next-sitemap
sitemap은 검색엔진에게 사이트 구조를 알려주는 지도 파일이다.
보통sitemap.xml형태로, 사이트 내 주요 URL 목록과 각각의 갱신 주기(changefreq), 우선순위(priority), 최근 수정 시각(lastmod) 등을 포함한다.
검색엔진(예: Google, Bing)은 이 파일을 참고해 페이지를 더 빠르고 정확하게 크롤링한다.
즉, 사이트맵은 SEO(검색 노출 최적화) 의 기초 인덱싱 단계에서 매우 중요한 역할을 한다.
robots.txt와 함께 사이트의 접근 정책과 크롤링 우선순위를 제어할 수 있다.
Next.js 프로젝트에서는 이를 직접 손으로 만들 필요가 없다.
next-sitemap라이브러리를 사용하면, Next.js의 모든 라우트 정보를 기반으로 sitemap.xml과 robots.txt를 자동 생성할 수 있다.
Next.js metadata vs next-sitemap — 무엇이 다르고 언제 쓰나
metadata는 페이지의<head>메타 태그를 Next.js 차원에서 타입 안전하게 관리할 수 있게 해주는 기능이다.
title,description,openGraph,alternates.canonical,robots등 SEO 관련 메타 정보 전반을 선언적으로 다룰 수 있다.
App Router에서는 아래처럼 페이지마다 정의한다.export const metadata: Metadata = { title: "홈 | MyPlanMate", description: "나만의 플래너, PlanMate에서 하루를 설계해보세요.", };.
반면,next-sitemap은 검색엔진용 정적 파일(sitemap.xml,robots.txt)을 빌드 시 자동 생성하는 도구다.
즉,<head>태그 내부가 아니라 검색엔진이 읽는 XML/텍스트 파일을 만들어주는 역할을 한다.
📊 핵심 차이 한눈에 보기
구분 Next.js metadatanext-sitemap목적 <head>메타 태그 관리 (SEO, OG, 트위터, canonical 등)sitemap.xml·robots.txt생성 (크롤링용 지도 파일)실행 시점 빌드/런타임 (페이지 렌더 시) 빌드 이후 postbuild명령으로 정적 생성적용 범위 페이지·레이아웃 단위 세밀 제어 사이트 전역 URL 자동 수집 출력 결과 없음 (HTML 내부 삽입) public/sitemap.xml,public/robots.txt대규모 라우트 직접 루프 돌려야 함 sitemapSize로 자동 분할 지원다국어(i18n) alternates.languages로<link hreflang>alternateRefs로 XML 내 다국어 URL 삽입동적 라우트 generateMetadata()로 계산transform()훅으로 경로별 정책 조정사용 목적 메타 정보 중심 크롤링·인덱싱 중심 .
❓“그럼 metadata만 쓰면 사이트맵이 필요 없나?”
그렇지 않다.
두 기능의 목적은 완전히 다르다.
metadata→ 페이지 품질(SEO 메타) 를 담당한다.sitemap.xml·robots.txt→ 검색엔진이 사이트를 어떻게 탐색할지를 담당한다.
결국 이 둘은 상호보완 관계다.
메타가 페이지의 “내용”을 잘 설명해준다면, 사이트맵은 “전체 구조”를 알려준다.
즉, 메타 + 사이트맵 = 완전한 인덱싱 환경이 된다.
🧩 “Next.js에도
app/sitemap.ts,app/robots.ts가 있는데?”App Router에는 자체적으로
app/sitemap.ts,app/robots.ts를 만들어
동적으로 sitemap과 robots.txt를 생성하는 기능이 있다.
작은 규모의 사이트나 페이지 수가 적은 프로젝트라면 이 방식도 충분하다.
하지만 다음과 같은 상황에서는next-sitemap이 훨씬 효율적이다.
URL이 많아 자동 분할(sitemap index) 이 필요할 때
다국어(hreflang), 멀티 도메인 등 복잡한 설정이 있을 때
CI에서 한 번만 생성 후 정적 배포로 끝내고 싶을 때
설정 파일 한 장으로 일관성 있게 관리하고 싶을 때
✅ 결론소규모/동적 생성 중심 →
app/sitemap.ts,app/robots.ts중·대규모/정적·운영 중심 →
next-sitemap
🧱 “그럼 next-seo는 이제 안 써도 되나?”
그렇다.
next-seo는<head>메타 태그를 컴포넌트 형태로 관리하는 서드파티 라이브러리다.
하지만 Next.js 13+의metadataAPI가 동일한 기능을 공식적으로 지원하면서
별도 의존성 없이 타입 안전하게 메타를 관리할 수 있게 되었다.
따라서 이제는 다음처럼 역할을 나누면 된다.
- 메타 데이터 관리 →
metadata/generateMetadata- 사이트맵·로봇 파일 관리 →
next-sitemap
⚙️ 권장 조합 (이 글의 방향)
기능 사용 방법 메타 태그 metadata/generateMetadata사이트맵 next-sitemap(빌드 시 자동 생성)canonical metadata.alternates.canonical설정환경변수 SITE_URL로 로컬/프리뷰/프로덕션 구분.
🧠 요약
metadata는 “페이지 메타 정보”,
next-sitemap은 “사이트 구조 지도”
— 둘은 함께 써야 SEO 인덱싱의 완성도가 높아진다.
패키지 설치 (devDependencies)
pnpm add -D next-sitemap설치가 완료되면
package.json의devDependencies에next-sitemap이 추가된다.
별도의 설정이 없을 경우 루트 디렉터리의next-sitemap.config.js를 읽어 sitemap 생성 규칙을 정의한다.
참고:-D옵션은 개발 의존성(devDependencies)에만 설치하기 위함이다.
sitemap은 런타임 코드가 아니라 빌드 시점 전용 작업이기 때문이다.
환경변수 정리 (SITE_URL: 로컬/프로덕션)
next-sitemap은 사이트의 기준 도메인(Base URL) 을 알아야 한다.
이 값이sitemap.xml에 포함되어 모든 URL의 앞부분으로 붙는다.
예를 들어/about경로는https://myplanmate.vercel.app/about처럼 완전한 URL로 변환된다.
따라서 환경에 맞게SITE_URL변수를 설정해둬야 한다.
