📢 데이터베이스들의 기본 용어들
기본 용어 #1
- Database : Relation의 집합
- Relation : 순서 없는 tuple의 집합, table과 동일.
- Relation Schema: attribute의 집합
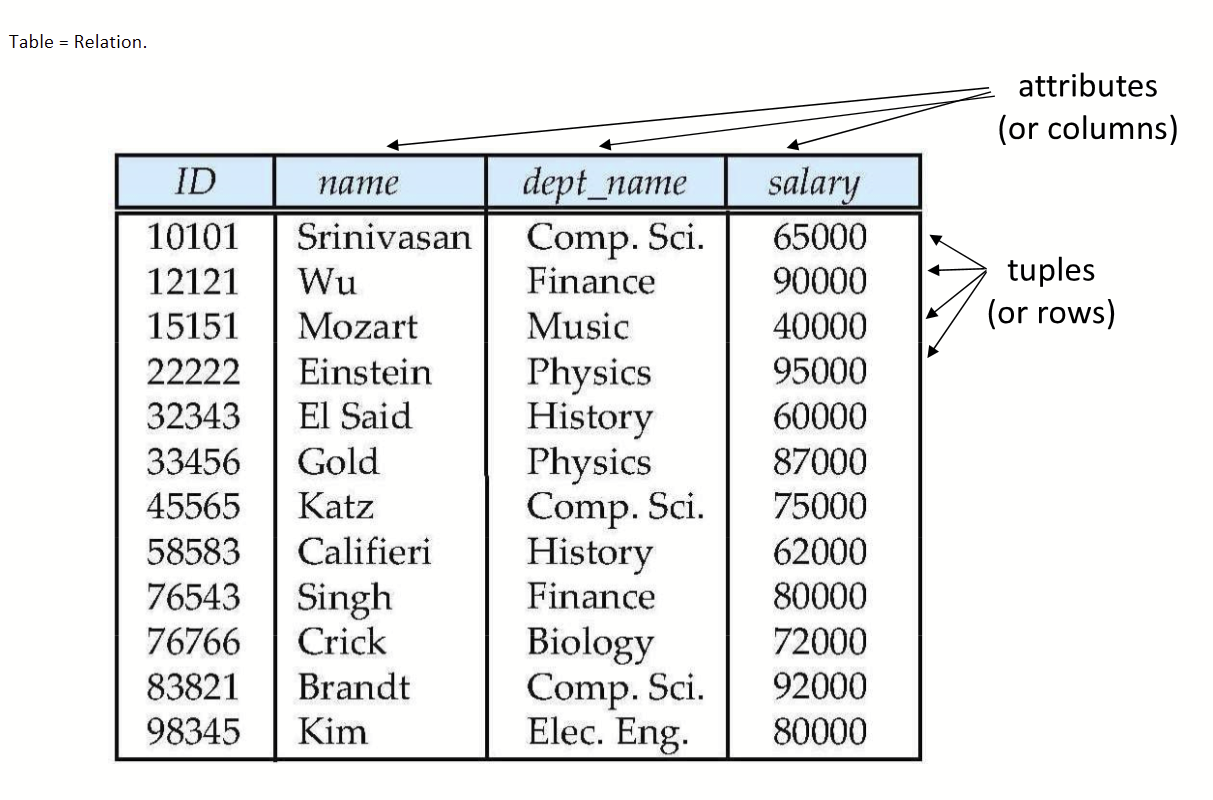
- 📜 해당 table의 relation schema는 {ID, name, dept_name, salary}
- Attribute(속성, column) : table의 열에 해당, 대체로 atomic함(속성 값은 고유)
- Domain : 각 속성에 해당하는 값들의 집합(+null은 모든 domain의 원소)
📜 예를 들어, dept_name 속성의 domain은 {Comp, Finance, Music, Phycics, Biology....}- Tuples (튜플, row): table의 행에 해당
기본 용어 #2
- Super key: 만일 Relation R의 특정 attribute들의 집합 K가 특정 tuple을 구분 할 수 있는 기준이 될 때, K를 R의 Super key라고 한다.
- 📜 (ID), (ID, Name)은 모두 instructor table의 super key이다.
- Candidate key: super key 중 집합의 크기가 가장 작은 super key
- 📜 (ID), (ID, Name)중 (ID)가 instructor table의 candidate key이다.
- Primary key: 여러개의 candidate key중 특별히 선택한 key
- Foreign key: 한 테이블의 속성 중 다른 테이블의 행을 식별할 수 있는 키
- 📜 주문 정보 테이블에 물건 이름과 ID를, 회원 정보 테이블에 ID가 있을 때, ID는 회원을 식별할 수 있는 foreign key가 된다.
