깃헙 graphrag 설명
티스토리 정리
공식문서
1. Local Search
로컬 검색은 엔티티를 컨텍스트 구축을 위한 진입점으로 사용한다.
모든 엔티티 설명은 색인 중에 포함되며, 로컬 검색이 실행될 때 가장 가까운 엔티티를 찾기 위해 쿼리 텍스트를 포함한다.
그런 다음 그래프 탐색을 사용해 이렇게 검색된 엔티티, 관계, 커뮤니티로부터 프롬프트 컨텍스트를 구축할 수 있다.
이렇게 하면 일반적으로 엔티티에 대한 타깃 쿼리에 대해 로컬 검색을 더 잘 수행할 수 있다.
Local Search는 AI가 추출한 지식그래프의 관련 데이터를 원본 문서의 텍스트 조각(chunk)과 결합하여 답변을 생성한다. 이 방법은 문서에 언급된 특정 엔티티에 대한 이해가 필요한 질문(ex. 카모마일의 치유 특성은 무엇인가요?)에 적합하다.
1.1 Entity-based Reasoning
Local Search는 지식 그래프의 구조화된 데이터 + 입력 문서의 비구조화된 데이터를 결합하여, 질의 시점에 관련 엔티티 정보를 LLM 컨텍스트에 추가한다.
1.2 Methodology
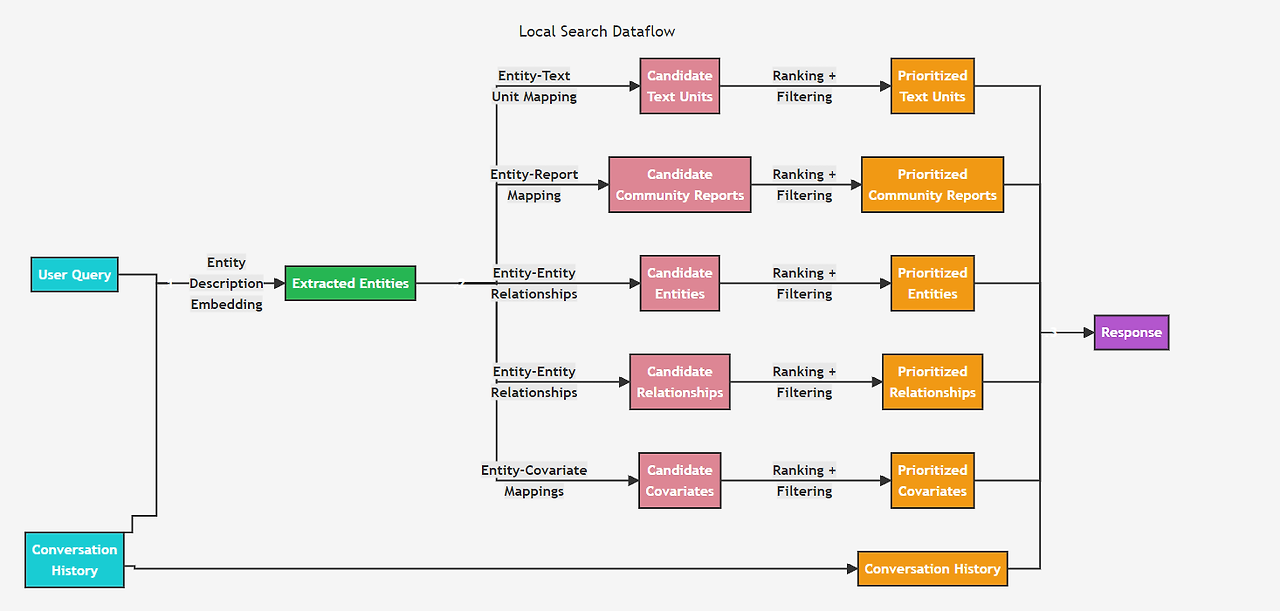
사용자의 질의와, 선택적으로 대화 내역을 바탕으로, Local Search는 지식 그래프에서 사용자 입력과 의미적으로 관련된 엔티티 집합을 식별한다.