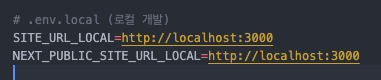
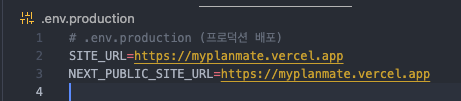
아래처럼.env파일들에 나누어 정의하면 된다.# .env.local (로컬 개발) SITE_URL_LOCAL=http://localhost:3000 NEXT_PUBLIC_SITE_URL_LOCAL=http://localhost:3000 # .env.production (프로덕션 배포) SITE_URL=https://myplanmate.vercel.app NEXT_PUBLIC_SITE_URL=https://myplanmate.vercel.app
.
다음 글에서 설명할건데next-sitemap.config.js에서는 다음처럼 불러온다const siteUrl = process.env.SITE_URL ?? "https://myplanmate.vercel.app"; export default { siteUrl, generateRobotsTxt: true, outDir: "public", };⚠️ 주의
Vercel 배포 환경에서는
SITE_URL이 자동으로 들어가지 않으므로,
프로젝트 Settings → Environment Variables에서 직접 추가해야 한다.
(이 값이 빠지면 sitemap이localhost기준으로 생성되어 검색엔진 등록 시 오류가 발생한다.)
Vercel에서
SITE_URL추가하기1) Production 값 (실 도메인)
- Create new 탭 그대로.
- Environments 드롭다운에서 Production 선택.
- Key:
SITE_URL
Value:https://myplanmate.vercel.app- Sensitive: 끄거나 켜도 됨(비밀 값은 아니지만 켜도 무방).
- Save.
3) Development 값 (로컬 개발)
- 다시 Create new.
- Environments → Development 선택.
- Key:
SITE_URL_LOCAL
Value:http://localhost:3000- Save.
기본 설정 파일 생성 (next-sitemap.config.js)
next-sitemap은 이 설정 파일을 기준으로 작동한다.
즉, “어떤 도메인을 기준으로”, “어떤 페이지를 포함하거나 제외할지”, “어떤 주기로 갱신되는지”를 전부 이 파일에 정의한다.
이 설정이 있어야 빌드 시 자동으로sitemap.xml과robots.txt가 생성된다.
먼저 프로젝트 루트(Next.js의 최상단 폴더)에next-sitemap.config.js파일을 만든다.
여기에 아래 코드를 그대로 넣어두면 된다./** @type {import('next-sitemap').IConfig} */ const siteUrl = process.env.SITE_URL ?? "https://myplanmate.vercel.app"; const config = { siteUrl, // 모든 URL의 기준 도메인 generateRobotsTxt: true, // robots.txt 함께 생성 outDir: "public", // 생성물 출력 경로 (sitemap.xml, robots.txt) sitemapSize: 5000, // URL 많을 때 자동 분할 기준 // 사이트맵에서 제외할 경로 exclude: [ "/api/*", "/admin/*", "/debug", "/lab/*", ], // 경로별 기본 필드 커스터마이즈 transform: async (config, path) => { // 홈은 우선순위를 높게 const priority = path === "/" ? 1.0 : path.startsWith("/blog") ? 0.8 : config.priority ?? 0.7; return { loc: path, // 최종 URL (siteUrl이 자동으로 앞에 붙음) changefreq: "daily", // 기본 갱신 주기 priority, // 우선순위 lastmod: new Date().toISOString(), // alternateRefs: [], // i18n 사용 시 채운다(아래 참고) }; }, // robots.txt 커스텀 robotsTxtOptions: { policies: [ { userAgent: "*", allow: "/" }, { userAgent: "*", disallow: ["/api/", "/admin/", "/debug", "/lab/"] }, ], additionalSitemaps: [ // 필요 시 커스텀/서버 생성 사이트맵을 병합 // `${siteUrl}/server-sitemap.xml`, ], }, }; export default config;이 설정은 간단히 말하면 사이트의 크롤링 규칙서다.
검색엔진은 여기서 지정한 규칙을 읽고 “이 페이지는 중요하구나”, “이 폴더는 건너뛰어야겠네” 같은 판단을 한다.
즉, 이 파일 하나로 크롤링 범위와 우선순위를 통제할 수 있는 셈이다.
필수 옵션만 요약
siteUrl: 사이트의 기준 도메인이다.
.env에 넣어둔SITE_URL환경변수를 읽어온다.
(예: 로컬 →http://localhost:3000, 프로덕션 →https://myplanmate.vercel.app)
generateRobotsTxt:robots.txt파일을 자동으로 만들어준다.
이 파일은 “크롤러야, 어떤 폴더는 접근하지 마” 같은 명령을 담는 문서다.
exclude: 검색 노출이 불필요한 내부 경로를 제외한다.
보통 API 라우트나 관리자 페이지(/api/*,/admin/*)를 적는다.
transform: 각 페이지의 세부 설정을 조정할 수 있다.
예를 들어 홈(/)은priority: 1.0으로 가장 중요하게 두고,
블로그(/blog/...)는 0.8로 두는 식이다.
또한lastmod를 자동으로 “지금 시각”으로 기록해 최신 업데이트로 표시할 수 있다.
빌드 연동 (package.json postbuild / 수동 생성)
Next.js 프로젝트에서
next-sitemap은 빌드 결과물(라우트 정보) 을 이용해
/sitemap.xml과/robots.txt를 생성한다.
즉, 실제로 페이지가 어떻게 배포될지 알아야 정확한 사이트맵을 만들 수 있기 때문에
Next.js의 빌드가 끝난 뒤(postbuild 단계) 실행해야 한다.
이 과정을 자동화하면, 배포할 때마다 sitemap이 최신 상태로 갱신된다.
새 페이지를 추가하거나 URL 구조를 바꿔도 별도로 명령을 실행할 필요 없이
한 번의 빌드로 완전한 사이트맵과 로봇 파일이 자동 생성된다.
이렇게 해두면 SEO 관리가 훨씬 단순해지고, 실수로 오래된 sitemap을 배포하는 일도 없다.
스크립트 추가
package.json에 아래를 추가한다.{ "scripts": { "build": "next build", "postbuild": "next-sitemap", // 빌드 후 자동 생성 "sitemap": "next-sitemap" // 필요 시 수동 실행 } }빌드 이후(postbuild) 실행으로
public/sitemap*.xml과robots.txt가 생성된다.
