
2022년 7월 15일 기준으로 Kaggle AMEX(캐글 아멕스) 대회에 2,767 팀이 참여하고 있다.
코드를 처음부터 빌드해가는 방법도 있겠지만, 오픈소스가 많고 다들 공유하는 분위기라... baseline은 많이 참고하는 듯 하다.
우리팀이 참고했던 코드를 이해해보고 잘 활용해보자.
Data Preprocessing
먼저 전처리하는 코드이다. 주최측에서 제공한 파일은 csv 포맷에 총 크기가 50.31GB 이라서 다루기가 쉽지 않다. 다른 아티클을 참고하여 .parquet, .pickle, .feather 등의 포맷을 사용한다고 알게되었다.
- Radder - amex data int types - train
다른 코드들에서 많이 가져다쓰는 데이터셋이길래 일단 적용해보았다.- 랜덤 노이즈 제거
floorify - category 컬럼 라벨인코딩
- dtype 변경
- 랜덤 노이즈 제거
최종적으로 .parquet 포맷으로 변경되어 사용할 수 있다. 데이터 파일
Baseline Model
LightGBM Quick start - by Ambrosm
Code Here
가장 먼저 참고한 베이스라인 모델코드였다.
LGBM은 가볍지만 좋은 성능으로 쉽게 돌려보는 용도로 많이 쓰인다. User defined Function (UDF)를 제외하고 코드를 조금 이해해보자면 아래와 같은 순서로 되어있다.
- Feature Engineering
- Customer_id 당 data point로 이뤄진 df로 변환
- 이 과정에서 Customer_id 당
mean,min,max,last값을 계산하게 된다. - 최종 shape: (924621, 469) - Train set
- Model Training
- Stratified K-Fold (5 folds) : default 데이터이다 보니까 0,1 의 binary 값을 가지게 된다. 따라서 fold 마다 1 [default] 값이 골고루 들어가도록 하기 위해서 stratified k-fold를 사용한다.
- Parameters 모델의 하이퍼파라미터를 설정해준다. 따로 튜닝은 해주지 않은 듯하다.
(언급이 있었는데 제가 못찾은 것일지도)
- Prediction
학습한 모델에 test 데이터를 집어 넣고 prediction 값을 리턴한다.
| fold0 | fold1 | fold2 | fold3 | fold4 | OOF | |
|---|---|---|---|---|---|---|
| Result | 0.79374 | 0.79152 | 0.79357 | 0.79545 | 0.79488 | 0.79383 |
위 표와 같은 결과를 얻을 수 있다.
캐글 사이트에서 제출했을 때 0.793 점수가 나왔었다.
OOF 결과와 비슷하게 나온 것 같다.
개선해볼점
1. 다른 피쳐를 추가해보자: std, first 값 등
2. 파라미터 튜닝 (아직은 하지 않았다. 거의 최종단계에서 돌려보자)
3. NA 값 채우기
4. 처리해준 피쳐가 전부 같은 처리를 한 것이 아니라 선택적으로 처리를 해줬는데, 이에 대한 래셔널이 맞는지 확인해볼 필요가 있다.
Keras Neural Network - by Ambrosm
Code Here
간단한 뉴럴넷 모델로 돌려보려고 참고한 코드이다.
통상적으로 tabular 데이터에는 뉴럴넷보다는 머신러닝 알고리즘(lgbm, xgb, rf)이 성능이 더 좋다고 알려져있지만 다른 모델도 적용해보고자 참고하였다.
- Feature Engineering
- 위에서 언급한 lgbm과 동일한 사람이 작성한 코드이기 때문에 해준 처리는 동일하다.
- Model Training
- 다른점만 언급하자면 모델만 다르다. 4개의 hidden layer, skip connection, dropout을 포함한 아래와 같은 모델을 선택했다.
