
프로그래머스의 퍼즐 조각 채우기같은 문젠 줄 알았는데 그것보다는 쉬운 것 같았다.
문제
폴리오미노란 크기가 1×1인 정사각형을 여러 개 이어서 붙인 도형이며, 다음과 같은 조건을 만족해야 한다.
- 정사각형은 서로 겹치면 안 된다.
- 도형은 모두 연결되어 있어야 한다.
- 정사각형의 변끼리 연결되어 있어야 한다. 즉, 꼭짓점과 꼭짓점만 맞닿아 있으면 안 된다.
정사각형 4개를 이어 붙인 폴리오미노는 테트로미노라고 하며, 다음과 같은 5가지가 있다.
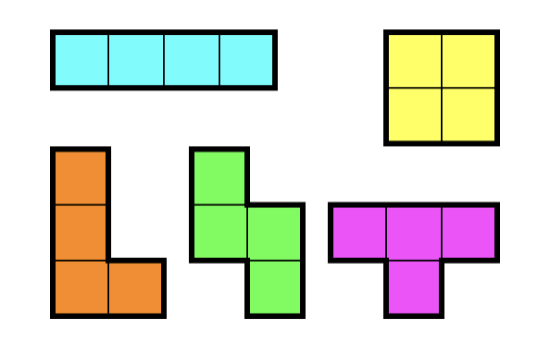
아름이는 크기가 N×M인 종이 위에 테트로미노 하나를 놓으려고 한다. 종이는 1×1 크기의 칸으로 나누어져 있으며, 각각의 칸에는 정수가 하나 쓰여 있다.
테트로미노 하나를 적절히 놓아서 테트로미노가 놓인 칸에 쓰여 있는 수들의 합을 최대로 하는 프로그램을 작성하시오.
테트로미노는 반드시 한 정사각형이 정확히 하나의 칸을 포함하도록 놓아야 하며, 회전이나 대칭을 시켜도 된다.
입력
첫째 줄에 종이의 세로 크기 N과 가로 크기 M이 주어진다. (4 ≤ N, M ≤ 500)
둘째 줄부터 N개의 줄에 종이에 쓰여 있는 수가 주어진다. i번째 줄의 j번째 수는 위에서부터 i번째 칸, 왼쪽에서부터 j번째 칸에 쓰여 있는 수이다. 입력으로 주어지는 수는 1,000을 넘지 않는 자연수이다.
출력
첫째 줄에 테트로미노가 놓인 칸에 쓰인 수들의 합의 최댓값을 출력한다.
아이디어
- 내 아이디어
-
우선 문제 그림에 주어진 블럭을 회전하고 뒤집으면 총 19개의 서로 다른 모양의 블럭이 나오게 된다.
-
배열의 모든 칸을 한칸씩 탐색하면서 dfs 방식으로 4칸의 블럭 위치를 찾으면 될 거라고 생각했고, 브루트포스 방식이지만 최대한 시간을 줄여보려고 가로로 두칸, 세로로 두칸을 먼저 lst에 넣은 다음에 남은 2칸만 dfs 방식으로 찾으려고 했다.
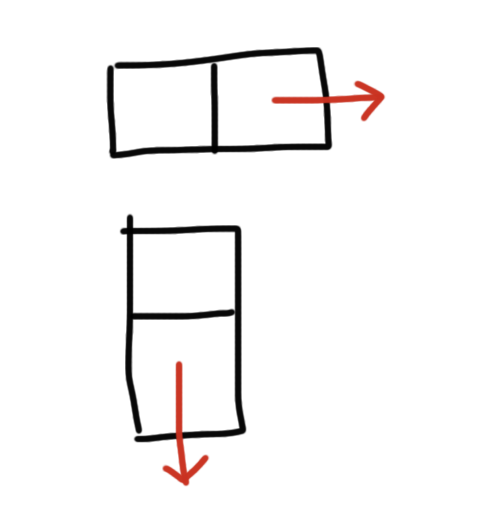
-
그런데 이 방식으로 하면 ㅗ 모양의 블럭은 찾을 수가 없었다. 그래서 테케 3번이 자꾸 틀렸다
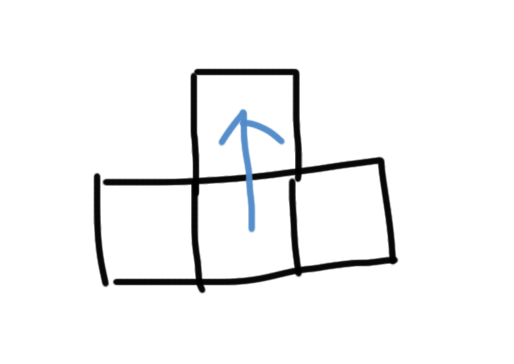
ㅗ 모양은 이런 방식으로 가운데에 있는 블럭부터 찾아나가야 하기 때문에 이 부분은 예외처리를 하고 코드를 다시 짰다. 우선 - ㅣ 모양으로 3칸의 블럭을 찾은 다음에 가운데 부분부터 시작해서 1칸만 가는 dfs 방식을 구현
for i in range(N):
for j in range(M):
if i+1<N:
lst = [[i, j], [i+1, j]]
tetromino(lst, i+1, j, paper[i][j]+paper[i+1][j])
if i+2<N:
lst.append([i+2, j])
tetromino(lst, i+1, j, paper[i][j]+paper[i+1][j]+paper[i+2][j])
if j+1<M:
lst = [[i, j], [i, j+1]]
tetromino(lst, i, j+1, paper[i][j]+paper[i][j+1])
if j+2<M:
lst.append([i, j+2])
tetromino(lst, i, j+1, paper[i][j]+paper[i][j+1]+paper[i][j+2])- 하지만 이런 식으로 찾으면 19개 중 13개는 찾을 수 있는데 아래와 같은 블럭 모양을 찾을 수가 없었다
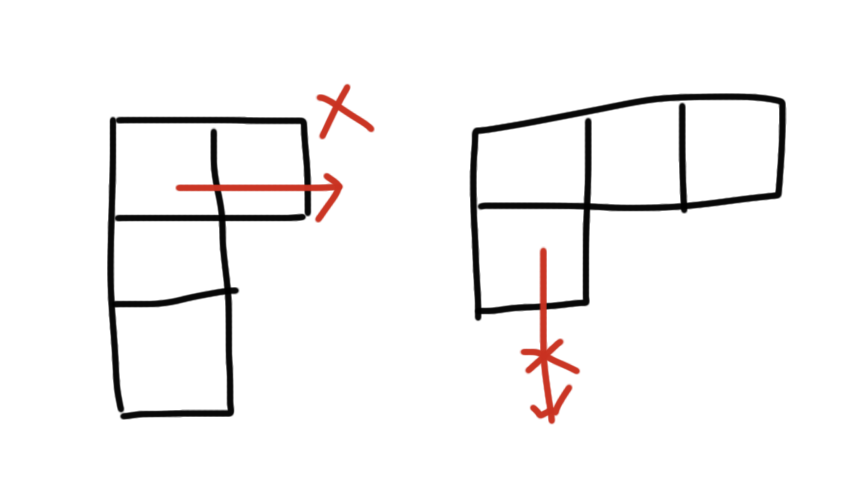
이런 식으로 dfs를 돌려도 찾을 수 없는 방향에 나머지 조각들이 위치하고 있기 때문에.. 그렇다고 첫번째 블럭부터 dfs를 돌리게 되면 이미 찾았던 조각을 한 번 더 탐색하게 되는 중복 탐색이 겁나 많을 것 같았다. 결국 모든 2칸만 미리 담아두는 걸 빼고 그냥 1칸을 시작으로 나머지 3칸을 탐색하는 찐브루트포스 탐색을 했고, ㅗ 부분만 예외처리를 했다
def main():
for i in range(N):
for j in range(M):
tetromino([[i, j]], i, j, paper[i][j])
if i+2<N:
lst = [[i, j], [i+1, j], [i+2, j]]
tetromino(lst, i+1, j, paper[i][j]+paper[i+1][j]+paper[i+2][j])
if j+2<M:
lst = [[i, j], [i, j+1], [i, j+2]]
tetromino(lst, i, j+1, paper[i][j]+paper[i][j+1]+paper[i][j+2])얄짤없이 시간초과가 터졌다