📢 Relational Algebras & Operators
📜 Relational Algebras
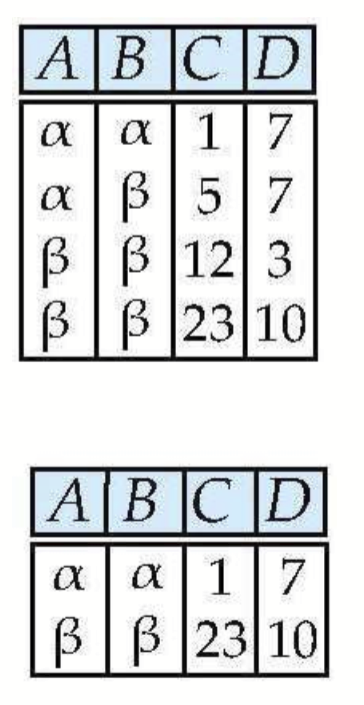
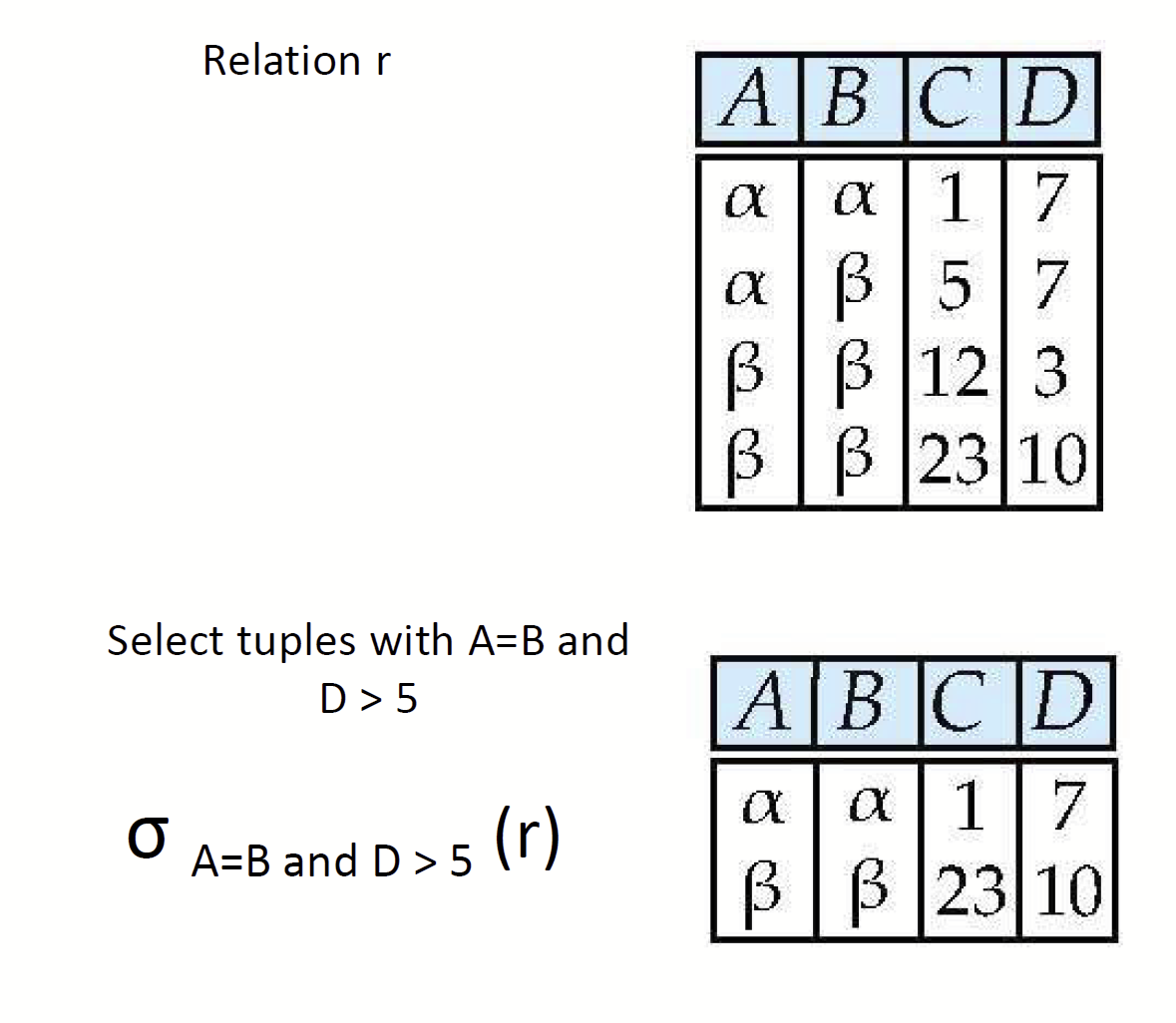
- Selection(σ) : 조건에 맞는 튜플들을 가져온다.
