11 SQL의 활용 2
11.1. 그룹 함수
데이터 분석 개요
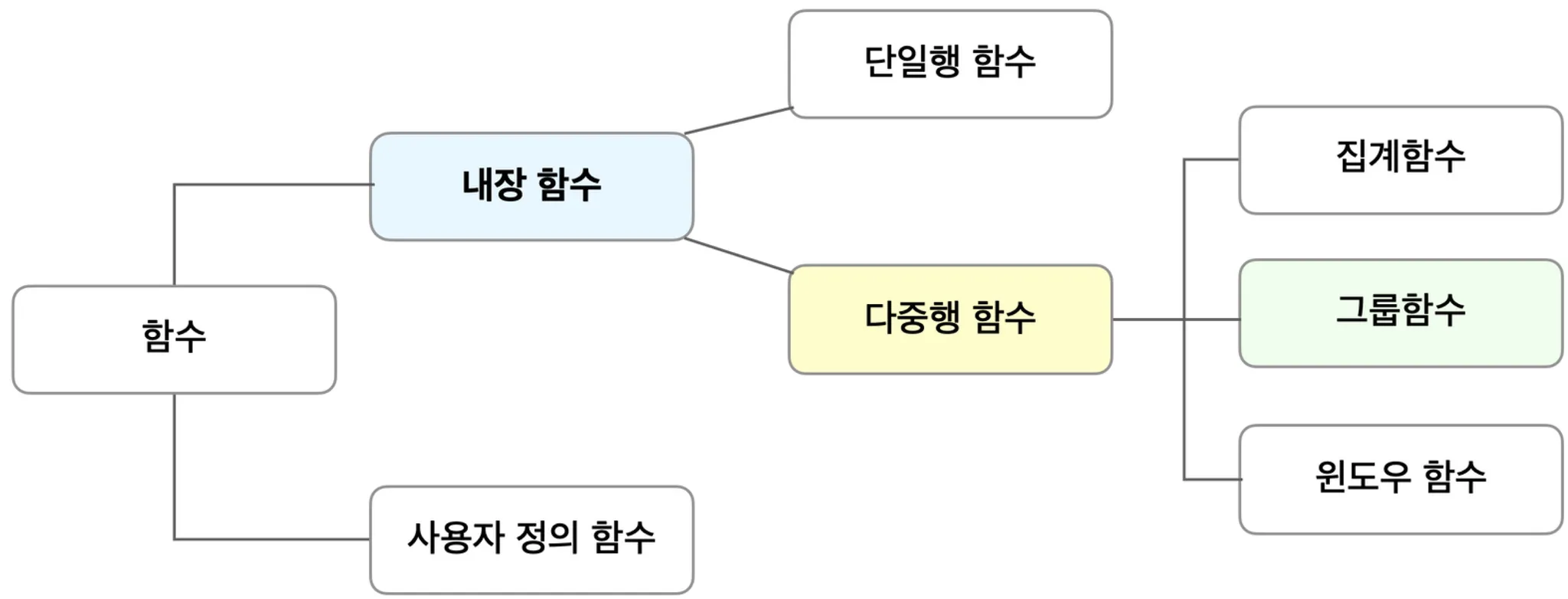
ANSI/ISO SQL 표준에서는 데이터 분석을 위해서 3가지 함수를 정의하고 있습니다. 첫 번째로는 집계(AGGREGATE)함수, 두 번째는 그룹(GROUP)함수, 세 번째는 윈도우(WINDOW)함수입니다. 이들은 모두 내장 함수이며 다중행 함수에 속합니다.
AGGREGATE FUNCTION
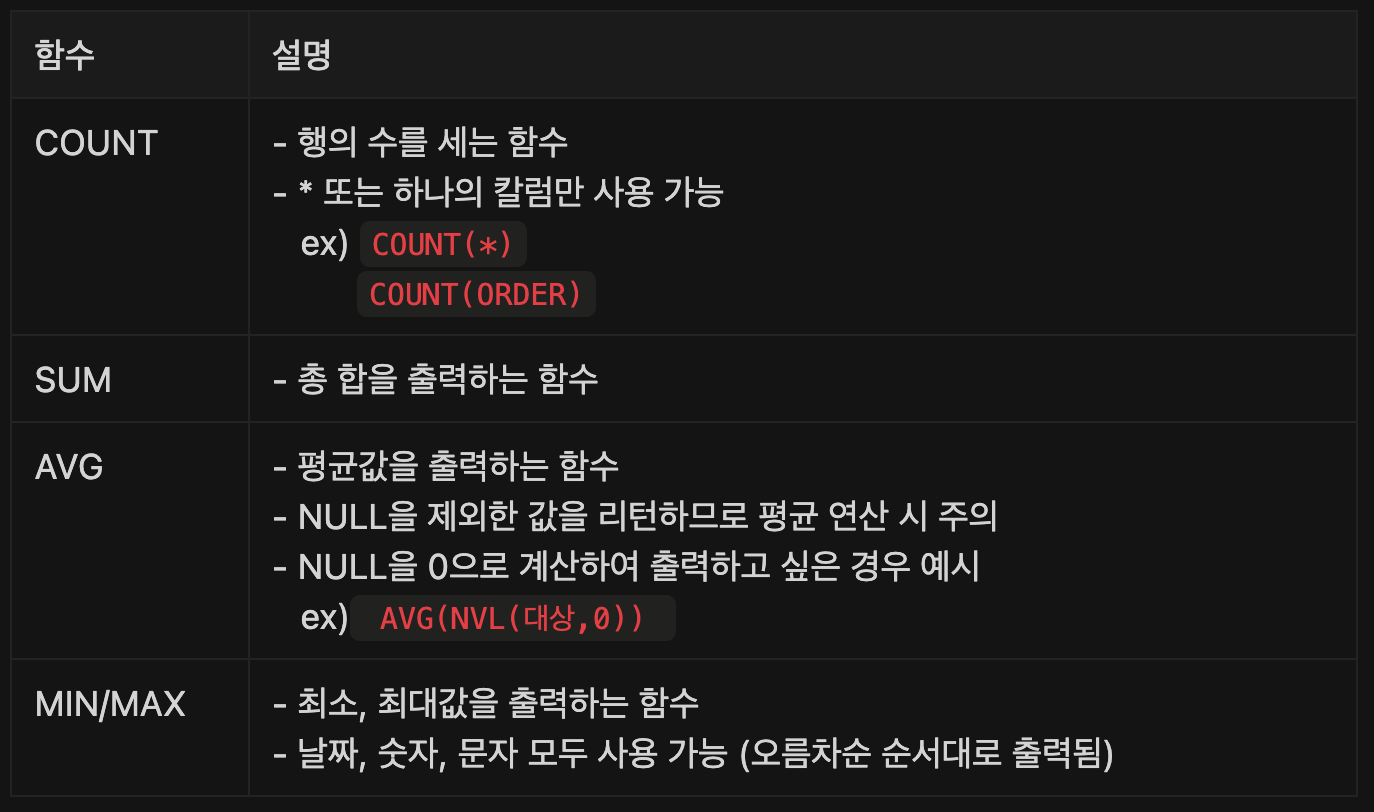
먼저, 집계 함수입니다. 집계함수는 GROUP 함수의 한 부분으로 분류할 수 있습니다. COUNT, SUM, AVG, MAX, MIN 이 모두 집계 함수이며 그 외에도 다른 다양한 집계 함수가 있습니다
WINDOW FUNCTION
분석 함수나 순위 함수로도 알려져 있는 윈도우 함수는 데이터웨어하우스에서 발전한 기능으로, 행과 행간의 관계를 나타내기 위해 사용합니다. 다음 장에서 자세하게 다루도록 하겠습니다.
GROUP FUNCTION
그룹함수는 데이터에 대한 결산 개념의 연산을 할 때 주로 사용되는 함수입니다. 결산의 대표적이라 할 수 있는 판매 시스템의 경우 소계, 합계 등 여러 단계의 보고서를 만들 때 UNION, UNION ALL 로 묶은 후 하나의 테이블을 여러 번 읽어 재정렬하는 복잡한 단계를 거쳐야 했습니다. 하지만 그룹 함수인 GROUPING 함수와 CASE 함수를 이용하면 동일한 결과를 훨씬 더 쉽게 추출할 수 있습니다.
그룹함수는 집계 함수를 제외하고 ROLLUP 함수, GROUP BY 항목들 간 다양한 소계를 계산할 수 있는 CUBE 함수, 특정 항목에 대한 소계를 계산하는 GROUPING SETS 함수가 있습니다. 이번 레슨에서는 그룹 함수에 대해서 조금 더 자세하게 알아보도록 하겠습니다.
