데이터 리터러시, 데이터 문해력
1. 데이터 리터러시의 기초
1.1. 데이터 리터러시의 정의
1.1.1 데이터 리터러시란?
- 데이터를 읽는 능력
- 데이터를 이해하는 능력
- 데이터를 비판적으로 분석하는 능력
- 결과를 의사소통에 활용할 수 있는 능력
결국 데이터 리터러시랑 데이터 수집과 원천을 이해하고
데이터에 대한 활용법을 이해하고
데이터를 통한 핵심지표를 이해 하는 것을 말함.
-> 데이터 리터러시는 올바른 질문을 던질 수 있도록 만들어짐.
올바른 질문? 데이터 왜 분석하는지, 어떤 결과를 기대하고 하는지
뚜렷한 목적을 생각하게 도와줌.
1.2 데이터 분석에 대한 착각
- 데이터를 잘 분석하면 문제, 목적, 결론이 나올 것이라고 생각
- 데이터를 잘 가공하면 유용한 정보를 얻을 수 있다고 생각
- 분석에 실패하면 방법론, 스킬이 부족한 것이라고 생각
2. 데이터 분석의 첫걸음: 문제 정의
2.1 데이터 분석에 실패하는 이유
풀고자 하는 문제를 명확하게 정의하지 않고 나서 데이터 분석 작업에 먼저 뛰어들어 마주하는 여러가지 문제들을 발견할 수 있었다. 이번 단원에서는 문제정의란 무엇인지, 어떤 방식으로 풀어나갈 수 있는지, 이것은 왜 하는지에 대해서 알아보자.
2.1.1 문제 정의란
- 데이터 분석 프로젝트의 성공을 위한 초석
- 분석하려는 틀정 상황이나 현상에 대한 명확하고 구체적인 진술
- 프로젝트의 목표를 설정하고 분석 방향을 결정
2.1.2 문제 정의 사례
잘못된 문제 정의
상황 : 패션플랫폼 A, 매출 증가가 목표
문제 정의 : 매출을 어떻게 늘릴 수 있을까?
- 문제 정의는 했지만 모호하고 구체적이지 않음
- 어떤 고객층, 제품에 초점을 맞출지에 대한 명확한 지침이 없음
- 데이터 분석할 시 방향성을 잡기가 어려움
옳은 문제 정의
상황 : 패션플랫폼 A, 매출 증가가 목표
문제 정의 : 지난 6개월 동안 25~35세 여성 고객층의 구매 전환율이 급격히 감소했다.
이 고객층의 전환율을 현재의 2%에서 5%로 끌어올리기 위해 어떤 마케팅 전략을 적용할 수 있을까?
구매전환율(%) = 구매고객수/방문고객수*100
2.1.3 문제 정의 예제
상황
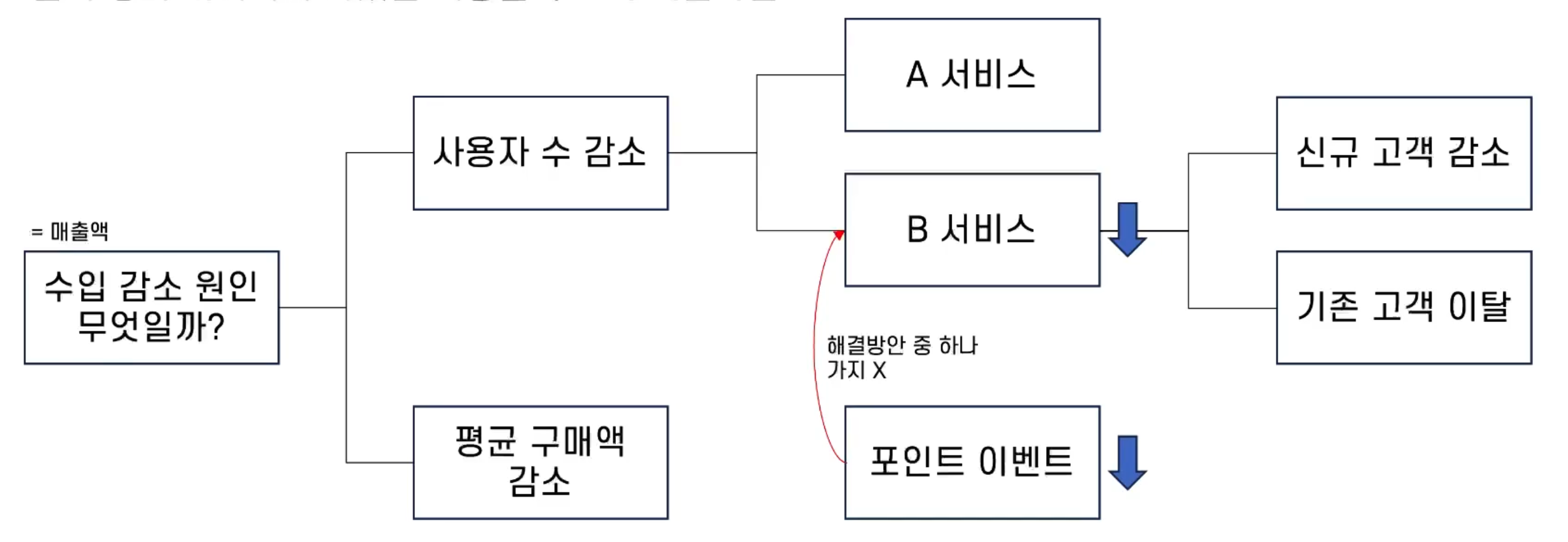
3개월 전부터 자사 제품의 사용자 수가 감소하고 있다.
사용자 수를 늘리기 위한 포인트 이벤트를 하고 있지만 효과가 없어 보인다. 또한 자사 제품 내 서비스 중 A보다 B가 더 안 좋은 상황이다. 사용자가 줄었기 때문에, 수입도 감소하고 있다.
문제 정의
-
사용자 수가 감소하고 있다.
- 사용자 수는 충분히 생각해볼 문제이나 결과적으로 풀고자 하는 것이 수입 감소라고 한다면, 사용자 수는 문제가 아닌 원인이 된다.
-
이벤트 효과가 없다.
- 이벤트 효과가 없다는 것은 추분히 살펴볼만 하다. 하지만 이벤트가 효과적이지 않기 때문에 발생하는 문제가 근본적으로 해결되어야 하지 않을까?
-
A서비스 보다 B 서비스가 상황이 안 좋아진 이유를 살펴보아야 한다
- 위 내용은 분석 과정 중 확인해 봐야 할 내용인 것 같다. 그러나 이것을 근본적인 문제라고 하기에는 어렵다.
-
수입이 감소한 것이 문제다
- 궁극적인 무제의 관점에서 수입의 감소는 매우 중요한 문제라고 판단된다. 그러나 단어의 정의에 있어 더 명확할 필요가 있다. 가령 수입이 의미하는 것이 매출액인지, 순이익인지 등을 고려해야 한다.
결과적으로 문제 정의는 더 복잡하고 시간이 소요되는 과정이다.
항상 문제를 올바르게 정의 하였는가? 라는 물음을 가지고 임해야 함.
