
📒문제


📌 1차 풀이
<코드>
from collections import defaultdict
def solution(info, query):
data = defaultdict(list)
score_data = defaultdict(list)
result = []
for i, s in enumerate(info):
d1, d2, d3, d4, d5 = map(str, s.split())
d5 = int(d5)
data[d1].append(i)
data[d2].append(i)
data[d3].append(i)
data[d4].append(i)
score_data[d5].append(i)
for q_str in query:
num = 0
q_str = q_str.replace(' and ', ' ')
query_set = list(map(str, q_str.split()))
tmp_1 = set()
flag = -1 # 아직 합집합으로 시작하지 않음을 의미하는 플래그 이게 바뀌면 이제 교집합 연산을 해준다
for i in range(0, 4):
if query_set[i] == '-':
continue
if query_set[i] != '-' and flag == -1:
flag = 1
tmp_1 = tmp_1 | set(data[query_set[i]])
elif flag == 1:
tmp_1 = tmp_1 & set(data[query_set[i]])
tmp_2 = set()
for k in score_data.keys():
if k >= int(query_set[4]):
for i in range(len(score_data[k])):
tmp_2.add(score_data[k][i])
if flag == 1: result.append(len(tmp_1&tmp_2))
else: result.append(len(tmp_1|tmp_2))
return result<코드 설명>
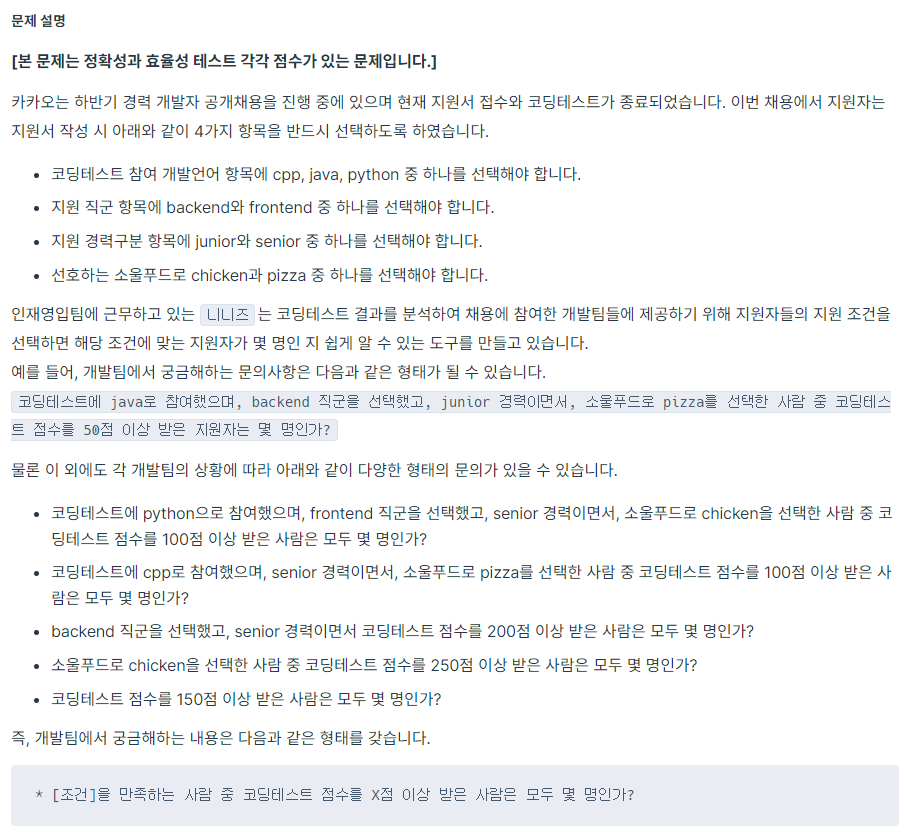
문제를 처음 봤을때 나는 이 문제가 정확성과 효율성 배점이 나눠져 있는 것을 보고 무조건 해시맵을 사용해야 하는 문제라고 일단 생각이 들었다.
-
enumerate를 사용하여, 나눈 문자열을 key값으로, index값(여기선 지원자를 구분하는 기준으로 사용함)을 value값으로 하는 해시맵을 defaultdict, data로 작성해준다. 다만 코딩테스트 점수는 일치만 하면 되는 다른 파트와 달리 기준 값 이상을 가진 지원자를 모두 찾기를 요구하고 있으므로, 점수 값만 저장하는 해시맵을 작성해 주었다.