그룹함수의 종류
ROLLUP, CUBE, GROUPING SETS

ROLLUP 함수
기본형태
ROLLUP 함수는 칼럼으로 그룹을 만든 후 각 칼럼의 중간 합계를 만들기 위해 사용하는 함수입니다. 그룹화된 칼럼의 개수를 N이라고 했을 때 ROLLUP 함수의 결과는 N + 1개의 합계가 생성됩니다. 여기서 +1 은 그룹화된 칼럼들의 전체 합계를 의미합니다. ROLLUP의 중요한 특징 중 하나는 함수의 인수는 계층 구조를 가진다는 점입니다. 인수의 순서가 바뀌게 되면 수행 결과도 바뀌게 되므로 원하는 결과를 위해서는 인수의 순서에도 주의를 기울여야 합니다.
- 기본구조
ROLLUP(A,B): A별, (A,B)별, 전체 그룹 연산 결과 출력 → 나열 대상의 순서가 중요함
- 기본 예시
SELECT
DNAME,
JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM EMP,
DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB);결과 1
- L1 - GROUP BY 수행 시 생성되는 표준 집계 (9건)
- L2 - DNAME 별 모든 JOB의 SUBTOTAL (3건)
- L3 - GRAND TOTAL (마지막 행, 1건)
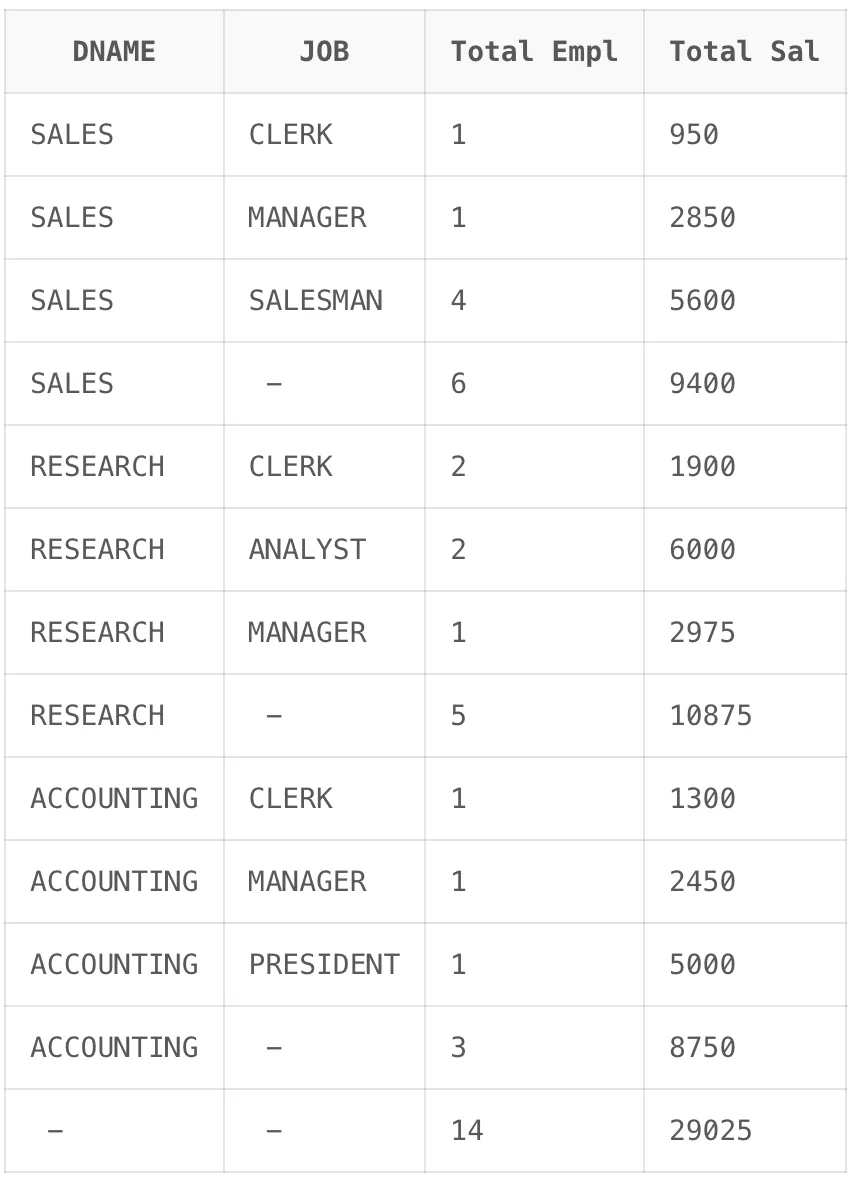
DNAME 과 JOB이 그룹화된 칼럼이며 DNAME 별 그룹화된 JOB의 중간 합을 집계함수 COUNT와 SUM을 통해서 나타낼 수 있습니다.
실습 데이터
CREATE TABLE PARTICIPANT (
partic_id NUMBER,
nation_id NUMBER,
main_sport_id NUMBER,
first_name VARCHAR2(30),
last_name VARCHAR2(30),
gender VARCHAR2(1),
height NUMBER,
weight NUMBER
);
INSERT INTO PARTICIPANT VALUES (1, 1, 101, 'John', 'Doe', 'M', 180, 75);
INSERT INTO PARTICIPANT VALUES (2, 2, 102, 'Jane', 'Smith', 'F', 165, 55);
INSERT INTO PARTICIPANT VALUES (3, 3, 103, 'Michael', 'Johnson', 'M', 175, 70);
INSERT INTO PARTICIPANT VALUES (4, 4, 104, 'Emily', 'Davis', 'F', 160, 50);
INSERT INTO PARTICIPANT VALUES (5, 5, 105, 'Chris', 'Brown', 'M', 190, 80);
INSERT INTO PARTICIPANT VALUES (6, 1, 101, 'Sarah', 'Wilson', 'F', 170, 60);
INSERT INTO PARTICIPANT VALUES (7, 2, 102, 'David', 'Lee', 'M', 175, 70);
INSERT INTO PARTICIPANT VALUES (8, 1, 102, 'Laura', 'Johnson', 'F', 160, 55);CREATE TABLE NATION (
nation_id NUMBER,
country_name VARCHAR2(30),
population NUMBER
);
INSERT INTO NATION VALUES (1, 'United States', 331002651);
INSERT INTO NATION VALUES (2, 'India', 1380004385);
INSERT INTO NATION VALUES (3, 'China', 1444216107);
INSERT INTO NATION VALUES (4, 'Brazil', 212559417);
INSERT INTO NATION VALUES (5, 'United Kingdom', 67886011);
INSERT INTO NATION VALUES (6, 'Canada', 37742154);
INSERT INTO NATION VALUES (7, 'Australia', 25788221);CREATE TABLE SPORT (
sport_id NUMBER PRIMARY KEY,
sport_name VARCHAR2(20),
max_weight NUMBER,
min_weight NUMBER
);
INSERT INTO SPORT VALUES (101, 'Football', 100, 60);
INSERT INTO SPORT VALUES (102, 'Basketball', 120, 50);
INSERT INTO SPORT VALUES (103, 'Tennis', 90, 50);
INSERT INTO SPORT VALUES (104, 'Swimming', 85, 45);
INSERT INTO SPORT VALUES (105, 'Gymnastics', 80, 40);실습 1
위 ‘기본 예시 1’의 쿼리를 ROLLUP이 아닌 UNION ALL로 대체하여 표현해 보세요.
-- DNAME과 JOB으로 그룹화한 집계
SELECT
DNAME,
JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM EMP,
DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME, JOB
UNION ALL
-- DNAME으로만 그룹화한 집계
SELECT
DNAME,
NULL AS JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM EMP,
DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME
UNION ALL
-- 전체 집계
SELECT
NULL AS DNAME,
NULL AS JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM EMP,
DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO;실습2
GROUP BY로 sport_name와 nation_id 칼럼 순서로 ROLLUP 하여 nation_id, sport_name, 국가별 총 참가자 수, 평균 몸무게를 출력해 보세요. 평균 몸무게는 소수점 둘째 자리까지 반올림하여 출력해 주세요.
SELECT p.nation_id,
s.sport_name,
COUNT(*) "total",
ROUND(AVG(weight), 2)
FROM participant p, sport s
WHERE p.main_sport_id = s.sport_id
GROUP BY ROLLUP (s.sport_name, p.nation_id);위의 GROUP BY ROLLUP 에서 칼럼의 순서를 바꿔서 결과를 확인해보세요
SELECT p.nation_id,
s.sport_name,
COUNT(*) "total",
ROUND(AVG(weight), 2)
FROM participant p, sport s
WHERE p.main_sport_id = s.sport_id
GROUP BY ROLLUP (p.nation_id, s.sport_name);ROLLUP의 경우 계층 간 집계에 대해서는 LEVEL 별 순서(L1→L2→L3)를 정렬하지만, 계층 내 GROUP BY 수행 시 생성되는 표준 집계에는 별도의 정렬을 지원하지 않습니다. 이는 ROLLUP과 CUBE 함수 모두 마찬가지이기 때문에 L1, L2, L3 계층 내 정렬을 위해서는 별도의 ORDER BY 절을 사용해야 합니다. 아래 예시를 통해 확인해 봅시다.
