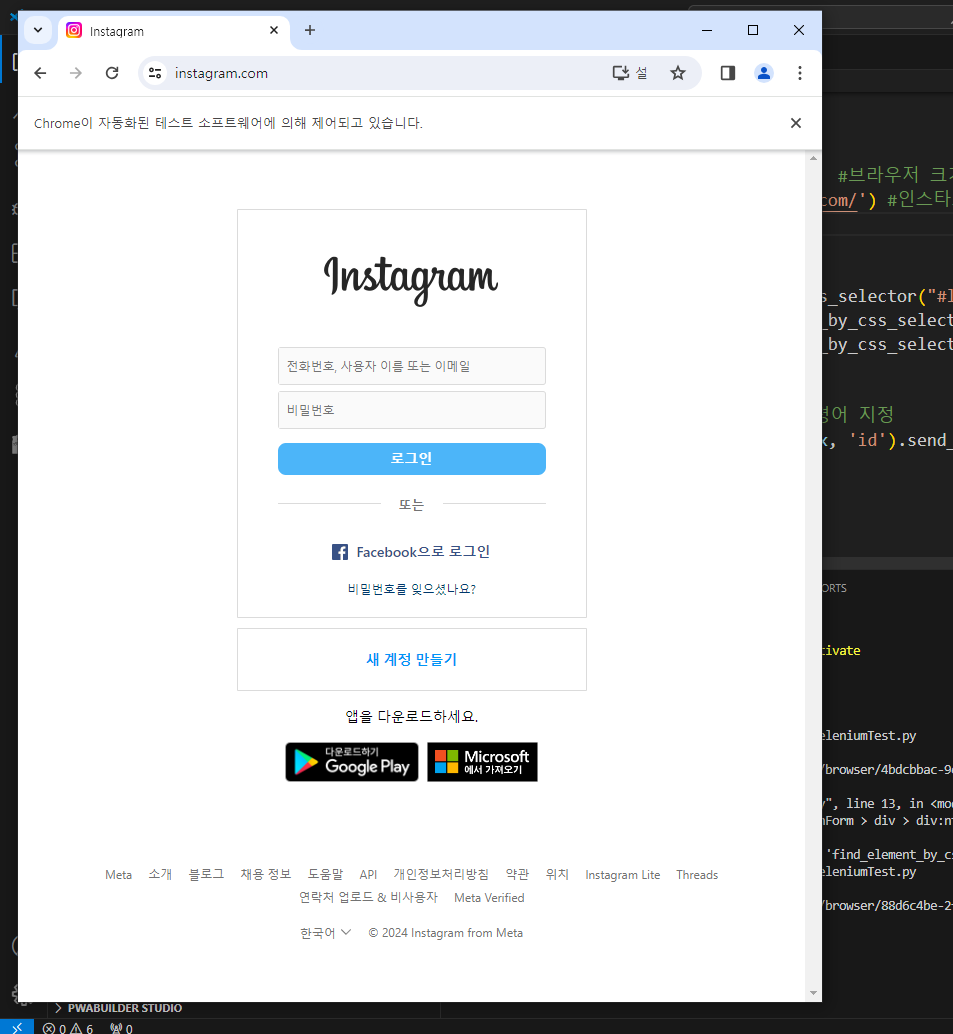
time.sleep(2)실행해보면 내가입력한 url이 입력된 chrome창이 하나 뜬다.
아래에 보면 "Chrome이 자동화된 테스트 소프트웨어에 의해 제어되고 있습니다." 라는 글귀가 있다.
로그인처리
예제 소스를 가져와서 붙어넣기 해준다.
id_box = dr.find_element_by_css_selector("#loginForm > div > div:nth-child(1) > div > label > input") #아이디 입력창
password_box = dr.find_element_by_css_selector("#loginForm > div > div:nth-child(2) > div > label > input") #비밀번호 입력창
login_button = dr.find_element_by_css_selector('#loginForm > div > div:nth-child(3) > button') #로그인 버튼
#동작 제어
act = ActionChains(dr)#동작 명령어 지정
act.send_keys_to_element(id_box, 'id').send_keys_to_element(password_box, 'pwd').click(login_button).perform()#아이디 입력 -> 비밀 번호 입력 -> 로그인 버튼 클릭
time.sleep(2)※ 잘 되는줄 알았는데 아래 오류가 뜨면서 브라우저가 종료된다.