- 더했을 때 최대값을 구하는 것이기 때문에 잘 생각해보면 백트래킹을 할 수도 있다는 점을 몰랐다. 2차원 배열에서 최대 값을 찾은 다음에
(현재까지 구해진 합) + (앞으로 구해야 할 조각의 수) * (2차원 배열의 최대값) < (현재까지 구해진 최대합)
이라는 조건식을 덧붙이게 되면 쓸데없이 4번 다 찾아봤자 답도 아닐텐데 돌아가게 되는 경우의 수를 많이 줄일 수 있게 된다. 백트래킹 안 하면 10배 더 걸림
- 모든 조각을 다 구해놓고 탐색하는 방식(블로그 참고)
- 블럭의 모양만큼만 탐색하는 방식
- 배열의 모든 칸에 대해서 19번의 함수를 호출
# 1236ms
import sys
input = sys.stdin.readline
def block1(r, c):
if r+3<N:
return paper[r+1][c]+paper[r+2][c]+paper[r+3][c]
return 0
def block2(r, c):
if c+3<M:
return paper[r][c+1]+paper[r][c+2]+paper[r][c+3]
return 0
def block3(r, c):
if r+2<N and c+1<M:
return paper[r+1][c]+paper[r+1][c+1]+paper[r+2][c+1]
return 0
def block4(r, c):
if r+1<N and -1<c-2:
return paper[r][c-1]+paper[r+1][c-1]+paper[r+1][c-2]
return 0
def block5(r, c):
if r+2<N and -1<c-1:
return paper[r+1][c]+paper[r+1][c-1]+paper[r+2][c-1]
return 0
def block6(r, c):
if r+1<N and c+2<M:
return paper[r][c+1]+paper[r+1][c+1]+paper[r+1][c+2]
return 0
def block7(r, c):
if r+1<N and c+2<M:
return paper[r+1][c]+paper[r][c+1]+paper[r+1][c+1]
return 0
def block8(r, c):
if r+2<N and c+1<M:
return paper[r+1][c]+paper[r+2][c]+paper[r+2][c+1]
return 0
def block9(r, c):
if r+2<N and -1<c-1:
return paper[r+1][c]+paper[r+2][c]+paper[r+2][c-1]
return 0
def block10(r, c):
if r+1<N and c+2<M:
return paper[r+1][c]+paper[r+1][c+1]+paper[r+1][c+2]
return 0
def block11(r, c):
if -1<r-1 and c+2<M:
return paper[r][c+1]+paper[r-1][c+1]+paper[r][c+2]
return 0
def block12(r, c):
if r+2<N and c+1<M:
return paper[r+1][c]+paper[r+2][c]+paper[r+1][c+1]
return 0
def block13(r, c):
if r+2<N and -1<c-1:
return paper[r+1][c]+paper[r+1][c-1]+paper[r+2][c]
return 0
def block14(r, c):
if r+1<N and c+2<M:
return paper[r][c+1]+paper[r][c+2]+paper[r+1][c+1]
return 0
def block15(r, c):
if r+1<N and c+2<M:
return paper[r+1][c]+paper[r][c+1]+paper[r][c+2]
return 0
def block16(r, c):
if r+1<N and c+2<M:
return paper[r][c+1]+paper[r][c+2]+paper[r+1][c+2]
return 0
def block17(r, c):
if r+2<N and -1<c-1:
return paper[r][c-1]+paper[r+1][c-1]+paper[r+2][c-1]
return 0
def block18(r, c):
if r+2<N and c+1<M:
return paper[r][c+1]+paper[r+1][c+1]+paper[r+2][c+1]
return 0
def block19(r, c):
if r+1<N and -1<c-2:
return paper[r+1][c]+paper[r+1][c-1]+paper[r+1][c-2]
return 0
