1. 데이터와 정보
1.1. 데이터의 이해
데이터의 정의
데이터의 정의
데이터(Data)는 1646년 영국 문헌에 처음 등장한 것으로 라틴어인 dare(주다), Datum(주어진 것)이란 의미로 처음 사용. 과거에는 관념적이고 추상적인 개념이었다가 1940년대 이후 컴퓨터 시대가 도래하면서 기술적이고 사실적인 의미의 자료로 변화되고 있습니다
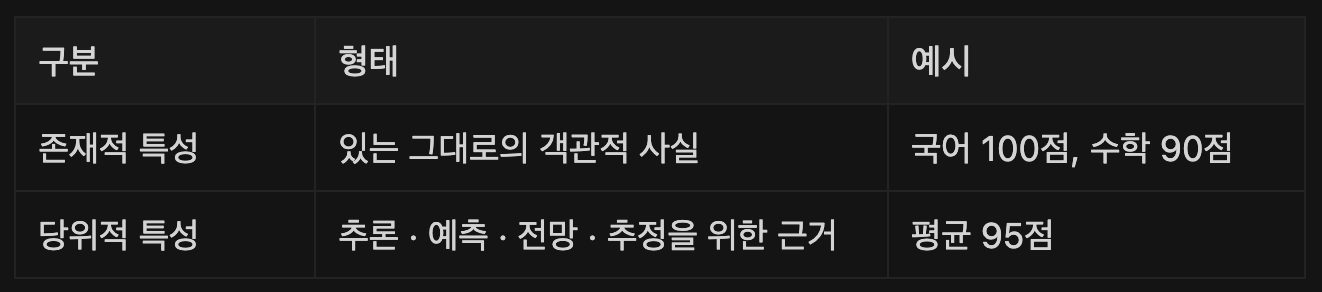
데이터의 특성
데이터는 객관적 사실이라는 존재적 특성을 가지며 추론 · 예측 · 전망 · 추정을 위한 근거로 기능하는 당위적 특성 또한 가지고 있습니다. 이러한 데이터는 축적되어 사용되며 객관적 사실로서의 개별 데이터는 중요하지 않습니다. 아래 표에서 예시를 함께 살펴볼게요.
데이터의 유형
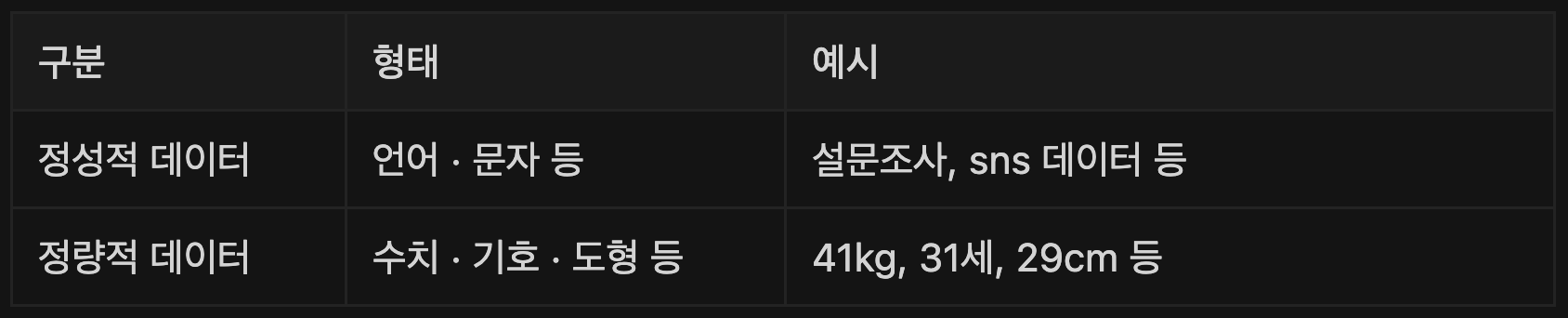
정성적 데이터와 정량적 데이터
정량적 데이터 : 수치, 도형, 기호를 예시로 들 수 있다.
정성적 데이터 : 주관적인 데이터로 분석이 어렵다
정량 데이터는 데이터의 양이 증가하더라도 데이터 관리 시스템 (ex.DBMS)에 저장 · 검색 · 분석하여 활용하기가 용이하나 설문조사 주관식 응답, 블로그 게시글 등과 같은 정성 데이터의 경우 형태가 명확하게 정해져 있지 않기 때문에 상대적으로 많은 비용과 기술적 투자가 필요합니다.
정형 데이터 · 비정형 데이터 · 반정형 데이터
정형 데이터 : 고정 틀을 가지고 있는 데이터. 수집/분석 용이
반정형 데이터 : 고정된 틀은 있지만 연산 불가. HTML, JSON, XML 파일 등.
비정형 데이터 : 영화 리뷰와 같은 사용자가 작성한 텍스트 파일 등.
암묵지와 형식지
암묵지
‘자전거 타기’와 같이 학습과 체험을 통해 개인에게 습득되어 있지만 겉으로 드러나지 않는 지식을 말한다.
-외부로 표출되지 않기 때문에 공유와 전달의 어려움이 있습니다.
형식지
교과서, 매뉴얼 등과 같이 형상화된 지식을 의미하며 유형의 대상이 있기 때문에 공유할 수 있는 지식을 말합니다.
- 문서처럼 형식화되어 있기 때문에 공유와 전달이 용이합니다.