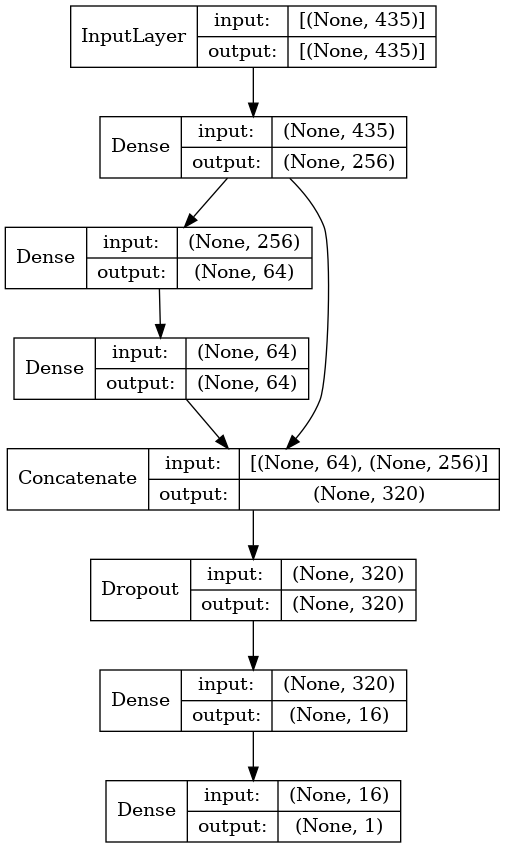
- lgbm과 마찬가지로 stratified K-fold를 적용했는데, 폴드 수만 10으로 증가시켰다. 이 부분은 저자에게 discussion 탭을 통해 물어보니 10 fold로 바꿔서 LB 스코어가 증가될 것을 기대했다고 한다.
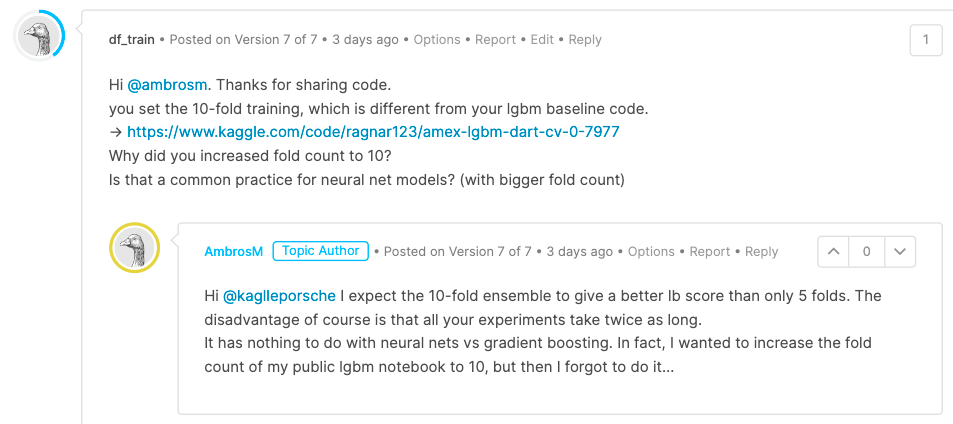
- 무작정 폴드 수를 늘리는 것이 스코어를 늘린다는 보장은 없으나, 달리 해보는 것은 의미가 있을 듯하다.
- Prediction
예측하는 부분 코드도 크게 달라진점은 없었다.
| fold0 | fold1 | fold2 | fold3 | fold4 | ||
|---|---|---|---|---|---|---|
| Result | 0.79485 | 0.78556 | 0.78797 | 0.79310 | 0.78511 | |
| fold5 | fold6 | fold7 | fold8 | fold9 | OOF | |
| Result | 0.79027 | 0.79326 | 0.79456 | 0.79074 | 0.78690 | 0.79023 |
OOF 점수가 0.79023 이 나왔고
실제 제출결과는 0.790 으로 거의 동일하게 나왔다.
개선해볼점
1. 마찬가지로 Feature 추가
2. 모델의 변경 - feature를 추가함에 따른 모델의 노드 개수 변경 & 히든레이어나 구조자체를 바꿀 수 있겠다.