기본예시 2
SELECT
DNAME,
JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM EMP,
DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB)
ORDER BY DNAME, JOB;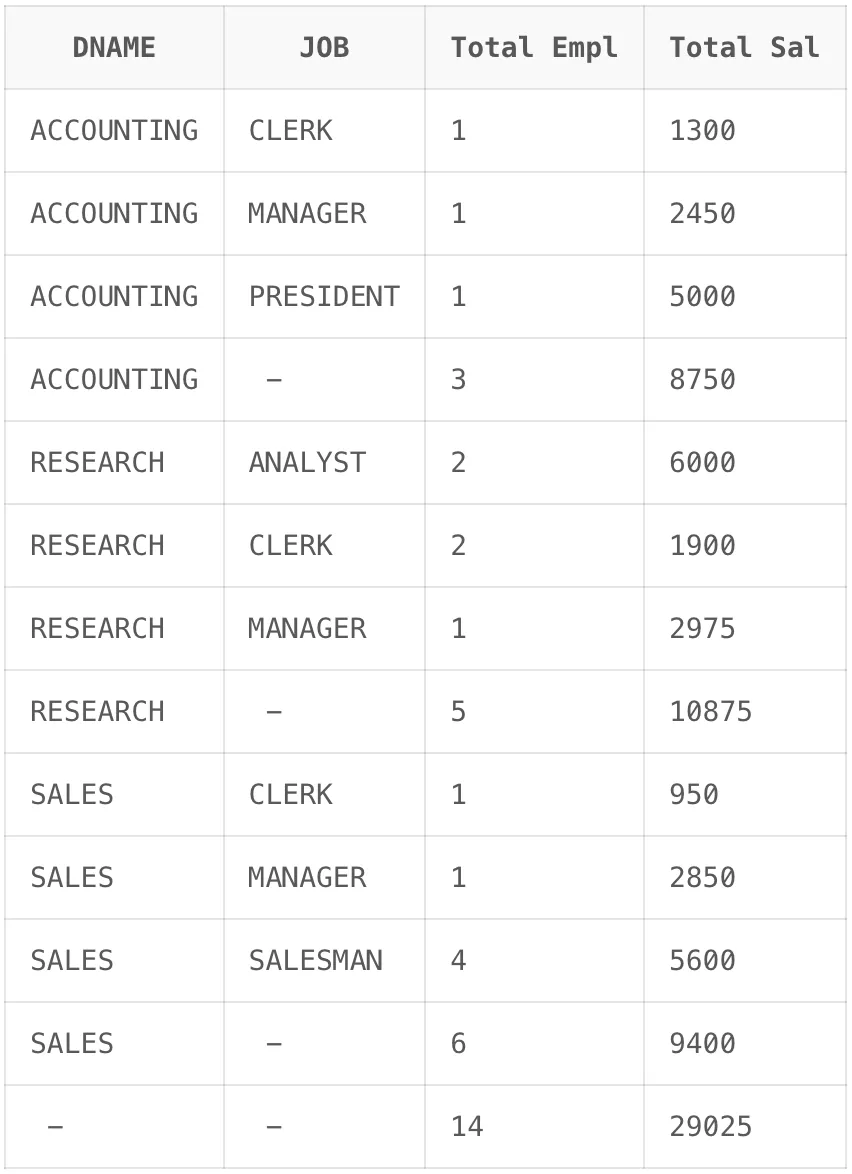
DNAME을 기준으로 1차 정렬을 하고, 이후 정렬된 값에서 나머지 요소는 JOB을 기준으로 다시 한번 정렬된 것을 확인할 수 있습니다.
GROUPING 함수
GROUPING 함수는 ROLLUP 이나 CUBE에 의해서 그룹화 된 칼럼의 소계가 계산된 결과를 1로 표시하고 그 외의 결과는 0으로 표시해 주는 함수입니다. 즉, ROLLUP 함수에 기재한 칼럼을 GROUPING 함수의 인자로 출력하면 합계를 표현하는 행에 대해서는 1이 출력됩니다. 소계와 합계로 집계되어 출력된 행을 구분할 때 사용합니다. 예시를 통해 어떻게 활용할 수 있는지 살펴봅시다.
기본 예시
SELECT DNAME, GROUPING(DNAME), JOB, GROUPING(JOB), COUNT(*) "Total Empl", SUM(SAL) "Total Sal" FROM EMP, DEPT WHERE DEPT.DEPTNO = EMP.DEPTNO GROUP BY ROLLUP (DNAME, JOB) ORDER BY DNAME, JOB;
ACCOUNTING 그룹은 8,750 RESEARCH 그룹은 10,875 SALES 그룹은 9,400 그리고 모든 그룹에 대해서는 29,025의 그룹화 된 결괏값을 확인할 수 있습니다. 또한, GROUPING 필드에서 출력된 합계를 표현하는 행은 1 그렇지 않으면 0이 출력된 것을 확인할 수 있습니다.
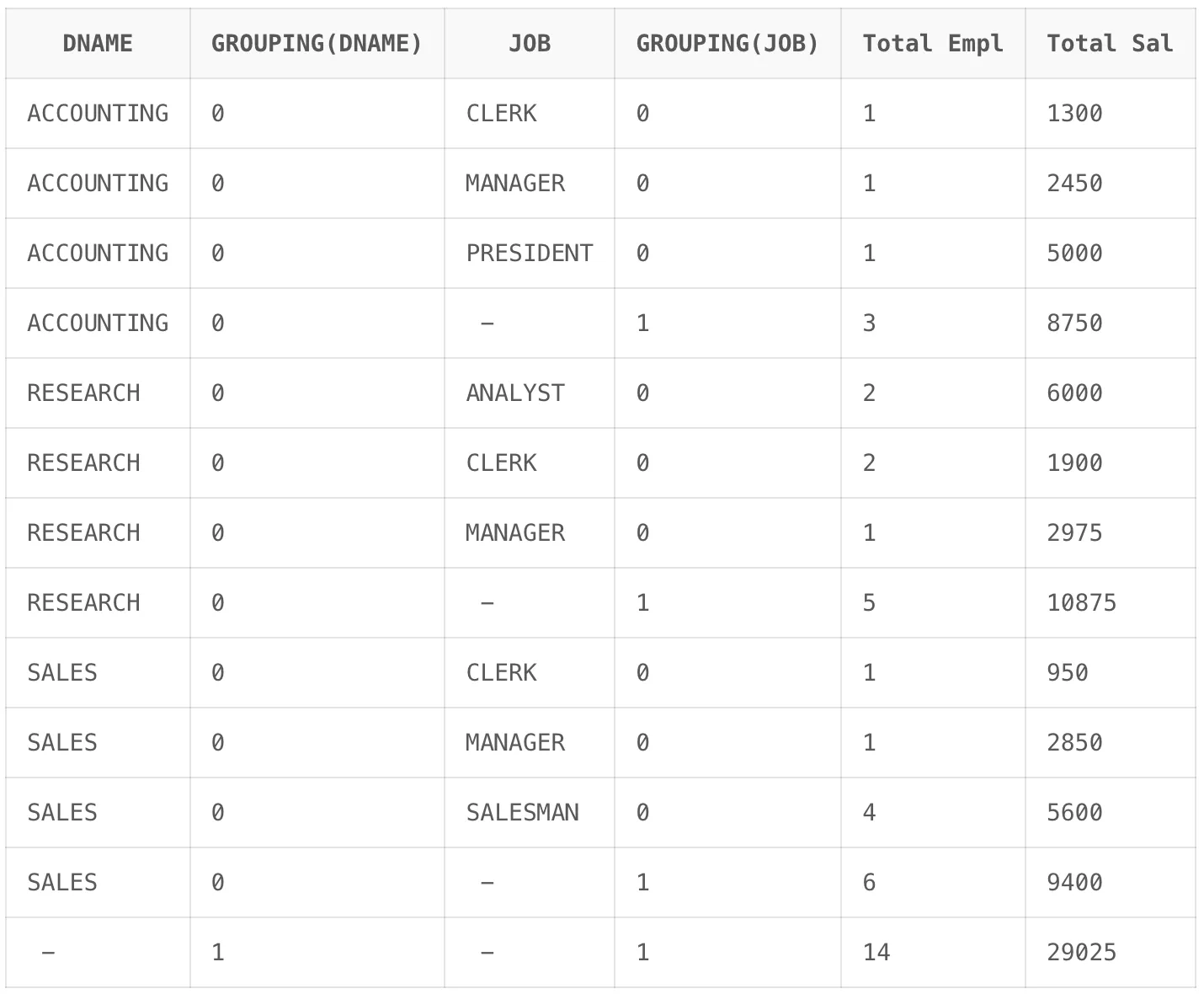
- 실습
이전 실습에서 GROUPING 함수를 사용하여 nation_id와 sport_name 칼럼에서 모든 값을 총계 내는지 확인하는 칼럼을 추가해보세요.
