Chapter 8 Virtual Memory
가상 메모리 :
사람의 욕심은 끝이 없기 때문에 점점 더 큰 메모리를 원한다.
메모리 관리 요구사항
- Relocation
- Logical organization
- Physical organization
- Protection
- sharing
- Bigger memory (virtually infinite)
Hardware and Control Structures
우리가 메모리 관리에서 중요한 두가지 특징
- 모든 메모리의 참조
- 프로그래머가 생각하는 모든 메모리 참조는 논리 주소인데 논리 주소를 물리 주소로 바꾸어주는 것이 필요하다.
- 프로세스를 연속적이지 않은 메모리 덩어리로 나누어 메모리에 넣고 실행시키는 것이 필요하다.
- 이러한 사항에서 반드시 수행 중에 메인 메모리에 모든 프로그램이 들어갈 수는 없다.
만약 두 개의 특성이 만족 된다면 페이지나 세그먼트가 모두 메인 메모리에 들어갈 필요가 없다.
필요할 때 가져오고, 필요 없으면 세컨더리 저장소에 집어 넣으면 되는데 이를 os가 해결하고자 한다.
가상기억장치 정리하기
Virtual memory
메모리를 할당하는 방법으로 세컨더리 저장소를 프라이머리 메모리와 같이 프로그램에서 접근할 수 있도록 해주는 기억장치 이다.
만약에 발생한 주소가 메인 메모리에 없는 기억 장소를 가리킨다면 그것을 자동으로 os에 의해서 메인 메모리에 가져오게 하는 방법이다.
모든 주소는 앞에서 본 것처럼 물리적 주소로 실행 시간에 번역되서 메인 메모리에 없으면 세컨더리 저장소에서 그것을 번역해서 가져오도록 확장한 것이다.
이러한 가상 저장소의 크기는 범위가 없는데, 컴퓨터 시스템 안에 번역하는 테이블 크기와, 세컨더리 저장소의 크기에 한정이 된다.
세컨더리 저장소가 메인 메모리보다 더 크기 때문에 사용자가 보기에 크기의 제한이 없는 메모리를 만들게 된것이다.
단점은 세컨더리 저장소에 접근하기 때문에 속도가 느려진다.
Virtual address
논리적 주소를 의미한다.
Virtual address space
개발자가 보는 프로세스의 주소 공간인데 그 주소공간은 결국 무한정으로 커지게 된다.
Address space
한 프로세스가 쓸 수 있는 주소공간.
Real address
메인 메모리에서 저장소 위치의 주소를 뜻한다.
Execution of a Process
한 프로세스가 실행되기 위해서 운영체제는 메인 메모리로 프로그램의 조각을 가져오게 되고 실행하게 된다.
메인 메모리 안에 들어있는 프로세스의 조각을 Resident set이라고 부른다.
만약에 프로그램이 실행되다가 메인 메모리에 없는 것이 발견되면 인터럽트가 발생되고 운영체제는 그 프로세스를 블록상태로 만든다.
Think Execution of a Process
메인 메모리에 없는 프로그램의 덩어리를 가져오기 위해 논리 주소에 접근이 되면 운영체제는 디스크 i/o를 발생시킨다.
다른 프로세스는 블록이 되고 딴 프로세스가 디스패치되어 cpu를 차지하여 실행한다.
디스크 i/o가 완료되면 인터럽트 시키고, 운영체제는 해당 되는 메모리 블록을 메인 메모리에 집어 넣었다는 사실을 프로세스 컨트롤 블록에 페이지 매이핑 테이블에 집어 넣고 그 프로세스를 준비 상태로 만들어 준다.
Implications
더 많은 프로세스가 메인 메모리에 들어 올 수 있다.
- 각 프로세스의 조각들이 부분적인 로딩이 가능하다.
- 메인 메모리에 들어와 있는 프로세스의 개수는 많아지고 준비 상태의 프로세스 개수가 증가한다.
프로세스는 모든 메인 메모리 보다 더 커진다.
Real and Virtual Memory
Real memory
메인메모리, RAM
virtual memory
디스크에 있는 메모리
메인 메모리의 크기에 의해서 한정되는 프로그래머의 어려움을 해결한다.
Thrashing
virtual memory에도 단점은 있다.
보조 기억장치를 사용해서 swapping process가 발생하게 되고 i.o 인터럽트가 발생하게 되고 os의 수행 속도가 느려진다. 전체 cpu 시간 중에 io인터럽트 처리 시간이 증가하면서 사용자가 쓸 수 있는 시간이 줄어든다. 이를 쓰레싱이라고 한다.
즉 프로세스의 처리시간보다 페이지 교체에 소요되는 시간이 더 많아 지는 현상
Principle of Locality
지역성이 중요하다
프로그램과 데이터는 특정 부분에 접근하다.
커다란 행렬을 가지고 연산을 하게 되는데 연산을 한다는 것은 행렬에 집중적으로 계산이 집중된다. 짧은 구간 동안에 연산들이 집중적으로 접근이 된다. 그 계산이 한번 시작되면 계산이 집중된다는 추측이 가능하다. 그렇게 된다면 지역성 만큼의 크기가 실제 메모리에 존재한다면 쓰레싱을 피할 수 있다. 반대로 그것보다 적은 메모리를 사용한다면 쓰레싱이 발생한다.
