[논문 정리] OCR-free Document Understanding Transformer (WIP)
Abstract
- 현재의 Visual Document Understanding (VDU) 기법은 텍스트 추출을 OCR 엔진에 맡기고, OCR이 반환한 텍스트를 이해하는 방식에 집중해왔다.
- 하지만 OCR을 활용하는 것에는 다음의 3가지 문제가 존재한다.
1. OCR을 사용하기 위해 높은 컴퓨팅 리소스가 필요하다.
2. OCR 모델은 문서의 종류 혹은 언어에 대한 유연성을 갖고있지 않다.
3. OCR에서의 에러가 다음 절차에 영향을 미친다. - 따라서 OCR을 쓰지 않는 VDU 모델인 Donut(Document nderstanding transformer)을 제안한다.
github: clovaai/donut
paper: <OCR-free Document Understanding Transformer>, Kim et al., 2022
1. Introduction
- Visual Documnet Understanding (VDU): 문서 이미지 (송장, 영수증, 명함 등)에서 정보를 추출하는 작업으로, 산업에서 꼭 필요한 작업이면서도 아래의 세부 작업이 수반된다는 점에서 연구자들에게 어려운 주제이다.
- 문서 분류 (document classification)
- 정보 추출 (information extraction)
- 시각질의응답 (Visual Question Answering (VQA)
- 기존 VDU 방법은 two-stage 방식으로 풀이된다.
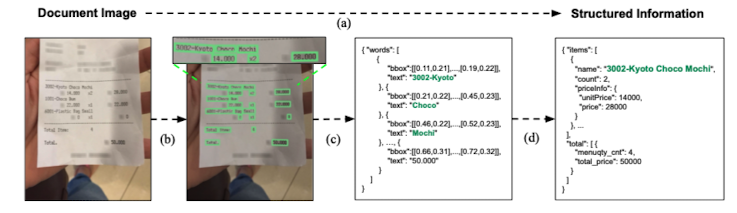 Fig.1. The schema of the conventional document information extraction (IE) pipeline
Fig.1. The schema of the conventional document information extraction (IE) pipeline
- 문서 이미지에서 텍스트 읽기
- 문서의 총체적인 이해
-
OCR-dependent한 방법의 문제점.
- OCR 전처리는 비용이 높다.
- 사전학습된 기성 OCR 엔진을 사용할 수 있지만, 고품질의 OCR 결과를 위한 추론 비용이 높다.
- 기성 OCR은 다양한 언어 및 도메인의 변화에 맞춘 유연한 대응이 어렵다.
- 직접 OCR 모델을 훈련시키는 것 또한 상당한 규모의 데이터셋과 비용이 수반된다.
- OCR에서의 에러가 VDU 시스템에 전파됨으로써 후속 절차에 부정적인 영향을 끼친다.
- 한국어, 중국어와 같이 OCR의 품질이 상대적으로 낮은 경우에 이 문제는 더 심각해진다.
- 이를 위해 OCR 후처리 (교정) 모듈을 도입하는 것이 일반적이나, 전체 시스템의 규모와 유지보수 비용의 측면에서 실용적인 해결책은 아니다.
- OCR 전처리는 비용이 높다.
-
제안
- 이에 OCR 없이 raw input image를 의도된 output으로 직접 매핑시키는 모델을 제안한다.
- 아키텍쳐: Transformer-only
- 간단한 아키텍쳐와 사전훈련 방법으로 기존 방법보다 전반적으로 더 나은 성능을 얻을 수 있다 (아래 Fig.2. 참조).
