일정
- 주제 선택 : 2024. 10. 07 (월) 14:00까지
- 최종 제출 마감 : 2024. 10. 11. (금) 11:00까지
- 과제 발표회 : 2024. 10. 11. (금) 14:00 ~ 17:00
과제 목표 및 진행 사항 안내
1️⃣ 과제 목표
목적 : “주제를 선택하여 SQL을 활용해 EDA 해보기”
EDA? 수집한 데이터가 들어왔을 때, 이를 다양한 각도에서 관찰하고 이해하는 과정입니다.
→ EDA (Exploratory Data Analysis) 탐색적 데이터 분석이라고 부릅니다.
→ 데이터를 분석하기 전, 그래프나 통계적인 방법으로 자료를 직관적으로 바라보는 과정
[SQL 활용 범위] 강의 포함 / 미포함
- 데이터 추출 및 탐색
SELECTDISTINCT - 데이터 필터링 및 조건부 검색
WHEREBETWEENLIKEINNOT - 데이터 집계 및 그룹화
GROUP BYHAVING - 통계량 계산
COUNTSUMAVGMINMAX - 데이터 변환
JOINUNION - 데이터 정렬 및 분류
ORDER BY - 데이터 변형 및 계산
CASE WHENIF
2️⃣ 주제 선택
선택[이커머스] 이커머스 이벤트 히스토리를 활용한
효과적인 광고 노출 전략 세우기
공통 주제 : 제공된 데이터를 활용하여 SQL 기능들을 다양하게 활용하기
[세부 목표]
- 유저 활동이 제일 활발한 시간대 구해하기
- 장바구니 이탈율이 높은 아이템들의 공통점 구하기
- 구매 및 장바구니 추가 횟수에 따른 인기 브랜드 분석하기
- 아이템 금액 / 구매 횟수로 매출전략 파악하기
- 아이템 별 / 아이템 카테고리 별 의존도 분석하기
- 가격 대비 구매 전환율 (장바구니 > 구매) 조사하기
- 이 달의 베스트 상품 정하고 타당한 기준 수립하기
현재 데이터로 추출하기 어려운 주제 제외
카테고리별 / 아이템 구매 주기 & 재구매율 파악영구 사용자와 임시사용자의 행동 차이 분석?
이유 : 일반적인 제품 수명보다 짧은 기간의 데이터(10~2월)로는 파악하기 어려운 주제
이유 : 영구 사용자와 임시 사용자의 분류 기준이 모호함
3️⃣ 과제 진행
진행 순서
-
2번 과제 선택에서 주제를 선택합니다 ✅
-
선택된 주제에 데이터를 확인하고 SQL로 분석할 수 있는 환경을 설정합니다.(DBeaver 등등)
-
제공된 데이터를 주어진 [SQL 활용 범위] 안에서 EDA를 진행합니다.
- SQL 활용이 어렵다면 아래 [SQL 활용 가이드]를 참고해주세요.
-
추가로 세부 주제를 자유롭게 설정하여 해당 주제에 대한 데이터 분석을 진행합니다.
[SQL 활용 가이드]
1. 데이터 추출 및 탐색
- 목적: 데이터베이스에서 원하는 데이터를 추출하고 필터링하여 특정 부분 확인
- 예시:
- 특정 날짜에 판매된 제품 리스트 추출
- 특정 조건에 맞는 사용자 목록 탐색- 중복 데이터 제거:
- 주요 명령어:DISTINCT
- 목적: 중복된 데이터 제거하여 고유한 값만 추출
- 예시: 특정 제품 카테고리의 고유한 제품 리스트 조회
2. 데이터 필터링 및 조건부 검색
- 주요 명령어:
WHERE,NOT- 조건부 검색 기법:
-BETWEEN: 범위 검색
-LIKE: 패턴 검색
-IN: 특정 값 목록 검색- 예시:
- 최근 1년 동안 매출이 1,000만 원 이상인 고객 목록 추출
- 특정 조건을 만족하지 않는 데이터 검색 (예: 매출이 500만 원 미만인 고객)
3. 데이터 집계 및 그룹화
- 주요 명령어:
GROUP BY,HAVING- 목적: 데이터를 그룹별로 집계하고 요약
- 예시:
- 각 지역별 매출 총합
- 시간대별 자전거 이용량 평균
4. 통계량 계산
- 집계 함수:
COUNT,SUM,AVG,MIN,MAX- 목적: 기초 통계량 계산
- 예시:
- 상품의 평균 판매량
- 최고 매출을 기록한 고객 조회
5. 데이터 변환
- 주요 명령어:
JOIN,UNION,서브쿼리- 목적: 여러 테이블을 결합하거나 복잡한 데이터 처리
- 예시:
- 고객 테이블과 구매 테이블을 결합해 고객별 구매 이력 분석
- 두 개의 다른 테이블에서 같은 구조의 데이터를 결합하여 전체 사용자 목록 조회
6. 데이터 정렬 및 분류
- 주요 명령어:
ORDER BY- 목적: 특정 열을 기준으로 오름차순 또는 내림차순 정렬
- 예시:
- 가장 많이 팔린 제품 상위 10개 리스트
- 가장 많이 대여된 자전거 공유소 순위
7. 데이터 변형 및 계산
- 주요 명령어:
CASE WHEN- 목적: 특정 조건에 따라 데이터 분류 또는 계산
- 예시:
- 매출이 500만 원 이상인 고객을 VIP로 분류
- 날짜를 년, 월, 일로 분리하여 분석
데이터 확인
이커머스 이벤트 히스토리 데이터
01. 개요
- 해당 주제는 이커머스에 실제로 일어나는 행동 데이터를 SQL로 활용하여 기초 분석을 진행
- 데이터는 중형 화장품 온라인 스토어의 1개월(2020년 2월)의 행동 데이터를 사용
02. 배경
이커머스란?