실행 순서
pnpm build # 1) Next.js 빌드 # ↳ 자동으로 next-sitemap 실행 # ↳ public/sitemap.xml, public/robots.txt 생성생성물 위치
빌드 후
next-sitemap이 아래 파일들을 만든다. 기본 출력 경로는public/이다.1)
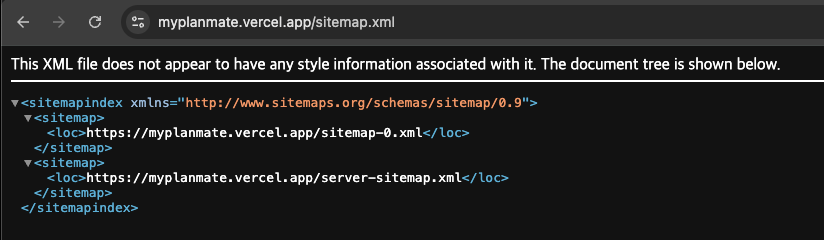
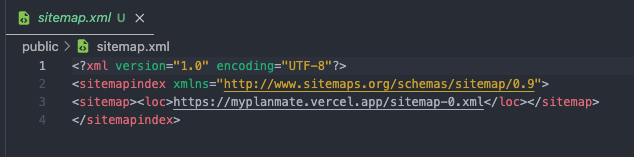
public/sitemap.xml— 인덱스 파일여러 개의 사이트맵으로 분할될 때 “목차” 역할을 하는 인덱스다.
브라우저에서https://myplanmate.vercel.app/sitemap.xml로 확인한다.
메모: URL 수가 늘면
sitemap-1.xml,sitemap-2.xml… 로 자동 분할된다.
인덱스(sitemap.xml)는 항상 최신 파편 목록을 가리킨다.
2)
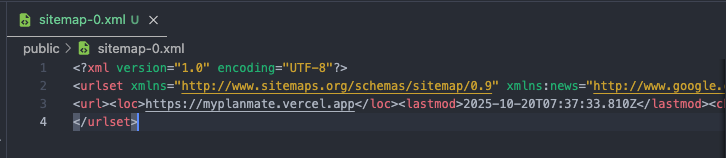
public/sitemap-0.xml— 실제 URL 목록각 페이지의 절대 URL(도메인 포함)과
lastmod가 담긴다.
브라우저에서https://myplanmate.vercel.app/sitemap-0.xml로 확인한다.
3)
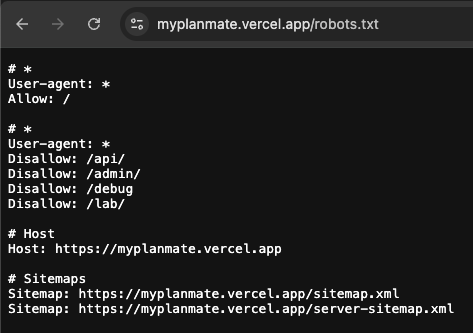
public/robots.txt— 크롤링 정책모든 크롤러 허용 + 내부 경로 차단 + Host/Sitemap 라인을 포함한다.
브라우저에서https://myplanmate.vercel.app/robots.txt로 확인한다.
빠른 점검 체크리스트
- 환경변수: Vercel Settings에
- Development →
SITE_URL=http://localhost:3000- Production →
SITE_URL=https://<프로덕션-도메인>
- config 파일: 프로젝트 루트에
next-sitemap.config.js존재- 빌드 스크립트:
postbuild에next-sitemap연결- 생성물 확인: 배포 후
https://<도메인>/sitemap.xmlhttps://<도메인>/robots.txt
- exclude 적용:
/api/*,/admin/*,/debug,/lab/*가 사이트맵에 포함되지 않음- 우선순위 확인:
/는priority: 1.0, 블로그는 0.8 등 의도대로 반영
자주 나는 이슈 & 해결
- 도메인이
localhost로 찍힘
→ Production 환경의SITE_URL누락. Vercel에 추가 후 재배포한다.
- 파일이 생성되지 않음
→postbuild가 실행되지 않았거나,next-sitemap.config.js위치가 루트가 아님. 위치/스크립트 확인.
- 여러 개의
sitemap-*.xml이 생김
→ 정상 동작이다(대규모 URL 분할).sitemap.xml은 인덱스 파일이다.
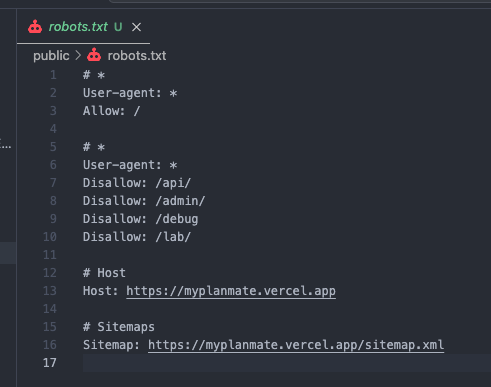
⚠️ 트러블슈팅 — next-sitemap 설정 파일을 못 찾는 에러
증상
원인
next-sitemap4.x부터 기본 설정 파일명 탐색 규칙이 변경됐다.
이제 기본값은next-sitemap.config.js만 자동으로 탐색한다.
즉,next-sitemap.config.js(ESM)로 만들어두면 CLI가 못 찾는다.
해결 방법 (택 1)
방법 A — 파일명을
.js로 변경(추천)
- 설정 파일 이름 변경
next-sitemap.config.mjs→next-sitemap.config.js
방법 B —
.mjs유지 + CLI에 경로 지정
package.json스크립트에서--config옵션으로 파일 경로를 명시한다.{ "scripts": { "postbuild": "next-sitemap --config next-sitemap.config.js" } }장점: ESM 문법 유지 가능.
단점: 매번 경로를 명시해야 해 관리가 다소 번거롭다.
robots.txt 정책 설계 (크롤러 접근 가이드)
robots.txt는 검색엔진 크롤러에게 “이 사이트를 어디까지 읽어도 되는지” 알려주는 안내문이다.
쉽게 말하면, “이 폴더는 봐도 돼요 / 여긴 내부용이니 들어오지 마세요”를 정리한 규칙표다.