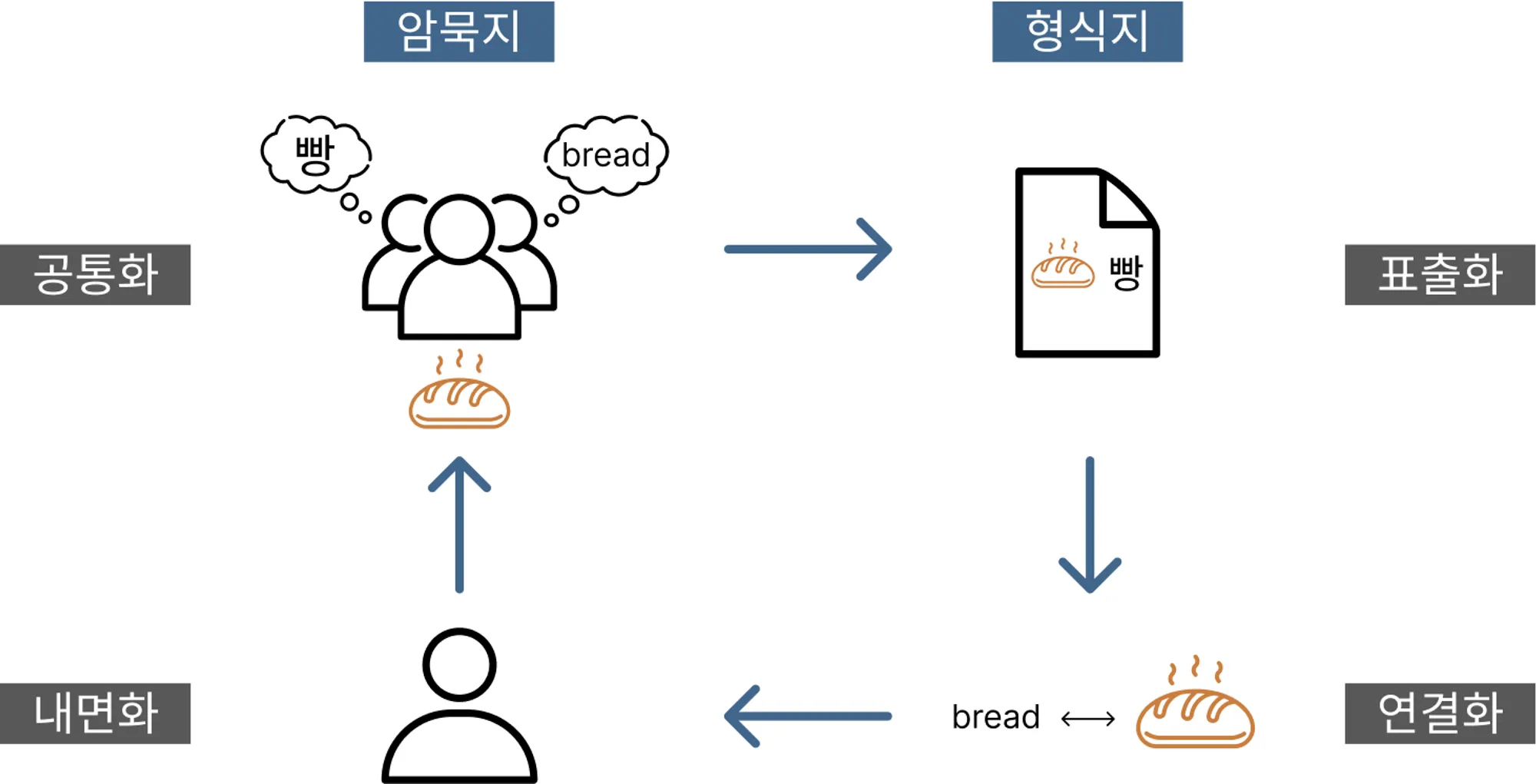
개인에게 내면화된 지식을 조직의 지식으로 공통화하기 위해서는 기호, 숫자 등의 형태로 표출화하고 이를 다시 개인의 지식으로 연결하여 그 바탕 위에서 새로운 경험을 부가하여 다시 내면화되는 과정을 거칩니다. 상호 순환작용을 통해 조식의 지식이 증대된다고 보기 때문에 데이터는 지식 형성의 중요한 기초를 이룹니다
데이터와 정보
DIKW 피라미드
Data : 가공되지 않은 있는 그대로의 사실
Information : 여러 데이터 간 상호 관계 속에서 얻은 의미 있는 자료
Knowledge : 여러 정보의 종합적인 결과로 개인의 결정에 기준이 되는 가치 있는 자료
Wisdom : 개인 깊숙한 곳에 내재되어 타인과 공유하기 어려운 자료. ex) 악기 연주가의 머슬메모리 등.
연습문제
1번
암묵지와 형식지의 상호작용과 관련 없는 것은?
1. 공통화
2. 추상화
3. 내면화
4. 표출화
정답
암묵지와 형식지의 상호작용 : 공통화, 연결화, 내면화, 표출화
2번
데이터는 그 형태에 따라 정성 데이터와 정량 데이터로 구분된다. 다음 중 정량 데이터에 속하는 것은?
1. 인터뷰
2. 가게 매출 증가
3. 습도
4. 관찰기록
정답
정량 데이터는 수치, 도형 등으로 기술된다 - 3
3번
다음 중 지식의 예시로 적절한 것은?