전자 상거래(電子商去來, 영어: electronic commerce, e-commerce, eCommerce)는 컴퓨터 등을 이용해 인터넷과 같은 네트워크 상에서 이루어지는 즉, 전자적 매체(시스템)를 이용하여 가상 공간에서 이루어지는, 제품이나 용역을 사고 파는 거래행위이다. 현대의 전자 상거래는 더 넓은 범위에 있어서 전자우편을 사용하기도 하지만, 보통 월드 와이드 웹을 사용한다.
전자 비즈니스(E-business)의 한 부분으로서 인터넷이나 네트워크, 다른 디지털 기술들을 이용해 전자적으로 제품이나 서비스를 사고 파는 것을 말한다. 또한, 전자상거래는 광고, 마케팅, 고객 지원, 배송, 지불 등과 같은 활동들을 포함한다.
- 오픈마켓 : G마켓, 11번가 등등
- 기존 온라인 쇼핑몰과는 다르게 다수의 개인 판매자들이 인터넷에 직접 제품을 마케팅, 업로드하여 상품이나 서비스를 올려 전자 상거래 즉 이커머스가 이루어지는 공간을 의미합니다.
- 온라인 쇼핑몰에서 중간 유통이윤을 생략할 수 있어 구매자와 판매자를 직접 연결하여 기존보다 저렴한 가격으로 제품을 구매할 수 있는 대표적인 이커머스 채널입니다.
- 소셜커머스 : 쿠팡, 인스타그램 등등
- 소셜 커머스(social commerce)는 소셜 미디어와 온라인 미디어를 활용하는 전자상거래의 일종이다. 좀더 간단히 말하자면, 전자상거래를 통한 매매 과정에서 SNS를 활용하는 것이다.
- 이커머스는 전자 상거래로 인터넷과 같은 네트워크 상에서 이뤄지는 거래행위입니다.
- 그렇기에 해당 거래가 이뤄지기 전에 소비자들이 보여주는 행동 패턴들이 있습니다.
- 플랫폼에서 해당 상품을 확인하고 장바구니에 상품을 추가하거나 삭제하거나 해당 이벤트들이 반복적으로 이뤄지다가 최종적으로 구매를 하거나 안합니다.
- 이러한 행동들을 분석하여 패턴을 확인하고 유의미한 분석을 진행해봅니다.
03. 설명
- 이 파일에는 중형 화장품 온라인 스토어의 1개월(2020년 2월)의 행동 데이터가 포함되어 있습니다.
- 파일의 각 행은 이벤트를 나타냅니다.
- 모든 이벤트는 제품 및 사용자와 관련이 있습니다.
- 각 이벤트는 제품과 사용자 간의 다대다 관계와 같습니다.