2.1.4 문제 정의 방법론
MECE
MECE (Mutually Exclusive, Colectively Exhaustive)
- 문제 해결과 분석에서 널리 사용되는 접근 방식
- 문제를 상호 배타적(Mutually exclusive)이면서, 전체적으로 포괄적(collectively exhaustive)인 구성요소를 나누는 것
- MECE를 통해 복잡한 문제를 체계적으로 분해하고, 구조화된 방식으로 분석할 수 있음
잘못된 MECE 예시
사람- 남성, 여성, 아저씨로 나눔 : 남성과 아저씨가 중복영화 장르- 액션, 스릴러, 공포로 나눔 : 멜로, 코메디 등 누락 장르 존재자동차- SUV, 세단, 쿠페, 현기차로 나눔 : 분류 기준이 다름. 자동차 종류 vs 브랜드3학년 3반 학급원- 영어 우수 학생, 수학 우수 학생으로 나눔 : 분류 기준이 불명확, 서로 중복되고 누락된 정보가 존재
2.1.5 문제 로직 트리(Logic Tree)
- MECE 원칙을 기반으로 복잡한 문제를 더 작고 관리하기 쉬운 하위 문제로 분해하는데 사용
- 상위 문제로부터 시작하여 하위 문제로 계층적 접근
- 일반적으로 도표 형식으로 표현되어 쉽게 파악할 수 있음
로직트리를 활용하여 문제정의 해보기
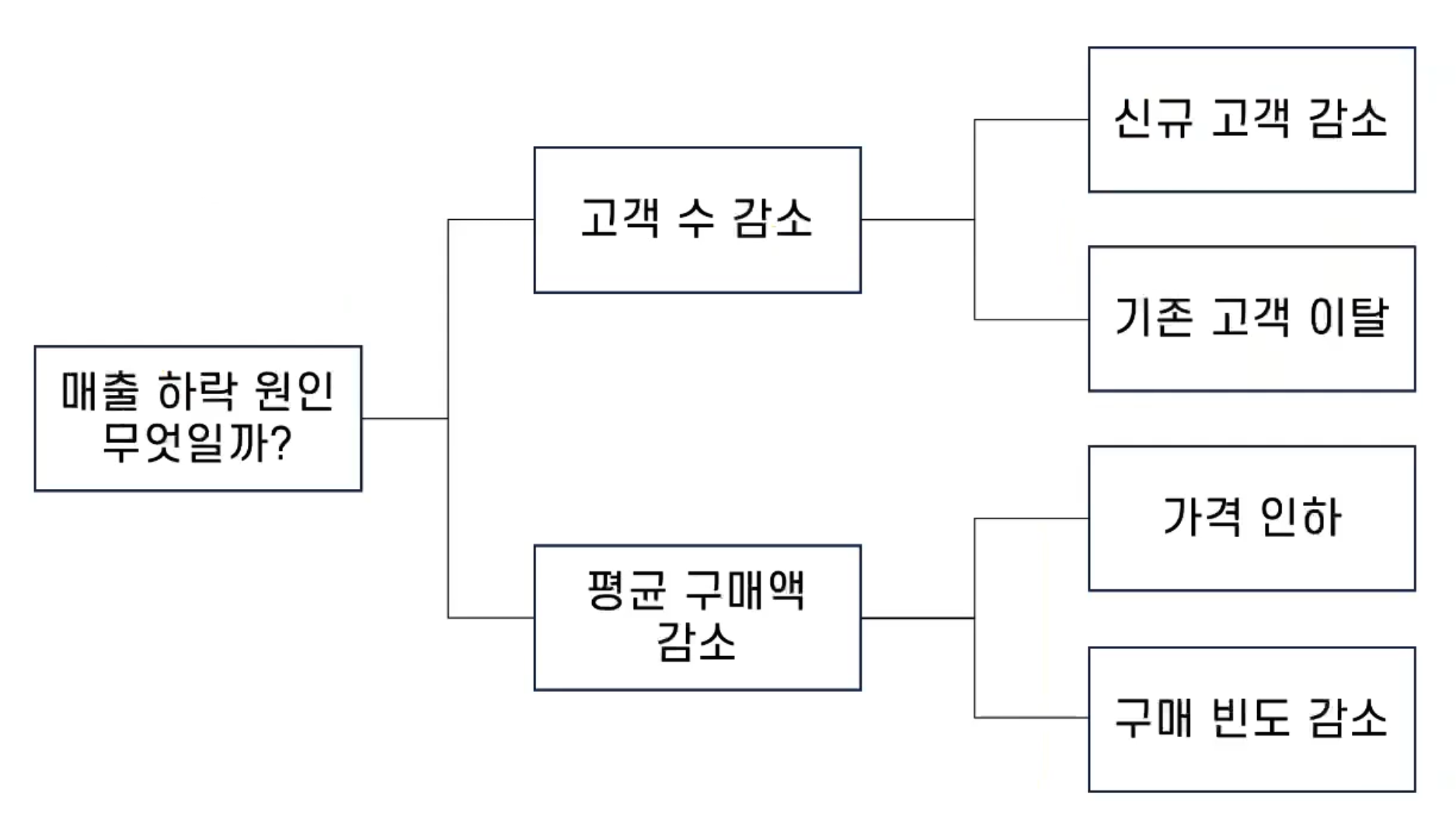
문제 정의 예제에서 나왔던 내용을 구조화 해본다면?
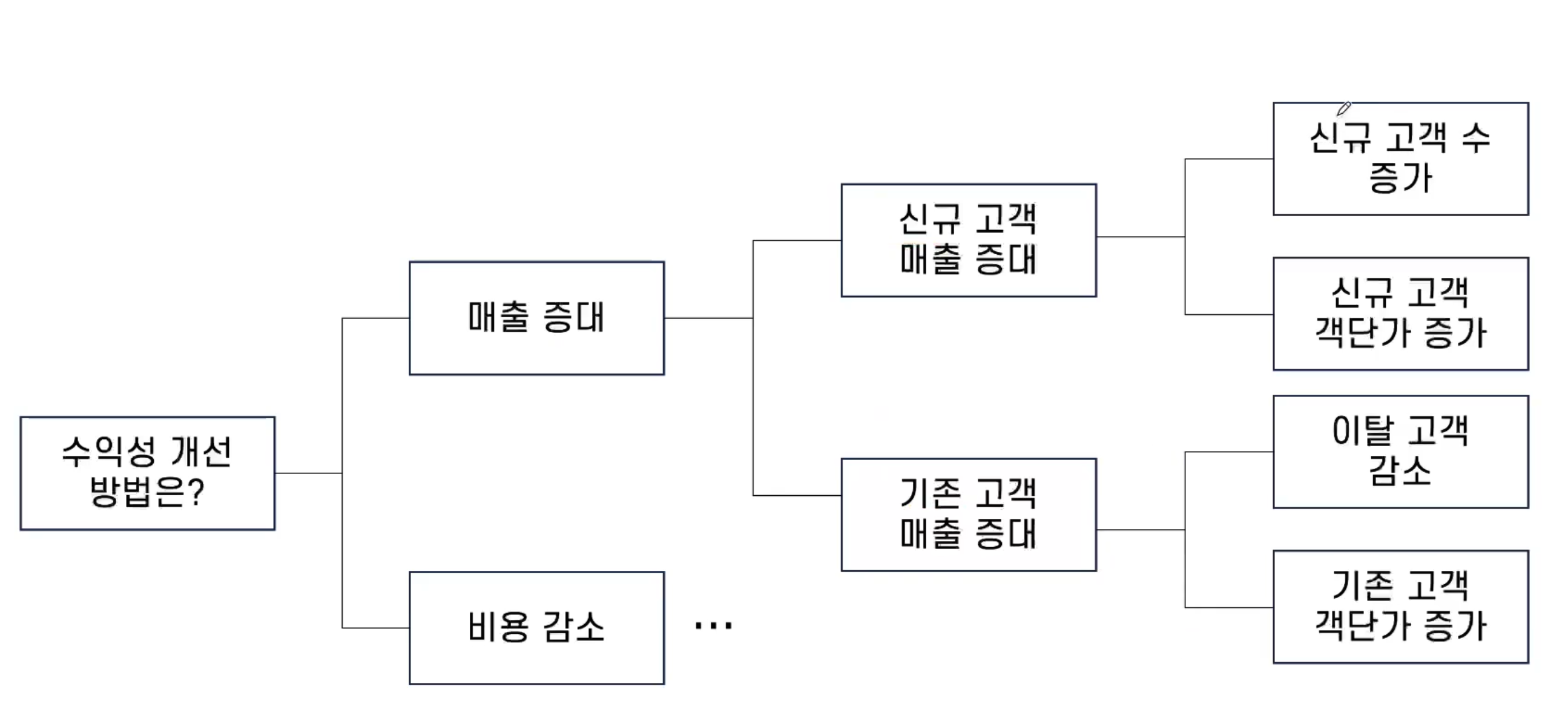
로직트리 예제
수익성 개선 방법에 대한 로직트리를 그려보자.
2.1.6 로직트리 Cheat Sheet
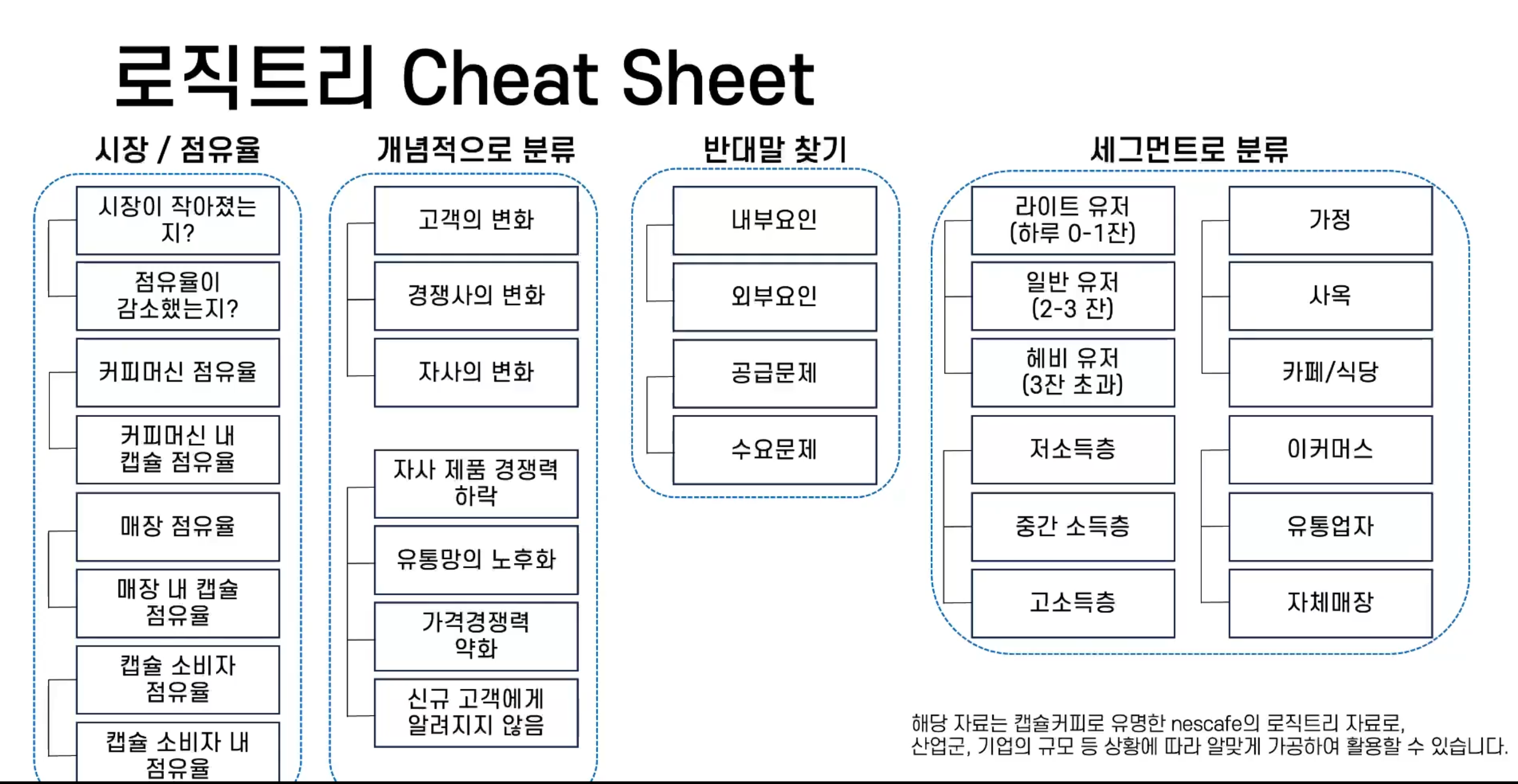
네스카페의 로직트리 자료로 실제로 활용할 땐 개념을 바꿔서 사용해야 함.