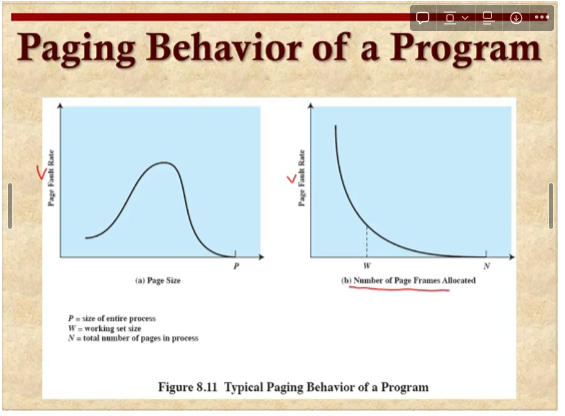
Paging Behavior
우리가 프로그램을 수행시키면서 페이징이 어떻게 발생하는지 살펴보자
페이지 번호, 수행시간

특정 시간에 메모리가 집중되는 것을 확인 할 수 있다.
Support Needed for virtual memory
지역성을 잘 활용하면 큰 용량의 메모리를 저렴한 비용으로 만들 수 있다.
지역성을 활용한다면 → 하드웨어는 반드시 페이징과 세그멘테이션을 지원해야한다.
운영체제는 반드시 테이블을 채워주고 보조기억장치를 할당해주고 인터럽트를 처리해서 메인메모리에 가져와주고 메인메모리에서 업데이트된 메모리 내용을 보조기억장치로 보내준다.
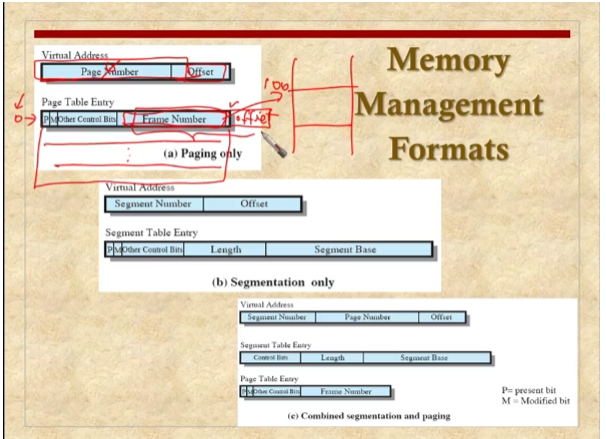
Paging
가상 메모리를 제공하기 위해 각 프로세스가 페이지 테이블을 가지게 된다.
각각의 페이지 테이블 엔트리는 메인메모리에서 상응하는 페이지의 프레임 숫자를 가진다.
페이지 테이블의 엔트리가 여러개 존재한다.
페이지 테이블의 엔트리는 물리 페이지 프레임의 주소를 저장하는 역할을 수행
커다란 프로그래밍 가능한 메모리를 만들기 위해 페이징을 이용
프로그램을 페이징으로 나누고 그것과 같은 크기인 페이징 프레임 단위로 메인 메모리를 나누어서 그들 사이에 매핑을 해서 실행시간에 가상 주소를 실제 주소로 변환시켜주는 방법
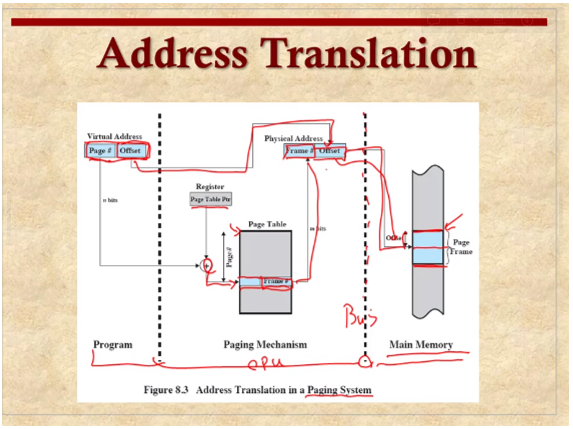
페이지 테이블을 사용해서 페이지 매핑 테이블을 각 프로세스마다 가지고 있어서 논리 주소를 물리 주소로 변환시켜준다.
페이징에서 주소 변환는 virtual address , 그니깐 논리 주소가 주어진다면 그것의 페이지넘버를 잘라서 그 부분을 프리픽스로 해서 페이지 테이블 포인터라는 페이지 테이블의 첫 부분을 가리키는 레지스터의 값과 더해서 그것을 인덱스로 엔트리를 찾는다 일종의 배열인 것이다. 여기서 프레임 넘버를 꺼내서 그것과 이 뒤에 offset을 붙혀서 실제주소를 만들고 그 주소를 내보내서 메모리에 접근하게 된다.
os가 하는 일은 페이징 테이블을 채워준다.