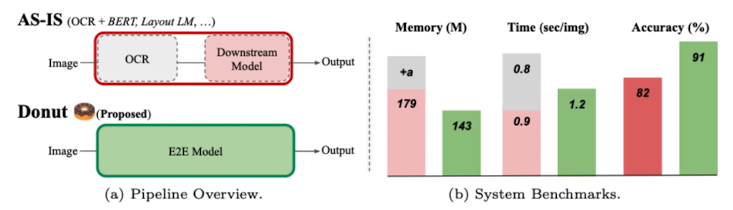 Fig.2. The pipeline overview and benchmarks
Fig.2. The pipeline overview and benchmarks
-
훈련 스키마
- pre-training: 어떻게 텍스트를 읽는지 학습 (이미지와 이전 텍스트 문맥을 함께 조건화하여 다음 단어를 예측하는 방식)
- 합성 데이터를 사용하여 도메인과 언어에 대한 유연성을 확보
- fine-tuning: downstream task에 맞게 전체 문서를 이해하는 법을 학습
- pre-training: 어떻게 텍스트를 읽는지 학습 (이미지와 이전 텍스트 문맥을 함께 조건화하여 다음 단어를 예측하는 방식)
-
본 논문의 기여점
- End-to-End 방식으로 훈련된 최초의 Transformer 아키텍쳐의 OCR-free VDU 방법
- 합성 데이터의 활용을 가능케 한 단순한 사전학습 스키마
- 본 논문에서 제안한 SynthDoG (합성 데이터 생성기)를 통해 편리하게 다국어 설정을 확장할 수 있다.
- 공공 벤치마크와 특정 산업의 데이터셋 모두에 대한 다양한 실험을 진행함으로써 본 방법이 단순히 SOTA 성능을 낼 뿐만 아니라 실용적인 이점(e.g. 비용효율)을 제공한다는 점도 확인했다.
- GitHub에 소스코드, 사전학습 모델, 합성 데이터를 공개하였다.
2. Method
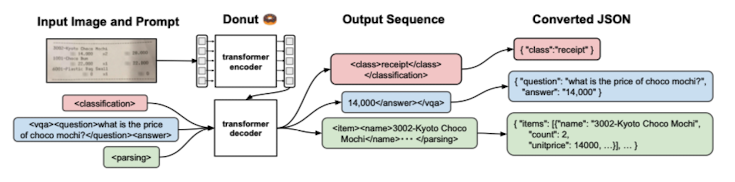 Fig.3. The pipeline of Donut
Fig.3. The pipeline of Donut
2.1 Preliminary: background
(위 Introduction에서의 내용과 겹치므로 생략)
2.2 Document Understanding Transformer
- Donut은 문서 이미지에 대한 전반적인 이해를 하는 End-to-End의 VDU 모델이다.
- 아키텍쳐는 Transformer 기반의 visual encoder와 textual decoder로 구성되어 있다(전체 흐름은 위 Fig.3 참조).
- visual encoder: 주어진 문서 이미지에서 특징 추출을 수행하며, 그 어떤 OCR 기능과 연관된 모듈을 사용하지 않는다.
- textual decoder: 파생된 특징(visual encoder에서 나온 feature)를 일련의 subword 토큰과 매핑하여 원하는 구조화된 형식을 구성한다(e.g., JSON).
Encoder
- Visual encoder는 문서 이미지(input)를 embeddings(output)으로 변환한다.
- input:
- : 이미지 높이
- : 이미지 너비
- : 이미지 채널
- output:
- : feature map의 크기 or 이미지 패치의 수
- : 인코더의 latent vectores의 차원 수
- input:
- 아키텍쳐는 CNN-based 모델, Transformer-based 모델 모두 사용 가능하며, 본 논문에서는 Swin Transformer를 사용하였음.
- 사유: 문서 파싱과 관련된 선행 연구에서 가장 좋은 연구를 보였기 때문
Swin Transformer의 활용
- input image x를 non-overlapping patches로 분할
- Swin Transformer blocks을 patchtes가 통과
- Swin Transformer block의 구성: shifted window-based multi-head self-attention 모듈과 2겹의 MLP
- patch를 병합하는 레이어가 각 단계에서 patch tokens에 대해 적용
- 최종 block의 output인 {z}는 textual decoder에 전달
- 사유: 문서 파싱과 관련된 선행 연구에서 가장 좋은 연구를 보였기 때문
Swin Transformer의 활용
Decoder
- 가 주어졌을 때, textual decoder는 token sequence를 생성한다.