이러한 엔티티는 지식 그래프에 접근하는 출발점 역할을 하고, 연결된 엔티티, 관계, 엔티티 공변량(claim), 커뮤니티 보고서와 같은 추가적인 관련 정보를 추출할 수 있도록 한다. 또한, 식별된 엔티티와 연관된 원본 문서의 관련 텍스트 조각도 추출한다. 그런 다음 이 후보 [1]데이터 소스들은 하나의 미리 정의된 크기의 컨텍스트 창에 맞도록 우선순위를 정하고 필터링되며, 이를 통해 사용자 질의에 대한 응답을 생성한다.
[1]
후보 텍스트 유닛, 커뮤니티 보고서, 엔티티, 관계, 공변량 등이 각각의 랭킹 및 필터링 과정을 통해 중요한 정보로 우선순위가 매겨지고, 이 중 가장 중요한 정보들이 선택되어 사용자에게 제공될 답변을 구성하게 된다.
1. 사용자 질의(User Query): 사용자의 질문이 입력된다.
2. 추출된 엔티티(Extracted Entities): 질문과 연관된 엔티티들이 지식 그래프에서 추출된다.
3. 후보 데이터 소스들(Candidate Data Sources): 추출된 엔티티들과 관련된 텍스트, 보고서, 엔티티 관계, 공변량 등의 데이터들이 수집된다.
4. 우선순위 지정 및 필터링: 이 데이터들이 관련성과 중요도에 따라 랭킹이 매겨지고 필터링되어, 미리 정의된 크기의 '컨텍스트 창'에 맞도록 정리된다. 이 '컨텍스트 창'은 사용자가 이해할 수 있는 양의 정보만 포함되도록 제한된 크기를 의미한다.
5. 응답(Response): 최종적으로 필터링된 정보가 사용자에게 응답으로 제공된다.2. Global Search
글로벌 검색은 각 엔터티 커뮤니티의 미리 계산된 요약을 사용하여 답변을 생성한다.
이는 모든 커뮤니티에 질문을 한 다음 전체 요약 답변으로 롤업하는 방식으로 이루어진다. 일반적으로 이 방식은 직접 참조하지 않는 광범위한 주제별 질문에 대해 글로벌 검색을 더 잘 수행함.
일치하는 항목의 순위 지정, 컨텍스트 윈도우 크기 제한 관리 등의 측면에서 좀 더 자세한 내용은 문서와 코드에서 확인할 수 있다.
Global Search는 AI가 생성한 모든 커뮤니티 보고서를 map-reduce 방식으로 검색하여 답변을 생성한다. 이 방법은 리소스를 많이 소모하지만, 데이터셋 전체에 대한 이해가 필요한 질문(ex. 이 노트북에서 언급된 허브들의 가장 중요한 가치들은 무엇인가요?)에 대해 종종 좋은 응답을 제공한다.
2.1 Whole Dataset Reasoning
기본 RAG는 데이터셋 전반에 걸친 정보를 집계하여 답변을 구성해야 하는 질의에 대해 어려움을 겪는다. 예를 들어, "데이터에서 상위 5개의 주제는 무엇인가요?"와 같은 질문은 기본 RAG가 데이터셋 내에서 의미적으로 유사한 텍스트 콘텐츠에 대해 벡터 검색을 수행하기 때문에 제대로 작동하지 않는다. 질의에 맞는 올바른 정보를 찾을 지침이 부족하기 때문이다.
그러나 GraphRAG를 사용하면 이러한 질문에 답변할 수 있다. LLM이 생성한 지식 그래프의 구조는 데이터셋의 구조(따라서 주제들)에 대해 알려주기 때문에, 데이터셋을 의미 있는 의미적 클러스터로 조직할 수 있다. 이 클러스터들은 미리 요약되어 있으며, Global Search를 통해 LLM은 이러한 클러스터들을 사용해 사용자 질의에 대한 주제를 요약할 수 있다.