(비즈니스에 따라서 정의가 달라짐)
앱 서비스에 적용하기 위해 변경해 본다면?
고객 세그먼트 분류
- 라이트 유저, 일반유저, 헤비유저 >> 구매 전 고개, 재구매 고객, VIP고객으로 변경
점유율 분야
- 캡슐 점유율 > 해당 서비스 시장 점유율로 변화
2.1.7 문제정의 정리 & 팁
문제정의 왜 하는 것인가?
- 문제 정의는 풀고자 하는 것을 명확하게 정의하고
- 이것을 해결하기 위한 데이터 분석의 방향성을 정하고
- 결과를 정리하고 해석하여
- 더 나아지기 위한 새로운 액션 플랜을 수립하기 위함
문제정의의 핵심은 So What?, Why so?
So What?
- 수집한 정보와 소재에서 '결국 어떻다는 것인지'를 알아내는 작업
- 그래서, 따라서, 이렇듯 앞에 오는 정보나 소재에서 과제의 답변에 맞는 중요한 핵심을 추출하는 작업
- 나타난 현상을 바탕으로 과제에 비추어 말할 수 있는 내용의 핵심을 추출하는 작업
Why so?
- 왜 그렇게 말할 수 있는지
- 구체적으로 무슨 뜻인지를 검증하고 확인하는 작업
- So What?한 요소의 타당성을 자료 전체 혹은 그룹핑한 요소로 증명할 수 있다는 사실을 검증하는 작업
2.1.8 문제 정의와 관련된 팁
- 결과를 공유하고자 하는 사람이 누구인지 정의하기
- 결과를 통해 원하는 변화를 생각하기
- 회사 소속이라면, 경영자의 입장에서 보려고 노력
- 많은 사람들과 의견을 나눠보는 것도 방법
- 반드시 혼자서 오래 고민해보는 시간을 가질 것
3. 데이터 분석을 위한 핵심 지표 설정
3.1 데이터의 유형
3.1.1 정성적 데이터와 정량적 데이터
정성적 데이터
- 비수치적인 정보로 사람의 경험, 관점, 태도와 같은 주관적인 요소를 포함함
- 대부분 텍스트, 비디오, 오디오 형태로 존재함
- 정형되지 않고 구조화 되어있지 않음
- 데이터를 구조화하기 어렵다
- 새로운 현상이나 개념에 대한 이해를 심화하는데 사용함
정량적 데이터
- 수치적으로 표현되는 정보로 양적인 측정과 분석을 통해 얻을 수 있음
- 데이터가 숫자 형태로 존재하기 때문에 통계적으로 분석하기 쉽다
- 개인의 해석이나 주관이 적게 작용하는 객관성을 가지고 있음
- 지표로 만들기에 용이하다
- 설문조사, 실험, 인구 통계, 지표 분석 등에 활용함
데이터 유형별 비교
| 정량적 데이터 | 정성적 데이터 | |
|---|---|---|
| 유형 | 정형 데이터 반정형 데이터 | 비정형 데이터 |
| 특징 및 관점 | 여러 요소의 결합으로 의미 부여 주로 객관적 내용 | 객체 하나가 함축된 의미 내포 주로 주관적 내용 |
| 구성 및 형태 | 수치나 기호 데이터베이스, 스프레드 시트 | 문자나 언어 웹 로그, 텍스트 파일 |
| 위치 | DBMS, 로컬 시스템 등 내부 | 웹사이트, 모바일 플랫폼 등 외부 |
| 분석 | 통계 분석 시 용이 | 통계 분석 시 어려움 |
비즈니스 목표를 위해서 두 가지 데이터를 적절하게 활용하는 것이 필요
지표설정과 분석에 활용하기 위한 정량적 데이터를 중점적으로 살펴볼 예정
3.2 지표 설정
3.2.1 지표란?
- 특정 목표나 성과를 측정하기 위한 구체적이고 측정 가능한 기준
- 목표 달성도를 평가하고 전략적 결정에 필요한 핵심 정보를 제공
- 정의한 문제에 대해 정확하게 파악하기 위해서 필요
3.2.2 문제 정의 vs 지표 설정
| 문제 정의 | 지표 설정 |
|---|---|
| 어떤 문제를 풀고자 하였는가? | 어떤 결과를 기대하는가? |
| 둘 이상의 해석이 나오지 않도록 구체적으로 표현하고 정의하였는가? | 정의한 문제를 확인하는데 적합한가? |
3.3 주요 지표 이해하기
3.3.1 Active User (활성유저)
Active User 지표의 역할
우리는 누구를 '활성유저'라고 정의할까?
- 서비스에 들어오는 모든 유저..? x..
- Active User에 대한 정의에 따라 전략과 방향이 달라짐
- Active User에 대한 정의로 '이탈 유저'가 정의됨
- 투자를 위한 서비스 지표에 중요한 역할을 하게 됨
Active User 설정 해보기
-
사이트 진입 유저
- 메인 홈 화면에 진입 시 활성 유저로 정의
- 허들이 가장 낮음
- Active User 지표가 가장 높게 측정됨
- 그러나 해당 유저 대상 액션 효율이 떨어짐
-
사이트 진입 후 추가 행동을 한 유저
- 허들이 두 번째로 낮음
- 사이트에 진입하여 강의 중 하나에 진입한 유저
- 1번 보다 대상 액션 효율이 높을 수 있음
-
서비스의 최종 액션까지 수행한 유저
- 가장 허들이 높음
- 자사 서비스의 Goal 액션을 한 유저
- 자사 서비스의 핵심과 효용성을 경험한 유저
- 해당 유저 대상 액션을 할 때 효율과 이익이 가장 높음
- Active User 지표가 가장 낮게 측정
-
정리
- 정밀도, 허들이 높아질 수록 Active User의 수는 낮아지는 구조
- 정밀도: 측정의 정밀함을 나타내는 정도
- 정밀도, 허들이 높아질 수록 Active User의 수는 낮아지는 구조
우리 서비스만의 Active User를 찾기 위해선?
- 어디까지 경험한 유저가 우리의 활성유저일까?
- 일반유저와 활성유저를 나누는 기준은?
- 유저는 어디서 우리 서비스의 효용성을 느낄까?
- 우리가 핸들링할 수 있는 유저의 사이즈는 얼마나 될까?
그 외 주요 지표 정리
| 지표 | 정의 |
|---|---|
| 전체 Active User | 앱 접속 이력이 있는 유저 |
| 서비스별 Acive User | 서비스별 서브메인이하 추가 액션이 있는 유저 |
| DAU | Daily Active User |
| WAU | Weekly Active User |
| MAU | Monthly Acitve User |
| 이탈유저 (이탈율) | 전체 DAU로 잡혔지만, 각 서비스의 DAU로 잡히지 않은 유저 (비율) |
| CVR(Conversion Rate) | 특정 행동을 한 후, 전환된 비율 |
| CTR(Click Through Rate) | 어떤 페이지에 접근한 후, 특정 요소를 클릭한 비율 |
3.3.2 Retention Ratio (재방문율)
리텐션이란?
회사는 TV광고, SNS 마케팅 등 돈을 주고 데려온 고객들이 서비스를 한 번만 이용하지 않고, 여러번 이용해야 사용한 비용 이상을 고객에게 얻을 수 있다. 고객이 서비스를 지속적으로 이용하고 있는지를 파악할 수 있는 것이 리텐션이다.
Retention Ratio의 역할
- 몇%의 유저가 우리 서비스를 다시 사용하는가?
- 정의: 서비스를 사용한 사람이 다시 서비스를 사용하는 비율 %
- 리텐션이란 한번 획득한 유저가 서비스로 다시 돌아왔는가?에 대한 지표
- 리텐션이 높은 서비스는 획득비용에 투자한 비용을 빠르게 회수할 수 있음
- 리텐션은 서비스(특히 앱서비스) 성장에 있어서 매우 중요한 지표
Retention 더 알아보기
리텐션은 기본적으로는 방문을 기준으로 측정하지만, Active User에서 활성의 기준을 정해줬던 것과 같이, 서비스의 특성에 따라 '활성'의 기준을 다르게 정의할 수 있다.