selenim3에서 4버전으로 업데이트 되면서 find_element_by_css_selector는 삭제되었고find_element를 사용하라고 한다.
find_element() 로 변경
아래 코드와 같이 수정해주면 동작하게 된다.
지가 알아서 아이디와 패스워드를 집어넣고 로그인 버튼까지 누른다.
#추가
from selenium.webdriver.common.by import By
id_box = dr.find_element(By.CSS_SELECTOR, "#loginForm > div > div:nth-child(1) > div > label > input") #아이디 입력창
password_box = dr.find_element(By.CSS_SELECTOR, "#loginForm > div > div:nth-child(2) > div > label > input") #비밀번호 입력창
login_button = dr.find_element(By.CSS_SELECTOR, '#loginForm > div > div:nth-child(3) > button') #로그인 버튼
#동작 제어
act = ActionChains(dr)#동작 명령어 지정
act.send_keys_to_element(id_box, 'id').send_keys_to_element(password_box, 'pwd').click(login_button).perform()#아이디 입력 -> 비밀 번호 입력 -> 로그인 버튼 클릭
time.sleep(2)| 속성 |
|---|
| ID |
| XPATH |
| LINK_TEXT |
| NAME |
| TAG_NAME |
| CLASS_NAME |
| CSS_SELECTOR |
크롤링 기능 구현
1. url 변경
인스타 계정을 알고있으니 계정에 접근할수있는 URL로 변경한다.
https://www.instagram.com -> https://www.instagram.com/hola_pork/
2. 첫번째 게시물 클릭
브라우저에서 F12를 눌러 개발자 모드로 들어가면 태그들을 확인 할수 있다.
time.sleep()을 넉넉히 걸고 천천히 찾아보자

각각 한줄씩 3개의 게시물이 있는 형태이고 그중의 1번 div에 접근하여 하위 a태그를 click 해주어야 한다.
과거 jquery가지고 개발해봤던게 많은 도움이 되었다.
$('#tag[attr="value"]:eq(0)').parent().parent().find('li').children()[0]....
어쨌든.. 그렇게 파악한뒤 코드로 작성하면 아래와 같다.
_board_a_tag = dr.find_element(By.CSS_SELECTOR, "div._ac7v.xzboxd6.x11ulueq.x1f01sob.xwq5r7b.xcghwft > div:nth-child(1) > a")
act = ActionChains(dr)
act.click(_board_a_tag).perform()3. 로그인
그러면 로그인창이 뜨게 되는데 위의 예제와는 달리 팝업창으로 뜨기때문에 다시 찾아주어야한다.

오예~ input중에 name 속성을 이용해서 2개 input 태그를 얻을수 있을거 같다.
ID : input[name="username"]
PW : input[name="password"]
그리고 로그인버튼의 경우 아래의 class에 적힌 내용을 전부 써주자
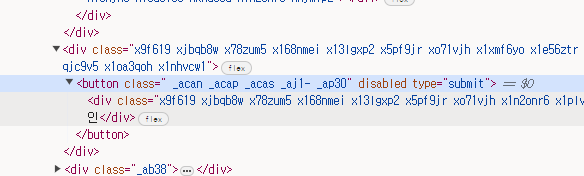
#로그인처리
username_box = dr.find_element(By.CSS_SELECTOR, 'input[name="username"]')
pw_box = dr.find_element(By.CSS_SELECTOR, 'input[name="password"]')
login_btn = dr.find_element(By.CSS_SELECTOR, 'button._acan._acap._acas._aj1-._ap30')
act.send_keys_to_element(username_box, '내ID').send_keys_to_element(pw_box, '비밀번호').perform()
time.sleep(2)
act.click(login_btn).perform()
time.sleep(4)
#정보저장 '나중에하기'
later_btn = dr.find_element(By.CSS_SELECTOR, 'div._ac8f > div')
act.click(later_btn).perform()
time.sleep(5)여기서 의문점
왠지 class안에 값들이 고정값은 아닌거 같은데
바뀌면 어쩌나 하는 생각이 들었지만 ... 다른 방법이 없으니 패스하기로했다.
이것때문에 추후에 다시 만들어야 할지도 모른다는 생각이 들었다.
4. 그다음 다시 게시물 클릭
로그인 처리가 끝나면 다시 화면이 뜨는데 이 화면은 아까 봤던 화면과 달라져서 다시 접근한다.