1. 대부분의 상품이 A 편의점보다 B 편의점이 더 저렴하게 팔 것이다
2. 상대적으로 저렴한 B 편의점에서 연필을 사야겠다
3. A 편의점은 연필이 1,500원 B 편의점은 1,000원에 판매한다
4. B 편의점의 연필이 더 저렴한다
정답
DIKW 피라미드에 대한 설명으로 바르게 짝지어진 것을 묻는 질문이며, ‘지식’은 상호 연결된 정보 패턴을 이해하여 이를 토대로 예측한 결과물을 의미한다
1.2. 데이터베이스
데이터베이스 정의
용어의 현역
데이터베이스(database) 용어의 첫 등장
- 1950년대 미국 군대의 군비 상황을 집중적/효율적으로 관리하기 위해 수집된 자료를 일컫는 ‘데이터(Data)’와 ‘기지(Base)’의 합성어로 처음 등장
1963년 데이터베이스 용어의 공식적인 첫 사용
- 1963년 6월 미국 SDC(system Development Corporation)가 개최한 심포지엄에서 첫 사용
- 데이터베이스 초기 개념 : 대량의 데이터를 축적하는 기지
- GE(General Blectronic)의 c. 바크만(Charles Bachman)은 최초로 현대적 의미의 데이터베이스 관리 시스템 IDs(Integrated Data Store)를 개발하였으며 이후 다양한 데이터 모델과 데이터베이스 관리 시스템이 개발되었음
데이터베이스의 다양한 정의

DB의 종류
데이터베이스 종류에는 계층형, 네트워크형, 관계형, NoSQL 등이 있다
관계형 데이터베이스(Relational Database)
- 데이터를 행과 열로 표현된 표형식으로 저장하며 데이터 간의 관계를 나타내는 테이블을 사용함
- 관계형 데이터베이스는 SQL(Structured Query Language)을 사용하여 데이터를 조작하고 검색
- Oracle, MySQL, MariaDB, SQLite, Postgresql 등
비관계형 데이터베이스(NoSQL)
- "Not Only SQL" 또는 "Non-SQL"의 약자로, 관계형 데이터베이스(Relational Database)가 아닌 다른 형태의 데이터베이스 관리 시스템을 나타내는 용어
- 관계형 데이터베이스와는 다른 데이터 모델과 기술을 사용하여 데이터를 저장, 검색 및 관리
- 비정형 데이터와 대용량의 데이터 분석 및 분산 처리에 용이
- MongoDB, ElasticSearch, Redis, Dynamo 등
데이터베이스 특징
데이터베이스의 일반적인 특징
- 변화하는 데이터 : 삽입, 수정, 삭제를 통해 항상 정확한 최신 정보를 유지
- 통합된 데이터 : 데이터의 중복이 발생하지 않음
- 공용 데이터 : 여러 사용자가 공동으로 이용 가능함
- 저장된 데이터 : 컴퓨터와 같은 전자기기 매체를 통해 접근 가능함
데이터베이스의 다양한 측면에서의 특징

정보의 축적 및 전달 측면(기계), 정보 이용 측면(사용), 정보 관리 측면(데이터 관리), 정보기술 발전의 측면, 경제-산업적 측면
데이터베이스 활용
기업내부 데이터베이스
1980년대 기업내부 데이터베이스
-
OLTP(Online Transaction Processing) : 정보시스템
- 데이터베이스의 데이터를 수시로 갱신하는 프로세싱
- 데이터 갱신 위주
ex. 주문이 들어올 경우 이를 처리하고(주문입력시스템), 재고를 업데이트(재고관리시스템)하는 데 사용
-
OLAP (Oaline Analytical Processing) : 분석 중심의 시스템
- 데이터 조회 위주 → 모아둔 데이터에 초점
ex. 복잡한 데이터를 분석하여 제품의 판매 추이, 구매 성향 파악 등을 프로세싱
- 데이터 조회 위주 → 모아둔 데이터에 초점
데이터베이스란 데이터를 체계적으로 저장한 데이터의 집합
DB는 중복된 데이터를 갖고 있지 않다는 통합된 데이터의 특징이 있다.
DBMS는 관계형 데이터베이스뿐 아니라 비정형 데이터베이스 관리 시스템을 포괄한 개념이다.
