https://leetcode.com/problems/human-traffic-of-stadium/description/
문제
Table: Stadium
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| id | int |
| visit_date | date |
| people | int |
+---------------+---------+
visit_date is the column with unique values for this table.
Each row of this table contains the visit date and visit id to the stadium with the number of people during the visit.
As the id increases, the date increases as well.
Write a solution to display the records with three or more rows with consecutive id's, and the number of people is greater than or equal to 100 for each.
Return the result table ordered by visit_date in ascending order.
The result format is in the following example.
Example 1:
Input:
Stadium table:
+------+------------+-----------+
| id | visit_date | people |
+------+------------+-----------+
| 1 | 2017-01-01 | 10 |
| 2 | 2017-01-02 | 109 |
| 3 | 2017-01-03 | 150 |
| 4 | 2017-01-04 | 99 |
| 5 | 2017-01-05 | 145 |
| 6 | 2017-01-06 | 1455 |
| 7 | 2017-01-07 | 199 |
| 8 | 2017-01-09 | 188 |
+------+------------+-----------+
Output:
+------+------------+-----------+
| id | visit_date | people |
+------+------------+-----------+
| 5 | 2017-01-05 | 145 |
| 6 | 2017-01-06 | 1455 |
| 7 | 2017-01-07 | 199 |
| 8 | 2017-01-09 | 188 |
+------+------------+-----------+
Explanation:
The four rows with ids 5, 6, 7, and 8 have consecutive ids and each of them has >= 100 people attended. Note that row 8 was included even though the visit_date was not the next day after row 7.
The rows with ids 2 and 3 are not included because we need at least three consecutive ids.내 풀이
풀이 과정
- people 세어본다
- 100 미만인 row들 쭉 찾아본다
- 2번에 해당하는 아이디들 저장하고 앞 뒤에 0, (max)+1 값들 붙여준다. (계산하려고)