- token sequence:
- : 번째 토큰의 one-hot vector
- : 토큰 사전의 크기
- : 하이퍼파라미터 (각각)
- token sequence:
- 아키텍쳐: BART
- 디코더 모델의 initial weight를 사전학습된 multi-lingual BART 모델로 초기화
Model Input
- 전통적인 Transformer의 방법을 따라 teacher-forcing 스키마를 사용
- teacher-forcing: 학습 간 input으로 이전 time step의 모델 output이 아닌 ground-truth를 사용하는 전략
- Test 때는 GPT-3에서 영감을 받아, 주어진 프롬프트에 맞게 모델이 토큰을 생성
- 실험 간, 각 downstream task의 프롬프트에 스페셜 토큰 추가
- 위 Fig.3의 output sequence에 실험 때 사용한 프롬프트 확인 가능
- teacher-forcing과 decoder의 출력 형식에 관한 추가적인 설명은 논문의 Appendix A.4에서 확인 가능
Output Conversion
- output으로 나온 토큰 시퀀스를 원하는 구조의 형식으로 변환한다.
- 본 논문에서는 JSON 형식을 채택함 (높은 표현 능력 때문)
- 위 Fig.3에서 확인이 가능하듯, 하나의 토큰 시퀀스는 JSON 데이터로 1:1 변환이 가능하다.
- 스페셜 토큰은
[START_*],[END_*]2개만을 사용하였다.*은 추출할 각 영역을 나타낸다.- output 토큰 시퀀스가 잘못 구성되면, 해당 영역이 유실된 것으로 처리한다.
- e.g.)
[START_name]은 존재하지만[END_name]이 없다면 "name" 영역은 추출에 실패한 것으로 간주하였다. - 이는 간단한 정규표현식으로 구현 가능
- e.g.)
2.3 Pre-training
Task
- 모델은 이미지 내 모든 텍스트를 순서에 맞게 읽어내는 것을 학습한다(기본적으로 좌상단 -> 우하단 순 진행).
- 학습 목표: 이미지와 이전 문맥을 함께 조건화하여 다음 토큰 예측의 cross-entropy loss를 최소화하는 것
- pseudo-OCR task로도 해석할 수 있다.
- 모델은 시각적 말뭉치(visual corpora), 즉 문서 이미지에 대한 시각 언어 모델 (visual language model)로 학습된다.
Visual Corpora
- 데이터셋 구축
- IIT-CDIP: 11M 규모의 스캔된 영어 문서 이미지 데이터셋
- CLOVA OCR API (상업용): pseudo text label 획득을 위해 활용
- Synthetic Document Generator (SynthDoG): 하지만 위와 같은 데이터셋은 (특히 다른 언어에 대해) 매번 구축 및 사용이 어렵기 때문에 본 논문의 연구진은 합성 데이터 생성기를 만들었다.
* SynthDoG와 위키피디아(중국어, 일본어, 한국어, 영어)를 사용하여 각 언어별 0.5M 샘플 생성
Synthetic Document Generator
 Fig.4. Generated English, Chinese, Japanese, and Korean samples with SynthDoG.
Fig.4. Generated English, Chinese, Japanese, and Korean samples with SynthDoG.
- 이미지 렌더링 파이프라인은 <SynthTIGER: Synthetic Text Image GEneratoR Towards Better Text Recognition Models>, 2021, Yim et al.에서의 방법을 따랐다.
- 위 Fig.4에서 볼 수 있듯, 생성된 샘플은 여러 개의 컴포넌트로 구성되어 있다; 배경, 문서, 텍스트, 레이아웃.
- 배경 이미지: ImageNet에서 샘플링
- 문서의 질감: 수집한 종이 사진에서 샘플링
- 단어와 어구: 위키피디아에서 샘플링
- 레이아웃: 그리드를 무작위로 쌓는 간단한 rule-based 알고리즘에 의해 생성
- 실제 이미지를 모방하기 위해 여러 이미지 렌더링 기술이 적용되었다. 활용된 이미지 렌더링 기술
- SynthDoG에 대한 자세한 내용과 코드는 논문의 Appendix A.2에서 확인할 수 있다.
Fine-tuning
- 모델은 문서 이미지를 어떻게 이해할지 학습한다.