관계형 DB 관리 시스템 RDBMS 는 SQL을 필요로 하고
비정형 DB를 다룰 때 NoSQL 같은 경우에는 SQL이 아닌 REST API 같은 방식으로 소통
데이터베이스
기업 수준의 데이터베이스 활용 : EAI(Enterprise Application Integration)는 기업 응용 프로그램의 통합을 의미
사회기반 데이터베이스 : ITS(지능형 교통 시스템) , NEIS(교육 행정 정보 시스템) , GPS(범지구위치결정시스템)
3. 빅데이터의 이해, 가치와 영향
빅데이터 등장 배경
스마트폰의 등장 > 신규 메신저 서비스 이용 고객 증가
이미지, 영상, 음성 등 자료들 컴퓨터가 읽을 수 있도록 디지털화
대용량 데이터 다루는 분석기법, 분석도구 등장
<인공위성을 활용한 범지구위치결정시스템(GPS)은 빅데이터 등장 배경과 직접벅 영향은 적다.>
빅데이터로 인한 변화
| 변화 | 내용 |
|---|---|
| 표본 > 전수 | |
| 질 > 양 | |
| 사전 > 사후 | 빅데이터가 도래한 21세기 분석 목적에 맞게 사전처리 방식에서 가능한 많은 데이터를 분석대상으로 보는 사후처리로 변화 |
| 인과 > 상관 |
현대사회 빅데이터 기능
차세대로 넘어가기 위한 발판을 마련해준다. (석탄, 철)/ 현대사회의 에너지를제공해주는 원동력. (원유)
기존에 모르던 새로운 가치를 발견할 수 있도록 도와준다. (미생물 발견 렌즈)
공동 활용의 목적으로 구축된 유무형의 구조물 (플랫폼)
빅데이터 활용 기본 테크닉
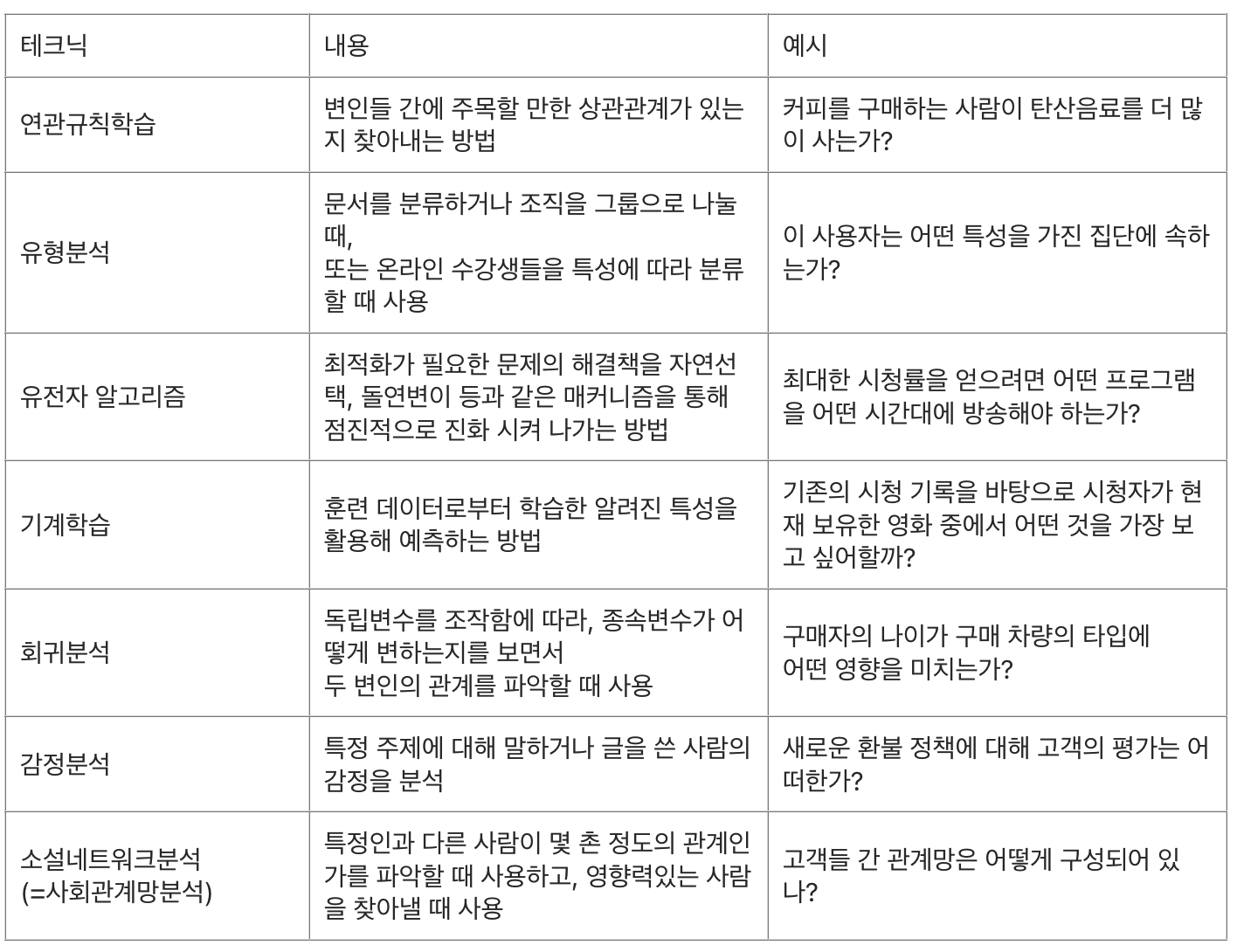
유형분석 - 기업의 파산/회생 여부를 분류
회귀분석 - 이용 시간 대비 온라인상 흩어진 개인정보양의 관계
연관분석 - A를 시청한 고객이 B시청할 가능성
빅데이터 위기 요인, 통제 방법
사생활 침해 : 구글은 사용자의 인터넷 기록 및 검색을 분석하여 인너넷 종료 이후 사용자의 행동을 87%의 정확도로 예측 / SNS 사용자의 게시글은 누구나 접근 가능, 수집 가능. > 악용
사생활 침해 통제 방법 : 동의에서 책임으로.
책임 원칙 훼손 : 예측 알고리즘의 희생양, 마이너리 리포트 , 신용도와 무관하게 대출 거부
통제 방법 : 결과 기반 책임
데이터 오용 : 일어난 일에 대한 데이터를 활용하기에 예측이 항상 맞을 순 없다.