2.2 Methodology
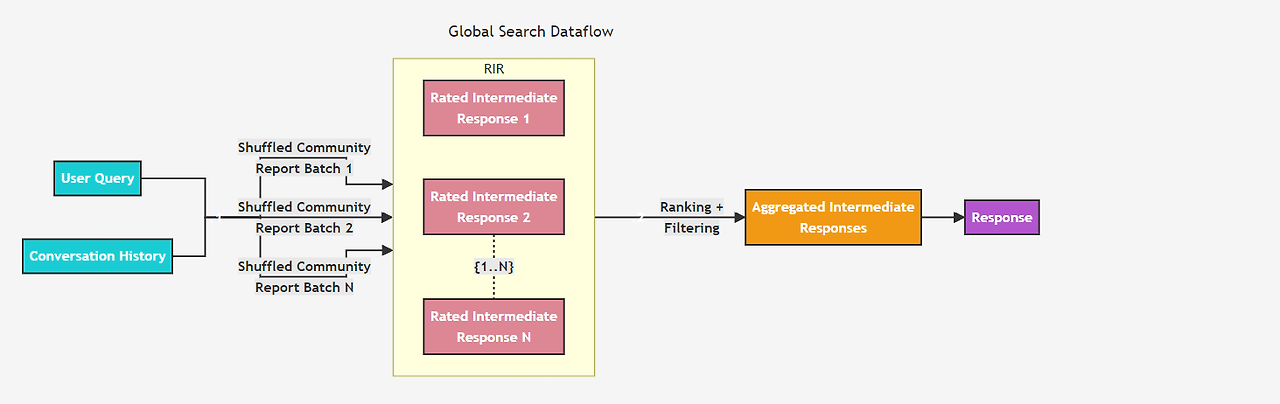
사용자의 질의와 선택적으로 대화 기록을 기반으로, Global Search는 그래프의 커뮤니티 계층 구조에서 지정된 수준의 LLM이 생성한 커뮤니티 보고서들을 컨텍스트 데이터로 사용하여, 맵리듀스 방식으로 응답을 생성한다.
Map단계에서는 커뮤니티 보고서들이 미리 정의된 크기의 텍스트 조각으로 분할된다. 각 텍스트 조각은 중간 응답을 생성하는 데 사용되며, 중간 응답에는 각 점에 대해 중요도를 나타내는 수치가 포함된 목록이 생성된다.Reduce단계에서는 중간 응답에서 가장 중요한 점들만 필터링하여 최종 응답을 생성하는 데 필요한 컨텍스트로 사용된다.
글로벌 검색의 응답 품질은 커뮤니티 보고서의 출처가 되는 커뮤니티 계층의 수준에 따라 크게 영향을 받을 수 있다. 하위 계층의 보고서는 더 상세한 내용을 제공하여 더 철저한 응답을 생성할 수 있지만, 보고서의 양이 많아짐에 따라 응답 생성에 필요한 시간과 LLM 자원이 증가할 수 있다.
3. 질문 생성
질문 생성은 모델에서 분석의 시작점을 제공하려는 사용 사례에 유용할 수 있다.
이는 모델이 색인된 모든 콘텐츠에 액세스할 수 있고 사람이 읽는 것에 비해 빠르게 요약할 수 있기 때문에 유용하다.
또한 질문 생성은 이전 사용자 질문을 입력으로 받아 관련성 있는 다음 질문을 제안할 수 있다.
이전 대화 기록이 없을 때 맥락을 구축하기 위한 출발점으로, 질문 생성은 순위에 따라 상위 k개의 엔터티를 검색한다(순위는 노드 등급으로 계산되므로 가장 많이 연결된 상위 k개의 엔터티를 효과적으로 검색할 수 있음).