사이트의 루트(/public/robots.txt)에 두면, Google·Bing·Naver 같은 검색엔진이
페이지를 방문하기 전에 가장 먼저 이 파일을 읽고 크롤링 범위를 판단한다.
예를 들어/api나/admin같은 내부 전용 페이지는
검색결과에 뜰 필요가 없고, 오히려 노출되면 보안상 불필요한 정보가 드러날 수도 있다.
이럴 때robots.txt에서 해당 경로를Disallow로 지정하면
검색엔진이 그 페이지를 크롤링하지 않는다.
반대로, 메인 페이지나 블로그 글처럼
검색 노출이 필요한 영역은 반드시 Allow 상태로 두어야 한다.
robots.txt에서 차단해버리면, 검색엔진이 그 페이지를 아예 방문하지 못하므로
metadata로 아무리 SEO 메타를 잘 써도 색인(indexing)이 불가능하다.
즉,robots.txt는 SEO의 첫 관문이다.
검색엔진이 “어디까지 들어올 수 있는가”를 결정하고,
그 다음 단계에서metadata나sitemap.xml을 참고해 실제 콘텐츠를 색인한다.
💡 요약
robots.txt는 “검색 로봇의 출입 통제문”이다.- “검색에 나오게 하고 싶은 페이지”는
Allow,
“내부 관리용/비공개 영역”은Disallow.- SEO와 보안을 동시에 고려하는 핵심 설정이다.
⚠️ 중요: robots.txt는 “색인 금지(noindex)” 명령이 아니다.
robots.txt는 “들어오지 마” 신호일 뿐, “검색결과에서 제외해라”라는 명령은 아니다.
즉, 이미 색인된 페이지를 검색결과에서 내리고 싶다면
페이지 자체에 noindex 메타 태그를 추가해야 한다.
Next.js에서는metadata.robots옵션으로 손쉽게 처리할 수 있다.// app/secret/page.tsx export const metadata = { robots: { index: false, // 색인 금지 follow: false, // 링크 따라가지 않음 }, };📍 이런 방식은 민감하거나 내부 전용이지만 접근은 필요한 페이지에 적합하다.
예: 로그인 페이지(/login), 테스트 페이지(/debug), 팀 내부 문서 페이지(/internal) 등
→ 검색엔진은 읽지만 색인하지 않는다.
기본 원칙
- 허용이 기본, 차단은 최소화한다. 크롤링을 막으면 인덱싱도 지연/불가해질 수 있다.
- API·관리 화면·내부 툴처럼 검색 노출이 무의미한 경로만 차단한다.
- 배포 환경이 하나(프로덕션)라면, 프리뷰/스테이징 차단 규칙은 불필요하다.
- 차단 후 이미 색인된 문서는
robots.txt만으로 제거되지 않는다 → Search Console에서 제거 요청 ornoindex.
next-sitemap에서 robots 설정하기
next-sitemap.config.js의robotsTxtOptions.policies에서 크롤러별 허용/차단을 정의한다.
이전에 미리 작성해서 지금은 살펴보기만 한다!const config = { // ... generateRobotsTxt: true, robotsTxtOptions: { policies: [ { userAgent: "*", allow: "/" }, { userAgent: "*", disallow: ["/api/", "/admin/", "/debug", "/lab/"] }, ], }, }; export default config;빌드 후 생성물(
public/robots.txt) 예시는 다음과 같은 구조가 된다.
Sitemap:라인은 사이트맵 위치를 명시해 크롤러가 더 빨리 URL을 수집하도록 돕는다.
i18n & 멀티 도메인 (hreflang, alternateRefs)
다국어/지역 버전이 있으면, HTML(head)과 사이트맵(XML) 모두에 언어 정보를 일치시켜야 한다.
핵심은hreflang이다: “같은 콘텐츠의 언어/지역별 버전”을 서로 연결해 준다.
1) 사이트맵에 언어 버전 넣기 (
alternateRefs)
next-sitemap.config.js의transform반환값에alternateRefs를 채운다.// 예: ko / en 두 언어 운영 return { loc: path, changefreq: "daily", priority, lastmod: new Date().toISOString(), alternateRefs: [ { href: `${siteUrl}/ko`, hreflang: "ko" }, { href: `${siteUrl}/en`, hreflang: "en" }, ], };언어-지역이 필요하면
hreflang: "en-US"처럼 지역 코드를 붙인다.
2) HTML(head)에도 동일하게 (
metadata.alternates.languages)Next.js에서
<head>도 동일한 매핑을 갖도록 하고, 환경변수(SITE_URL)로 기준 도메인을 주입한다.
metadataBase에 기준 도메인을 넣으면,languages에 상대 경로만 적어도 자동으로 절대 URL로 변환된다.// app/layout.tsx import type { Metadata } from "next"; export const metadata: Metadata = { // 기준 도메인(절대 URL 계산용). env로 주입 metadataBase: new URL(SITE_URL), // canonical 및 언어별 hreflang alternates: { canonical: "/", // => https://myplanmate.vercel.app/ languages: { ko: "/ko", // => https://myplanmate.vercel.app/ko en: "/en", // => https://myplanmate.vercel.app/en }, }, };원칙: HTML과 XML의 언어 매핑을 동일하게 유지.
검색엔진이 “이 페이지들의 관계”를 안정적으로 이해한다.
3) 멀티 도메인 운영 시
언어별로 도메인을 나눴다면
href에 해당 도메인을 넣는다.alternateRefs: [ { href: "https://planmate.kr/ko", hreflang: "ko" }, { href: "https://planmate.app/en", hreflang: "en" }, ];
대규모 라우트 대비 & 동적 라우트 정책
웹사이트가 커지면 페이지 수도 함께 늘어난다.
처음엔/,/about,/contact정도로 단순하지만,
블로그나 커뮤니티, 쇼핑몰처럼 게시글·상품이 수천~수만 개가 되면 크롤링 효율이 급격히 떨어진다.
검색엔진 입장에서는
“어떤 페이지가 더 중요한가?”,
“얼마나 자주 업데이트되는가?”,
“이걸 한 파일로 다 읽어야 하나?”
이런 정보를 알 수 없으면 색인 순서와 빈도가 비효율적이 된다.
예를 들어,
- 매일 바뀌는 홈이나 블로그 목록은 빠르게 크롤링돼야 하고,
- 거의 변하지 않는 약관·소개 페이지는 느긋하게 방문해도 된다.