#로그인완료되면 다시 최신 게시글 올리기
target__ = dr.find_element(By.CSS_SELECTOR, 'div._aagu')
act.click(target__).perform()그러면 아래와같이 게시물이 팝업으로 뜨는데
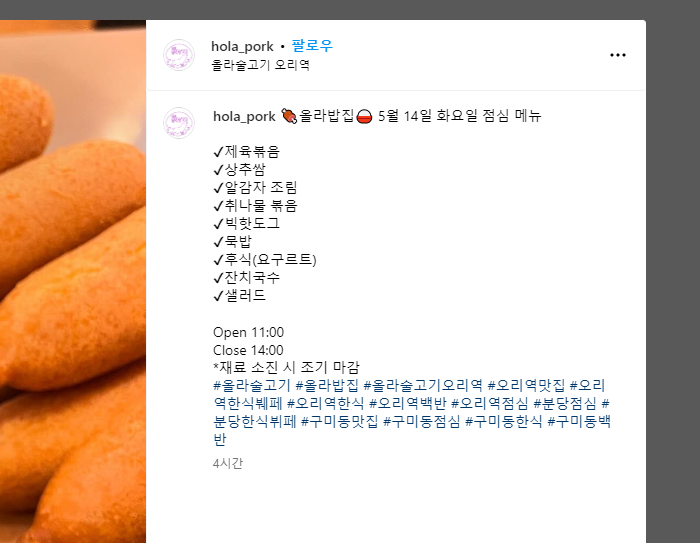
해당하는 class를 전부 때려넣어서 가져와준다.
#팝업창에서 메뉴 정보 얻기
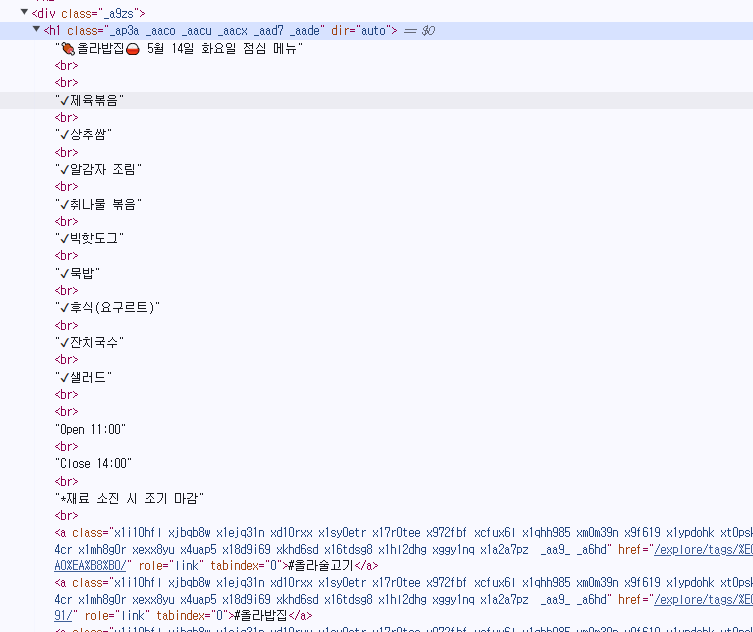
menu = dr.find_element(By.CSS_SELECTOR,'h1._ap3a._aaco._aacu._aacx._aad7._aade')데이터 후처리 및 검증
이제 정보를 얻었으니 브라우저에서 처리할 작업은 다 끝났다.
menu.text로 정보를 불러와서 python 코드 안에서 처리해주도록 하자
데이터를 찍어보면 아래와 같다
print(f'menu_text : {menu.text})'
올라밥집
5월 14일 화요일 점심 메뉴
제육볶음
상추쌈
알감자 조림
취나물 볶음
빅핫도그
묵밥
후식(요구르트)
잔치국수
샐러드
Open 11:00
Close 14:00
*재료 소진 시 조기 마감
#올라술고기 #올라밥집 #올라술고기오리역 #오리역맛집 #오리역한식붸페 #오리역한식 #오리역백반 #오리역점심 #분당점심 #분당한식뷔페 #구미동맛집 #구미동점심 #구미동한식 #구미동백반
- 가끔 게시글이 안올라올수 있으니 2번째 줄의 작성된 날짜와 오늘날짜가 맞는지 판단한다.
- 마지막줄에 태그(#)로 시작하는 줄을 제거 한다.