통제 방법 : 알고리즘 접근 허용 ( 알고리즈미스트 필요 )
빅데이터 활용에 필요한 3요소
데이터, 기술, 인력
데이터 : 모든 것의 데이터와 < 사물인터넷
기술 : 진화하는 알고리즘, 인공지능
인력 : 데이터 사이언티스트, 알고리즈미스트
사물끼리 정보를 주고 받는 사물인터넷 시대를 빅데이터의 관점에서 바라볼 때 다음 중 사물인터넷의 의미로 가장 적절한 것은? > 데이터
5. 전략 인사이트
전략도출 가치기반 분석
일차원적 분석과 비교했을 때 전략도출 가치기반 분석은
사회 변화 및 고객의 니즈 변화를 빠르게 파악하고 새로운 기회를 포착할 수 있다.
데이터 사이언스
데이터 사이언스는 데이터 공학, 수학, 통계학, 컴퓨터공학 등 다양한 전문 지식을 종합한 학문으로 여러 데이터로부터 의미 있는 정보를 추출하고 나아가서 그 결과를 효과적으로 전달하는 것을 포함.
하둡
하둡 : 대룡량 데이터 분산 처리를 위해 개발된 자바 기반 프레임워크.
여러 개의 컴퓨터를 하나인 것 처럼 작업을 수행하기 때문에 우수한 처리 속도.
데이터를 key, vlaue 의 쌍으로 표현, 데이터를 키 값에 따라 나누는 맵 함수, 원하는 함수를 적용하고 결과 종합하는 리듀스 함수를 사용하여 처리한다.
2과목
1. 데이터 분석 기획 방향성
데이터 사이언티스트 요구 역량
빅데이터 분석 방법론
강력한 호기심
R의 ggplot2 또는 파이썬의 Matplotlib와 seaborn
가트너가 제시한 데이터 사이언티스트 역량
데이터에 대한 이해, 분석론에 대한 지식, 비즈니스요소의 초점 외
커뮤니케이션, 협력, 디러십, 창의력 등
분석 주제 분류
분석 주제 유형
분석 대상 (what)
분석 방법 (how)
|||||
|-|-|-|-|
|||분석 대상|분석 대상|
|||안다|모른다|
|분석 방법|안다|최적화|통찰|
|분석 방법|모른다|솔루션|발견|
|||↓ 하향식 접근|↑ 상향식 접근|
데이터의 분석 방법과 다양한 분석 도구(구조)의 활용은 충분히 이해하고 있으나, 조직 내 분석 대상이 무엇인지 인지하지 못하는 경우 통찰
분석은 분석 대상(What) 및 분석 방법(How)에 따라서 4가지로 나눌 수 있다. 분석 대상이 명확하게 무엇인지
모르는 경우에는 기존 분석 방식을 활용하여 ( 가 )를 도출해냄으로써 문제의 도출 및 해결에 기여하거나,
( 나) 접근법으로 분석 대상 자체를 새롭게 도출할 수 있다.
목표 시점별 분석 기획 방안
||과제중심 방식
(당면한 과제 해결)|마스터 플랜방식
(지속적인 분석 내재화)|
|1차 목표|Speed & Test|Accuracy & Deploy|
|과제의 유형|Quick & Win|Long Term View|
|접근방식|문제해결
Problem Solving|문제정의
Problem |
▶ 두 방식을 융합하여 사용하는 것이 바람직함
과제 중심적 접근방식
Quick & Win
Problem Solving
Speed & Test
마스터 플랜방식
Accuracy & Deploy
Long Term View
문제정의
2. 분석 방법론
서로 피드백을 주고받는 단계
데이터 준비와 데이터 분석 단계는 서로 피드백을 주고받을 수 있다.
빅데이터 분석 방법론에서 예상되는 위험으로부터 대응하기 위한 방법
회피, 수용, 전이, 완화
분석 기획 시 고려사항 (데, 유, 장)
가용 데이터, 적절한 유즈 케이스, 장애요소들에 대한 사전계획 및 관리
3. 분석 과제 발굴
하향식 접근 방식
문제가 주어지고 이에 대한 해법을 찾기 위해 각 과정이 체계적으로 단계하되어 수행하는 분석과제 발굴 방식
4. 분석 프로젝트관리 방안
5. 마스터 플랜 수집
6. 분석 거버넌스 체계
데이터 거버넌스 3가지 구성요소
원칙, 조직, 프로세스
데이터 거버넌스의 체계 순서
데이터 표준화 -> 데이터 관리 체계 -> 데이터 저장소 관리 -> 표준화 활동
데이터 표준화는 데이터 표준용어 설명, 명명규칙, 메타데이터 구축, 데이터 사전 구축 등의 업무로 구성
데이터 관리 체계는 데이터 정합성 및 활용의 효율성을 위해 표준데이터를 포함한 메타데이터와 데이터 사전의 관리원칙을 수립
데이터 저장소 관리는 메타데이터 및 표준데이터를 관리하기 위한 전사차원의 저장소를 구성
표준화 활동은 데이터 거버넌스 체계를 구축한 후 표준준수 여부를 주기적으로 모니터링 한다.
데이터 분석 조직구조의 유형
데이터 분석 조직구조의 유형 세가지
집중구조 : 전사 분석 업무를 별도의 분석 전담 조직에서 담당. 전사차원에서 수선순위 결정할 수 있으나 현업 업무부서와 이중화, 이원화의 가능성이 있다는 단점.
기능구조 : 해당 업무 부서에서 분석 수행, 전사적 차원x
분산구조 : 분석조직 인력을 현업부서로 직접 배치, 전사적 차원 O, 업무과다 이원화 가능성.