여담으로 솔직히 이거보단 코드를 더 깔끔하게 쓸 수 있을 것 같은데, 아직 경험이 부족한 것인지 아주 찝찝하게 코드를 작성한 기억이 있다....
for i, s in enumerate(info):
d1, d2, d3, d4, d5 = map(str, s.split())
d5 = int(d5)
data[d1].append(i)
data[d2].append(i)
data[d3].append(i)
data[d4].append(i)
score_data[d5].append(i)-
다음은 query를 분석하는 과정을 거쳤다. query의 문자열에 주어지는 형태는
java and backend and junior and pizza 100
과 같은 식인데, 다른 분야와는 달리 코딩테스트 점수는 앞에 and가 없어 나중에 split을 통해 문자열을 파싱할 때 분명 문제가 될 것이라고 생각했다. 따라서 " and " 를 빈 칸으로 replace를 통해 바꾸어 빈 칸을 기준으로 문자열을 파싱하도록 했다.
q_str = q_str.replace(' and ', ' ')
query_set = list(map(str, q_str.split()))- 그리고 코딩테스트 점수를 제외한 분야에 관해 탐색을 진행한다. 여기서 4개 분야에 대한 조건을 만족하는 지원자를 tmp_1 집합에 저장해준다. flag 변수는 처음 조건을 만족하는 지원자를 찾았을 땐 교집합 연산이 아닌 합집합 연산을 해야만 tmp_1 집합에 추가 될 것이므로, (초기에는 tmp_1이 공집합이기 때문에) 이를 구분하는 변수를 넣어주었다.
tmp_1 = set()
flag = -1 # 아직 합집합으로 시작하지 않음을 의미하는 플래그 이게 바뀌면 이제 교집합 연산을 해준다
for i in range(0, 4):
if query_set[i] == '-':
continue
if query_set[i] != '-' and flag == -1:
flag = 1
tmp_1 = tmp_1 | set(data[query_set[i]])
elif flag == 1:
tmp_1 = tmp_1 & set(data[query_set[i]])🎈 Case1) 만일 파싱한 문자열이 '-'라면, 해당 분야에 대한 조건은 모든 지원자가 만족하므로 굳이 합집합을 통해 계산할 이유가 없다.
🎈 Case2) 파싱한 문자열이 '-'는 아니지만 처음 탐색한 분야라면, tmp_1에 조건을 만족하는 지원자를 추가하기 위해 합집합 연산을,
🎈 Case3) 그 이외의 경우에는 교집합 연산을 통해 조건을 모두 만족하는 지원자들을 솎아낸다.
- 4개 분야와는 달리 코딩테스트 점수는 일치 뿐만 아니라 query에 명시된 점수 이상을 받은 모든 지원자들을 찾을 것을 요구하므로,
score_data의 key값을 반복문으로 돌면서 query의 코딩테스트 점수보다 높거나 같다면 score_data에 저장된 모든 지원자들을 tmp_2에 넣는다.
tmp_2 = set()
for k in score_data.keys():
if k >= int(query_set[4]):
for i in range(len(score_data[k])):
tmp_2.add(score_data[k][i])-
그리고 최종적으로 tmp_1과 tmp_2에 대한 조건을 만족하는 지원자를 한번더 교집합 연산으로 솎아낸다.
이때 합집합 연산을 하는 경우는 (flag == -1) 4개 분야에 대한 모든 query가 '-'이어서 tmp_1에 대한 조건을 고려할 필요가 없는 경우이다. 이때 tmp_1은 공집합이다.
다만, flag==1일 때 tmp_1이 공집합이라면, 이는 조건을 만족하는 지원자가 단 한 명도 없는 경우이므로, 이때는 합집합 연산이 아닌 교집합 연산을 해주어야 한다.
따라서 tmp_1이 공집합이라도 이유는 서로 다르므로, len을 통해 조건을 나누면 틀릴 수 밖에 없다...
if flag == 1: result.append(len(tmp_1&tmp_2))
else: result.append(len(tmp_1|tmp_2)) 다 쓰고 보니 틀린 풀이를 이렇게 자세하게 설명하면서 정리하는 건 좀 잘못된 공부 방향 아닌가 싶다. 앞으로 velog에 올릴 땐 틀린 풀이는 간결하게 쓰고, 올바른 풀이를 자세하게 써주어야 겠다.