1번의 경우 정규식으로 작성하고
today = datetime.now().strftime("%m월 %d일")
# 텍스트에서 날짜를 추출하 정규식
date_pattern = r'(\d{1,2}월 \d{1,2}일)'
match = re.search(date_pattern, menu.text)2번은 한줄씩 읽어서 #으로시작(startsWith)하는지 판단한다.(중간에 올수도있으니..)
result_msg = ''
for line in lines:
if not line.startswith('#'):
result_msg += line + '\n'슬랙 보내기
회사에서 slack과 slack-bot을 사용중이니 이걸 활용해서 알림을 발송해주도록 한다.
slack 발송방법에는 두가지가 존재하는데
1. channel과 token을 이용
2. restAPI를 이용한 webhook 방식
조금더 구현이 간단한 webhook방식을 사용하기로 정했다.
서버팀의 도움을 받아 URL을 얻었고 봇 추가방법이나 webhook url을 얻는 방법은 다음에 자세히 다뤄보도록 하겠다.
API 호출이기 때문에 python의 requests를 이용하여 호출할 수 있다.
(내장 함수이기 때문에 설치는 안해도 되고 import만 해주면 된다.)
#요거추가
import requests
def send_slack(_text):
headers = {'Content-type': 'application/json'}
payload = {'text': _text}
response = requests.post('https://hooks.slack.com/services/{...}/{...}/{...}', data=json.dumps(payload), headers=headers)
return response.status_code == 200테스트
slack 알람이 잘 오는것을 확인해보자

굳굳~~ 이제 거의 마무리 되어간다.
스케줄링 작업 등록
윈도우에서 특정 시간마다 실행하기위해서는 '작업 스케줄러'를 이용하면 된다.
스케줄에 등록하기 위해서 pyinstaller로 exe파일로 만든뒤 해당 exe파일을 특정 시간마다 실행시켜주는 작업을 등록하면 된다.
1. exe파일 만들기
pip install pyinstaller 설치후
pyinstaller --onefile lunch_bot.py
이렇게 하면 dist 폴더안에 exe가 생성된다.
2. exe 파일을 실행하는 작업을 생성
윈도우 "작업 스케줄러" 검색
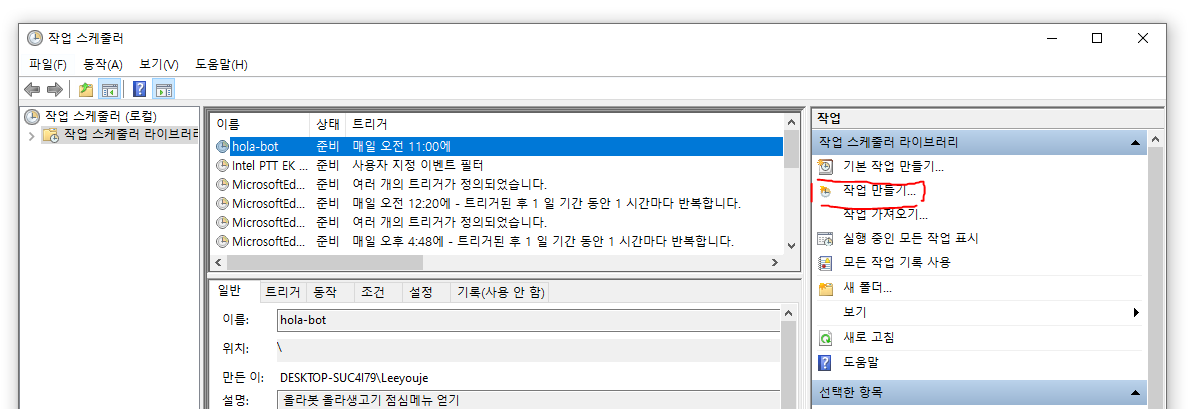
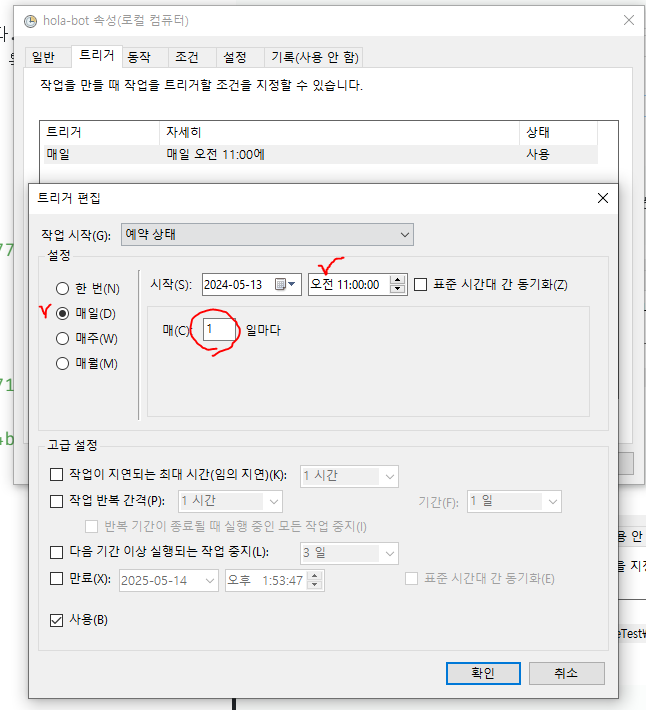
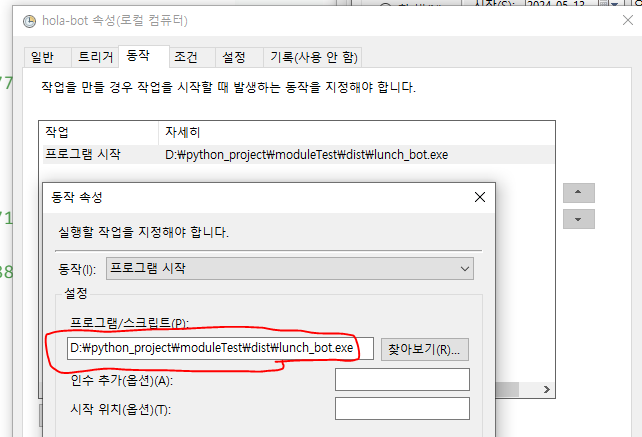
※※ 중요 ※※