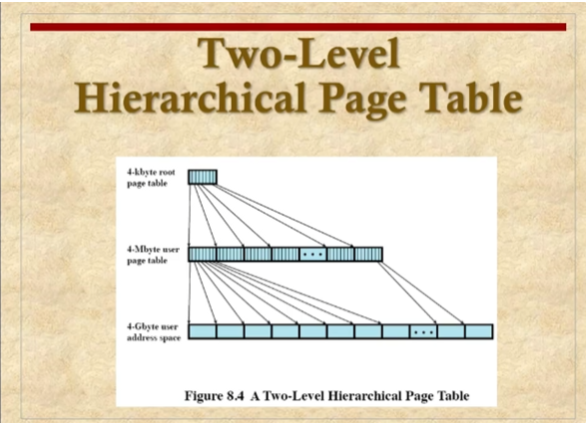
페이지 매핑 테이블을 만들면 모든 전체 주소 공간에 대해서 테이블을 가지고 있어야 해서 엔트리가 많아진다.
페이지가 1kbyte라면 1GBytes로 나누면 1Mbyte의 엔트리 갯수가 필요하다. 프로그램이 커지면 커질 수록 큰 페이지 테이블이 필요해지기 때문에 계층으로 나누어서 적어도 두 개의 레벨로 나누어 문제를 해결한다.
필요한 부분에 대해서 만 매핑 테이블을 만든다. 프로세스당 페이지 테이블을 만드는데 필요한 메모리 공간을 줄이게 된다.

Inverted Page Table
역 변환 페이지 테이블
테이블이 프로세스 당 하나 씩 생긴다. 전체 메모리를 가지고 테이블을 만들고 그것을 프로세스에게 나누어주자고 생각하게 되었는데 이를 역변환 페이지 테이블이라고 한다.
페이지 번호 부분을 하드웨어 해싱을 사용해서 특정 엔트리를 가리키게 한다. 그 엔트리가 역변환 페이지 테이블이 된다.
하나의 실제 메모리에 연결된 것이다. 주소 변환을 위해 각 프로세스 당 역변환 페이지 테이블의 엔트리만 가지고 있으면 거꾸로 주소를 변역할 수 있다.

전체 메모리에 대해서 해쉬 테이블 가지고 있다가 프레임 넘버를 찾도록 한 것이다.
Inverted Page Table
각 엔트리에 대해서 페이지 넘버에 대해서 프로세스 id와 컨드롤 bit, chain pointer로 구성되어 있다.
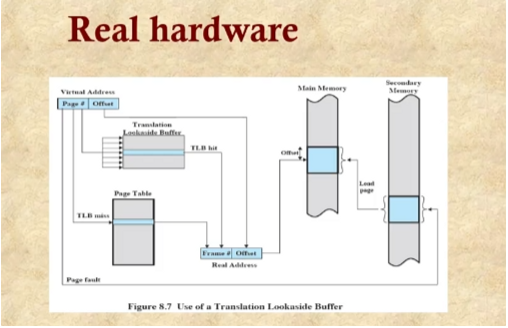
어느 방식을 사용하더라도 페이지 테이블을 가져야 하는데 페이지 테이블 자체가 메모리에 저장되면 한번 메모리 접근을 위해 테이블이 하나이면 두번 메모리 접근해야 하고 이계층이면 3번 메모리에 접근해야한다. 메모리 접근 속도는 느리기 때문에 한번 메모리 접근할때마다 10이라는 시간이 든다면 주소 변환이라면 시간이 점차 늘어난다. 그래서 이 주소 번역에 대한 캐쉬를 만들게 되었다 이를 TLB 라고 한다.
가상 메모리는 한번 메모리에 접근하기 위해 두번의 메모리 접근을 한다. 첫번째는 페이지 테이블 엔트리를 가져오기 위해서 두번째는 실제 데이터를 가져오기 위해서
이를 극복하고자 TLB를 만들었다. 일종의 빠른 속도 캐쉬이다.
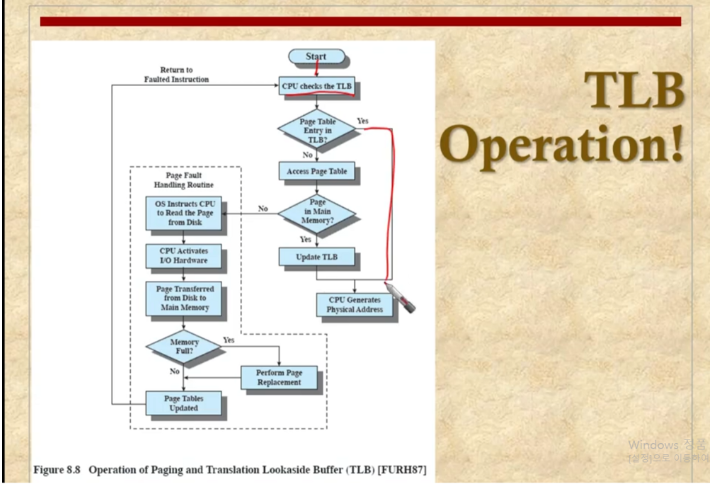
페이지 번호를 가지고 TLB라 하는 컨텐츠 어드레스 메모리를 검색을 한다. 동시에 검색을 하는데 엔트리를 찾게 되는데 이를 가지고 프레임 넘버를 집어넣어 offset에 붙혀서 실제 주소를 찾느다. 만약 메인 메모리에 없으면 보조기억 장치에 찾아간다.