📌 2차 풀이
사실 예상은 했지만, 정확성만 통과하고 효율성은 통과하지 못했다. 그래도 해시맵을 썼으니 어느정도는 통과하지 않을까 실낱같은 희망을 걸어봤는데 해시맵을 쓰는건 당연한 거였다 ㅋㅋㅋㅋ
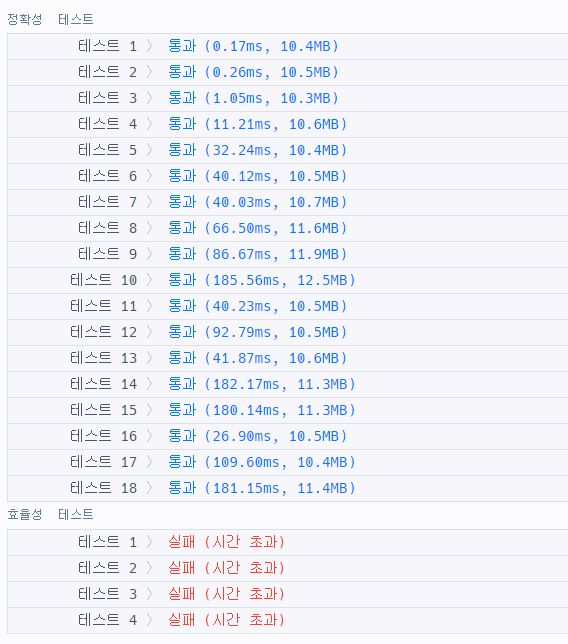
1시간 정도 고민하면서 생각을 해봤는데 먼저 조건을 만족하는 지원자를 순차적으로 구하는 부분과, 코딩테스트 점수 기준을 만족하는 지원자를 반복문을 돌면서 구하는 부분이 비효율적이라고 판단해 머리를 굴려봤는데 도저히 생각이 안 났다.... ㅠㅠ
카카오 공식사이트의 풀이와 다른 분들의 코드를 참조하면서 모범 답안을 작성해 보았다.
from itertools import combinations as combi
from collections import defaultdict
from bisect import bisect_left
def solution(info, query):
answer = []
data = defaultdict(list)
for i in info:
i = i.split()
i_key, i_val = i[:-1], int(i[-1])
for j in range(5):
for cb in combi(i_key, j):
key = "".join(cb)
data[key].append(i_val)
for key, val in data.items():
data[key].sort()
for q in query:
q = q.replace(' and ', ' ')
q = q.replace('- ', '')
q = list(map(str, q.split()))
q_key = "".join(q[:-1])
q_val = int(q[-1])
if q_key in data.keys():
n_left = bisect_left(data[q_key], q_val)
answer.append(len(data[q_key]) - n_left)
else: answer.append(0)
return answer🎈1. info 데이터 정돈하기
기존에 틀렸던 코드는 분야 하나하나 별로 key를 만들어서 dict에 저장해두었다면, 모범 코드는 모든 분야를 종합한 값을 key로, 코딩테스트 점수값을 value로 저장한다. 이때 핵심은 해당 info가 포함될 수 있는 그룹을 조합을 통해 모든 케이스를 dict안에 저장한다는 것이다.