| Property | - | 설명 |
|---|---|---|
| event_time | 이벤트 시간 | 이벤트가 발생한 시간(UTC). |
| event_type | 이벤트 유형 | 이벤트의 유형은 총 4가지 *Event types로 구성되어있습니다. |
| product_id | 제품_아이디 | 제품의 ID |
| category_id | 카테고리_아이디 | 제품 카테고리 ID |
| category_code | 카테고리_코드 | 제품의 카테고리 택소노미(코드명)는 가능하다면 만들 수 있습니다. 일반적으로 의미 있는 카테고리에 존재하고 다양한 종류의 액세서리에는 건너뜁니다. |
| brand | 상표 | 브랜드 이름의 소문자 문자열. 놓칠 수 있음. |
| price | 가격 | 제품의 부동 가격. 현재. |
| user_id | 사용자_아이디 | 영구 사용자 ID. |
| user_session | 사용자 세션 | 임시 사용자의 세션 ID. 각 사용자 세션에 대해 동일합니다. 사용자가 긴 일시 정지에서 온라인 스토어로 돌아올 때마다 변경됩니다. |
Event type 컬럼의 이벤트 유형
view: 사용자가 제품을 보았습니다cart: 사용자가 장바구니에 제품을 추가했습니다.remove_from_cart: 사용자가 장바구니에서 제품을 제거했습니다.purchase: 사용자가 제품을 구매했습니다
04. 데이터
원본 데이터 확인 : ( eCommerce Events History in Cosmetic Shop )
데이터 타입 확인
| 컬럼명 | Data Type |
|---|---|
| event_time | varchar(32) |
| event_type | varchar(16) |
| product_id | int |
| category_id | int |
| category_code | varchar(64) |
| brand | varchar(16) |
| price | double |
| user_id | int |
| user_session | varchar(64) |
결측치 확인 & 시각화
| 컬럼명 | NULL Count | NULL Percentage |
|---|---|---|
| event_time | 0 | 0 |
| event_type | 0 | 0 |
| product_id | 0 | 0 |
| category_id | 0 | 0 |
| category_code | 4079497 | 98.143110 |
| brand | 1825908 | 43.927055 |
| price | 0 | 0 |
| user_id | 0 | 0 |
| user_session | 1055 | 0.025381 |
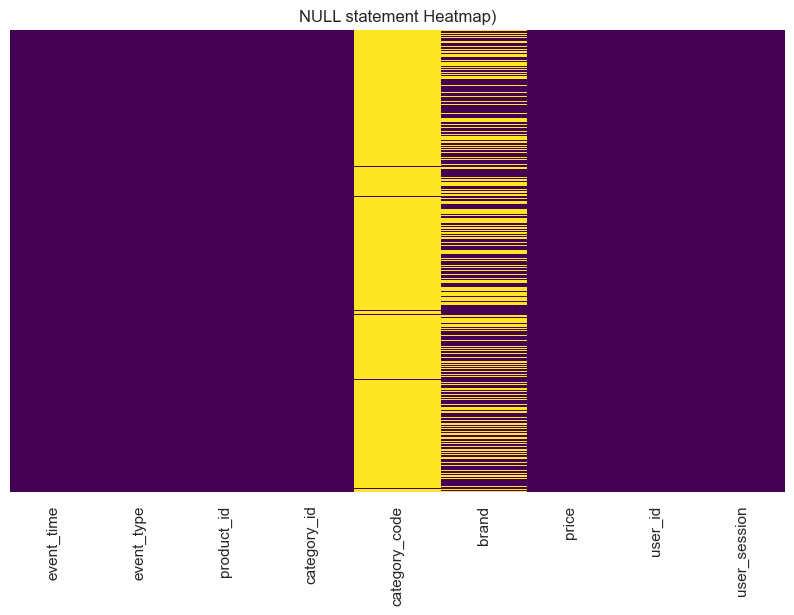
- category_code 칼럼의 높은 결측치 확인
버려야 하는 데이터의 기준
분석 목적에 대한 기여도:
category_code가 분석 결과에 크게 기여하지 않는다면 버릴 수 있습니다. 특히 결측치 비율이 50% 이상일 경우, 그 변수는 분석에 큰 영향을 미치지 않을 가능성이 높습니다.
결측치의 대체 가능성:
대체할 수 없는 경우, 즉 결측치를 다른 정보로 대체할 방법이 전혀 없을 때 데이터를 버리는 것이 좋습니다.
데이터의 신뢰성:
결측치가 너무 많거나 특정 패턴이 없다면 데이터의 신뢰성을 잃을 수 있습니다. 이 경우, 해당 변수를 제거하는 것이 바람직합니다.
ㅇ
1.5 결측치 처리 전 확인 사항
- 결측치 처리 어떻게 할거냐?
결측치 처리 방법 1.2.3.4 가 있다. ~방법,~방법 쓸거다
데이터 확인 정보 종합
- 제품의 ID는 있지만 제품명이 없다. 제품을 분류 하기 힘듦.
- 결측치 많은 항목은 분석에 쓸 수 없으니 제외.
분석환경 설정
DBeaver 설정
1. DBeaver 에 2020-Feb.csv 불러오기
결측치 처리
앞서 선택한 ~ 방법으로 처리할 예정이다.
분석 진행
아이템 구매 단계
SELECT
product_id,
view_count,
purchase_count,
purchase_ratio
FROM (
SELECT
product_id,
COUNT(CASE WHEN event_type = 'view' THEN 1 END) AS view_count,
COUNT(CASE WHEN event_type = 'purchase' THEN 1 END) AS purchase_count,
COUNT(CASE WHEN event_type = 'purchase' THEN 1 END) /
COUNT(CASE WHEN event_type = 'view' THEN 1 END) AS purchase_ratio
FROM
eCommerce.`2020_Feb`
GROUP BY
product_id
) AS sub
WHERE
purchase_ratio IS NOT NULL
ORDER BY
view_count DESC;