이런 페이지 중요도(priority) 와 변경 주기(changefreq) 를
검색엔진에게 직접 알려주는 기능이 바로next-sitemap의 동적 라우트 정책(transform 설정) 이다.
또한,
페이지 수가 일정 기준(약 5,000~10,000 URL)을 넘으면
하나의sitemap.xml이 너무 커져 로딩이 느려지거나 일부 엔진에서 잘리지 않는다.
이때 자동 분할 기능(sitemapSize) 을 써서 여러 파일로 나누면
검색엔진이 사이트 전체를 더 빠르게 읽을 수 있다.
즉,
이 섹션은 “사이트가 커졌을 때도 크롤링 품질을 유지하는 법”을 다루는 것이다.- URL이 많을 때:
sitemapSize로 분할 인덱스- 경로마다 다를 때:
transform으로 우선순위/갱신주기 조정
이 두 가지가 함께 있어야,
검색엔진이 “이 사이트는 잘 구조화돼 있고 변화가 많은 부분은 자주 크롤링해야겠다”라고 인식하게 된다.
대규모 라우트 대비 — 분할 인덱스 이해(성능/안정성)
URL이 많아지면 하나의
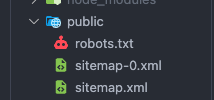
sitemap.xml로는 비효율적이다.next-sitemap은sitemapSize기준으로 자동 분할한다.
sitemap.xml→ 인덱스 파일(목차)sitemap-0.xml,sitemap-1.xml… → 실제 URL 리스트
현재로서는sitemap.xml과sitemap-0.xml만 생긴 상태이다!
권장// next-sitemap.config.js const config = { // ... sitemapSize: 5000, // 5천~1만 선이 현실적. 트래픽/캐시 상황 따라 조절 }; export default config;분할은 정상 동작이다. Search Console에
sitemap.xml인덱스만 제출하면 나머지는 자동 인식한다.
동적 라우트 정책 — 경로 패턴별 priority/lastmod 전략
페이지 성격에 따라 우선순위(
priority)와 변경주기(changefreq)를 다르게 주면 크롤링 힌트를 잘 전달할 수 있다.// next-sitemap.config.js const config = { // ... transform: async (cfg, path) => { // 1) 우선순위 전략 const priority = path === "/" ? 1.0 : path.startsWith("/blog/") ? 0.8 : path.startsWith("/notes/") ? 0.7 : 0.6; // 나머지 기본 return { loc: path, // 최종 URL (siteUrl이 자동으로 앞에 붙음) changefreq: "daily", // 기본 갱신 주기 priority, // 우선순위 lastmod: new Date().toISOString(), alternateRefs: [ { href: `${siteUrl}/ko${loc === "/" ? "" : loc}`, hreflang: "ko" }, { href: `${siteUrl}/en${loc === "/" ? "" : loc}`, hreflang: "en" }, ], }; }, }; export default config;패턴 설계 팁
- 홈:
priority: 1.0,changefreq: daily- 콘텐츠 허브(블로그 목록, 제품 목록): 0.8 / weekly
- 상대적으로 덜 바뀌는 정보 페이지(About/Terms): 0.6 / monthly
- API/관리/디버그:
exclude로 제외
priority는 절대 명령이 아니라 힌트다. 그래도 일관성 있게 주면 수집 품질이 좋아진다.
URL 수가 폭발하는 경우(수만~수십만)
- 프리렌더 가능한 정적 URL만 사이트맵에 포함한다.
- 초대형 컬렉션은 서버 생성 사이트맵(예:
/server-sitemap.xml)을 카테고리/기간 단위로 나눠additionalSitemaps에 병합한다.- Search Console 제출은 인덱스 1개만. (나머지는 자동 추적)
서버 생성 사이트맵 병합 (additionalSitemaps)
웹사이트가 커지면 “정적 페이지”와 “사용자나 데이터로부터 동적으로 만들어지는 페이지”가 함께 존재하게 된다.
예를 들어, 랜딩·소개·약관 페이지처럼 변하지 않는 페이지는 빌드 시점에 한 번만 만들면 되지만,
사용자가 만든 콘텐츠나 블로그 글처럼 자주 바뀌는 영역은
매번 빌드를 다시 하기보다 서버에서 자동으로 최신 sitemap을 만들어 제공하는 게 효율적이다.
이때next-sitemap은 이런 구조를 쉽게 지원한다.
정적 페이지용 sitemap(빌드 자동 생성)에,
서버에서 만든 동적 sitemap을 추가로 연결해 검색엔진이 함께 읽을 수 있도록 하는 기능이다.
즉, “한 지도에 다 담기지 않는 방들을 별도 지도에 그리고, 그 지도 링크를 목차에 추가하는 방식”이라고 이해하면 된다.
📌 참고
이 아래의 ① 단계는 세팅 단계에서 진행해도 되는 작업이다.
② ~ ③ 단계같은 경우에는 Next.js에서 실제 페이지(Route) 파일을 만들 때 수행하는 작업이다.TIP: 로그인·회원가입·비밀번호 관련 페이지는 noindex 또는 sitemap 제외
1) 기본 인덱스에 “동적 사이트맵 연결하기”
이제
next-sitemap.config.js에서 방금 만든 동적 사이트맵을
기본 인덱스(sitemap.xml) 에 연결하면 된다.
이렇게 하면 “정적 sitemap + 실시간 sitemap”이 하나의 인덱스에 함께 관리된다.// next-sitemap.config.js /** @type {import('next-sitemap').IConfig} */ const siteUrl = process.env.SITE_URL || "https://myplanmate.vercel.app"; const config = { // ... robotsTxtOptions: { policies: [ { userAgent: "*", allow: "/" }, { userAgent: "*", disallow: ["/api/", "/admin/", "/debug", "/lab/"] }, ], // ✅ 추가 사이트맵을 연결하는 부분 additionalSitemaps: [ `${siteUrl}/server-sitemap.xml`, // ← 방금 만든 동적 sitemap ], }, }; export default config;🧩 결과
public/sitemap.xml(인덱스)에 추가 사이트맵 경로가 자동으로 포함된다.robots.txt에도Sitemap:라인이 여러 개 생겨서
검색엔진이 모든 영역을 한 번에 탐색할 수 있다.