ROLLUP과 CASE문
ROLLUP 함수에서 소계나 합계의 경우 NULL로 표시됩니다. 소계나 합계를 NULL로 둘 수도 있지만 어떤 그룹화된 값인지를 표현하고 싶은 경우 CASE 문을 사용하면 됩니다. CASE 문은 ROLLUP 함수에서 사용자 정의 텍스트로 원하는 text 값으로 표현할 수 있습니다. GROUPING 함수와 CASE 문을 활용한 아래 예시를 통해 자세히 확인해 봅시다.
기본 예시
SELECT
CASE GROUPING(DNAME) WHEN 1 THEN 'All Departments' ELSE DNAME END AS DNAME,
CASE GROUPING(JOB) WHEN 1 THEN 'All Jobs' ELSE JOB END AS JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM EMP,
DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME, ROLLUP(JOB);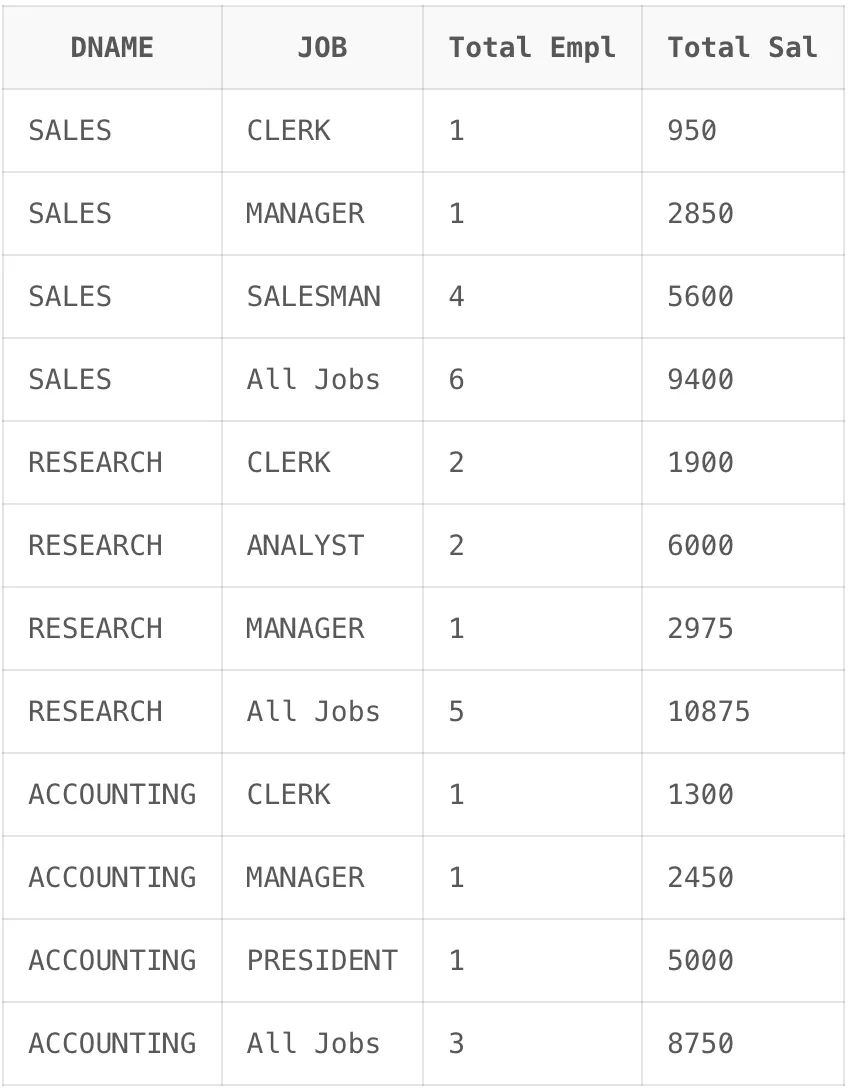
ROLLUP을 JOB에만 적용을 하여 기존에 나타났던 13번째 줄이 보이지 않는 것을 확인할 수 있습니다. 이렇게 필요한 합계나 소계를 나타내기 위해서는 필요한 컬럼 데이터만 ROLLUP 함수에 사용해주면 됩니다.
- 실습
이전 쿼리문에서 CASE 문을 통해서 nation_id의 전체 총계를 나타내는 행이면 999 개별 총계는 해당 nation_id를 출력하고, sport_name의 전체 총계를 나타내면 'ALL SPORTS' 로 개별 스포츠의 총계인 경우에는 sport_name 을 그대로 사용하여 데이터를 나타내 보세요.
SELECT CASE GROUPING(p.nation_id) WHEN 1 THEN 999 ELSE p.nation_id END AS "NATION_ID",
CASE GROUPING(s.sport_name) WHEN 1 THEN 'ALL SPORTS' ELSE s.sport_name END AS "SPORT",
count(*) "total",
ROUND(AVG(height), 2) "avg_height"
FROM participant p, sport s
WHERE p.main_sport_id = s.sport_id
GROUP BY ROLLUP (p.nation_id, s.sport_name)
ORDER BY p.nation_id DESC, s.sport_name;ROLLUP과 괄호
ROLLUP은 같은 형태를 띠고 있지만 괄호를 어디에 두느냐에 따라 다른 결과가 나옵니다. 아래 그림을 살펴보면 괄호로 결합하여 두 칼럼을 하나의 집합 칼럼처럼 간주하여 사용하고 있습니다. 이렇게 사용하면 집합 칼럼으로 묶인 칼럼은 칼럼 별 집계를 따로 계산하지 않아도 됩니다

- 기본 예시
-- 괄호 위치1
SELECT
DNAME,
JOB,
MGR,
SUM(SAL) "Total Sal"
FROM EMP,
DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP(DNAME, (JOB, MGR));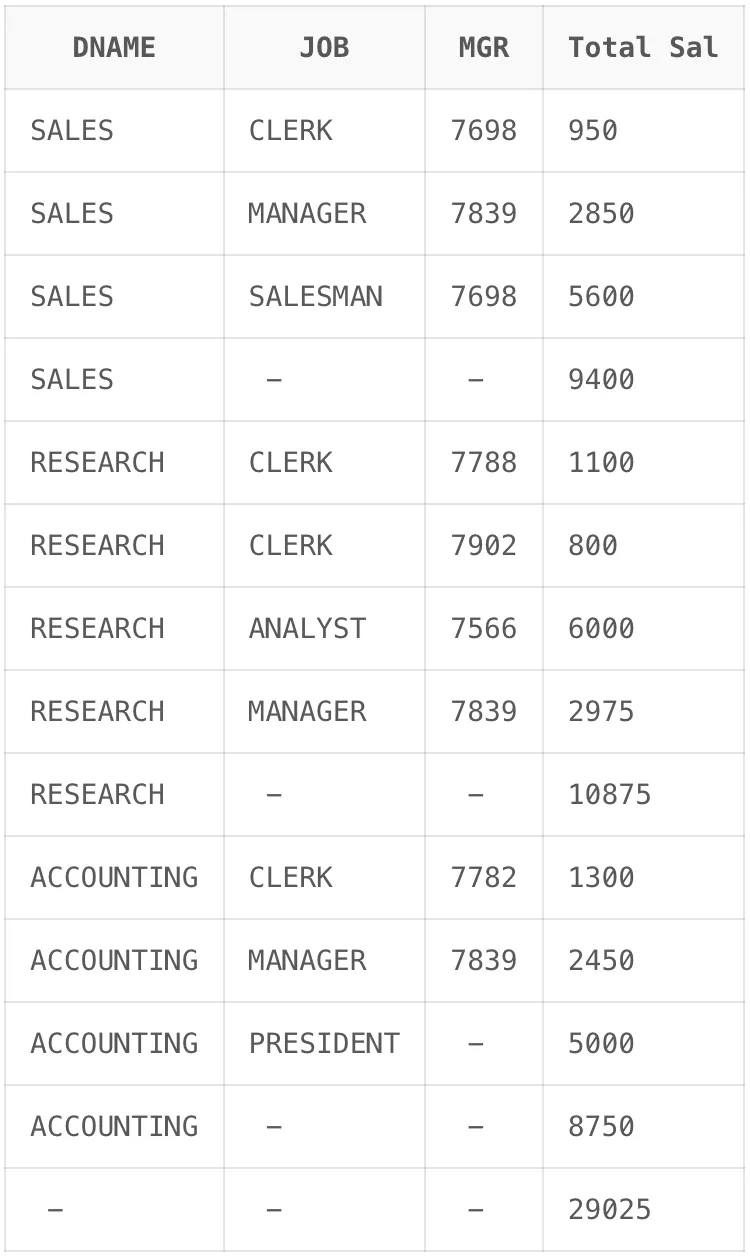
-- 괄호 위치2
SELECT
DNAME,
JOB,
MGR,
SUM(SAL) "Total Sal"
FROM EMP,
DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP((DNAME, JOB), MGR);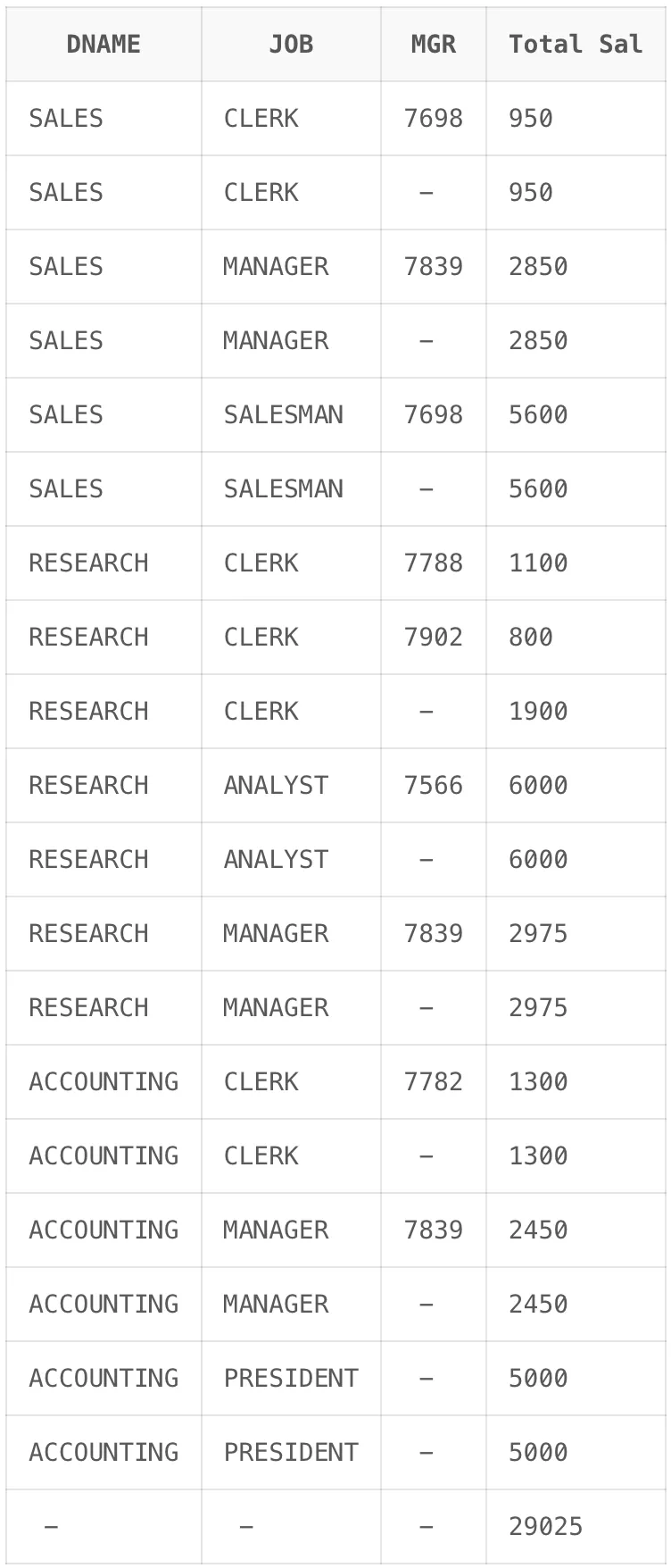
-- 괄호 위치3
SELECT
DNAME,
JOB,
MGR,
SUM(SAL) "Total Sal"
FROM EMP,
DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB, MGR);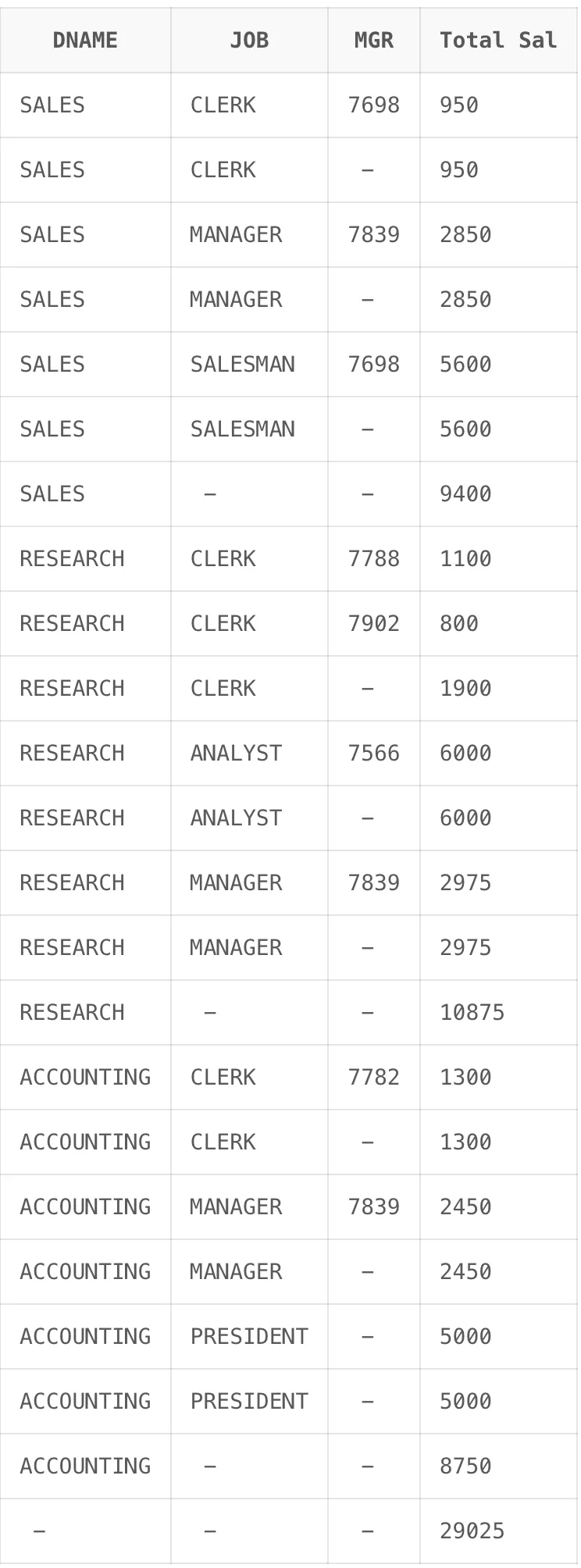
실습
다음 세 쿼리문의 결과를 비교해 보세요.
-- 1
SELECT p.nation_id, p.gender, s.sport_name, count(*) "total", ROUND(AVG(weight), 2)
FROM participant p, sport s
WHERE p.main_sport_id = s.sport_id
GROUP BY ROLLUP ((p.nation_id, p.gender), s.sport_name)
ORDER BY p.nation_id DESC, s.sport_name;
-- 2
SELECT p.nation_id, p.gender, s.sport_name, count(*) "total", ROUND(AVG(weight), 2)
FROM participant p, sport s
WHERE p.main_sport_id = s.sport_id
GROUP BY ROLLUP (p.nation_id, (p.gender, s.sport_name))
ORDER BY p.nation_id DESC, s.sport_name;
-- 3
SELECT p.nation_id, p.gender, s.sport_name, count(*) "total", ROUND(AVG(weight), 2)
FROM participant p, sport s
WHERE p.main_sport_id = s.sport_id
GROUP BY ROLLUP (p.nation_id, p.gender, s.sport_name)
ORDER BY p.nation_id DESC, s.sport_name;CUBE 함수
기본형태
CUBE 함수는 표시된 그룹화된 칼럼에 대한 계층별 집계를 구할 수 있습니다. 여러 열을 기반으로 데이터를 다양한 방식으로 집계하며 다차원적인 소계를 계산하는 기능이기에 결합 가능한 모든 값에 대해 집계를 생성합니다
쉽게말해 그룹화된 데이터의 모든 가능한 조합에 대해 합계를 계산하는 것
이때 표시된 칼럼 간의 계층 구조인 ROLLUP과는 다르게 평등한 관계이므로 칼럼의 순서가 바뀌어도 정렬되는 순서는 바뀌지만 데이터의 결과는 동일합니다. 결과에 대한 정렬이 필요한 경우는 ORDERY BY 절을 사용하여 명시적으로 정렬 칼럼을 작성하여 정렬해 주어야 합니다.