- 각자 이전 아이디끼리 뺀다. (Lag) 아이디들의 값의 차가 3초과인 순간 이전 id 부터 해당 아이디까지 까지 where 로 가져온다.
쿼리 시도 1
with under_100 as
(
SELECT 0 as u100_id
union all
SELECT id as u100_id
FROM Stadium
where people < 100
union all
SELECT (SELECT MAX(id) + 1 FROM Stadium)
),
diff as (
SELECT u100_id,
LAG(u100_id) over(order by u100_id) as prev_u100_id
from under_100
),
id_loc as(
SELECT prev_u100_id+1 AS start_id,
u100_id-1 as end_id
from diff
where u100_id - prev_u100_id >= 4
)
SELECT *
FROM Stadium
WHERE id between (select start_id from id_loc)
and (select end_id from id_loc)SELECT prev_u100_id+1 AS start_id, u100_id-1 as end_id
이부분이 헷갈리는 부분인데,
100 미만 숫자들은 제외를 시켜야 하기 때문에 해당 row들에 +1, -1 을 더해줬다.
예시로 살펴보자
| id | people |
|---|---|
| 1 | 10 ← under_100 |
| 2 | 109 ← keep |
| 3 | 150 ← keep |
| 4 | 99 ← under_100 |
| 5 | 145 ← keep |
| 6 | 1455 ← keep |
| 7 | 199 ← keep |
| 8 | 188 ← keep |
| 9 | 30 ← under_100 |
under_100 id 목록: 0, 1, 4, 9, 10
(10 = MAX(id)+1)
diff 결과:
| id | prev_id |
|---|---|
| 1 | 0 → 거리 1 → skip |
| 4 | 1 → 거리 3 → skip |
| 9 | 4 → 거리 5 ✅ |
| 10 | 9 → 거리 1 → skip |
그래서
SELECT prev_id + 1, id - 1
→ 4 + 1 = 5, 9 - 1 = 8결과: id BETWEEN 5 AND 8 구간 출력
위와 같은 쿼리는 15개의 테스트 케이스 중 10개를 통과했는데
통과하지 못 한 테스트 케이스에서 나온 에러메세지는 아래와 같다
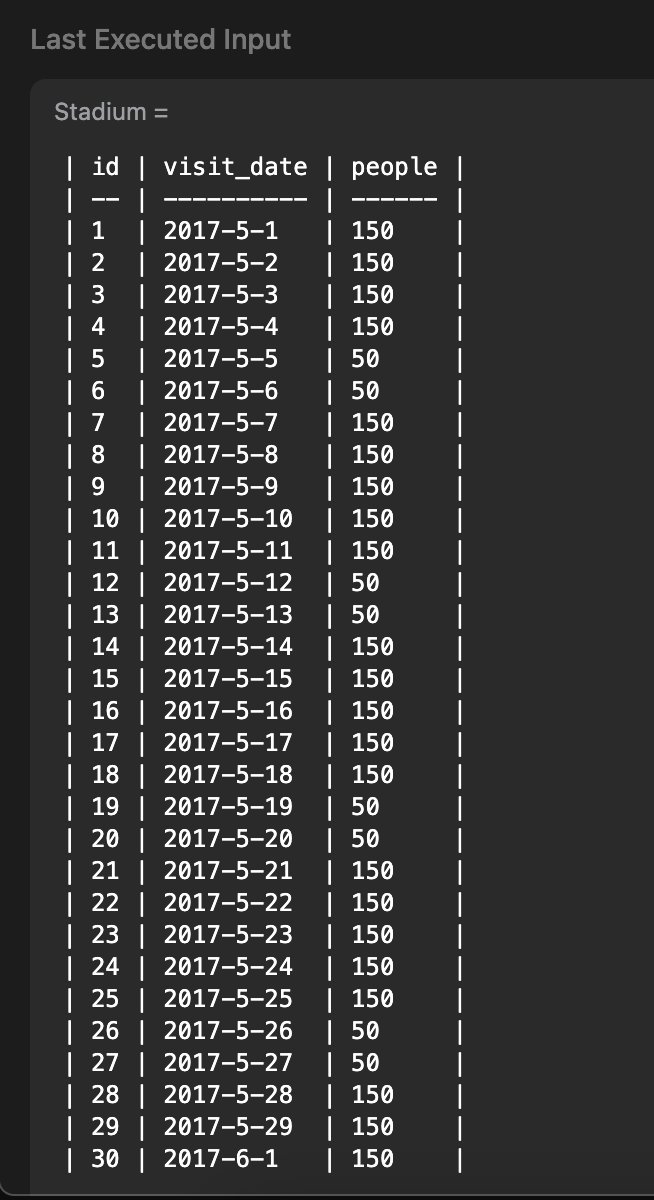
input의 형태를 보면
1~4, 7~11, 14~18, 21~25, 28~30 행에서 3개행 이상의 연속적인 records 들이 보였다.
이로 인해 문제가 되는 부분은 이곳인데,
id_loc as(
SELECT prev_u100_id+1 AS start_id,
u100_id-1 as end_id
from diff
where u100_id - prev_u100_id >= 4
)
SELECT *
FROM Stadium
WHERE id between (select start_id from id_loc)
and (select end_id from id_loc)id_loc의 결과가 여러 개가 되면서
맨 아래 Between에 걸리리는 서브쿼리의 Select의 개수가 2개 이상이 되고
Subquery returns more than 1 row 같은 에러 메세지가 나오는 것이다.
여기서부터는 멘붕.
어떻게 해야되냐.