2) 영역별 동적 사이트맵 “페이지” 만들기
권장 타이밍: 해당 영역(화면/URL)이 실제로 생길 때 생성.
어떤 페이지별로 쪼개는지는 3번에서 설명하고 있다.
정확한 경로(Next.js App Router):
src/app/sitemaps/marketing.xml/route.ts→/sitemaps/marketing.xmlsrc/app/sitemaps/builder.xml/route.ts→/sitemaps/builder.xml
예시: 마케팅/랜딩 묶음
// src/app/sitemaps/marketing.xml/route.ts import { NextResponse } from "next/server"; export async function GET() { const siteUrl = process.env.SITE_URL ?? "https://myplanmate.vercel.app"; // 공개 페이지들만 수집 (예: 랜딩, 소개, 완성(공개용)) const urls: string[] = ["/", "/about"]; // 실제로는 DB/목록에서 채우기 const xml = `<?xml version="1.0" encoding="UTF-8"?> <urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"> ${urls.map(u => ` <url> <loc>${siteUrl}${u}</loc> <lastmod>${new Date().toISOString()}</lastmod> </url>`).join("")} </urlset>`; return new NextResponse(xml, { headers: { "Content-Type": "application/xml" } }); }예시: 빌더/결과물 묶음
// src/app/sitemaps/builder.xml/route.ts import { NextResponse } from "next/server"; export async function GET() { const siteUrl = process.env.SITE_URL ?? "https://myplanmate.vercel.app"; // 퍼블릭 공유 가능한 결과 URL만 포함 const urls: string[] = []; // 나중에 공개 결과물 생기면 채우기 const xml = `<?xml version="1.0" encoding="UTF-8"?> <urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"> ${urls.map(u => ` <url> <loc>${siteUrl}${u}</loc> <lastmod>${new Date().toISOString()}</lastmod> </url>`).join("")} </urlset>`; return new NextResponse(xml, { headers: { "Content-Type": "application/xml" } }); }TIP
- 로그인·인증·비번 찾기·가입 단계 등은 보통 sitemap 제외(+ 필요 시
noindex).- 실제 URL이 없으면 처음엔
urls: []로 빈<urlset>을 반환해도 무방.- 영역이 늘어나면
sitemaps/<영역>.xml파일만 추가하고 1번의additionalSitemaps에 경로를 더하면 끝.
3) 나중에 이렇게 쪼개서 병합하면 좋아요 (MyPlanMate 구조 기준 예시)
데일리 커스텀 플래너는 구조적으로 페이지 구성이 명확하니까,
나중에 규모가 커지면 sitemap을 기능별로 나눠서 병합하는 게 좋다.
예를 들어 이렇게 쪼개면 깔끔할 것 같다 👇
구분 포함 대상 sitemap 경로 🏠 마케팅/랜딩 영역 랜딩 페이지, 기능 소개, 완성 페이지(공유 가능 버전) /sitemaps/marketing.xml🔑 계정/인증 영역 로그인, 비밀번호 찾기, 회원가입 단계(이메일·이름·비번·약관 등) 보통 sitemap 제외 ( noindex권장)🧩 빌더/기능 설정 영역 기능 선택, 디자인 선택, 기능 배치, 완성 페이지(퍼블릭 결과물) /sitemaps/builder.xml🙋♂️ 프로필 영역 내 프로필(로그인 필요) 비공개면 제외 / 퍼블릭이면 별도 sitemap
next-sitemap.config.js에서는 이렇게 연결해둘 수 있다.robotsTxtOptions: { // ... additionalSitemaps: [ `${siteUrl}/sitemaps/marketing.xml`, // `${siteUrl}/sitemaps/builder.xml`, // 퍼블릭 결과물 생기면 추가 ], },각
route.ts파일은 위 1) 예시처럼
해당 영역의 공개 URL 목록만 모아서 XML로 반환하면 된다.
💡 정리 가이드
- 검색 노출이 필요한 공개 페이지만 포함 (랜딩, 완성, 공유 링크 등)
- 로그인 필수 페이지나 중간 설정 단계는 제외 (
noindex또는exclude)- 영역별로 sitemap을 나누면 검색엔진이 병렬로 빠르게 크롤링할 수 있고,
나중에 특정 기능만 인덱싱 문제를 추적하기도 쉽다.
캐노니컬 & 중복 방지 (metadata.alternates.canonical)
검색엔진은 같은 화면이라도 주소가 조금만 다르면 서로 다른 페이지로 인식한다.
/todos,/todos/,/todos?filter=done,https://www.myplanmate.com/todos
모두 같은 내용을 보여줘도, Google은 “이게 네 개의 페이지인가?” 하고 헷갈릴 수 있다.
이런 중복 신호를 합치고 “대표 주소는 이것”이라고 알려주는 방법이 캐노니컬(canonical) 이다.1️⃣ canonical이란 무엇인가
개념 설명 canonical 페이지의 대표 URL 목적 비슷한 URL이 많을 때, 어떤 걸 색인해야 하는지 검색엔진에 명시 효과 중복 콘텐츠를 하나로 합쳐 검색 순위 분산 방지 주의 sitemap.xml의<loc>주소와 canonical이 완전히 동일해야 한다즉, canonical은 “이 콘텐츠의 진짜 주소는 이거야”라는 선언이다.
검색엔진은 이 신호를 기반으로 중복 URL을 병합한다.
2️⃣ Next.js에서 canonical 선언 (환경변수 연동)
Next.js에서는
metadataBase와alternates.canonical로 canonical을 지정할 수 있다.
metadataBase에 기준 도메인을 넣고, canonical에는 상대 경로만 쓰면 자동으로 절대 URL로 변환된다.// app/layout.tsx import type { Metadata } from "next"; import { SITE_URL } from "@/seo/constants" // process.env.NEXT_PUBLIC_SITE_URL ?? process.env.SITE_URL ?? "https://myplanmate.vercel.app"; export const metadata: Metadata = { metadataBase: new URL(SITE_URL), alternates: { canonical: "/", // => https://도메인/ }, };예시 —
/todos페이지// app/todos/page.tsx import type { Metadata } from "next"; export const metadata: Metadata = { alternates: { canonical: "/todos", // => https://도메인/todos }, };✅ 원칙
- canonical과 sitemap의
<loc>는 문자 그대로 동일해야 한다.metadataBase를 한 번만 지정하면, 모든 canonical이 절대경로로 자동 변환된다.