데이터 분석 수준 진단
분석 준비도 (Readiness)
문데인, 인기업
분석 업부, 분석 인력(조직) , 분석 기법, 분석 데이터, 분석 문화, 분석 인프라
| 1.분석 업무 파악 | 2. 인력 및 조직 | 3 분석기법 |
|---|---|---|
| 1.발생한 사실 분석 2.예측 분석 3.시뮬레이션 분석 4.최적화 분석 5.분석 업무 정기적 개선 | 1.분석전문가 직무 존재 2.전문가 교육훈련 프로그램 3. 관리자 기본분석능력 4. 전사총괄조직 5. 경영진 분석 업무 이해 | 1. 업무별 적합한 분석기법 2. 분석 업무 도입 방법론 3. 분석기법 라이브러리 4. 분석기법 효과성 평가 5. 분석기법 정기적 개선 |
| 4. 분석 데이터 | 5. 분석 문화 | 6. IT 인프라 |
|---|---|---|
| 1.분석업무를 위한 데이터 충분성/신뢰성/적시성 2.비구조적 데이터 관리 3.외부데이터 활용 체계 4.기준데이터 관리(MDM) | 1.사실에 근거한 의사결정 2.관리자의 데이터 중시 정도 3.회의 등에서 데이터 활용 4.직관보다 데이터 기반 의사결정 5.데이터 공유 및 협업 문화 | 1. 운영시스템 데이터 통합 2.EAI,ETL등 데이터 유통체계 3.분석 전용 서버 및 스토리지 4.분석 환경 (빅데이터/통계/비쥬얼) |
분석 성숙도
기업 분석 수준 확보방면 성숙도
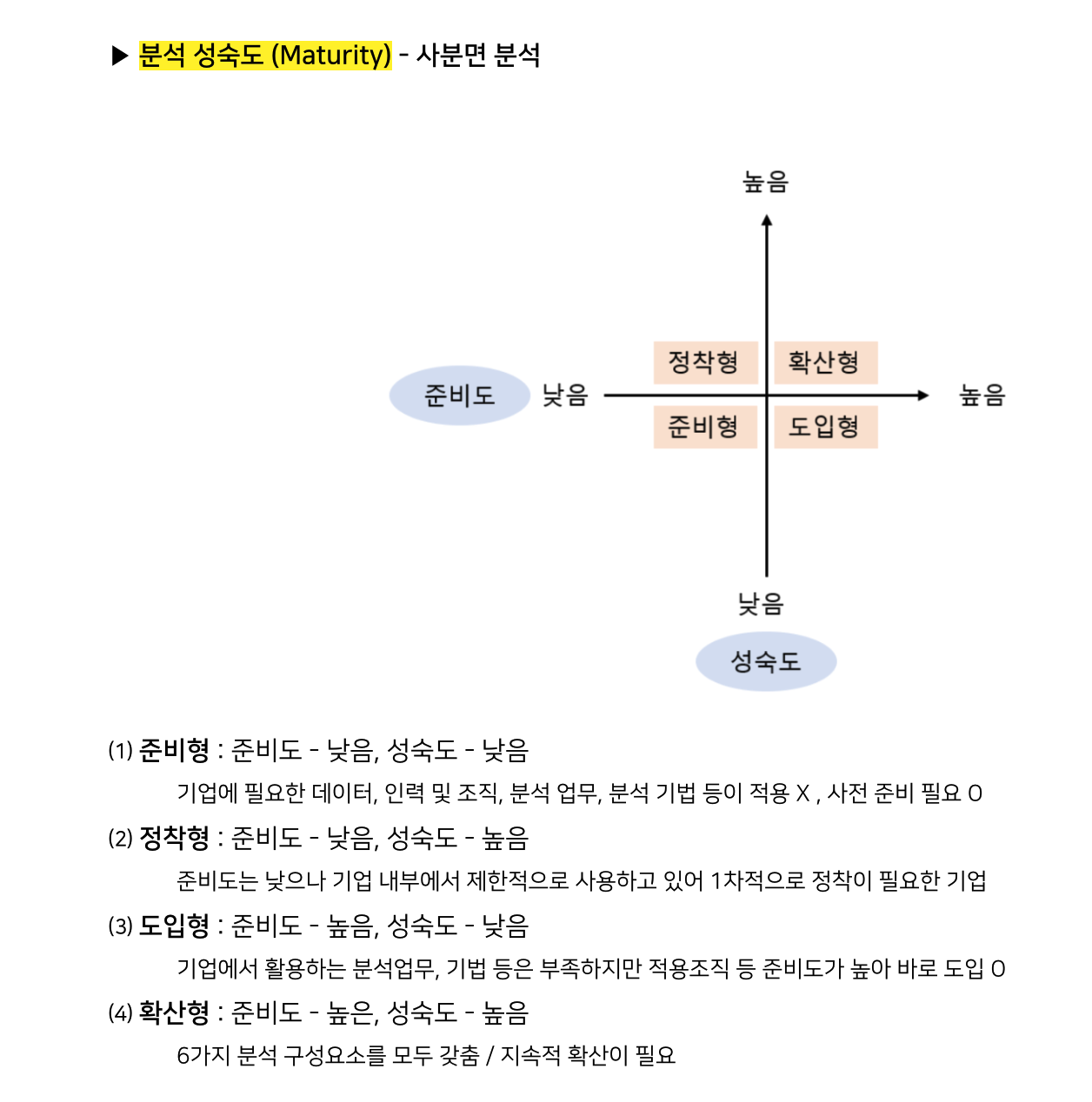
데이터, 인력, 조직, 분석업무 등이 적용되지 않아 성숙된 분석 수준을 확보하기 위한 여러 방면에서 사전준비가 필요한 기업의 유형은 > 준비형 기업
준비형 기업 : 데이터, 인력, 조직, 분석업무, 분석 기법 등이 적용되지 않은 낮은 수준의 성숙도와 낮은 수준의 준비도를 보유하고 있는 기업.