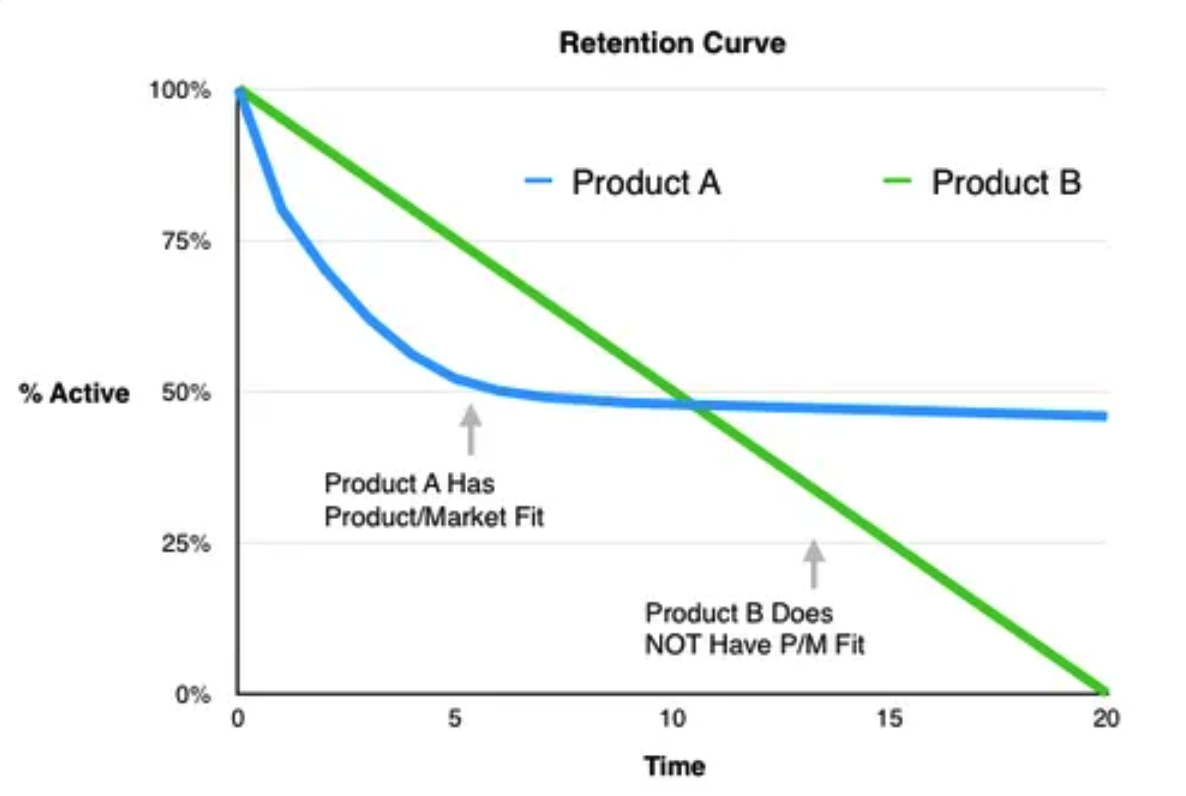
- 일반적으로 리텐션은 시간이 지남에 따라 자연스럽게 감소 (Product B)
- 기울기가 점점 완만해지며 안정화 되는 그래프를 가지고 있다면, 시장에 적합한 서비스라고 할 수 있음 (Product A)
Retention 측정 방법
1) N-Day 리텐션

- 최초 사용일로부터 N일 후에 재방문한 Active User의 비율
- 일반적으로 사용하는 리텐션 지표는 N-Day 리텐션
- 게임, 소셜 등 습관적으로 사용하거나 반복적으로 행동을 유도하는 제품에 적합
- 유저가 Active User로 집계된 최초 날을 Day 0으로 설정
- Day 0에 액티브 상태가 된 모든 유저들의 N일차 리텐션을 계산
- N-Week, N-Month도 가능
N-day 리텐션의 한계
- 위 사용예시에서 튜브는 1월 3일을 제외하고는 전부 방문
- 그렇다면, 1월 3일의 리텐션에도 튜브를 포함하는 게 맞는 것 아닐까?
- 서비스의 사용 주기가 길 경우, N-day 리텐션을 사용하면 실제보다 더 과소평가
- N-day 리텐션은 사용자가 매일 접속하는 서비스에 활용하기 적절한 지표
- 카카오톡
- 인스타그램
- 게임
2) Unbounded 리텐션
- 특정일을 포함하여 그 이후 한 번이라도 재방문한 유저의 비율
- 마지막 방문일 이전에는 방문한 것으로 계산
- 해석: Day5는 5일차 이후에 한 번 더 들어온 유저의 비율
- 유저가 정기적으로 반복해서 방문하는 서비스가 아닐 경우 적합

- Unbounded 리텐션은 이탈률의 반대 개념
- 실제로 방문하지 않았어도, 계산에는 함께 포함
- N-day 리텐션과 비교시 결과값에 큰 차이가 있음
- 사용 빈도가 높지 않은 서비스에 활용하기 적절한 지표
- 채용 사이트
- 쇼핑몰
- 부동산 매물 서비스
- 위와 같이 사용 주기가 좀 더 긴 서비스들에서는 N-day 리텐션을 적용하게 될 경우 불필요한 할인, 푸쉬 메시지 발송 등 잘못된 액션을 할 가능성이 존재
Unbounded 리텐션의 한계
- 다만, Unbounded 리텐션의 경우 1월 6일에 계속 접속하지 않던 무지가 접속할 경우, 이 전의 리텐션 값들이 전부 변동되는 상황이 발생할 수 있음
- 해당 지표는 절대적인 수치보다는 지표가 어떻게 변화하는 지에 대해 트렌드를 보는 용도로 활용하는 것을 권장
1) Bracket 리텐션
- 설정한 특정 기간을 기반으로 재방문율을 측정
- Bracket 리텐션은 N-Day 리텐션을 확장한 개념 > 일/주/월 단위가 아닌 지정한 구간으로 나눔
- 1(0일차) / 2(1-3일차) / 3(4-6일차) / 4(7-11일차)
- 활성유저가 특정한 활동을 위해 각 Bracket 내 서비스에 재방문시 잔존 유저로 해석

- Day 0: 1월 1일 (신규 가입일 or 최초 접속일)
- Day 1~3: 1월 2일 ~ 1월 4일
- Day 4~6: 1월 5일 ~ 1월 7일
- Day 1~3 방문한 유저: 튜브, 어피치, 라이언, 프로도
- Day 4~6 방문한 유저: 튜브, 어피치, 무지
- 하루 정도 서비스에 접속을 안했더라도, 리텐션에 영향을 주지 않기 때문에 기준이 조금 더 널널함
- 서비스 사용주기가 길거나 주기적인 경우 사용하기 적합한 지표