ROLLUP 함수에 비해서 시스템의 연산 대상이 많은 것이 특징입니다.
기본 구조
CUBE (A,B)
- A별, B별, (A,B)별, 전체 그룹 연산 결과 출력
- 그룹으로 묶을 대상의 나열 순서는 중요하지 않음
예시
SELECT
CASE GROUPING(DNAME) WHEN 1 THEN 'All Departments' ELSE DNAME END AS DNAME,
CASE GROUPING(JOB) WHEN 1 THEN 'All Jobs' ELSE JOB END AS JOB,
COUNT(*) "TotalEmpl",
SUM(SAL) "Total Sal"
FROM EMP,
DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY CUBE (DNAME, JOB);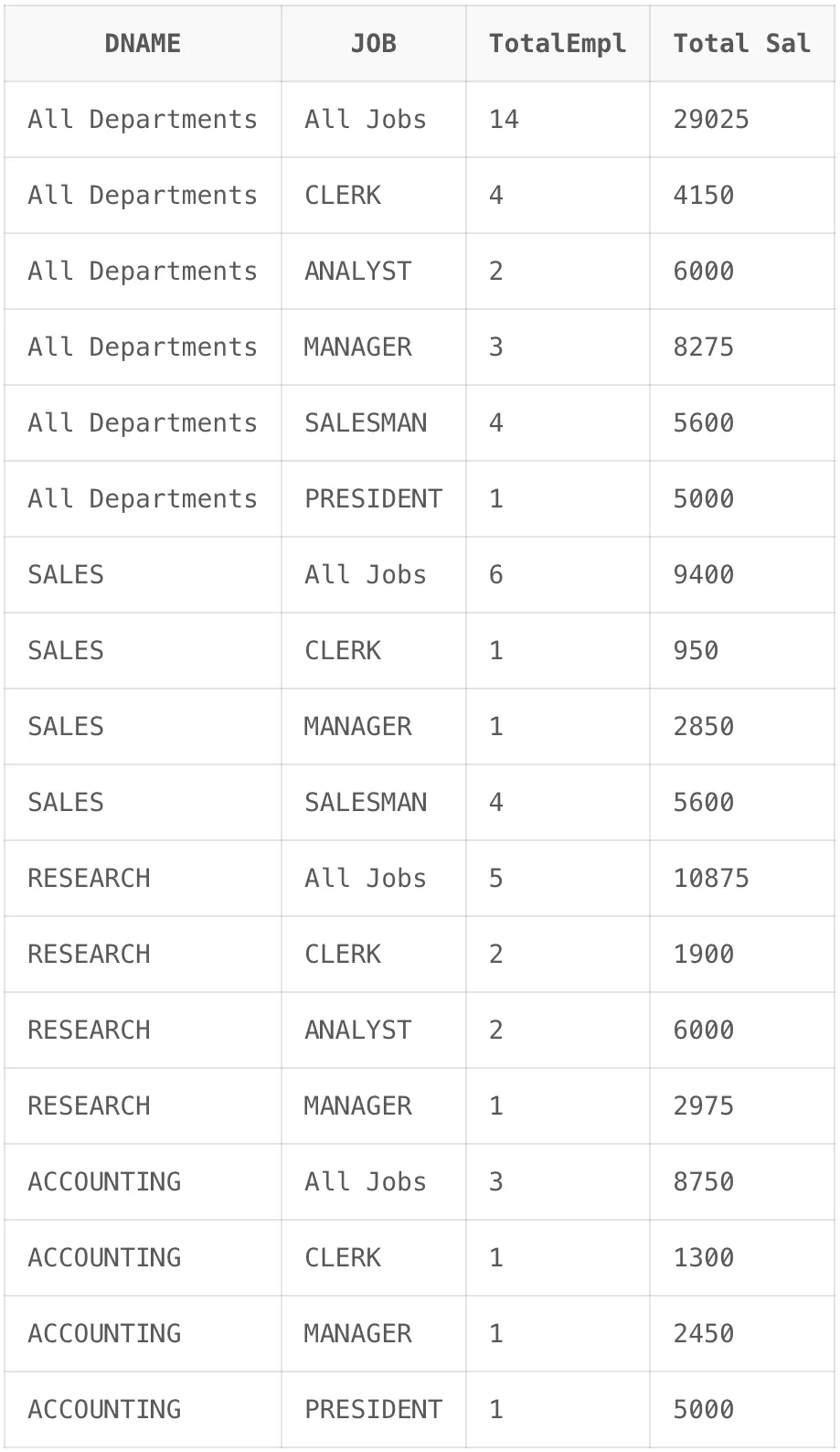
모든 경우의 수에 대하여 중간 합계를 나타내기 때문에 GROUPING 칼럼의 수가 N이라고 가정하면 개의 중간 합계를 생성하게 됩니다.
ROLLUP 함수 결과에 5개의 All Departments 의 JOB 별 소계 정보가 추가되어 나타난 것을 확인할 수 있습니다.
실습
GROUP BY로 nation_id와 sport_name 칼럼 순서로 CUBE 사용하여 nation_id, sport_name, 국가별 총 참가자 수, 평균 몸무게를 출력해보세요. 평균 몸무게는 소수점 둘째자리까지 반올림하여 출력해주세요.
CASE 문을 통해서 nation_id의 전체 총계를 나타내는 행이면 999 개별 총계는 해당 nation_id를 출력하고, sport_name의 전체 총계를 나타내면 'ALL SPORTS' 로 개별 스포츠의 총계인 경우에는 sport_name 을 그대로 사용하여 데이터를 나타내 보세요.
SELECT CASE GROUPING(p.nation_id) WHEN 1 THEN 999 ELSE p.nation_id END AS "NATION_ID",
CASE GROUPING(s.sport_name) WHEN 1 THEN 'ALL SPORTS' ELSE s.sport_name END AS "SPORT",
count(*) "total",
ROUND(AVG(weight), 2)
FROM participant p, sport s
WHERE p.main_sport_id = s.sport_id
GROUP BY CUBE (p.nation_id, s.sport_name);참고!
ROLLUP과 CUBE의 차이 한 눈에 살펴보기
ROLLUP (YEAR, MONTH, DAY)YEAR, MONTH, DAY YEAR, MONTH YEAR ()CUBE (YEAR, MONTH, DAY)YEAR, MONTH, DAY YEAR, MONTH YEAR, DAY YEAR MONTH, DAY MONTH DAY ()
(참고) UNION ALL과 CUBE 함수
UNION ALL 을 사용할 때 CUBE 함수를 사용할 때 성능 개선이 가능합니다. UNION ALL 사용할 때 SQL 연산에서 동일한 테이블 접근이 반복해서 일어날 수 있는 부분을 CUBE 함수 사용으로 줄일 수 있습니다. 이렇게 되면 수행 속도 및 자원 사용률도 개선할 수 있으며 SQL 문장도 더 짧아져서 가독성도 좋아집니다.