테스트할때는 브라우저가 뜨고 실행되었지만 작업 스케줄로 실행할경우 cmd로만 실행되기 때문에 브라우저 창이 뜰 수 없어서 headless 옵션을 추가해주어야한다.
3. chromeOptions "headless" 추가
별도의 창(브라우저) 없이 실행시키겠다는 option 이다.
options = webdriver.ChromeOptions()
options.add_argument('headless')
options.add_argument('window-size=1920x1080')
options.add_argument("disable-gpu")
#01. 웹 열기
dr = webdriver.Chrome(options=options)추가하고 테스트 해보자
cmd에서 작업이 이루어지는것을 확인 할 수 있다.
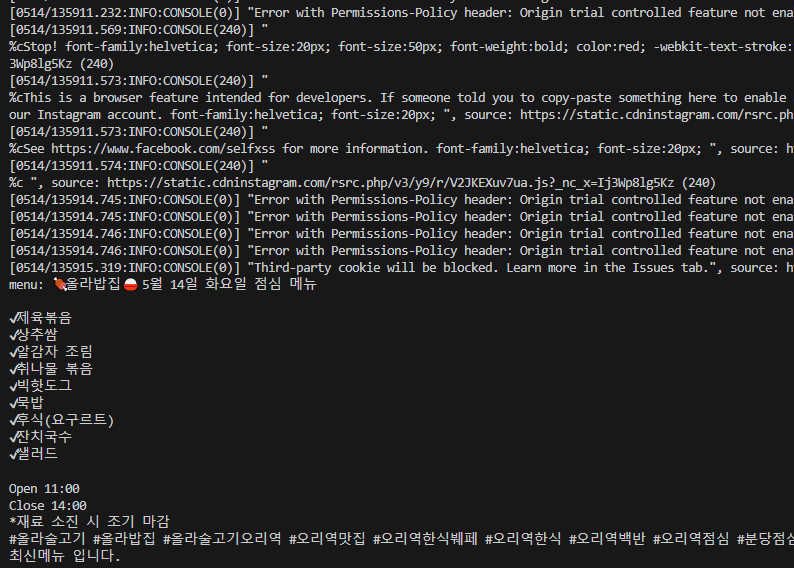
전체 소스코드
#selenium
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.by import By
from datetime import datetime
import time,json, re, requests
_SLACK_URL = 'https://hooks.slack.com/services/{your}/{path}'
_INSTAGRAM_ID = '인스타그램 ID'
_INSTAGRAM_PW = '인스타그램 비번'
#슬랙 메세지 발송 REST 호출
def send_slack(_text):
print(f'slack msg : {_text}')
headers = {'Content-type': 'application/json'}
payload = {'text': _text}
response = requests.post(_SLACK_URL, data=json.dumps(payload), headers=headers)
return response.status_code == 200
#option 설정 : 브라우저 안열고 cmd로만 처리
# 이렇게 해야 스케줄링을 돌릴수있음
options = webdriver.ChromeOptions()
options.add_argument('headless')
options.add_argument('window-size=1920x1080')
options.add_argument("disable-gpu")
#웹 열기
dr = webdriver.Chrome(options=options) # 셀레니움4부터는 chromedriver가 필요없다
dr.set_window_size(820, 1000)#브라우저 크기: 너무 작으면 누르지 못하는경우도있음
dr.get('https://www.instagram.com/hola_pork/') #인스타그램 접속
time.sleep(2) #2초 대기: 대기를 반드시 해주어야한다.