TLB의 Operation
Associative Mapping
TLB를 만들기 위해서 Associative 메모리를 사용한다.
지금 사용하는 대부분의 프로세스는 TLB를 가지고 있는데 그것을 Associative 메모리를 가지고 구현했고 이는 하나의 칩 안에 있다.
Page Size
작은 사이즈로 페이지를 만드면, internal frgmentation 이 작을 것이다.
- 하나의 프로세스를 위해서 많은 페이지가 필요로 하다
- 페이지를 여러개 사용하면 페이지 테이블의 크기가 커진다. → 메모리 효율 감소
- 멀티 프로그램이 많이 일어나는 환경일 경우 테이블의 어떤 부분은 가상 메모리에 들어가게 된다.
- 대부분의 보조기억 장치는 블록 장치로 읽어내는데 커다란 사이즈의 메모리 테이블을 읽는 것이 효율적이다.

Page size
페이지 사이즈라는 것은 결국에 물리적 메모리가 얼마나 되는지 많이 사용하는 프로그램의 크기는 얼마나 되는지에 많이 영향을 받는다.
그런데 메인 메모리는 점점 커지고 우리가 사용하고 있는 휴대폰의 경우 메모리 크기가 점점 커졌다. 앱의 크기가 점점 커지고 있다. 컴퓨터의 역사에 있어서도 어플리케이션의 크기가 커져왔다. 디스크에서 한번에 읽어내는 크기가 4k가 되어서 페이징을 해서 디스크로부터 메인메모리로 가져올때 한번 읽어낼 수 있는 블록의 크기만큼 가져오는 것이 효율적이다.
Segmentation
페이징은 외부 조각화 없이 메모리를 사용할 수 있지만 프로그램을 구성하는 각 세그먼트들 단위로 관리가 되지 않아서 Sharing과 protect이 이루어지지 않고 있다.
세그멘테이션은 프로그램이 컴파일 되서 만들어진 덩어리인 세그먼트 단위로 메모리를 관리한다. 각 메모리 덩어리들 별로 메모리를 증가시킨다던지 컴파일 한다던지 공유나 보호하는 것에 있어서 아주 효율적이다.
프로그래머가 보는 입장에서 공유과 보호를 할 수 있다.
Segment organization
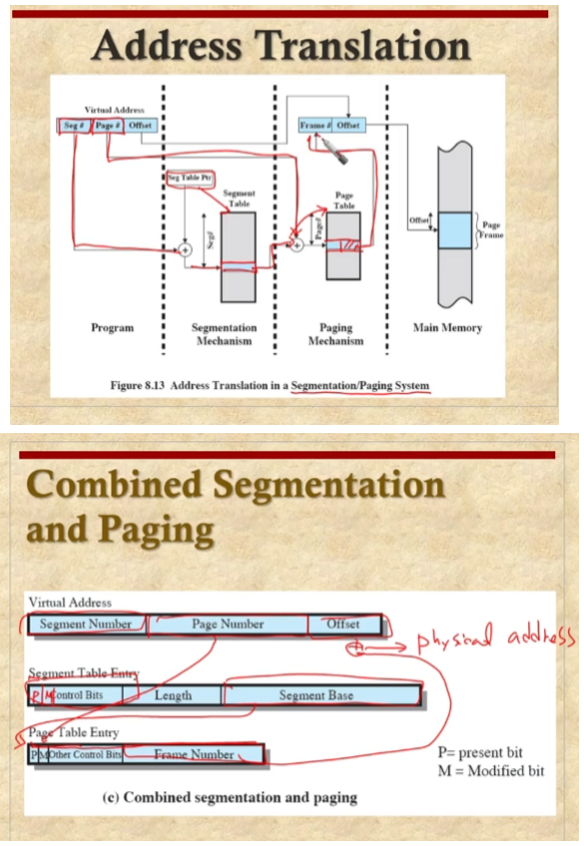
세그먼트 테이블 엔트리는 세그멘트의 시작 주소와 길이 값을 갖는다
만약 세그먼트가 이미 메인 메모리 안에 있다면 bit는 결정하는데 있어서 필요해진다.
실제로는 세그멘테이션과 페이징을 결합해서 사용한다.
먼저 세그먼트를 만들고 프로그램이 있으면 텍스트 데이타 bss 스택 이들을 프로그램 이미지가 되는데 이때 text를 다 페이지 단위로 나눈다. 세그멘테이션은 프로그래머한테 보여주는 단위, 페이징은 프로그래머한테 보이지는 않지만 메모리 관리의 좋은 점 외부 조각화가 일어나지 않는다.

세그멘테이션은 보호와 공유를 논리적 단위로 해줄수 있게 해준다.
세그멘테이션 엔트리는 base 주소와 길이가 들어있다.
이 단위로 공유 했을 때 몇개가 사용되고 있는지 참조 값을 가지고 있다.