- UNION ALL 코드 예시
SELECT DNAME, JOB, COUNT(*) "Total Empl", SUM(SAL) "Total Sal" FROM EMP, DEPT WHERE DEPT.DEPTNO = EMP.DEPTNO GROUP BY DNAME, JOB UNION ALL SELECT DNAME, 'All Jobs', COUNT(*) "Total Empl", SUM(SAL) "Total Sal" FROM EMP, DEPT WHERE DEPT.DEPTNO = EMP.DEPTNO GROUP BY DNAME UNION ALL SELECT 'All Departments', JOB, COUNT(*) "Total Empl", SUM(SAL) "Total Sal" FROM EMP, DEPT WHERE DEPT.DEPTNO = EMP.DEPTNO GROUP BY JOB UNION ALL SELECT 'All Departments', 'All Jobs', COUNT(*) "Total Empl", SUM(SAL) "Total Sal" FROM EMP, DEPT WHERE DEPT.DEPTNO = EMP.DEPTNO;
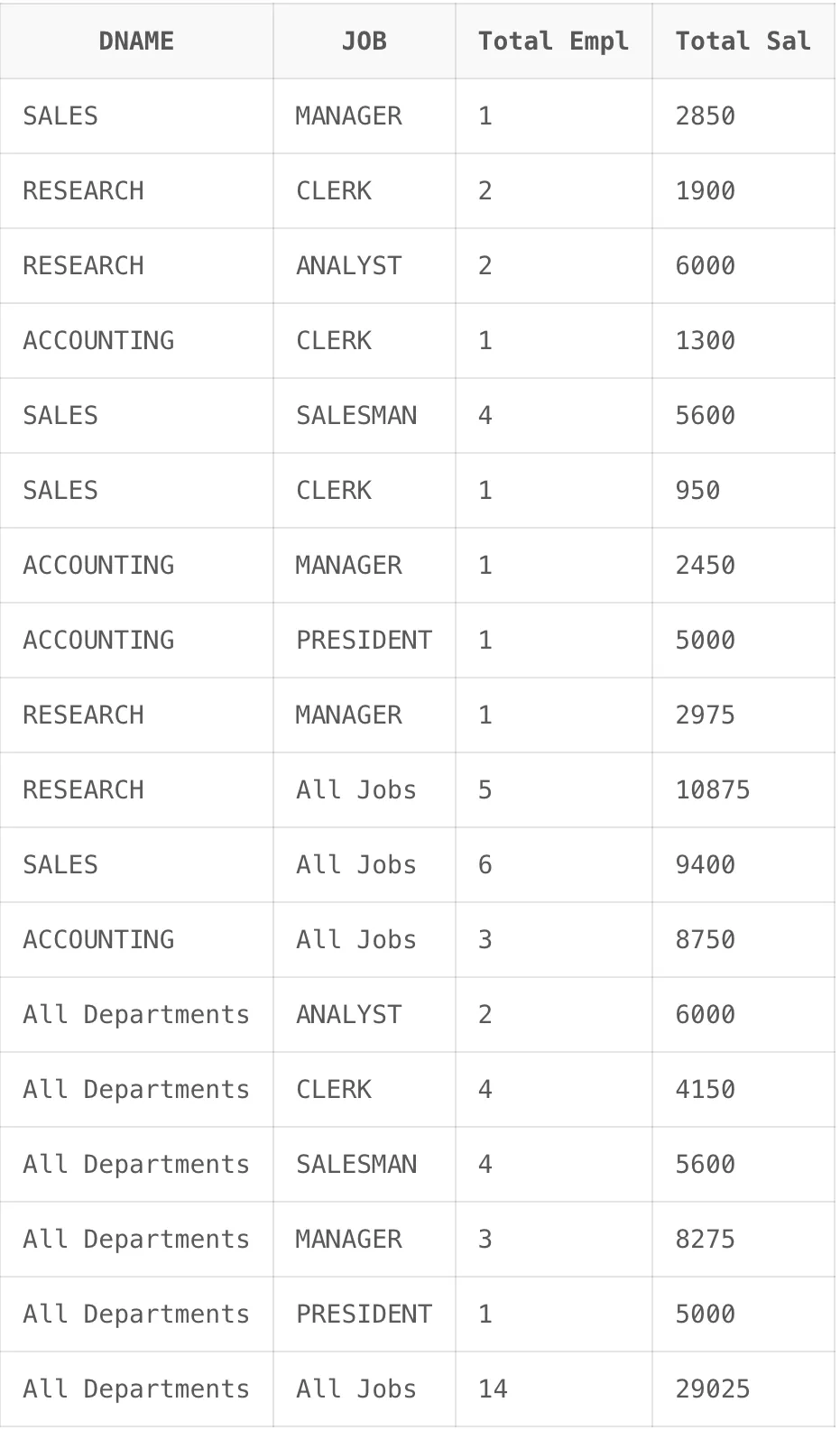
GROUPING SETS 함수
GROUPING SETS를 이용하면 GROUP BY 문장을 여러 번 반복하지 않아도 다양한 소계 집합을 만들 수 있습니다. GROUPING SETS에 표시된 모든 칼럼들에 대한 개별 집계를 구할 수 있으며 이때 표시된 칼럼들은 서로 평등한 관계이므로 순서가 바뀌어도 결과는 동일하게 나타납니다.
즉 ROLLUP 과 CUBE 와 비슷한 결과를 얻을 수 있지만 좀 더 명시적으로 원하는 그룹 수준을 정할 수 있습니다.
예시1
SELECT
DNAME,
JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY GROUPING SETS (DNAME, JOB);결과
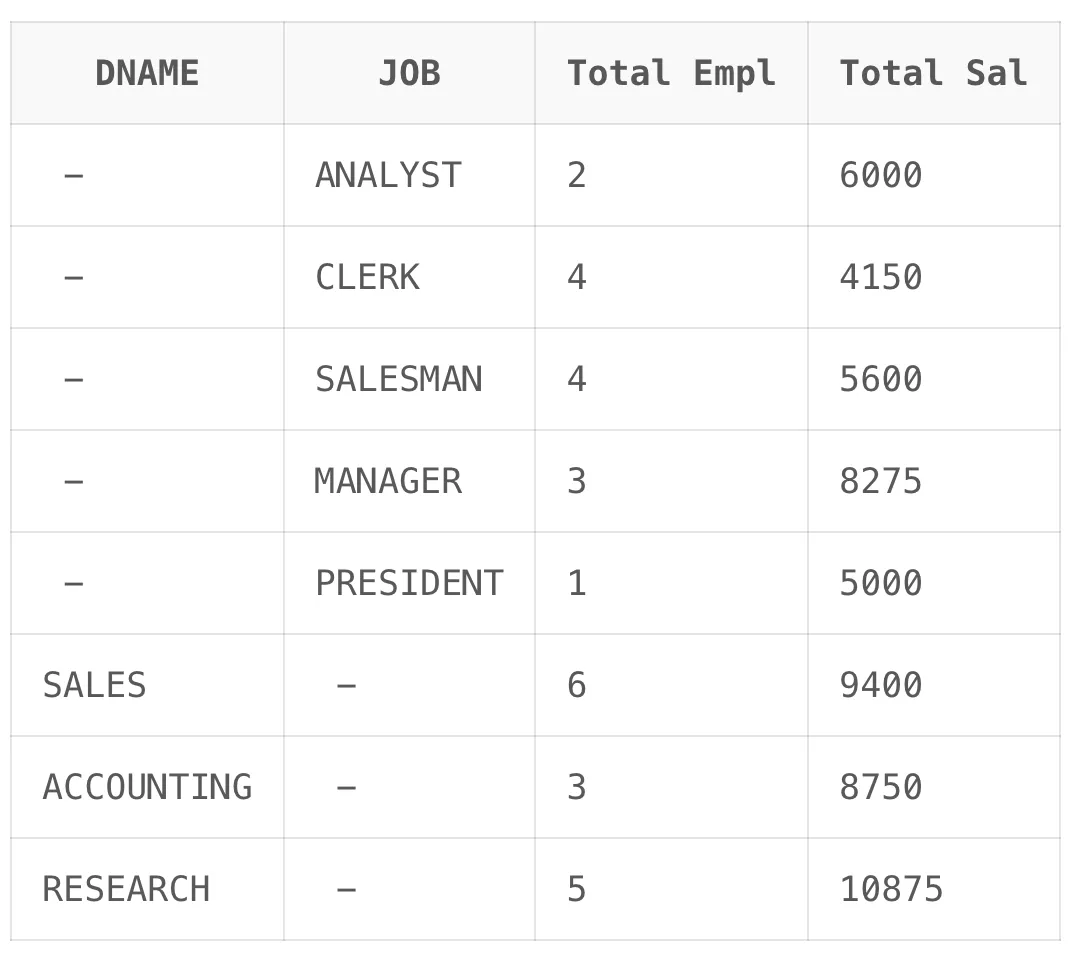
예시2
SELECT
DNAME,
JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY GROUPING SETS (DNAME,JOB,());GTOUPING SETS( DNAME , JOB, ()) -> 전체에 대한 집계 표시
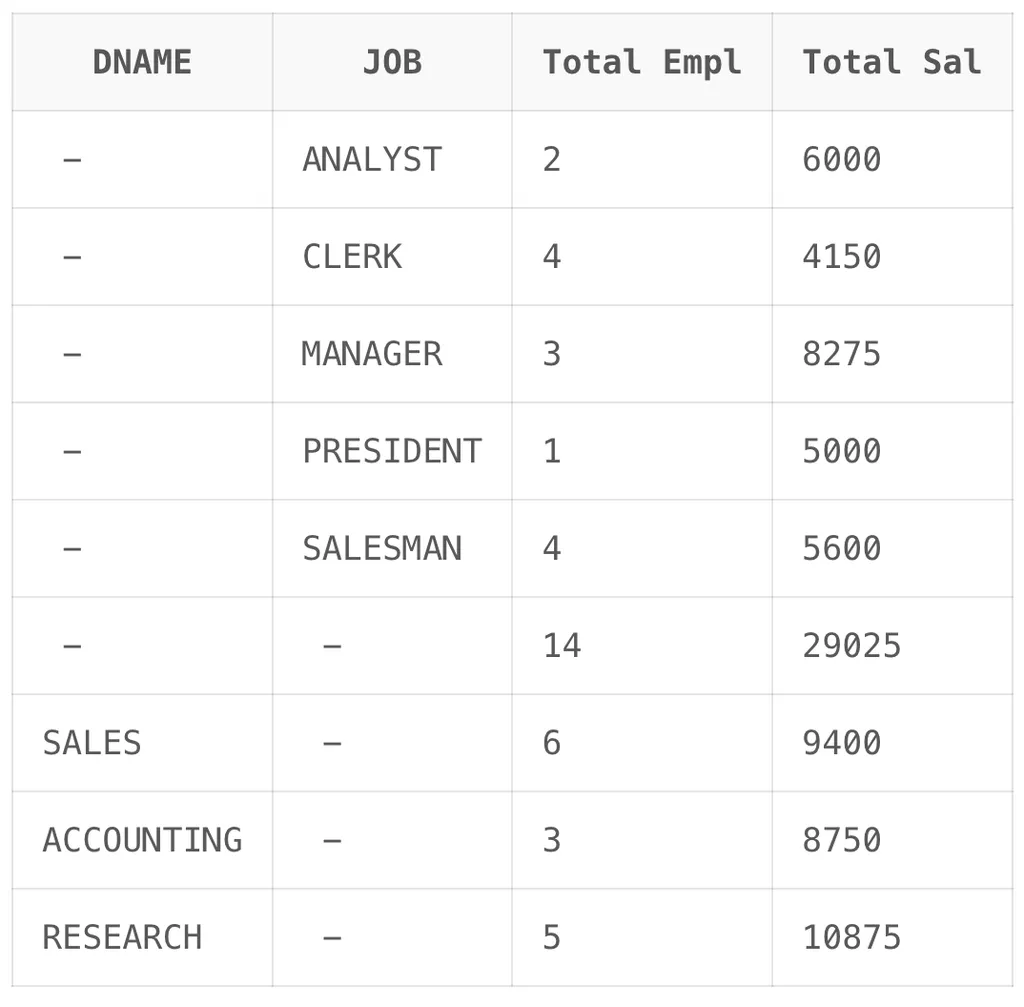
예시 3
GROUPING SETS 함수도 그룹화된 칼럼을 묶어서 하나의 인수로 사용할 수 있습니다.