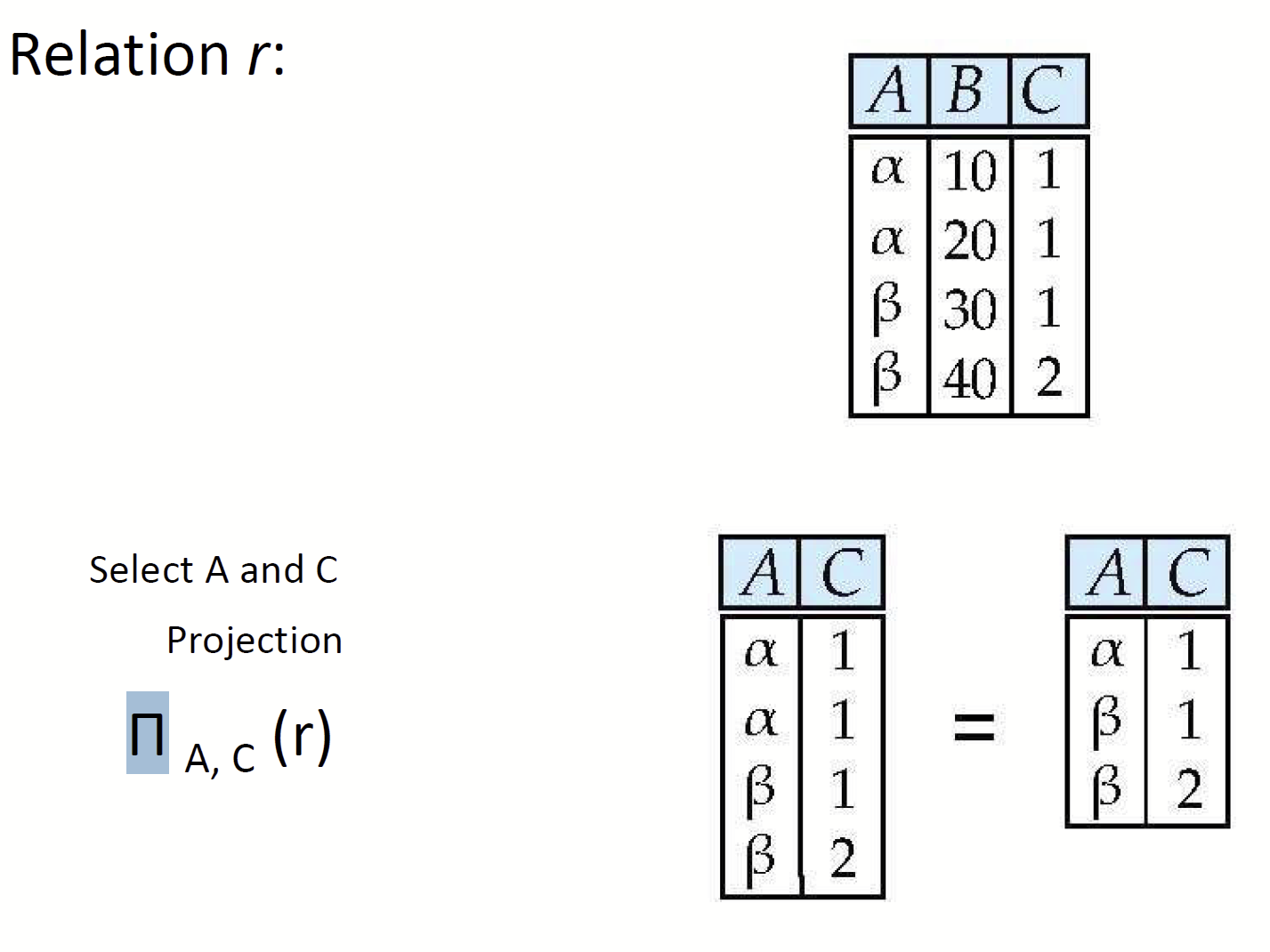
- Projection(Π) : 원하는 속성들만 보이도록 한다.
- Cartesian Product(X) : Relation끼리의 곱연산 수행
- Union(U), set difference(-), set intersection : Relation끼리의 합, 차, 교집합 연산 수행
- Natural Join(리본모양) : Relation끼리의 겹치는 속성의 값이 서로 동일할 때 그 tuple을 결합
e.g) 아래의 사례를 보면, B와 D가 서로 겹치는 속성이고, s에서 r의 맨 첫 번째 튜플과 B, D 값이 같은 튜플은 첫 번째, 세 번째 튜플이므로 이 튜플을 결합해준다.