- 예를 들어 java backend junior pizza 150 지원자의 경우에는
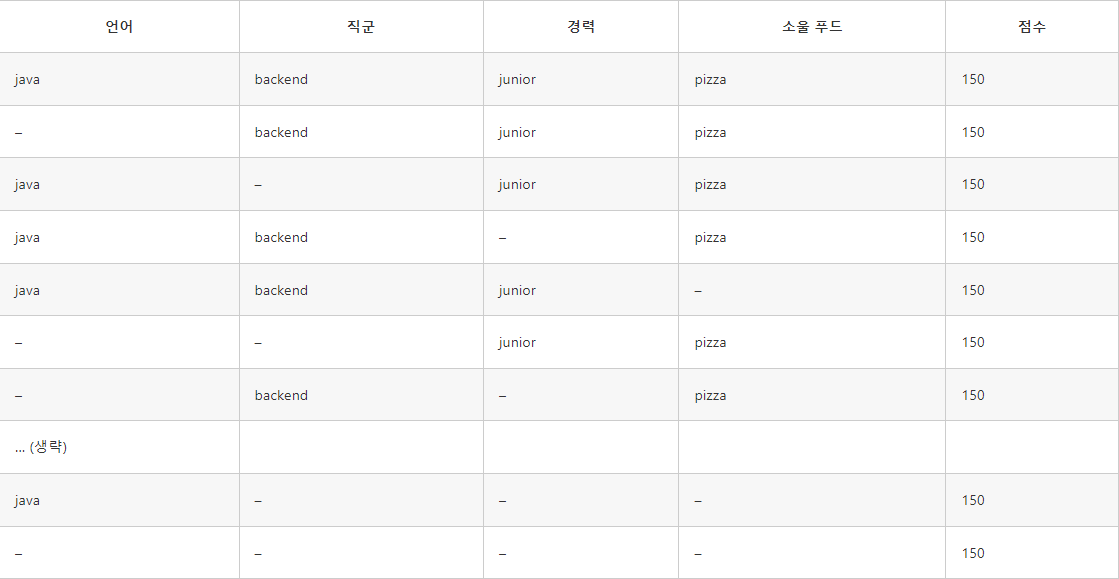
이때 이 지원자는 java, backend, junior, pizza 그룹에도 속할 수 있고, -, backend, junior, pizza 그룹에도 속할 수도 있다. dict에는 key를 그룹 이름(javabackendjuniorpizza, backendjuniorpizza...), value는 리스트로 점수값을 저장한다.
answer = []
data = defaultdict(list)
for i in info:
i = i.split()
i_key, i_val = i[:-1], int(i[-1])
for j in range(5):
for cb in combi(i_key, j):
key = "".join(cb)
data[key].append(i_val)그리고 나중에 점수값을 이진 탐색하기 위해, dict안의 모든 list를 정렬해준다.
for key, val in data.items():
data[key].sort()🎈2. query값
for q in query:
q = q.replace(' and ', ' ')
q = q.replace('- ', '')
q = list(map(str, q.split()))
q_key = "".join(q[:-1])
q_val = int(q[-1])
if q_key in data.keys():
n_left = bisect_left(data[q_key], q_val)
answer.append(len(data[q_key]) - n_left)
else: answer.append(0)replace를 통해 key값과 value값을 파싱해준다.
그 후, query 조건에 알맞는 info그룹이 존재한다면, 이진 탐색을 통해 해당 조건을 만족하는 인원을 세주기만 한다. data에는 query조건에 부합하는 지원자들의 코딩테스트 성적이 미리 정렬된 리스트 형식으로 저장되어 있기 때문이다.
이때, 해당 점수 이상을 받은 지원자의 수를 구해야 하므로, lower bound, 곧 bisect_left를 한 후 전체 리스트 길이에서 빼주면 해당 점수 이상을 받은 사람 수를 구할 수 있게 된다.
🎈3. 결과
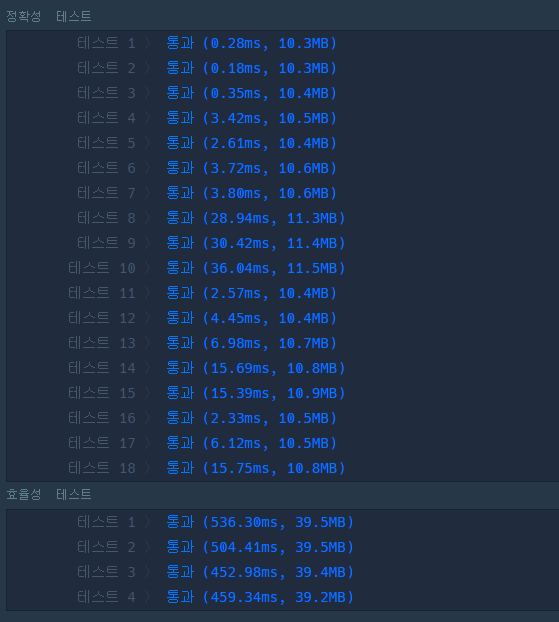
📌새롭게 알게 된 Python의 유용한 기능
- 이진 탐색할 때는 bisect_left, bisect_right 를 사용할 수 있지만, 기준 데이터보다 큰/작은 데이터의 개수를 구할때도 유용하게 쓰일 수 있다.
- combinations같이 긴 함수 import할때는 as를 통해 내가 원하는 이름으로 바꿔 쓸 수도 있다.