분석 마스터 플랜
탐색한 문제에 대한 해결 방안들을 총체적인 관점에서 적용 우선순위를 설정하기 위함.
우선순위 결정을 위해서는 전략적 중요도, ROI관점 비즈니스 성과, 실행 용이성 고려
적용범위 & 방식을 고려하기 위해 업무 내재와 적용 수준, 분석 데이터 적용 수준, 기술 적용 수준 고려
분석과제 도출, 우선순위 평가, 이행계획 수립 순서로 수행된다.
분석기획 3가지 주요 고려 사항
- 가용 데이터의 존재 여부
- 유스케이스 탐색
- 장애요소에 대한 사전 계획 수립이 있다.
하향식 접근법 단계
문제 탐색 : 분석 과제 발굴을 위해 무엇이 문제인지를 파악하고자 모델 기반 탐색과 외부 사례 기반 문제 탐색을 실시
문제 정의 : 탐색된 문제들에 대해 비즈니스적 문제를 > 데이터 문제로 변환하는 단계
해결 방안 탐색 :
타당성 검토 :
표본 조사와 추정
- 표본집단의 평균의 분산은 모집단의 분산보다 작다.
추정이란? 실제 모집단에 대한 모수를 찾기 위한 전수조사가 불가능하기 떄문에 표본조사를 통해 모집단의 모수를 예측하고자 하는 것.
점 추정이란? 모집단의 모수가 특정한 값일 것으로 생각하는 것. ( 일반적으로 모집단의 평균의 추정치는 표본집단의 평균)
구간추정이란? 모집단의 모수가 속할 것으로 예상되는 구간을 추정하는 것.
시계열 모형
시계열 모형 중 차분이 2번 요구되며 p=3 인 자기회귀 모형, q=2인 이동평균모형을 따를 때 사용 가능한 모형?
ARIMA(3,2,2) / AR(3) / MA(2) / ARMA(3,2) 중 선택해서 활용 가능.
분해시계열 요소
추세요인, 계절요인, 순환요인, 불규칙요인 이 있다.
정형 데이터 마이닝
데이터 마이닝은 크게 지도학습과 비지도학습으로 분류 가능
데이터 마이닝은 대용량 데이터 속에서 규칙 및 패턴을 발견하는 것이 목적
데이터 분할 목적은 과적합 방지
홀드 아웃은 데이터가 많을 경우 훈련용, 검정용, 평가용으로 나누고, 데이터가 적을 경우 훈련용과 평가용으로 분할하는 것을 의미.
홀드아웃의 각 데이터 셋이 전체 데이터를 대표하지 못할 가능성이 크다.
인공신경망
Softmax는 인공신경망에서 활성함수로 사용되는 함수들 중 표준화 지수 함수라고 불리고, 목표 변수가 다범주인 경우 활용되는 활성화 함수다
R
x<- seq(0,10,2) y<- req(c (1,3), each =3) z<- paste('ba','nana') w<- mean(x,na.rm=T)
x : 0 2 4 6 8 10
y : 1 1 1 3 3 3
z : 'ba nana' ( paste 함수의 파라미터 중 구분자를 의미하는 sep 기본값이 ' ' (1칸의 공백)이다.
w : 5
R 명령문 활용 데이터 마이닝 기법
princomp - 주성분분석
hclust - 계층적 군집분석
kmeans - k-평균
neuralnet - 인공신경망
ctree - 의사결정 나무
R 특징 오픈소스로 누구나 무료로 이용 가능 S 언어로 작성되어 있다. 확발한 커뮤니티와 다양한 논문 등 자료가 많아서 알고리즘 구현이 쉽다 모듈화로 설치 용량이 비교적 작다.
자료 분포 척도
첨도 : 자료의 뾰족한 정도를 나타냄 값이 클수록 뾰족
왜도 : 어느 쪽으로 긴 꼬리를 갖는지 나타냄. 음수면 왼쪽으로 긴 꼬리.
분산 : 자료의 모든 데이터에 대한 평균으롭터 흩어져있는 정도
중앙값 : 자료의 모든 데이터를 순서대로 나열했을 때 가운데 위치한 값
k-평균 분석
k-평균 군집의 초깃값 SEED의 개수 K 값을 결정하기는 쉽지 않다.
이상적인 k 값 결정을 위해 제곱합 그래프를 활용해 그래프가 수평이 되기 전 바로 전 단계를 값K로 결정.
C4.5 알고리즘
의사결정 나무를 구축을 위한 알고리즘. 불순도의 측도로 엔트로피 지수를 사용.
각 마디에서 가지 분리가 가능하다.
APRIORI 알고리즘은 연관분석을 위한 알고리즘.
계층적 군집분석
계층적 군집분석 수행하기 위한 방법들 여러가지 중.
와드 연결법 : 자료들이 군집화될 때 생성된 군집과 군집 밖의 자료의 거리를 계산할 때 군집에 속한 자료의 편차제곱합이 최소가 되는 위치와의 거리를 사용하는 방법
연관분석 특징
품목 수 증가는 계싼량의 기하급수적인 증가를 초래하므로 최소 지지도를 선정하여 최소 지지도 이상의 품목에 대해서만 분석을 수행
품목의 세분화의 어려움이 있다.