Operating System Software
우리가 운영체제 소프트웨어는 다음과 같은 구분점에 의해서 구분된다
가상 메모리를 사용하고 있는지 아닌지
있다면 세그멘테이션, 페이징, 세그멘테이션/페이징을 쓰는지
기본 메모리 관리 메카니즘을 위해 어떠한 정책으로 메모리 관리를 하는지 가있다,
Policies for Virtual Memory
앞에서 제공하는 기본 메카니즘을 가지고 어떻게 하면 페이지 폴트를 적게 만들 수 있을까?
페이지 폴트를 줄이기 위해서 여러 정책들이 만들어 졌다.
Fetch Policy : 어떻게 페이지를 가져올것인가
- 필요할때마다 가져온다.(Demand Paging)
- 미리 가져온다. (Prepaging)
Placement Policy : 가져온 페이지를 메인 메모리 안에 어디에 둘 것인가.
Replacement Policy: 메인 메모리가 부족할때 기존에 있는 프로그램의 페이지를 내보내고 그 빈곳에다가 새로운 페이지를 넣을 때 기존의 페이지 중에서 어떤 것을 내보낼 것인가.
- Optimal : 미래를 내다 본다면 최적 필요없는 페이지 내보내기
- Least recently used(LRU) : 최근에 덜 사용된 것 → 자주 사용됨
- First-in-first-out(FIFo) : 처음 들어온 것이 처음으로 제거한다.
- Clock : LRU를 간편화 한것
희생되는 페이지를 버퍼로 관리한다.
프로세스 별로 필요한 페이지 프레임의 갯수를 관리를 한다면 그것이 지역성을 수용할 만큼 유지가 된다면 페이지 폴트 수를 줄일 수 있다.
Resident set Management
- Resident set size
- Fixed
- Variable
- Replacement Scope : 레지던트 셋을 제거할 때
- Global
- Local
Cleaning Policy : 데이터가 수정된 페이지를 언제 적을지에 따라서
- Demand : 필요할 때
- Precleaning : 미리
Load Control
Degree of multiprogramming
Fetch Policy
페이지를 보조기억장치에서 메인메모리로 가져오는 방법
- 필요할때 가져오는 방법 : Demand Paging
- 페이지를 가져올때 다른 것을 곁들여서 가져오는 방법 : Prepaging
Demand Paging
하나의 참조가 어떤 페이지에 대해서 시작이 됐을때 참조가 됐을데 메인메모리로 그 페이지를 가져온다. 초반에는 페이지 폴트가 많이 생길 수 있으나 초반이후에는 페이지 폴트가 급격히 떨어진다.
Prepaging
초반에 많은 페이지 폴트가 생기는 Demand paging의 단점을 줄이기 위해 생겨난 기술이다.
페이지 폴트가 발생한 페이지 말고도 다른 페이지를 가져온다.
이 함께 가져오는 operation은 보조기억장치에서 인접된 블록을 읽는 것이 빠르기 때문에 좀더 효율적이다
다만 가져온 페이지가 안쓰일때 비효율적으로 변한다.
Placement Policy
가져온 페이지를 어디에 놓는지에 대한정책
가져온 프로세스를 실제 메모리에 어디에 놓을 것인가에 대해서는 세그멘테이션에 있어서 아주 중요한 디자인 요소이다.
페이징과 연결된 페이징의 경우에는 별로 중요하지 않는다.
병렬처리기 중에서 NUMA 시스템에서는 아주 중요한 역할을 한다.
페이지를 어디에 놓느냐에 따라서 메모리 접근 속도가 다르기 때문이다.
Replacement Policy
새로운 페이지가 메모리에 들어와야할때 기존의 메모리를 모두 쓰고 있을때 어느 한 페이지의 프레임을 비워서 새로 가져온 페이지를 집어넣어야 하는데 어떤 것을 선택할까?
희생이 된 페이지가 다시 금방 읽어 들어와야 한다면 무의미한 일이 되므로 미래에 사용되지 않을 페이지를 내보내는 것이 목적이다.
Frame Locking
어떤 페이지의 경우 예외적으로 디스크로 내보내면 안되는 페이지의 경우 locking을 건다.
커널 에서 사용되는 커널의 제어 구조체와 같은 경우 보조기억장치로 가면 안된다.
I/O 버퍼 그리고 time-critical areas는 메인 메모리 프로엠 안에 있어야 한다.