with under_100 as
(
SELECT 0 as u100_id
union all
SELECT id as u100_id
FROM Stadium
where people < 100
union all
SELECT (SELECT MAX(id) + 1 FROM Stadium)
),
diff as (
SELECT u100_id,
LAG(u100_id) over(order by u100_id) as prev_u100_id
from under_100
),
id_loc as(
SELECT prev_u100_id+1 AS start_id,
u100_id-1 as end_id
from diff
where u100_id - prev_u100_id >= 4
)
SELECT *
FROM id_locinput(test_case_10)
| id | visit_date | people |
| -- | ---------- | ------ |
| 1 | 2017-5-1 | 150 |
| 2 | 2017-5-2 | 150 |
| 3 | 2017-5-3 | 150 |
| 4 | 2017-5-4 | 150 |
| 5 | 2017-5-5 | 50 |
| 6 | 2017-5-6 | 50 |
| 7 | 2017-5-7 | 150 |
| 8 | 2017-5-8 | 150 |
| 9 | 2017-5-9 | 150 |
| 10 | 2017-5-10 | 150 |
| 11 | 2017-5-11 | 150 |
| 12 | 2017-5-12 | 50 |
| 13 | 2017-5-13 | 50 |
| 14 | 2017-5-14 | 150 |
| 15 | 2017-5-15 | 150 |
| 16 | 2017-5-16 | 150 |
| 17 | 2017-5-17 | 150 |
| 18 | 2017-5-18 | 150 |
| 19 | 2017-5-19 | 50 |
| 20 | 2017-5-20 | 50 |
| 21 | 2017-5-21 | 150 |
| 22 | 2017-5-22 | 150 |
| 23 | 2017-5-23 | 150 |
| 24 | 2017-5-24 | 150 |
| 25 | 2017-5-25 | 150 |
| 26 | 2017-5-26 | 50 |
| 27 | 2017-5-27 | 50 |
| 28 | 2017-5-28 | 150 |
| 29 | 2017-5-29 | 150 |
| 30 | 2017-6-1 | 150 |output
| start_id | end_id |
| -------- | ------ |
| 1 | 4 |
| 7 | 11 |
| 14 | 18 |
| 21 | 25 |
| 28 | 30 |쿼리 비교
( 수정본 )
내 쿼리
#1. people 세어본다
#2. 100 이하인 녀석들 쭉 찾아본다
#3. 해당 아이디 저장하고
#4. 각자 아래 아이디끼리 뺸다.
#5. 아이디 값의 차가 3 초과인 순간 그 아이디부터 빼기 전 id 까지 where 로 가져온다.
#6. 그 다음 없으면 마지막까지 출력.
with under_100 as
(
SELECT 0 as u100_id
union all
SELECT id as u100_id
FROM Stadium
where people < 100
union all
SELECT (SELECT MAX(id) + 1 FROM Stadium)
),
diff as (
SELECT u100_id,
LAG(u100_id) over(order by u100_id) as prev_u100_id
from under_100
),
id_loc as(
SELECT prev_u100_id+1 AS start_id,
u100_id-1 as end_id
from diff
where u100_id - prev_u100_id >= 4
)
SELECT s.*
FROM Stadium s
join id_loc i
on s.id between i.start_id and i.end_id
order by s.id특징
| 항목 | 내용 |
|---|---|
| 방식 | people < 100인 지점을 기준으로 연속 구간을 잘라냄 |
| 주요 함수 | LAG, BETWEEN, WITH RECURSION 없음 |
| 장점 | 쿼리 흐름이 직관적이고 조건 분리가 명확함 |
| 단점 | Stadium 테이블이 클 경우 JOIN, LAG, SUBQUERY 3중 연산 발생으로 성능 저하 우려 |
| 보장 사항 | 연속된 기간을 기준으로 사람 수 < 100이 나오기 전 구간을 잘라오기 때문에 비교적 안정적 |
성능 고려
- Stadium 테이블이 정렬된 ID 기반이면 성능 양호, 다만 JOIN + BETWEEN이 index 없이 돌아가면 Full Scan 발생
- under_100의 MAX(id)+1 등도 비효율적일 수 있음 (단건 쿼리지만 index 없으면 느려짐)
다른 사람들의 풀이 1 (grp_id 기반 쿼리)
WITH filtered AS (
SELECT *
FROM Stadium
WHERE people >= 100
),
grp AS (
SELECT *,
id - ROW_NUMBER() OVER (ORDER BY id) AS grp_id