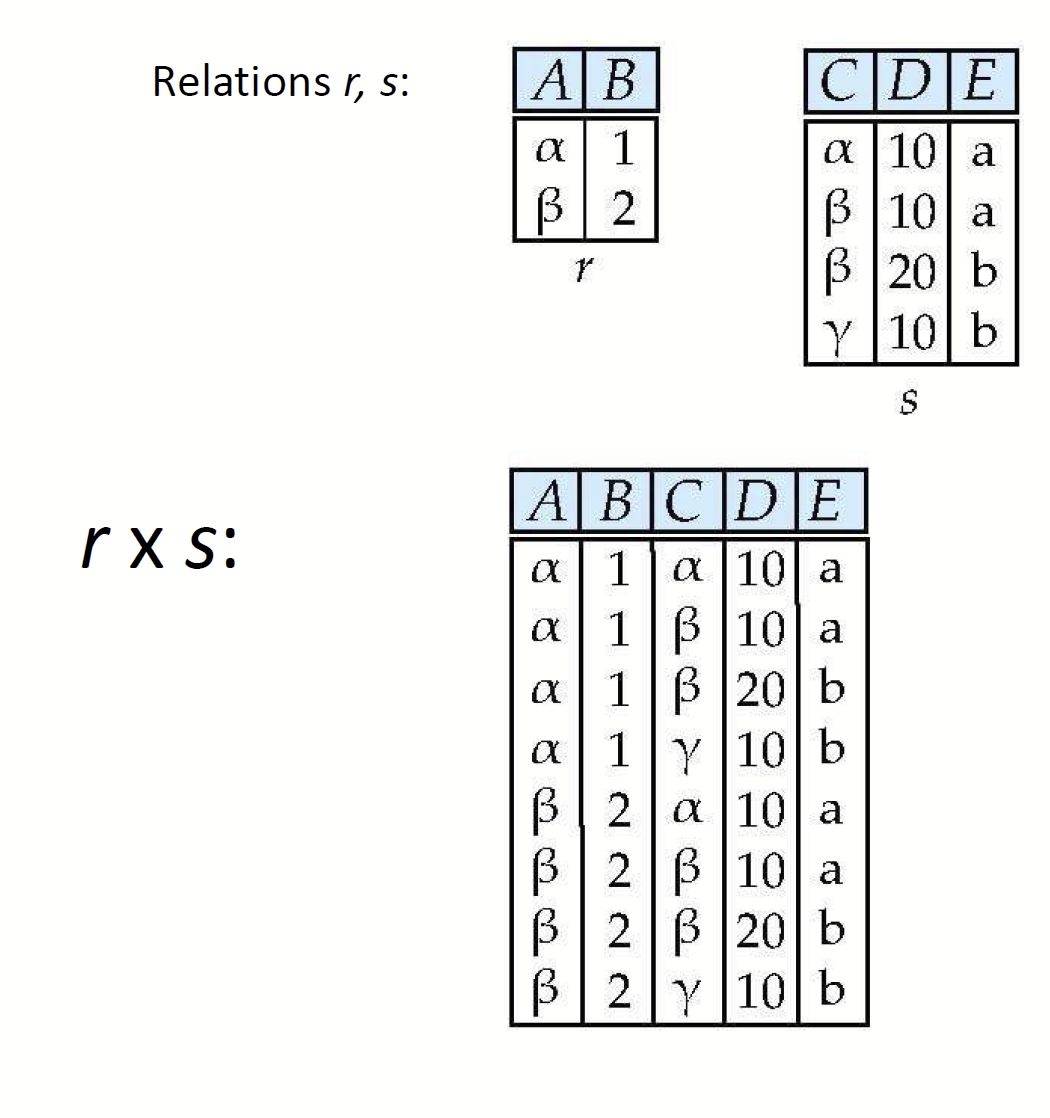
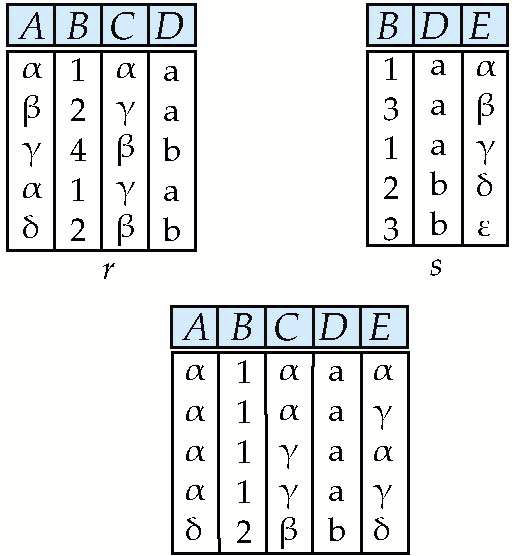
- Natural Join은 Cartesian product와 Selection으로 구현이 가능하기 때문에 기본 연산자는 아니며, Relational algebra의 기본 연산자는 Selection, Projection, Set difference, Cartesian Product, Union이다.

꿈이 많은 개발자 지망생