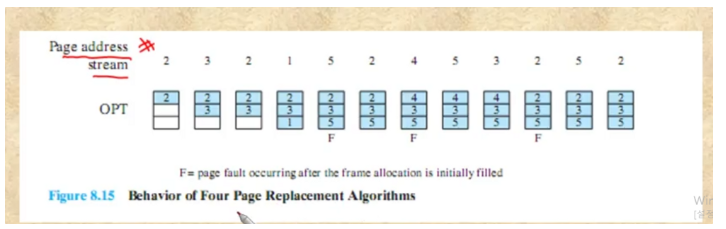
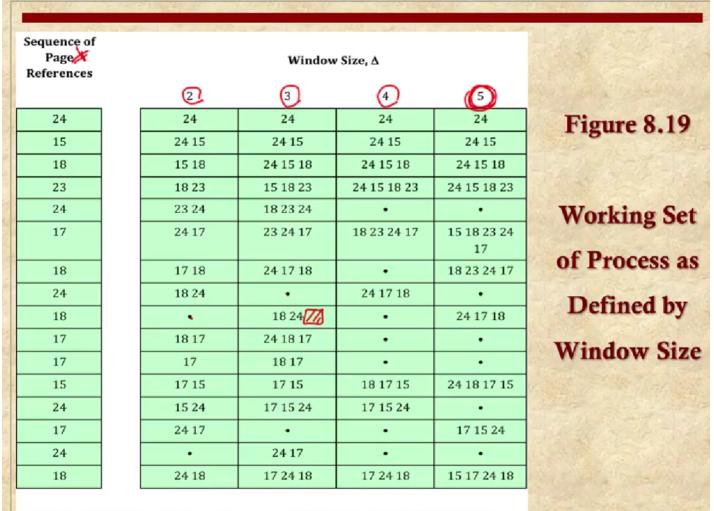
Optimal Policy
가장 먼 미래에 사용될 페이지를 선택하는 것이다.

2번이 들어왔으면 2번이 프레임을 차지 3번이들어오면 또 차지 2번이 들어오면 그대로 1번이 또 차지
5가 새로 들어왔는데 어느 것을 내보낼까? 미래를 봤을때 2번과 3번이 사용되므로 1번을 내보내고 5번으로 채워넣는다.
그다음에 2가 오는데 그대로 사용되고 4가 오면 5와 3이 사용되므로 2를 대체한다.
2대신에 4를 넣는다. 5와3은 그대로 2가 오면 없으므로 뭔가 하나를 빼야하는데 2와5가 사용되므로 4를 제거해서 2를 넣는다.
전체 페이지 교체는 3번이 일어난다.
미래를 알수 없는데 어떻게 하냐? → 만약 미래를 알 수 있다면 그것이 최적이므로 다른 방법과 이방법을 이용해서 다른 알고리즘의 성능을 파악한다.
Least Recently Used (LRU)
가장 최근에 사용되지 않은 페이지를 제거
지역성에 의하면, 미래에도 사용되지 않을 가능성이 높다
문제는 시간 정보가 있어야 한다. 이 시간 정보는 마지막 참조가 될때마다 업데이트가 되어 저장되어야 한다. 각 페이지마다 이렇게 시간정보를 넣는 것은 세그멘테이션 테이블이 차지 하는 양이 많은데 이보다 더 늘어나게 된다. 이는 감당하기가 어렵다 . 따라서 사용하기도 어려운데 지역성에 따르면 가장 좋은 거고 이론적으로 의미가 있다. 실제로 사용되지는 않는다.
동영상 비디오 캐시를 다룰 때 사용

2,3,1 이 채워졌다. 5가 들어오면 가장 오래된 것이 교체 되는데 3이 가장 오래되서 교체가 된다. 4가 오면 2 5 1 중에 가장 오래전에 사용된 1이 교체 된다. 3이오면 5 4 2 중에 가장 오래된 2가 대처된다. 2가 오면 3 5 4 중에 4가 제거된다.

First-in-First-out (FIFO)
LRU는 시간정보를 페이지 테이블 엔트리마다 유지해야해서 사용할 수 없다.
이 방법은 라운드 로빈 스타일로 페이지를 제거한다.
가장 먼저 들어온 것을 제거한다.
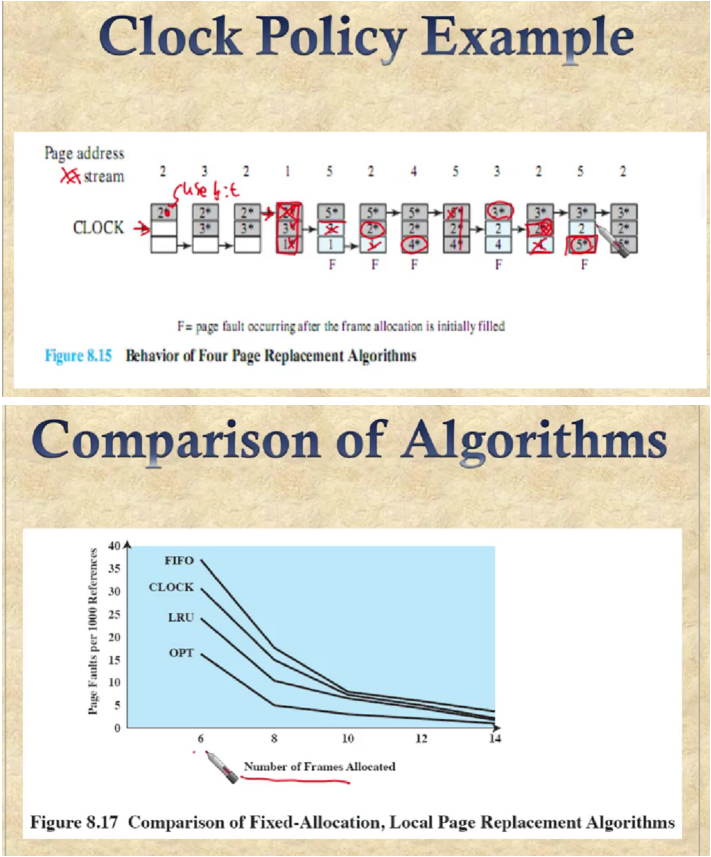
Clock Policy
각 페이지 프레임에 대해서 시간 정보 전체를 넣는 대신에 몇개의 추가적인 bit를 이용해서 그를 대처한다.
use bit을 1로 set → 해당 페이지가 사용되고 있다.