- 식료품 배달 서비스
- 세차 서비스
Retention에 대한 이해
- 리텐션이 높은 세그먼트를 발굴하는 작업이 필요함
- 서비스의 사용 주기에 따라 리텐션 조회 기간을 늘려야 함
- 사후 분석 시에 용이
3.3.3 Funnel (퍼널)
Funnel의 역할
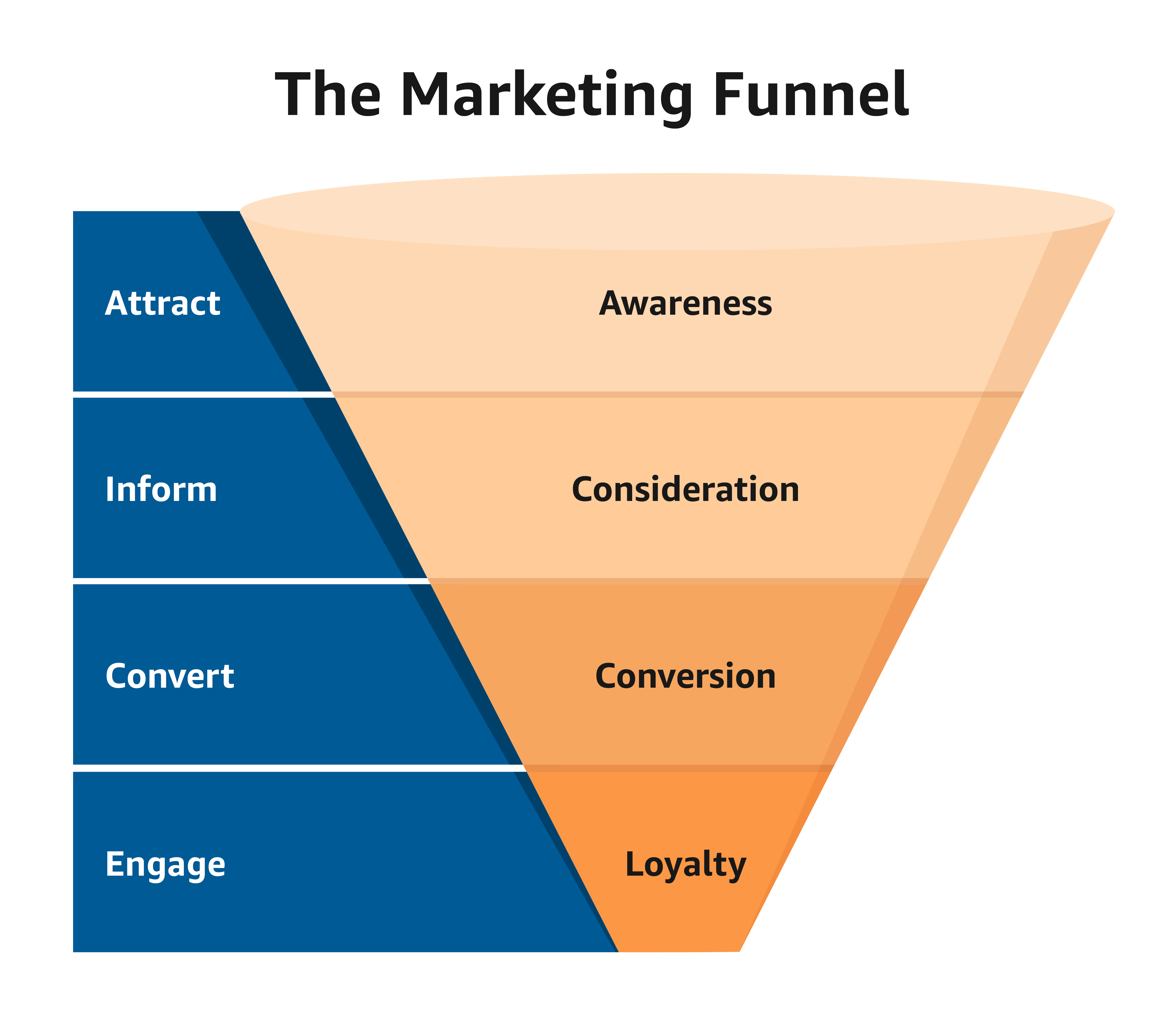
- 유저들이 어디서 이탈하는가?를 확인하기 위한 구조화
- 퍼널은 잠재고객을 유입시키며 최종적인 목표 액션을 달성할 때까지의 과정
- 모든 서비스와 비즈니스는 각 단계로 갈 수록 이용자 수가 줄어들게 됨
- 각 단계의 전환율 (or 첫 유입 대비 전환율)을 측정
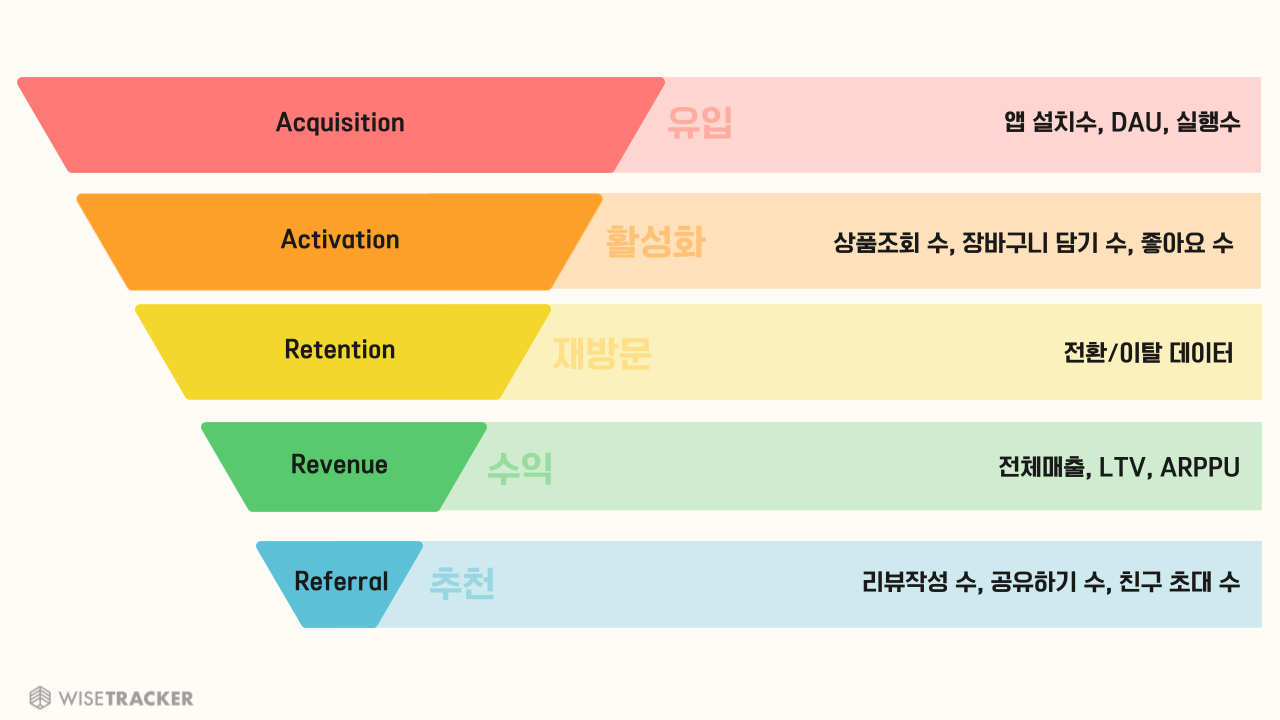
- 디지털 마케팅시 퍼널을 활용하는 프레임워크
- 단계별 전환율을 지표화 하여 서비스 보완 지점을 찾음
- Acquisition: 유입
- Activation: 활성화
- Retention: 재방문(재구매)
- Revenue: 수익
- Referral: 추천
3.3.4 LTV (Life Time Value, 고객 평생 가치)
LTV의 역할
- 해당 유저가 우리에게 평생 주는 이익은 얼마나 될까?를 나타내 지표
- 고객 생애 주기: 한 명의 유저가 서비스를 사용하기 시작하여 이탈할 때까지의 기간
- LTV는 한 명의 유저가 생애 주기 동안 얼마만큼의 이익을 주는지를 정량적으로 지표화 한 것이다.
- LTV는 유저와의 관계를 측정하고, 이를 사업적 이익으로 가져가는데 중요한 지표로
- LTV가 높다는 것은 해당 서비스와 관계가 좋고, 충성도가 높은 고객이 많다는 것

- 신규유저(프로도)가 1월에 서비스에 처음 들어와서 구매를 하다가 이탈함
- 프로도의 LTV는 50000 + 20000 + 5000 = 75000
- LTV 추측이 가능하다면, 신규 유저를 데려오는 비용(CAC: Customer Acquisition Cost)의 산출 및 효율적인 예산 운용이 가능
LTV 산출 방법
- 이익 x Life Time x 할인율(미래 비용에 대한 현재 가치)
- 연간 거래액 x 수익률 x 고객 지속 연수
- 고객의 평균 구매 단가 x 평균 구매 횟수
- (매출액 – 매출 원가) / 구매자 수
- 평균 구매 단가 x 구매 빈도 x 구매 기간
- (평균 구매 단가 x 구매 빈도 x 구매 기간) – (신규 획득 비용 + 고객 유지 비용)
- 월 평균 객단가 / 월 가중 평균 잔존율
- LTV를 산출하는 방법은 매우 여러가지이며, 서비스마다, 관점마다 다르기 때문에 다각도로 고민이 필요함
LTV 정리
자사 서비스에 딱 맞는 LTV를 산출하는 것은 매우 어려운 일이다. 사용 주기, 변수, 객단가 등 여러가지를 고려해야 한다. LTV는 가정을 베이스로 하는 지표이기 때문에 꾸준한 모니터링이 필요함.
LTV를 늘리기 위한 방안
- 객단가 상승
- 구매 빈도를 높임
- 이탈률 감소, 이용시간을 증가 등
LTV에 관심이 더 생긴다면 읽어보면 좋을 자료들
- PAP Excel로 Retention 변화에 따른 LTV 시뮬레이션하기
- 토스 - 무한한 사업 전략의 세계로 건너가는 법
- EO planet - 이제 LTV(고객생애가치)를 정확히 계산해 봅시다
3.4 북극성 지표
3.4.1 북극성 지표란?
