🔗
풀이
역시 카카오... 너무 어려워...
각 지원자 분류하기
언어, 분야, 경력, 음식 크게 4가지로 분류한 후 각 분류에 맞는 지원자들의 점수를 리스트 형태로 저장했다. 전체를 의미하는 -는 고려하지 않았다.
크게 4가지라서 전체 가지수는 24가지가 되고, 각 조건에 따라서 그 조건에 속하는 키워드들을 갖고 있는 분류에 속하는 지원자들의 점수를 모두 뽑아냈다. 만약 치킨이라는 키워드만 존재한다면, 파이썬-백엔드-시니어-치킨과 자바-프론트-주니어-치킨 2가지 모두가 뽑히게 되는 것이다.
그렇게 모~든 지원자들의 점수를 그냥 하나의 리스트 형태로 반환한 다음에 X 이상인 지원자들의 인원수를 세려고 했지만..... ❌ 시간 초과 ❌
😇 이진 탐색
사실 어디서 에러가 난 건지 감이 안 와서 힌트를 봤더니 다들 이진 탐색을 외치고 있었다. 생각도 못했는데? ㅋㅋ 일단 지원자가 5만이라서 두 번만 중복 탐색해도 25만이다... 일단 단위가 만을 넘어가면 트리를 쓰든 힙을 쓰든 이진 탐색을 쓰든 해야 하는 것 같다.
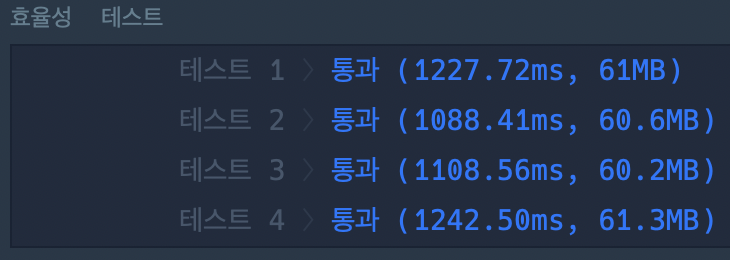
암튼 일단 조건을 만족하는 모든 지원자들의 점수를 합한 리스트를 만든 후 정렬해서 이진 탐색했지만 또 시간 초과였다ㅠㅠ
그래서 이번엔 아래처럼 각 분류에 따른 지원자들의 점수를 각각 정렬한 후, 조건에 만족하는 분류를 찾으면 그 분류내에서 만족하는 점수를 갖는 지원자의 수를 바로 찾았다. 이렇게 하면 다 합쳐서 100명 중 만족하는 점수를 찾을 걸, 7명 20명, 40명 이런 식으로 소분화돼서 찾을 수 있는데 확실히 더 빨리 찾을 수 있는 것 같다. 이렇게 바꾸자마자 바로 통과ㅠㅠ
def solution(info, query):
# 이진 탐색
def binary_search(result):
s, e = 0, len(result)-1
while s <= e:
m = (s+e)//2
if result[m] >= score:
s = m+1
else:
e = m-1
return s
# 조건 만족하는 X 개수 찾기
def find(order, score):
cnt = 0
for key in apply:
for o in order:
if o not in key:
break
else:
# print(apply[key])
cnt += binary_search(apply[key])
return cnt
apply = defaultdict(list)
for i in info:
key, value = i.split()[:-1], int(i.split()[-1])
apply[tuple(key)].append(value)
for i in apply:
apply[i].sort(reverse=True)
answer = []
for q in query:
*order, score = q.split()
order, score = list(set(order) - {'and', '-'}), int(score)
answer.append(find(order, score))
return answer
from collections import defaultdict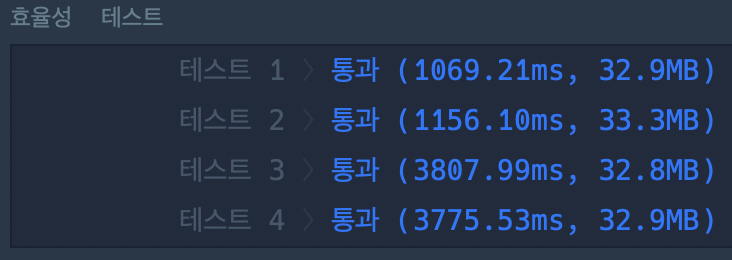
🧐 전체를 고려한 지원자 분류
하지만 역시 이 방법보다 훨씬 더 빠른 방법이 있었다. -를 고려하는 방식이다. 처음에 지원자들의 점수를 저장할 때 이 부분을 고려해서 점수를 저장하게 되면 쿼리를 돌면서 일일이 모든 조건이 만족하는지 찾을 필요가 없다.
위의 풀이에서는 파이썬, -, 주니어, -가 들어올 경우 파이썬과 주니어를 포함하는 모든 분류를 다 찾아냈지만 이 방식으로 하게 되면 [파이썬, -, 주니어, -]라는 키가 어떤 값을 갖고 있는지 한 번에 찾을 수 있다. O(1)만에 탐색이 가능하다.
def solution(info, query):
# 이진 탐색
def binary_search(result, score):
s, e = 0, len(result)-1
while s <= e:
m = (s+e)//2
if result[m] >= score:
s = m+1
else:
e = m-1
return s
apply = defaultdict(list)
for i in info:
i = i.split()
for lang in [i[0], '-']:
for end in [i[1], '-']:
for ior in [i[2], '-']:
for food in [i[3], '-']:
apply[f"{lang, end, ior, food}"].append(int(i[4]))
for i in apply:
apply[i].sort(reverse=True)
answer = []
for q in query:
q = q.split()
answer.append(binary_search(apply[f"{q[0], q[2], q[4], q[6]}"], int(q[-1])))
return answer
from collections import defaultdict조건에 맞는 지원자들을 매번 찾을 필요가 없어 find 함수가 필요 없어졌다. 이진 탐색만 수행하면 된다.