페이지 프레임들을 circular buffer 처럼 이용하면서 교체가 필요할때 use bit이 1로 되어 있는 것을 0으로 바꾸어주고 제거한 후 새로 넣어준다.
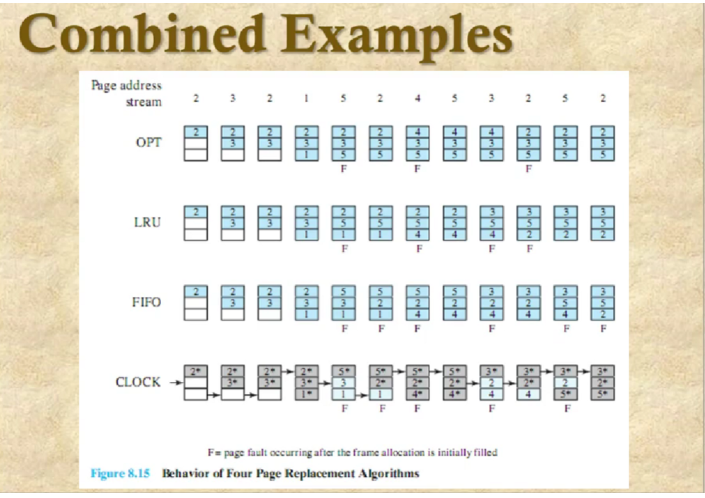
페이지 프레임의 갯수가 늘어나면 차이가 줄어든다. 프레임 갯수가 줄어들면 차이는 커진다

Page Buffering
페이징의 수행능력을 좋게 만들기 위해서 교체를 할때, 페이지들을 모아서 버퍼로 관리하는 방법이다.
교체를 할 페이지들을 실제로 디스크에 쓰는 일은 시간이 많이 들어서, 시스템에서 버퍼로 관리해서 두 개의 리스트를 가지고 관리를 하게 된다.
Free Page list : 쓸(write) 필요가 없는 페이지의 리스트
Modified Page list : 수정된 페이지들 가지고 있다가 디스크나 ssd에 써주게 된다.
페이지 버퍼링은 결국 캐시로 동작한다. 페이지 버퍼 안에서의 교체를 어떻게 하냐에 따라 성능에 영향을 미친다.
Resident Set Management
Resident set은 컴퓨터 시스템에서 현재 실행 중인 프로세스가 물리적인 메모리(RAM)에 올라와 있는 부분을 의미
Working set은 특정 시간 동안 프로세스가 실제로 사용한 메모리의 집합을 나타냅니다.
OS는 프로세스에 필요한 프레임의 갯수를 결정한다.
적게 만들수록 많은 프로세스가 메모리 안에 들어올 수 있. 그렇지만 각 프로세스보다 적게 할당하면 페이지 폴트를 많이 유발한다.
페이지를 몇 개 할당할지 결정을 직접적으로 하는 것이 좋은 해결책이다.
필요한 페이지 프레임 갯수보다 더 많이 할당하는 것은 좋은 결정은 아니다.
Resident set Size
프로세스 마다 할당할 프레임 페이지의 갯수를 결정하는 것은
Fixed-allocation : 고정된 갯수의 프레임 페이지를 나누어 주고 페이지 폴트가 발생했을 때, 자기 자신이 같고 있는 페이지 중에 교체할 페이지를 선택해야한다.
variable-allocation : 프로세스가 시작된 이후에도 할당된 프레임 페이지 갯수를 바꾸어 줄 수 있다.
Replacement scope
이러한 Resident set을 유지하는데 있는 방법에 있어서 페이지 교체를 할때 대상이 되는 것을 global 하게 할것인가? 프로세스 안에 한정되게 할것인가 두가지 방법이 있다.
Local : 프로세스의 Resident 페이지 안에서 선택
Global : 메인 메모리 전체에서 희생 페이지를 선택
Fixed Allocation, Local Scope
통계에 의해서 프로세스 별로 필요한 메모리의 사이즈, 페이지 프레임의 갯수를 알아내고 그것 만큼 할당
그것 보다 적게 할당하면 페이지 폴트가 발생, 많게 할당되면 프로세스의 idle time 발생→비효율적
Variable Allocation, Global Scope
가장 구현하기 쉽다
OS는 프리 프레임의 리스트를 유지한다.
페이지 폴트 발생시 프리 프레임은 프로세스의 working set에 맞춰서 resident set을 더한다.