N, M = map(int, input().split())
paper = [list(map(int, input().split())) for _ in range(N)]
max_sum = 0
for i in range(N):
for j in range(M):
temp_sum = paper[i][j]+max(
block1(i, j), block2(i, j), block3(i, j), block4(i, j), block5(i, j), block6(i, j),
block7(i, j), block8(i, j), block9(i, j), block10(i, j), block11(i, j), block12(i, j), block13(i, j),
block14(i, j), block15(i, j), block16(i, j), block17(i, j), block18(i, j), block19(i, j)
)
max_sum = max(temp_sum, max_sum)
print(max_sum)
- visited를 사용하는 dfs 탐색방식
- 대부분의 짧은 시간을 낸 코드는 다 이 방식이었다. lst에 담기는 블럭이 4조각 밖에 안 돼서 탐색 시간이 짧을 거라고 생각했는데 그래도 방문처리하는 것보다는 시간이 오래 걸리는 거 같다
# 150ms
def find_block(r, c, block_cnt, block_sum):
global max_sum
if block_sum + (4-block_cnt)*max_x < max_sum:
return
if block_cnt == 4:
max_sum = max(max_sum, block_sum)
return
if r+1<N and not visited[r+1][c]:
visited[r+1][c] = 1
if block_cnt == 2:
find_block(r, c, block_cnt+1, block_sum+paper[r+1][c])
find_block(r+1, c, block_cnt+1, block_sum+paper[r+1][c])
visited[r+1][c] = 0
if c+1<M and not visited[r][c+1]:
visited[r][c+1] = 1
if block_cnt == 2:
find_block(r, c, block_cnt+1, block_sum+paper[r][c+1])
find_block(r, c+1, block_cnt+1, block_sum+paper[r][c+1])
visited[r][c+1] = 0
if -1<r-1 and not visited[r-1][c]:
visited[r-1][c] = 1
if block_cnt == 2:
find_block(r, c, block_cnt+1, block_sum+paper[r-1][c])
find_block(r-1, c, block_cnt+1, block_sum+paper[r-1][c])
visited[r-1][c] = 0
if -1<c-1 and not visited[r][c-1]:
visited[r][c-1] = 1
if block_cnt == 2:
find_block(r, c, block_cnt+1, block_sum+paper[r][c-1])
find_block(r, c-1, block_cnt+1, block_sum+paper[r][c-1])
visited[r][c-1] = 0풀이
백트래킹 + dfs
# 624ms
import sys
input = sys.stdin.readline
def tetromino(lst, r, c, sum_nums):
global max_sum
if len(lst) == 4:
if max_sum < sum_nums:
max_sum = sum_nums
return
if sum_nums + maxx * (4-len(lst)) < max_sum:
return
if r+1<N and [r+1, c] not in lst:
tetromino(lst+[[r+1,c]], r+1, c, sum_nums+paper[r+1][c])
if c+1<M and [r, c+1] not in lst:
tetromino(lst+[[r,c+1]], r, c+1, sum_nums+paper[r][c+1])
if -1<r-1 and [r-1, c] not in lst:
tetromino(lst+[[r-1,c]], r-1, c, sum_nums+paper[r-1][c])
if -1<c-1 and [r, c-1] not in lst:
tetromino(lst+[[r,c-1]], r, c-1, sum_nums+paper[r][c-1])
def main():