북극성 지표
- 제품/서비스의 '성공'을 정의
- 제품/서비스가 유저에게 주는 core value를 가장 잘 나타낸 것
- 장기 성장을 위해 필수적으로 모니터링 해야 함
북극성 지표의 구조
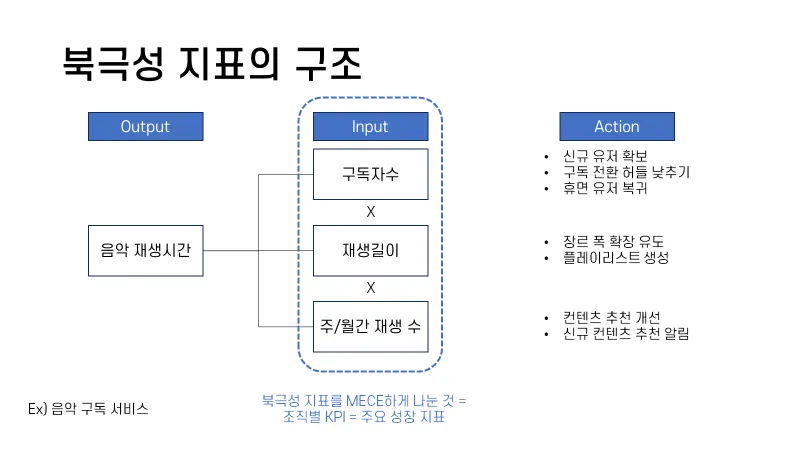
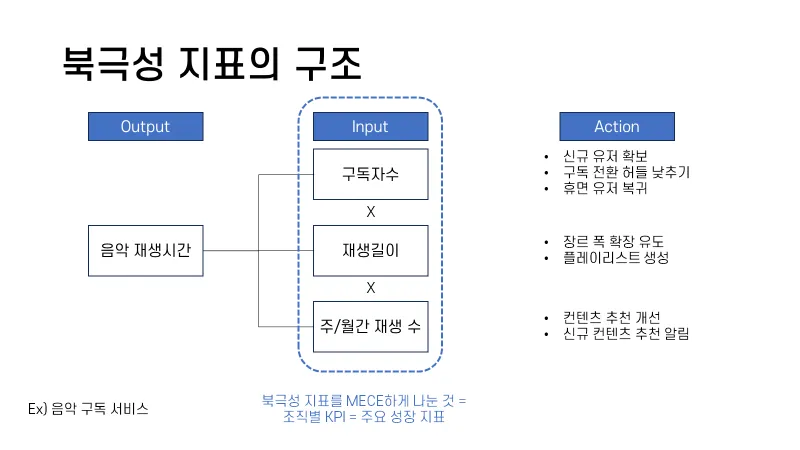
좋은 북극성 지표의 특징
- 제품/서비스 전략의 핵심
- 유저/고객이 제품/서비스에서 느끼는 가치
- 회사의 사업 목표를 나타내는 지표 중 선행지표 (후행X)
좋은 북극성 지표를 위한 체크리스트
- 유저가 목적을 달성하는 때가 언제인가?
- 모든 유저가 해당되나?
- 측정 가능한 지표인가?
- 측정 주기가 적절한가? (일, 주, 월, …)
- 외부 요인으로부터 영향을 많이 받진 않는가?
- 북극성지표의 성장이 사업의 성장과 함께하는가?
- AARRR 퍼널 전 과정이 북극성 지표에 영향을 주는가?
- 북극성 지표의 변화가 적어도 매주 관찰가능한가?
좋지 않은 북극성 지표의 예

- 외부 요인의 영향을 많이 받는 지표
- 유저/고객의 전체 여정을 반영하지 않는 지표
- 유저/고객이 직접 가치를 느낄 수 없는 지표
- 측정 불가하거나, 기간 설정이 안되는 지표
- 상황에 따라 위 지표들도 북극성 지표가 될 수 있음
3.4.2 북극성 지표의 사례
북극성 지표의 유형
| 북극성 지표 | 수익모델 | 서비스 유형 | 서비스 예시 |
|---|---|---|---|
| 사용시간 | 광고,사용료 | SNS,플랫폼,스트리밍 | 유튜브,인스타,넷플릭스 |
| 거래량 | 판매액,수수료 | 커머스,매칭서비스 | 쿠팡,크몽,에어비앤비 |
| 효용 | 사용료 | 생산성 도구,헬스 케어 앱 | 슬랙, 줌, 지라 |
대표적인 북극성 지표 사례
| 기업명 | 북극성 지표 | 전략 |
|---|---|---|
| 에어비앤비 | 예약 완료 수 | 예약완료 수 증가 |
| 엠플리튜드 | 매출, 주간 학습유저 | 유저 사용성 최적화 |
| 드랍박스 | 비즈니스 계정 사용 팀 수 | 결제 완료 수 증가 |
| 피그마 | 매출, 시장 점유율 | 매출 증대 |
| 인스타 | DAU | 유저 사용성 최적화 |
| 리프트 | 운행 수 | 운행 수 증대 |
| 넷플릭스 | 월간 시청시간 중앙값 | 사용 품질 개선 |
| 틴더 | 결제유저 비중 | 결제 유저 수 증대 |
3.4.3 북극성 지표가 중요한 이유
북극성 지표가 중요한 이유: 방향성
- 제품/사업 조직이 무엇에 최적화되어야 하고, 무엇을 포기해도 되는 지에 대한 방향 제시
- 제품/사업 조직의 진척과 가치창출을 전사에 보여줌
- 지원 조직이 더욱 적극적으로 지원, 제품개발 액션 실행속도가 빨라짐
- 제품/서비스 조직이 결과에 책임을 지도록 함
- 비즈니스 임팩트에 따라 평가가 가능
북극성 지표가 중요한 이유: 효율 증대
- 전 직원을 하나의 목표에 집중시킴
- 서로 상반된 목표에 집중하거나, 중복으로 일하는 것을 방지 (MECE한 구조)
4. 데이터 해셕의 오류와 함정
4.1 데이터 해석 오류 사례
4.1.1 심슨의 역설 (Simpson's Paradox)
심슨의 패러독스란 '부분'에서 성립한 대소 관계가 그 부분들을 종합한 '전체'에 대해서는 성립하지 않는 모순적인 경우를 말함.
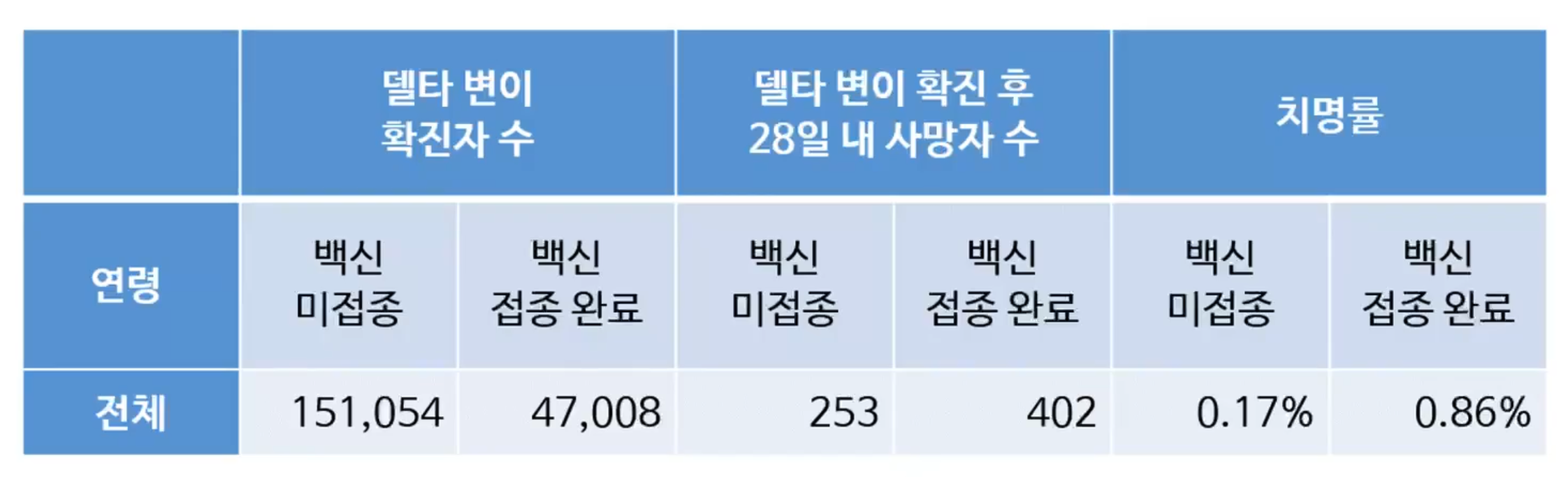
- 위 표는 영국 공공보건국에서 2021년 8월 발표한 코로나 변이 바이러스에 대한 브리핑 자료
- 백신 미접종자의 치명률 0.17%, 백신 2차 접종 완료 치명률 0.86%
- 백신 접종 완료자의 치명률이 미접종자에 비해 5배 이상 높게 나타난 의문스러운 결과
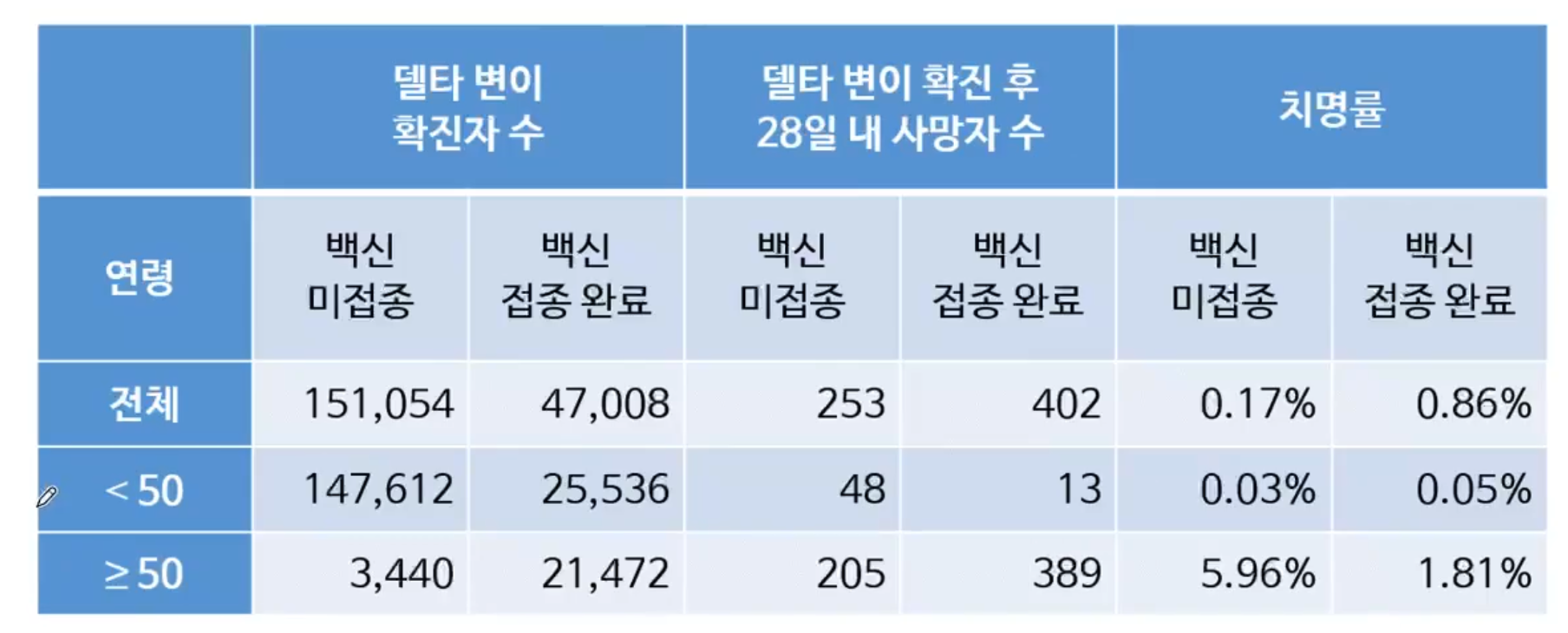
- 데이터를 50세 미만과 50세 이상으로 나누어 살펴보면 다른 결과를 확인할 수 있음
- 50세 미만 집단에서는 백신 미접종자의 치명률이 0.03%, 접종 완료자의 치명률이 0.05%
- 접종 완료자의 치명률이 더 높기는 했으나, 양쪽 모두 낮은 수준의 치명률을 나타냄.