3️⃣ 중복 주소 처리 — URL 정규화
검색엔진이 하나의 주소로 인식하도록,
리다이렉트 / canonical / sitemap을 같은 규칙으로 통일한다.
이 프로젝트는 무슬래시(/path) + non-www(https://myplanmate.com) 형태를 표준으로 쓴다.
A) 트레일링 슬래시(
/vs 없음) — 무슬래시 통일
/todos와/todos/는 검색엔진이 서로 다른 페이지로 본다.
이때/todos/를/todos로 정규화하려면, 리다이렉트 규칙이 아니라 Next.js 설정으로 처리한다.// next.config.ts const config = { // ✅ 슬래시 정책: 무슬래시 trailingSlash: false, }; export default config;⚠️ 예전 방식인
{ source: "/:path*/", destination: "/:path*" }리다이렉트는
개발 서버(HMR)와 충돌해 새로고침 루프가 발생할 수 있으므로 쓰지 않는다.
B) www → non-www 통일
www.myplanmate.com과myplanmate.com을 혼용하면 신호가 분산된다.
대표 도메인을.env의SITE_URL로 정하고, www 요청은 대표 도메인으로 리다이렉트한다.// next.config.ts import type { NextConfig } from "next"; const isProd = process.env.NODE_ENV === "production"; const RAW = process.env.SITE_URL ?? "https://myplanmate.vercel.app"; const ORIGIN = new URL(RAW); const NON_WWW_HOST = ORIGIN.hostname.replace(/^www\./, ""); const WWW_HOST = ORIGIN.hostname.startsWith("www.") ? ORIGIN.hostname : `www.${NON_WWW_HOST}`; const DEST_ORIGIN = `${ORIGIN.protocol}//${NON_WWW_HOST}`; const config: NextConfig = { trailingSlash: false, async redirects() { // ⚠️ dev 모드(HMR)에서는 비활성화 (루프 방지) if (!isProd) return []; return [ { source: "/:path*", has: [{ type: "host", value: WWW_HOST }], destination: `${DEST_ORIGIN}/:path*`, permanent: false, // 검증 후 true로 승격 }, ]; }, }; export default config;💡 dev에서는 redirect를 비활성화해야 HMR이 무한 리로드되지 않는다.
운영 배포에서 정상 동작을 확인한 뒤 permanent를true로 바꾼다.
C) 쿼리스트링 정리 — 깨끗한 canonical 유지
utm,ref,fbclid등 트래킹 파라미터는 canonical에 포함시키지 않는다.// app/todos/page.tsx import type { Metadata } from "next"; export async function generateMetadata(): Promise<Metadata> { return { alternates: { canonical: "/todos" } }; }→
/todos?utm=google과/todos모두/todos를 대표 주소로 인식한다.
D) 페이지네이션만 canonical에 반영
실제 콘텐츠가 달라지는
page파라미터만 canonical에 포함한다.// app/todos/page.tsx import type { Metadata } from "next"; export async function generateMetadata({ searchParams, }: { searchParams?: Record<string, string | string[] | undefined>; }): Promise<Metadata> { const sp = new URLSearchParams(); const page = Array.isArray(searchParams?.page) ? searchParams.page[0] : searchParams?.page; if (page && /^\d+$/.test(page)) sp.set("page", page); const canonical = sp.toString() ? `/todos?${sp.toString()}` : "/todos"; return { alternates: { canonical } }; }.
4️⃣ sitemap.xml과 canonical 일치 유지
sitemap.xml의<loc>값은 각 페이지의 canonical과 한 글자도 다르면 안 된다.// next-sitemap.config.js const RAW = process.env.SITE_URL ?? "https://myplanmate.vercel.app"; const siteUrl = RAW.replace(/\/+$/, ""); // 끝 슬래시 제거 const strip = (p) => (p !== "/" && p.endsWith("/") ? p.slice(0, -1) : p); export default { siteUrl, generateRobotsTxt: true, outDir: "public", sitemapSize: 5000, exclude: ["/api/*", "/admin/*", "/debug", "/lab/*"], transform: async (cfg, path) => { const loc = strip(path); const priority = loc === "/" ? 1.0 : loc.startsWith("/blog") ? 0.8 : (cfg.priority ?? 0.7); return { loc, // canonical과 완전히 동일 changefreq: "daily", priority, lastmod: new Date().toISOString(), alternateRefs: [ { href: `${siteUrl}/ko${loc === "/" ? "" : loc}`, hreflang: "ko" }, { href: `${siteUrl}/en${loc === "/" ? "" : loc}`, hreflang: "en" }, ], }; }, robotsTxtOptions: { policies: [ { userAgent: "*", allow: "/" }, { userAgent: "*", disallow: ["/api/", "/admin/", "/debug", "/lab/"] }, ], additionalSitemaps: [`${siteUrl}/server-sitemap.xml`], }, };.
5️⃣ 점검 체크리스트
항목 확인 방법 슬래시 정책 /todos/→/todos로 301 리다이렉트되는지도메인 정책 www → non-www리다이렉트 정상 동작 여부canonical <head>에 무슬래시 형태의 canonical 출력 여부sitemap <loc>이 canonical과 완전히 동일한지i18n alternateRefs와 canonical이 동일한 경로로 출력되는지.
✅ 요약
이 구성을 적용하면
/todos와/todos/가 하나로 병합되고,www와non-www신호가 대표 도메인으로 집중되며,- sitemap과 canonical이 완전히 일치하여 검색엔진이 혼동하지 않는다.
결과적으로 중복 URL이 모두 하나의 canonical 주소로 정규화되어,
색인 신호와 랭킹이 대표 페이지에 집중된다.
검색엔진 제출 & 모니터링 (Search Console / Bing)
웹사이트를 만들었다고 해서 검색엔진이 바로 다 알아서 찾아주는 건 아니다.
새 페이지를 언제 발견할지, 어떤 주소를 대표로 삼을지, 비공개 영역은 건드리지 말아야 하는지 검색엔진은 모른다.
그래서 사이트맵 제출과 모니터링이 필요하다.