for i in range(N):
for j in range(M):
tetromino([[i, j]], i, j, paper[i][j])
if i+2<N:
lst = [[i, j], [i+1, j], [i+2, j]]
tetromino(lst, i+1, j, paper[i][j]+paper[i+1][j]+paper[i+2][j])
if j+2<M:
lst = [[i, j], [i, j+1], [i, j+2]]
tetromino(lst, i, j+1, paper[i][j]+paper[i][j+1]+paper[i][j+2])
if __name__ == '__main__':
N, M = map(int, input().split())
paper = [list(map(int, input().split())) for _ in range(N)]
max_sum = 0
maxx = max(sum(paper,[]))
main()
print(max_sum)배열의 최대값 구하는 방식 수정
- 근데 어떤 방식으로 구해도 계속 시간이 400ms 밑으로 안 내려가길래 왜일까 했는데 2차원 배열의 최대값을 구하는 방식을 바꿔주니까 바로 160ms 됨 ㅋㅋ..
max(sum(paper, [])) -> max(map(max, paper))
원래 구하던 방식(오른쪽)은 2차원 배열을 1차원으로 나열한 다음에 거기서 최대값을 찾는 방식이라 최소 O(n^2), 바꾼 왼쪽은 배열의 행마다 돌면서 각 행의 최대값을 찾고 그 최대값들 중에서의 최대값을 찾는 방식으로 최대 O(N^2)인데 여기서 이렇게 오래걸리네...
# 156ms
import sys
input = sys.stdin.readline
def find_block(r, c, block_cnt, block_sum):
global max_sum
if block_sum + (4-block_cnt)*max_x < max_sum:
return
if block_cnt == 4:
max_sum = max(max_sum, block_sum)
return
if r+1<N and not visited[r+1][c]:
visited[r+1][c] = 1
if block_cnt == 2:
find_block(r, c, block_cnt+1, block_sum+paper[r+1][c])
find_block(r+1, c, block_cnt+1, block_sum+paper[r+1][c])
visited[r+1][c] = 0
if c+1<M and not visited[r][c+1]:
visited[r][c+1] = 1
if block_cnt == 2:
find_block(r, c, block_cnt+1, block_sum+paper[r][c+1])
find_block(r, c+1, block_cnt+1, block_sum+paper[r][c+1])
visited[r][c+1] = 0
if -1<r-1 and not visited[r-1][c]:
visited[r-1][c] = 1
if block_cnt == 2:
find_block(r, c, block_cnt+1, block_sum+paper[r-1][c])
find_block(r-1, c, block_cnt+1, block_sum+paper[r-1][c])
visited[r-1][c] = 0
if -1<c-1 and not visited[r][c-1]:
visited[r][c-1] = 1
if block_cnt == 2:
find_block(r, c, block_cnt+1, block_sum+paper[r][c-1])
find_block(r, c-1, block_cnt+1, block_sum+paper[r][c-1])
visited[r][c-1] = 0
def main():
for i in range(N):
for j in range(M):
visited[i][j] = 1
find_block(i, j, 1, paper[i][j])
visited[i][j] = 0
if __name__ == '__main__':
N, M = map(int, input().split())
paper = [list(map(int, input().split())) for _ in range(N)]
visited = [[0 for __ in range(M)] for _ in range(N)]
max_x = max(map(max,paper))
max_sum = 0
main()
print(max_sum)반례
틀렸습니다 : 19개의 블럭 중 구하지 못하고 있는 블럭이 있음
시간 초과 : 백트래킹 안 함