-50세 이상의 집단에서는 백신 미접종자의 치명률이 5.96% 접종 완료자의 칯명률이 1.81%
- 미접종자의 치명률이 접종 완료자에 비해 3배 이상 높게 나타님
- 즉 개별 연령 집단 내에서 살펴보면, 50세 미만은 백신 접종 여부에 관계없이 치명률이 매우 낮았고, 50세 이상의 위험군에서는 백신이 치명률을 낮추는 효과가 있음.
4.1.2 심슨의 역설이 의미하는 바
- 전체에 대한 결론이 언제나 개별 집단에 그대로 적용되는 것은 아님.
- 데이터에 기반한 결론이라고 해서 이를 명목적으로 받아들여서는 안됨.
4.1.3 시각화를 활용한 왜곡
자료의 표현 방법에 따라서 해석의 오류 여지가 존재
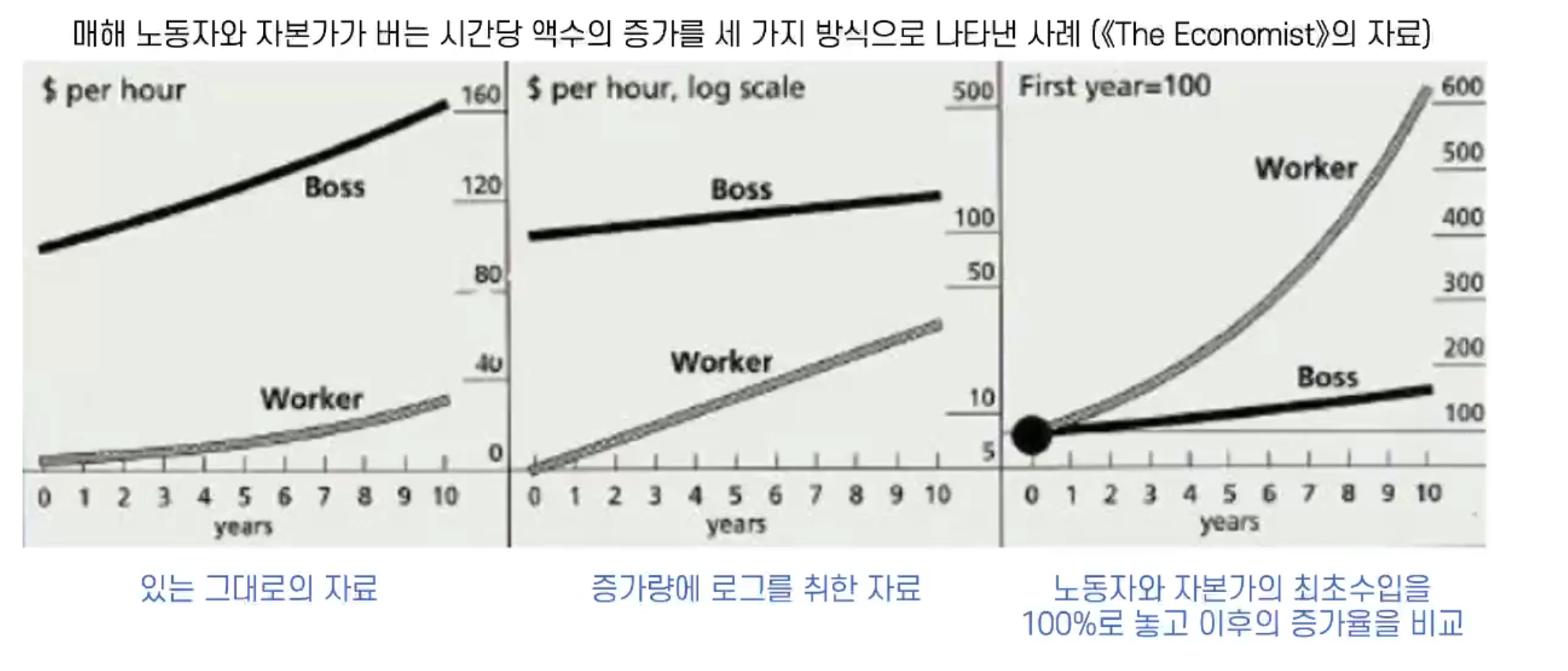
-왼쪽 그래프에서는 노동자의 임금이 현저히 낮은 것을 확인할 수 있음
- 중간 그래프에서는 노동자들의 임금 증가가 급격하게 이루어져 왔다고 해석될 여지 존재
- 오른쪽 그래프에서는 노동자들의 임금 증가가 자본가의 수입 증가를 훨씬 능가한다고 해석할 여지 존재
4.1.4 샘플링 편향 (Sampling Bias)
전체를 대표하지 못하는 편향된 샘플 선정으로 인해 오류가 발생
- 1936 미국 대통령 선거에서 Literary Digest 잡지사가 천만 명에게 우편물을 보내 수행한 대규모 여론조사 사례로 240만 명의 응답을 받았고 랜던이 선거에서 57% 득표를 얻을 것이라고 높은 신뢰도로 예측했만 루즈벨트가 61% 로 당선되었다.
문제는 Literary Digest의 샘플링 방법
- 첫째, 여론조사용 주소를 얻기 위해 전화번호부, 자사의 구독자 명부, 클럽 회원 명부 등을 사용. 이런 명부는 모두 공화당(따라서 랜던)에 투표할 가능성이 높은 부유한 계층에 편중된 경향이 존재
- 둘째, 우편물 수신자 중 25% 미만의 사람이 응답. 이는 정치에 관심 없는 사람, Literary Digest를 싫어하는 사람과 다른 중요한 그룹을 제외시킴으로써 역시 표본을 편향되게 만듦.
결국 표본이 편향되면서 실제와는 다르게 해석하게 될 수 있다.
Literary Digest는 이 일호 인해 폐간됨.
4.1.5 상관관계와 인과관계
상관 관계
- 두 변수가 얼마나 상호 의존적인지를 파악하는 것을 의미
- 파악 방법은 한 변수가 증가하면 다른 변수도 따라서 증가/감소하되 그 추이를 따름
인과관계
- 실질적으로 하나의 요인으로 인해 다른 요인으 수치가 변하는 형태를 의미
- 원인과 결과가 명확한 것
4.1.6 상관관계와 인과간계 오류 사례
1940년대 보건 전문가의 소아마비와 아이스크림 섭취 간의 연구 결과
-
당시 보건전문가는 소아마비와 아이스크림 섭취량의 상관관계가 있는 것을 발견, 전국에 소아마비 예방을 위해 아이스크림 섭취량을 줄일 것을 권고.
-
소아마비는 여름에 많이 발생
-
아이스크림은 여름에 판매량이 급증
-
즉 소아마비와 아이스크림 섭취 간에는 어떤 인과관계도 존재하지 않음
-
단순히 날씨라는 변수로 인해 공통으로 영향을 주기 됨.
4.1.7 이로 인해 알 수 있는 점
- 상관관계는 인과관계가 아닌 것을 항상 유의해야 함.