연관분에 시간의 개념을 추가하여 순차패턴분석을 수행할 수 있다.
연관분석의 결과를 확인하기 위해서 inspect를 사용
모형 기반 군집분석의 일종
혼합 분포 군집은 기댓값 최대화(EM) 알고리즘에 의해 수행된다.
하나의 확률분포가 여러 개의 확률분포의 가중합으로 표현되었을 때 이 확률분포를 구성하는 각 확률분포의 모수를 찾기 위한 방법으로 활용되는 알고리즘.
통계학
기댓값 활용해 분산을 구하는 식은
Var(X) = E(X2)-E(X)2
분산은 확률분포의 제곱의 평균에서 평균의 제곱값을 뺀 값.
summary(result) 해석
Residuals : Max = 잔차의 최댓값
Coefficients : Signif. codes : '*' 0.05 : 귀무 가설 유의수준 5% 내에서 기각 할 수 있음
회귀식 : (Intercept) + A (Estimate STd.)+ B (Estimate STd.) + C * (Estimate STd.) ...
결정계수는 많은 독립변수들에 의하여 의미 없는 분수에 의해서도 설명령이 올라가기 떄문에 수정된 결정계수를 보는 것이 적절하다.
분산분석의 사후 검정 방법
Tukey 검정, Bonferroni 검정, Fisher's LCD,
자료 분포가 정규분포인지 검정 방법
Shapiro 검정
신뢰도
판매 데이터를 보고 주스를 구매한느 고객이 사과를 구매할 확률을 바르게 계산한 것은?
| 품목 | 판매빈도 |
|---|---|
| {사과} | 30 |
| {주스} | 20 |
| {빵} | 30 |
| {사과,주스} | 30 |
| {주스,빵} | 40 |
| {사과,빵} | 40 |
| {사과,주스,빵} | 20 |
사과를 구매고객이 주스를 구매하는 확률은 연관규칙 '주스 -> 사과'의 신뢰도를 묻는 문제.
품목 주스의 구매율은 {주스} + {사과,주스} + {주스+빵} + {사과,주스,빵} / (전체 거래 수) = (20 +20 + 40 + 20 ) /200 = 0.5 다.
품목 사과와 주스의 지지도는 {사과,주스} + {사과, 주스,빵} / ( 전체거래 수) = (20 + 20) / 200 = 0.2 다. 따라서 연관규칙 '주스 -> 사과' 의 신뢰도는 (품목 사과와 주스의 지지도) / (품목 주스의 구매비율)인 0.2/0.5 = 2/5 이다.
데이터 마이닝 기법
비지도 학습 - 자지조직화지도, 연관분석, 혼합 분포 군집
지도 학습 - 의사결정나무(분류분석)
의사결정나무
정지 규칙 : 의사결정나무 모형 구축에 있어서 과적합 문제를 방지하기 위해 트리가 일정 깊이에 도달하거나 모든 자료들이 하나의 그룹에 속한다는 등 특정 조건을 만족할 경우 더 이상의 마디 분리를 수행하지 않고 모형 구축을 종료하는 규칙
CART 알고리즘
지니지수 : CART 알고리즘에서 의사결정나무를 구축하기 위한 불순도 지표로 활용되며, 모든 자료가 같아 동질적인 경우 0의 값을 가지고 이질적일수록 그 값이 커지는 특징을 갖고 있는 것은 무엇인가?
뉴런 모방 퍼셉트론 그림 계산.
활성 함수가 Relu 함수 일 경우.
ReLU는 입력값이 음수일 경우 0을 출력
입력값이 양수인 경우, ReLU 함수는 그 값을 그대로 출력
Relu(x) = max(0,x) 이므로 Relu(-0.2) = 0
민감도, 특이도
민감도는 실제 True 중 예측에 성공한 True의 값.
특이도는 실제 False 중 예측에 성공한 False의 값
| 예측 TRUE | 집단 FALSE | |
|---|---|---|
| 실제 TRUE | 75 | 25 |
| 집단 FALSE | 10 | 90 |
민감도는 실제 TRUE 중 예측에 성공한 TRUE의 값.
75/(75+25) = 0.75
특이도는 실제 FALSE 중 예측에 성공한 FALSE의 값.
90/(10+90) = 0.9
회귀분석
회귀분석에서 독립변수 사이의 선형관계가 존재한다면 종속변수의 추정이 어려운 문제가 발생한다.
이 문제를 진단하기 위해서 사용되는 지표의 수식은 1/(1-R2)으로,
4보다 크면 문제가 존재하며 10보다 큰 경우 이 문제가 심각하다고 판단한다. 이 지표는?
VIF : Variance Inflation Factors 분산 팽창 요인 / 분산팽창계수는 회귀분석에서 다중공선성(독립변수 간의 상호선형 관계) 존재 여부를 판단하기 위해 활용된다.
다이어그램
나무를 나타내는 다이어그램으로 계층적 군집분석의 수행 결과를 나타내기 위해 사용됨.
계층적 군집분석의 수행의 시작과 끝을 높이(height)변수를 통해 그래프로 나타내어 특정 height값에 따라 변화하는 군집을 쉽게 파악할 수 있고
데이터 간의 거리를 쉽게 파악할 수 있는 그래프는 무엇인가?
덴드로그램 : 군집분석의 결과는 덴드로그램을 통해 나타내며, height값에 따라 군집의 변화 파악이 쉽다.