한마디로 “우리 사이트의 지도와 이용 안내문을
이렇게 해두면 새로 만든 페이지를 더 빨리 찾게 하고(크롤링 가속), 같은 내용의 여러 주소가 있을 때 대표 주소 하나로 인식하게 만들며(중복/점수 분산 방지), 실수로 막아둔 페이지나 오류(404, 서버 에러, robots 차단)를 리포트로 바로 발견할 수 있다.
즉, 검색엔진에게 길을 안내하고, 안내가 제대로 먹히는지 매일 체온을 재듯 확인하는 단계다.
1️⃣ 지금 세팅 단계에서 할 수 있는 것
아직 페이지가 많지 않기 때문에,
“검색 노출”보다 기본 세팅이 올바르게 작동하는지 확인하는 게 목적이다.(1) 환경변수 적용 확인
이전 단계에서 등록한
SITE_URL이
빌드와 sitemap 생성 과정에 제대로 반영되는지 확인한다.
- 로컬이나 프로덕션에서 빌드 후
sitemap.xml을 열어본다.
각 URL이https://myplanmate.vercel.app처럼 절대 경로로 찍혀 있으면 정상이다.- 만약
http://localhost:3000으로 표시된다면
환경변수가 빌드 시점에 전달되지 않은 것이므로
Vercel이나 GitHub Actions의 환경설정에서 값을 다시 확인해야 한다.
(2) sitemap과 robots.txt 점검
- 브라우저로 아래 두 파일을 열어본다.
https://도메인/sitemap.xmlhttps://도메인/robots.txt
- 둘 다 200 OK로 응답되고, sitemap에
loc태그에sitemap.xml 주소가 보이면 정상이다.- robots.txt의 마지막 줄에
Sitemap:주소가 자동으로 붙어 있으면 제대로 연결된 상태다.
(3) postbuild 자동 실행 확인
package.json에 다음 코드가 포함돼 있는지 확인한다."scripts": { "build": "next build", "postbuild": "next-sitemap" }- 이렇게 설정되어 있으면 배포 시마다 sitemap과 robots.txt가 자동 생성된다.
(4) Search Console 사전 등록
지금은 콘텐츠가 없더라도
Google Search Console에 사이트 등록까지만 미리 해두면 좋다.
이 과정을 해두면, 나중에 페이지를 만들었을 때 바로 사이트맵을 제출할 수 있다.1.
2.
“속성 추가” 화면이 뜨면
왼쪽(도메인) ❌ → DNS 인증이 필요하므로 사용하지 않는다.
오른쪽(✅ URL 접두어, URL Prefix) 방식을 선택한다.3.
입력란에
https://myplanmate.vercel.app를 입력하고 계속(Continue) 클릭한다.
4.
인증 방법 선택 화면에서 “HTML 태그” 방식을 고른다.
5.
아래 회색 박스에 표시된 코드를 복사한다.
예시<meta name="google-site-verification" content="HwFH-3lcPM6" />이때
content="HwFH-3lcPM6"부분이 고유 인증값이므로,
전체 태그를 붙이지 말고 값만 복사해 사용한다.
6. Next.js 전역 레이아웃(
app/layout.tsx)의 메타데이터에 다음처럼 추가한다.// app/layout.tsx export const metadata = { // ... verification: { google: "HwFH-3lcPM6", // 복사한 content 값만 넣기 }, };또는
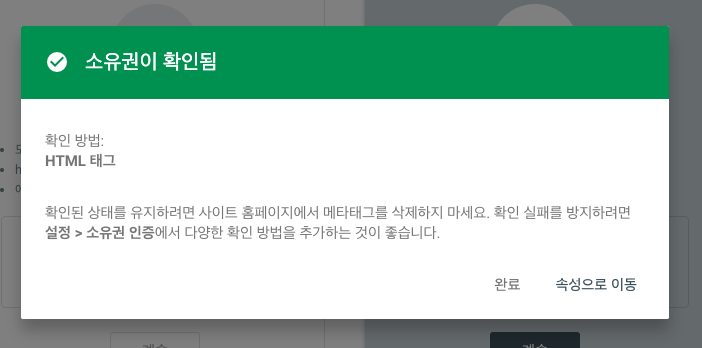
<head>태그에 직접 넣어도 된다.<head> <meta name="google-site-verification" content="HwFH-3lcPM6" /> </head>7. Vercel에 재배포 후, Search Console로 돌아가 “확인(Verify)” 버튼을 클릭한다.
8. “소유권 확인 완료” 메시지가 뜨면 등록 성공이다.
💡 참고
“도메인” 방식은 DNS 접근 권한이 필요하므로
vercel.app주소에서는 사용할 수 없다.
항상 “URL 접두어” 방식을 선택해야 한다.
2️⃣ 나중에 페이지가 만들어졌을 때 해야 하는 것
페이지가 일정 수준 완성되고 배포된 이후엔,
Search Console에서 사이트맵 제출 → 색인 상태 점검 → 노출 모니터링을 한다.
(1) sitemap.xml 제출
- Search Console → 좌측 메뉴 Sitemaps →
sitemap.xml입력 → 제출 클릭sitemap-0.xml,server-sitemap.xml등은 인덱스에서 자동 추적된다.
(2) 색인 요청
- 중요한 페이지(
/todos,/planner,/profile등)를 열어
“URL 검사” → “색인 생성 요청” 버튼을 눌러두면
Google이 바로 크롤링 대기열에 추가한다.
(3) 색인 현황 모니터링
- “색인 현황” 리포트에서 유효 / 제외 페이지를 본다.
- “Duplicate” 또는 “Alternate canonical” 경고 → canonical·무슬래시 정책 점검
- “Blocked by robots.txt” → 공개해야 할 페이지가 차단되지 않았는지 확인
- “성과” 탭에서 노출, 클릭, 검색 쿼리를 분석한다.
(4) 주간 점검 루틴
- 주 1회 정도 Search Console에 들어가 색인 현황을 확인한다.
- 새 기능이나 새 페이지를 배포하면 sitemap이 자동으로 갱신되므로
별도의 수동 작업은 필요 없다.- 다만, 로그인·개인정보 관련 페이지는
noindex로 유지한다.
💡 요약
시점 해야 할 일 세팅 단계 (지금) SITE_URL등록, sitemap/robots 확인, postbuild 연결, Search Console 속성 추가운영 단계 (페이지 완성 후) sitemap.xml 제출, 색인 요청, 색인 현황 모니터링, 주기적 점검