이러한 의미에서 엔티티를 진입점으로 사용하기 때문에 로컬 검색과 매우 유사하게 작동한다.
Question Generation 기능은 사용자의 질의 목록을 바탕으로 다음 후보 질문들을 생성한다. 이는 대화에서 후속 질문을 생성하거나 조사자가 데이터셋을 더 깊이 탐구하기 위해 질문 목록을 생성하는 데 유용하다.
3.1 Enityt-based Question Generation
Entity-based Question Generation은 지식 그래프의 구조화된 데이터와 입력 문서의 비구조화된 데이터를 결합하여 특정 엔티티와 관련된 후보 질문을 생성하는 방법이다.
3.2 Methodology
사용자의 이전 질문 목록을 바탕으로, 질문 생성 방법은 Local Search에서 사용되는 동일한 컨텍스트 구축 방식을 사용하여 엔티티, 관계, 공변량, 커뮤니티 보고서 및 원본 텍스트 조각을 포함한 관련 구조화 및 비구조화 데이터를 추출하고 우선순위를 매긴다.
그런 다음 이러한 데이터 기록들을 하나의 LLM 프롬프트에 맞춰 정리하여, 데이터에서 가장 중요한 정보나 긴급한 주제를 나타내는 후보 후속 질문을 생성한다.
Query CLI
python -m graphrag.query --config <config_file.yml> --data <path-to-data> --community_level <comunit-level> --response_type <response-type> --method <"local"|"global"> <query>
CLI Arguments
--config <config_file.yml>: 쿼리를 실행할 때 사용할 구성 YAML 파일이다. 이 옵션을 사용하면 아래의 환경 변수가 적용되지 않는다.
--data <path-to-data>: 인덱서를 실행한 후 생성된 .parquet 출력 파일이 포함된 폴더다.
--community_level <community-level>: Leiden 커뮤니티 계층 구조에서 커뮤니티 보고서를 로드할 커뮤니티 레벨을 설정한다. 값이 클수록 더 작은 커뮤니티의 보고서를 사용한다. 기본값: 2
--response_type <response-type>: 응답의 유형 및 형식을 설명하는 자유 형식의 텍스트로, 예를 들어 Multiple Paragraphs, Single Paragraph, Single Sentence, List of 3-7 Points, Single Page, Multi-Page Report 등 다양하게 설정할 수 있다. 기본값: Multiple Paragraphs
--method <"local"|"global">: 쿼리에 답변할 때 사용할 방법으로, 로컬 또는 글로벌 중 하나를 선택한다.
--streaming: LLM 응답을 스트리밍 방식으로 반환한다.
Example) GraphRAG ver_0.3.0
python -m graphrag.query --root (./graphragtest_01 그래프레그 폴더 위치)
--config (settings.yaml 위치) --data (./artifacts 폴더 위치)
--response_type "single paragraph" --method local "What ingredient has the effect of calming redness?"Example) GraphRAG 최신
openaitest_0209 폴더 안에 input 폴더를 만들고 그 안에 그래프레그에 학습시킬 데이터를 넣고 init으로 지정한다.
python3 -m graphrag init --root ./openaitest_0209init 되면 .env, settings.yaml 등 생겨나는데 전부 설정한 뒤
python3 -m graphrag index --root ./openaitest_0209이렇게 입력하고 실행하면 된다.
Output
The ingredient that has the effect of calming redness is Hippophae Rhamnoides Fruit Extract, which is featured in the Sea Buckthorn Vital 70 Cream by PURITO. This extract is known for its beneficial properties in skincare, specifically for reducing redness and providing nourishment to promote skin health [Data: Entities (4)].
Additionally, products like the Mushroom Collagen Ampoule by I'm from and the Dermide Balancing Barrier Balm by PURITO contain ingredients like Tremella Fuciformis Extract and Centella Asiatica Extract, which are also associated with redness-reducing effects [Data: Entities (4); Sources (10); Sources (10)].