- 위 Fig.3에서 볼 수 있듯, 본 논문에서 모든 downstream tasks는 JSON 예측 문제로 간주한다.
- decoder는 JSON으로 변환이 가능하면서도 원하는 output 정보를 나타내는 토큰 시퀀스를 생성하도록 학습된다.
3. Experiments and Analysis
3.1 Downstream Tasks and Datasets
 Fig.5. Samples of the downstream datasets.
Fig.5. Samples of the downstream datasets. (a) Document Classification.
(b) Document Information Extraction.
(c) Document Visual Question Answering
Document Classification
- 본 논문에서는 모델이 서로 다른 종류의 문서를 구별할 수 있는지 확인하기 위해 classification task를 테스트하였다.
- 일반적으로 인코딩된 임베딩에 대해 softmax를 통해 클래스 라벨을 예측하는 다른 모델들과 달리, Donut은 문제해결 방법의 일관성을 유지하기 위해 클래스 정보가 담긴 JSON을 생성하도록 하였다.
Document Information Extraction (IE)
-
모델이 문서의 복잡한 레이아웃과 문맥을 완전히 이해했는지 확인하기 위해, 본 논문에서는 다양한 실제 문서 이미지에 대해 IE task를 테스트하였다.
-
모델은 단순히 문자를 잘 읽는 것을 넘어서, 레이아웃과 의미를 이해하여 텍스트 간 복잡한 구조를 도출해낼 수 있어야 한다.
-
평가지표는 2가지를 채택하였다: field-level F1 score, Tree Edit Distance (TED) based accuracy
- F1 Score: 추출한 영역 정보가 ground truth에 속하는지를 확인한다.
- 본 점수는 하나의 문자라도 놓치면 영역 추출에 실패한 것으로 간주한다.
- 본 점수의 한계
- 부분적인 중복을 고려하지 않는다.
- 예측한 구조(그룹, nested hierarchy 등)를 측정할 수 없다.
- TED based metric
- 트리로 표현되는 모든 문서에 사용할 수 있다.
- : ground-truth
- : predicted
- : 빈 트리
- F1 Score: 추출한 영역 정보가 ground truth에 속하는지를 확인한다.
-
데이터셋은 2개의 공개된 벤치마크 데이터셋과 2개의 비공개된 산업용 데이터셋을 사용하였다.
The Consolidated Receipt Dataset (CORD) Ticket Business Card (In-Service Data) Receipt (In-Service Data)
Document Visual Question Answering (DocVQA)
- 본 논문에서는 모델의 성능을 더 검증하기 위해 DocVQA를 수행하였다.
- 문서의 이미지와 질문 한 쌍이 주어지면 모델은 이미지 내 시각 및 텍스트 정보를 모두 참고하여 질문의 답변을 반환한다.
- 일관된 방법을 유지하기 위해, 질문을 시작 프롬프트로 세팅하고 decoder가 답변을 생성하도록 하였다. 데이터셋: DocVQA
3.2 Setups
3.3 Experimental Results
Document Classification
Document Information Extraction (IE)
Document Visual Question Answering (DocVQA)
3.4 Further Studies
On Pre-training Strategy
On Encoder Backbone
On Input Resolution
On Text Localization
On OCR System
On Low Resourced Situation
4. Related Work
4.1 Optical Character Recognition (OCR)
4.2 Visual Document Understanding (VDU)
5. Conclusions
- Donut은 기존의 VDU 기법들과 달리 OCR에 의존하지 않고 end-to-end 방식으로 학습되었다.
- 문서 이미지 합성 데이터를 생성하는 SynthDoG를 제안하였다.
- 이를 통해 Donut은 실제 문서 이미지 데이터셋의 규모와 여러 언어 확장을 용이하게 하였다.
- 학습 단계를 "어떻게 읽을 것인지"와 "어떻게 이해할 것인지"로 나누어 점진적으로 학습시켰다.
- 실험과 분석을 통해 공공 벤치마크와 내부 서비스 데이터셋에 대해 본 모델이 더 높은 성능과 더 나은 비용 효율성을 가지는 것을 확인하였다.

안녕하세요, AI 엔지니어입니다