SELECT
DNAME,
JOB,
MGR,
SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY GROUPING SETS ((DNAME, JOB, MGR), (DNAME, JOB), (JOB, MGR));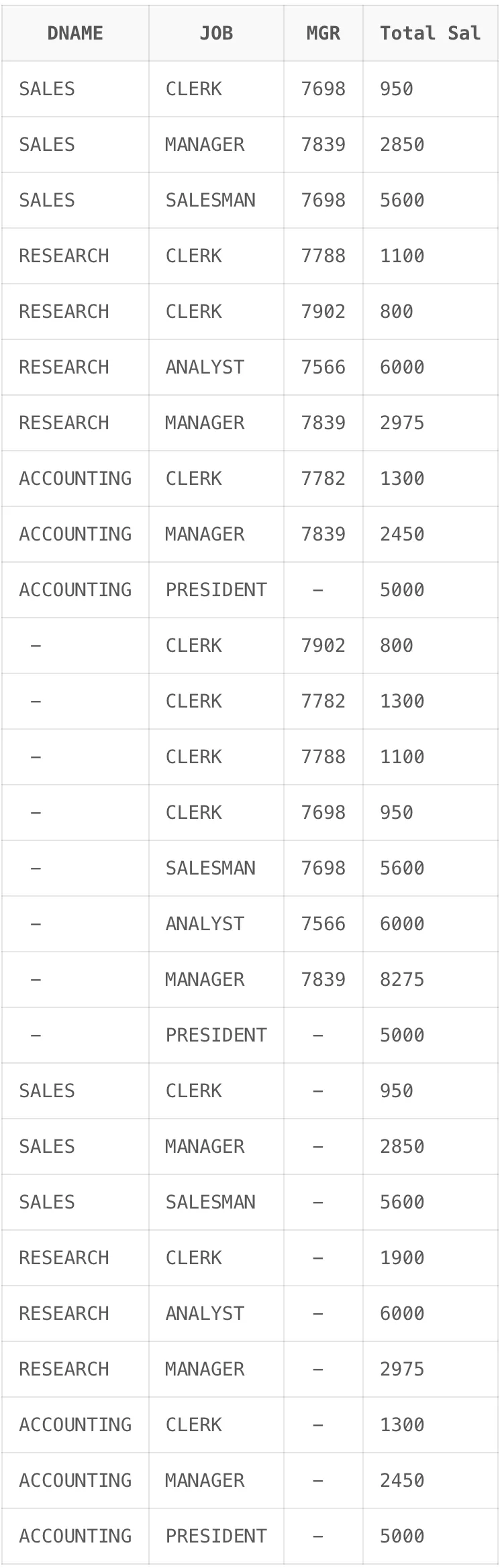
첫 번째 10건의 데이터는 (DNAME, JOB, MGR) 기준의 집계이고, 두 번째 8건의 데이터는 (JOB, MGR) 기준의 집계 입니다. 세 번째 9건의 데이터는 (DNAME , JOB) 기준의 집계 결과입니다.
실습 1
다음 GROUP BY 의 칼럼 순서가 다른 두 쿼리 문을 비교해보세요.
-- 1
SELECT CASE GROUPING(p.nation_id) WHEN 1 THEN 999 ELSE p.nation_id END AS "NATION_ID",
CASE GROUPING(s.sport_name) WHEN 1 THEN 'ALL SPORTS' ELSE s.sport_name END AS "SPORT",
count(*) "total",
ROUND(AVG(height), 2)
FROM participant p, sport s
WHERE p.main_sport_id = s.sport_id
GROUP BY GROUPING SETS (p.nation_id, s.sport_name);-- 2
SELECT DECODE(GROUPING(p.nation_id), 1, 999, p.nation_id) AS "NATION_ID",
DECODE(GROUPING(s.sport_name), 1, 'ALL SPORTS', s.sport_name) AS "SPORT",
count(*) "total",
ROUND(AVG(height), 2)
FROM participant p, sport s
WHERE p.main_sport_id = s.sport_id
GROUP BY GROUPING SETS (s.sport_name, p.nation_id);문제
1번
| Q. 문제 | 결합 가능한 모든 집계를 계산하는 그룹 함수는? |
|---|---|
| A. (1) | ROLLUP |
| A. (2) | CUBE |
| A. (3) | GROUPING SETS |
| A. (4) | GROUPING |
답
CUBE : 그룹화된 데이터의 모든 가능한 조합에 대해 합계를 계산하는 것
2번
| Q. 문제 | 그룹 함수에 대한 설명으로 가장 적절하지 않은 것은? |
|---|---|
| A. (1) | GROUPING SETS 함수는 특정 항목에 대한 소계를 구하는 함수 |
| A. (2) | ROLLUP 함수는 그룹화된 칼럼의 수가 N개면 소계는 N+1개 생성된다 |
| A. (3) | CUBE는 원하는 부분의 소계만 쉽게 추출할 수 있고 GROUPING SETS는 다차원 집계를 하므로 시스템에 부하를 줄 수 있다 |
| A. (4) | ROLLUP 함수는 인자로 주어진 컬럼의 순서에 따라 결과가 달라지므로 유의해야 한다 |
답
GROUPING SETS는 원하는 부분의 소계만 손쉽게 추출할 수 있고 CUBE는 다차원 집계를 하므로 시스템에 부하를 줄 수 있다
3번
| Q. 문제 | 아래 <보기>는 그룹 함수 CUBE에 대한 설명이다. ❓에 들어갈 숫자는 무엇인가? <보기> CUBE는 결합 가능한 모든 값에 대해 SUBTOTAL을 생성하므로 GROUPING 칼럼의 수가 N이라고 가정하면❓의 N승 LEVEL의 SUBTOTAL을 생성하게 된다. |
|---|---|
| A. (1) | 1 |
| A. (2) | 2 |
| A. (3) | 3 |
| A. (4) | 4 |
답
예를 들어, GROUPING 칼럼의 수가 2라고 가정하면, 2의 2승 = 4 LEVEL의 SUBTOTAL을 생성하게 된다.
11.1. 윈도우 함수
WINDOW FUNCTION 개요
기본 정의
기존 관계형 데이터 베이스는 칼럼 간의 연산, 비교, 연결이나 집합에 대한 집계는 비교적 쉽게 할 수 있었습니다. 하지만 행과 행간의 관계를 정의하거나, 행 간 비교를 하거나 하나의 SQL 문으로 처리하기는 매우 힘든 일이었습니다. 이렇게 복잡한 SQL 문을 작성해야 하던 것을 부분적으로나마 쉽게 정의하기 위해 만들어진 함수가 바로 윈도우 함수(WINDOW FUNCTION)입니다.
그룹 내 순위 함수
일반 집계 함수
(참고) 그룹 내 행 순서 함수
(참고) 그룹 내 비율 함수
개념 정리
연습문제
1번
답
2번
답
3번
답