만약에 프레임이 더이상 사용불가능하다면 교체가 되고 교체시간을 줄이기 위해 페이지 버퍼링을 이용
Variable Allocation, Local Scope
새로운 프로세스가 메인 메모리 안에 들어오게 되면, 페이지 프레임을 할당해주고, 페이지 폴트가 발생하면 교체할 페이지를 선정해서 배치를 해주고 전체 성능을 확인하면서 프로세스에게 페이지를 할당해주거나 회수하거나 하는 방법이다.
할당하는 프레임 페이지의 개수를 정하는게 중요하다. 이것은 미래에 얼마나 프레임 페이지를 사용하는지 추측하는 문제이다.
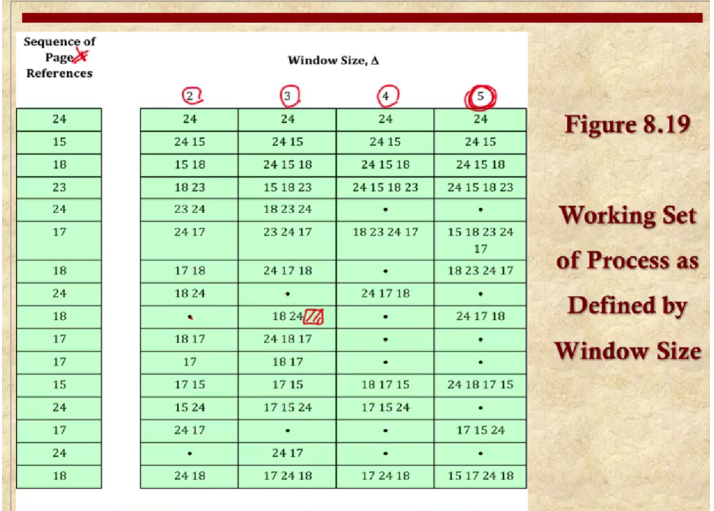
할당되는 프레임 페이지의 개수가 커지면 변화없이 유지되는 개수가 많아 진다.
Page Fault Frequency(PFF)
이 방법은 use bit을 사용해서 이것이 1이라는 것은 clock 정책처럼 이 페이지가 사용되는 것을 알려준다.
페이지 폴트가 발생할때 os는 use bit을 사용해서 일정시간동안 덜 사용된 페이지를 선택해서 교체를 한다.
이 방법은 트랜지션이 일어나는 동안에 working set이 바뀌고 있는 동안에는 일어나지 않는다.
이 방법이 transient 기간(시스템이 변화하거나 조정되는 동안의 일시적인 시간 간격을 의미)동안에 새로운 locality가 변하는 동안에 잘 동작하지 않는것을 해결하기 위해 VSWS가 제안됐다.
Variable-interval sampled Working Set(VSWS)
Working set의 크기를 추측하기 위해서 이 세가지 변수를 사용한다.
The minimum duration
The maximum duration
The number of page faults
Cleaning Policy
Modified 페이지는 보조기억장치에 반드시 적혀야 되는데 적혀질때, 교체가 일어날때에만 적는 것인 Demand Cleaning이 있다.
그것과 상관 없이 하드디스크나 ssd에 적혀지는데 성능을 얻기 위해서 배치로 적는 방법이 있다(precleaning)
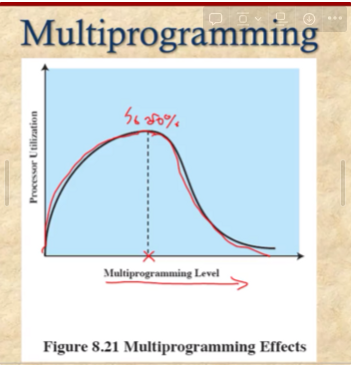
Load Control
실행하는 프로세스의 개수를 조절해서 간접적으로 스레싱이 발생하지 않도록 해주다.
실행중인 프로세스의 개수를 멀티프로그래밍 레벨을 일정한 정도를 유지한다.
너무 적은 프로세스가 돈다면 cpu가 낭비
너무 많으면 스레싱 발생
적절할 수의 프로세스 수 유지하기
Process Suspension
이렇게 부하의 정도를 조절해서 스레싱이 발생하지 않도록 할때 중단하는 프로세스를 없애는 것이 아니라 스와핑 한다. 서스팬드 시킬때 어떠한 프로세스를 서스팬드 시킬지 골라야 한다.
6가지 방법
- Lowest-priority process
- Faulting process
- Last process activated
- process with the smallest resident set
- largest process
- process with the largest remaining execution window
Unix
초기에 유닉스 운영체제는 Variable partitioning을 하고 버추얼 머신을 가지지 않은 운영체제였다. 그뒤에 유닉스는 솔라리스 운영체제와 함께 페이징을 사용하는 가상 기억장치를 제공하고 있다. 유닉스의 운영체제에는 페이징 시스템과 커널 메모리 할당을 제공하고 있다.
페이징 시스템은 가상 기억장치를 제공하는 기억장치 관리 방법
커널 메모리 할당은 가상 기억장치가 사용되기 전에 사용되는 메모리 할당이다.