FROM filtered
),
valid_groups AS (
SELECT grp_id
FROM grp
GROUP BY grp_id
HAVING COUNT(*) >= 3
)
SELECT g.id, g.visit_date, g.people
FROM grp g
JOIN valid_groups v ON g.grp_id = v.grp_id
ORDER BY g.visit_date;특징
| 항목 | 내용 |
|---|---|
| 방식 | id - ROW_NUMBER() 방식으로 연속 구간을 group id로 치환 |
| 주요 함수 | ROW_NUMBER, GROUP BY, JOIN |
| 장점 | 연속 구간 판단이 깔끔하고 성능 우수, 재사용 쉬움 |
| 단점 | ROW_NUMBER()는 정렬을 필요로 하므로 대규모 데이터에서 비용 발생 가능 |
| 보장 사항 | id가 연속일 경우에만 정확 (gap이 없다는 가정 하에 설계됨) |
성능 고려
- ROW_NUMBER()는 윈도우 함수이지만 단일 정렬 컬럼 기준이라 성능 부담 낮음
- people >= 100 필터가 먼저 적용되어 데이터 양이 줄어듦 → 이점 큼
- id가 gap 없이 연속된 숫자일 때만 정확히 작동하므로, 이 가정이 깨지면 위험
다른 사람들의 풀이 2(dense_rank + level 기반)
# Write your MySQL query statement below
WITH res_cte AS (
SELECT
*,
id - dense_rank() OVER (ORDER BY visit_date) level
FROM
Stadium
WHERE people >= 100)
,final_cte AS (
SELECT
id,
visit_date,
people,
COUNT(*) OVER (PARTITION BY level) consec_count
FROM res_cte
)
SELECT id, visit_date, people FROM final_cte WHERE consec_count > 2 ORDER BY visit_date;특징
| 항목 | 내용 |
|---|---|
| 방식 | id - DENSE_RANK()로 연속 구간을 판별 |
| 주요 함수 | DENSE_RANK, COUNT OVER PARTITION |
| 장점 | 날짜 기준 정렬 사용 가능, visit_date가 key인 경우 유연성 좋음 |
| 단점 | DENSE_RANK와 COUNT OVER 둘 다 비용 높은 윈도우 함수 |
| 보장 사항 | 연속된 날짜가 visit_date로 표현될 수 있다면 강력함 |
성능 고려
- DENSE_RANK()는 일반적으로 ROW_NUMBER()보다 약간 느림
- COUNT OVER PARTITION도 전체 구간 재계산 필요
- visit_date가 잘 정렬되어 있고 index가 있으면 성능 양호
전체 비교 요약
| 항목 | 너의 쿼리 | 쿼리 1 (grp_id) | 쿼리 2 (dense_rank) |
|---|---|---|---|
| 방식 | 구간 차이 기반 (LAG, diff) | 연속 그룹화 (ROW_NUMBER) | 연속 그룹화 (DENSE_RANK) |
| 윈도우 함수 사용 | LAG | ROW_NUMBER | DENSE_RANK, COUNT OVER |
| ID 연속성 필요 | ❌ | ✅ (id 연속 필요) | ❌ (날짜 기준 유연) |
| 성능 (소규모) | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 성능 (대규모) | ⭐⭐ (Join 많은 편) | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| 해석 직관성 | 높은 편 | 가장 높음 | 중간 |
| 유지보수성 | 보통 | 우수 | 보통 |
| 데이터 엔지니어링 적합성 | 이벤트 기반 처리에 적합 | ETL 중 정규화에 적합 | 시계열 기반 분석 적합 |
GPT 피셜 접근 방식에 차이
| 항목 | 너의 쿼리 | 쿼리 1 |
|---|---|---|
| 실시간 처리 | 이벤트 탐지에 유리 (ex. 특정 조건 발생 전후 감시) | 연속 레코드 집계에 강함 |
| 로그/센서 분석 | "임계값 이하" 탐지에 적합 | 정상 패턴 찾기, 예: 일정 기간 동안 이상 없이 작동한 구간 탐색 |
| 성능 고려 | LAG + JOIN 구조 → 대용량일수록 부담 | ROW_NUMBER만 사용하면 가벼움 |
| 의도 표현 | 비즈니스 로직 명확 (조건 기반) | 구조화된 패턴 분석에 유리 |
둘 다 결국 "연속된 구간"을 찾는 게 목적이지만, 연속을 정의하고 검출하는 방식이 완전히 다르지.
너의 쿼리는 “경계 조건(예: 100 미만)”이 중요한 경우에 적합함.
→ 이벤트 기반 처리가 필요한 로그/센서 분석, 에러 전후 상태 추적 등에 매우 유용함.
쿼리 1은 “연속된 구간” 자체를 패턴으로 정의하려는 구조임.
→ ETL, 정형 데이터 집계, 통계적 분석, 그룹별 계산 등에 적합함.
결국 또 성능과의 싸움에서 지고 말았다.
다른 사람풀이 1 번으로 복습하면서 보니 논리도 1번이 훨씬 깔끔하고 좋은 접근 방법인 것 같다.
강해져서 돌아와라..