# web의 경우 동적 로딩되는 경우가 있기 때문
#가장 최신 게시글 누르기
_a_tag_before_login = dr.find_element(By.CSS_SELECTOR, "div._ac7v.xzboxd6.x11ulueq.x1f01sob.xwq5r7b.xcghwft > div:nth-child(1) > a")
#동작 제어 : 객체 제어를 위해 추가
act = ActionChains(dr)
act.click(_a_tag_before_login).perform()
time.sleep(5)
#ID 입력, PW 입력 -> 로그인버튼 클릭
input_username = dr.find_element(By.CSS_SELECTOR, 'input[name="username"]')
input_password = dr.find_element(By.CSS_SELECTOR, 'input[name="password"]')
button_login = dr.find_element(By.CSS_SELECTOR, 'button._acan._acap._acas._aj1-._ap30')
act.send_keys_to_element(input_username, _INSTAGRAM_ID).send_keys_to_element(input_password, _INSTAGRAM_PW).perform()
time.sleep(2)
act.click(button_login).perform()
time.sleep(4)
#정보저장 '나중에하기'
link_later_save = dr.find_element(By.CSS_SELECTOR, 'div._ac8f > div')
act.click(link_later_save).perform()
time.sleep(5)
#로그인이 완료된 상태 다시 최신 게시글 클릭
a_tag_after_login = dr.find_element(By.CSS_SELECTOR, 'div._aagu')
act.click(a_tag_after_login).perform()
time.sleep(5)
#게시물 팝업창에서 정보 얻기
target_menu = dr.find_element(By.CSS_SELECTOR, 'h1._ap3a._aaco._aacu._aacx._aad7._aade')
menu_text = target_menu.text
print(f'menu_text: {menu_text}')
#오늘올라온 메뉴인지 체크
#(오늘날짜 == 공지에 올라온 %월 %일 %요일..) 정규식 match()
today = datetime.now().strftime("%m월 %d일")
date_pattern = r'(\d{1,2}월 \d{1,2}일)'
match = re.search(date_pattern, menu_text)
if match:
print('최신메뉴 입니다.')
lines = menu_text.split('\n')
# 태그(#)로 시작하지 않는 줄만 변수에 저장
result_msg = ''
for line in lines:
if not line.startswith('#'):
result_msg += line + '\n'
send_slack(result_msg)
else:
print('아직 업데이트 되지 않았습니다.')
dr.quit()마무리
막상 실제로 개발한 시간은 3시간 정도지만 정리하려니 생각보다 많은 시간이 소요되었다.
짧은시간에 정말 많은 오류를 경험했고 자료를 뒤적거리다 보니 정리해야될 내용이 많았다.
크롤링의 핵심은 원하는 tag를 찾는 것 이라고 생각하는데
"과연 이렇게 selector를 썼을때 유일한 tag에 접근할것인가.." 하는게 가장큰 고민이었다.
그래서 class에 있는걸 몽땅 때려넣고 select하도록 했다.
결과적으로는 동작에는 문제가 없으니 넘어가려고 한다.
과거에는 <tag id="tagId"/> 처럼 id 속성을 넣고 제어했는데 만들다보니 id처럼 고정된 값이 없어서 참~~ 불편했다. SPA의 특징인지 css framework의 특징인지는 공부를 좀더 해야되겠다는 생각이 들었다.
총총

정말 좋은 글이네요!