- 상관관계 만으로 섣불리 의사결정 하지 않기
- 양쪽을 모두 활용하여 합리적인 의사판단 하기
4.2 데이터 유형 예제
4.2.1 정량적 데이터 사례
- 인구 통계 데이터
- 수치형 설문조사 데이터 (고객 만족도)
- 비즈니스 데이터 (매출 데이터, 주문 금액)
- 행동 로그 데이터 ( 웹 행동 트래킹 )
- 마케팅 데이터 ( 광고 관리 데이터 , 얼마 썼는지 )
4.2.2 정량적 데이터의 활용
정량적 데이터는 객관적이고 측정가능한 지표를 만들기에 적합하다.
일일 활성 사용자수(DAU, Daily Active User), 재방문 비율(Retention) 등 서비스의 건강 상태를 나타내는 중요한 지표들을 확인할 수 있다.
수치형 설문조사 데이터를 정량적인 기준으로 나눈 사례, 추천 지수(NPS)를 만들 수 있음
- NPS(Net Promoter Score) = 추천고객 비율 - 비추천 고객 비율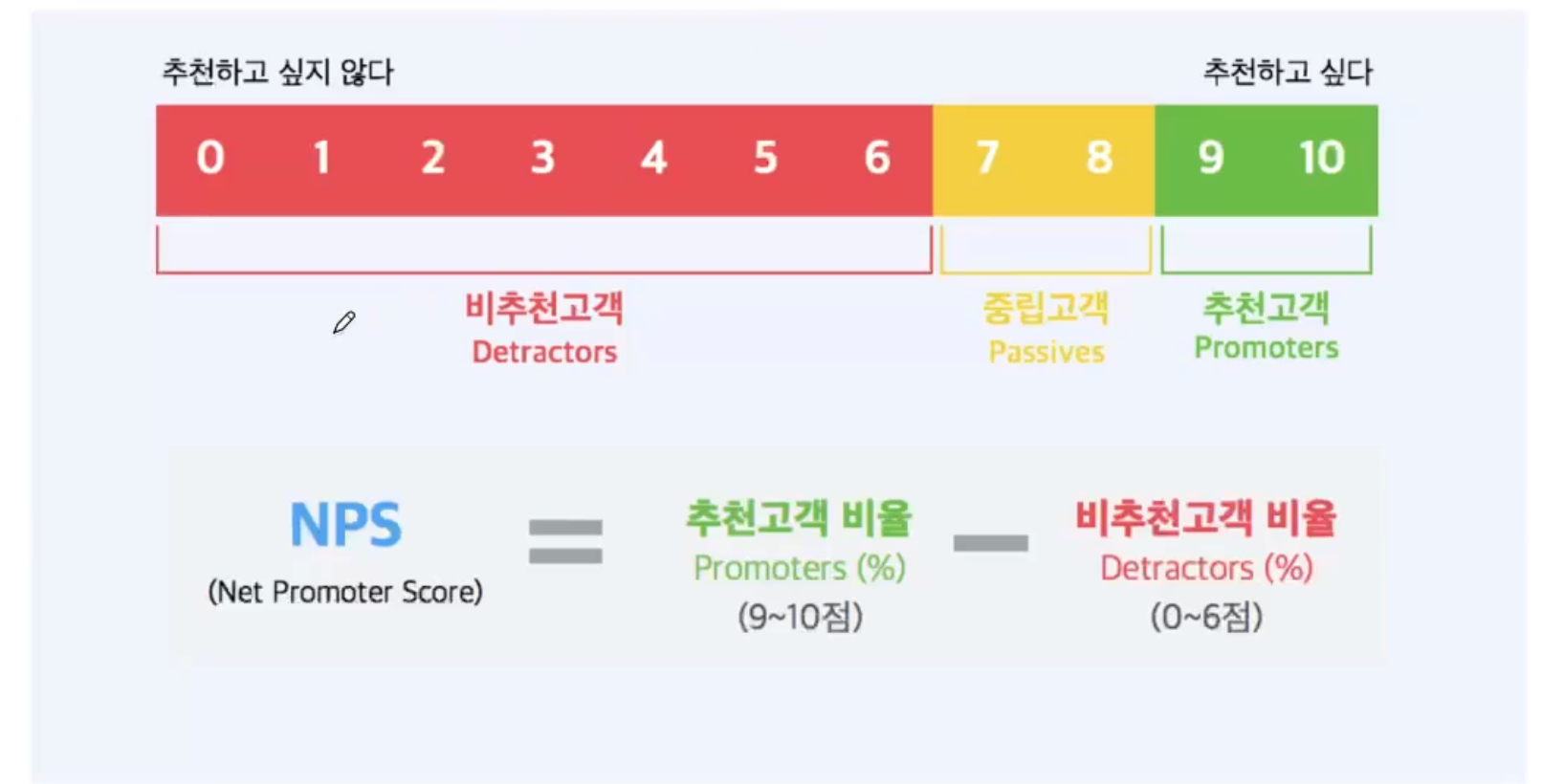
4.2.3 통계적 분석 적용
- 분포, 평균, 중앙값 등을 계산해서 데이터의 경향성과 패턴을 파악할 수 있다.
- 해당 내용을 근거로 의사결정 과정에서 중요한 판단을 내린다.
4.2.4 다양한 데이터 분석 방법 적용
비즈니스 분석, 예측 모델링, 추세 분석을 포함한 머신러닝과 같은 현대적 데이터 분석 기법에 활용할 수 있다. 이를 통해 미래 예측, 효율적 자원 배분, 시장 변화에 대한 적응이 가능해 짐.
4.2.5 위 특성을 바탕으로 정량적데이터는 다음과 같은 질문에 대답을 할 수 있다.
- 한 달 동안 우리 회사가 벌어들이는 매출은 얼마인가?
- 하루 평균 우리 플랫폼에 접속하는 고객 수는?
- 지난달에 방문한 유저 중 얼만큼이 다시 우리 서비스를 이용했는가?
5. 분석 결과와 결론 도출
5.1 데이터 분석 접근법
문제 및 가설 정의 >> 데이터 분석 >> 결과 해석 및 액션 도출
5.2 결론 도출
5.2.1 결과와 결론의 차이
결과
데이터 처리, 분석, 모델링 후에 얻어진 구체적인 데이터의 출력으로 계산과 분석을 해서 나온 결과물이다. 숫자, 통계, 그래프, 차트 등의 형태로 나타낼 수 있다.
- ex) “고객 설문 조사 데이터를 분석한 결과, 고객 만족도와 구매 빈도 사이에 강한 상관관계가 있음을 보여줄 수 있다.”
결론
결론이란 분석된 데이터 결과를 바탕으로 이끌어낸 의미나 통찰을 의미한다. 결론은 데이터에 기반한 해석, 추론 또는 권고 사항을 포함해서 목적에 대해 어떤 의미가 있는지 설명해야 한다.
- ex) “고객 만족도와 구매 빈도 사이의 강한 상관관계를 보여주는 결과를 토대로, 고객 만족도 향상이 전반적인 매출 증가로 이어질 수 있다는 결론을 내릴 수 있다.”
실제로 우리가 필요한 것은 '결론'이지만, 보통 결과를 많이 이야기 함. 이르는 과정은 본질적으로 동일하지만, 표현 방식이 다름
결론 도출 시 주의사항
결과 - 결론 도출 시에는 스토리텔링이 필요하다. 그러나, 필요 이상으로 자신의 해석을 융합해서는 안된다.
- 데이터를 통해 알 수 있는 범위에서만 생각해야 함
5.2.2 결론을 잘 정리하는 법
단순하고 쉽게 전달
- 핵심 지표 위주로 먼저 공유
- 지표를 해석하는 방법에 대해서도 설명
- 해당 지표에 오너십이 있는 조직에서 활용할만한 포인트 제안
- 액션 아이템을 제안 하는것이 핵심
흥미 유발
- 모든 내용을 담지 않고 흥미로운 부분 위주로 공유
- 상대가 궁금해할만한 내용은 뭘까? 고민하고 필터링 하기
- 궁금한 사람들을 위해서는 디테일한 문서 따로 공유
대상자 관점에서의 접근
- 공유 받는 사람(=대상자)의 시선에서 이해하기 쉽도록 정리
- 지식의 저주에 빠지지 않고 논지를 뒷받침 해줄 자료들을 함께 첨부
- 대상자의 허들이 낮은 시각화 활용
시각화 팁
- 화려한 그래프 보다는 대상이 직관적으로 이해할 수 있도록 구성
- 보통 선, 막대 그래프로 거의 대부분의 리포팅이 가능
- 각 그래프의 범례와 단위 함께 표기해주기
결론 보고서에 쓰면 좋은 플로우
- 전체 내용을 한 문장으로 정리하는 요약
- 해당 보고서의 메인 주제
- 해당 보고서를 쓴 이유와 원하는 변화
- 문제 정의 단계
- 핵심 내용 전개
- 결론 및 액션 아이템
정리
- 앞서 문제 정의, 지표 설정을 할 당시의 목적을 떠올리며 정리
- 결론을 공유할 대상이 누구이며, 어떻게 변화하길 원하는지? 생각
5.2.3 결국 데이터 리터러시란?
- 눈앞에 있는 데이터에 의존하지 않고 스스로 목적과 문제를 정의하는 것
- 그 목적을 달성하는데 필요한 데이터와 지표를 설정하는 것
- 데이터를 어떻게 봐야 문제의 정보를 효과적으로 얻을 수 있는지 분석하는 것
- 단순히 데이터를 보는 방식이나 분석 방법론, 통계지식에 매몰되지 않는 것
- 왜?를 항상 생각하기
