왜 XGBoost, LightGBM 모델을 사용하셨나요?
이 글은 위 질문에 대해 단순히
트리 부스팅 계열의 알고리즘이 Tabular 데이터에 좋기 때문에 사용했어요~
라고 답하지 않기 위해 작성하기로 했다.
먼저 앙상블,
질문에 답하기 위해서는 먼저 알아야할 개념이 있다.
부스팅과 앙상블.
앙상블 먼저 짚고 넘어가자.
Ensemble(앙상블)
여러 개의 약한 모델(weak learner)을 활용하여 강력한 모델(strong learner)을 만드는 방법
당연하게도 여러가지 방법으로 앙상블을 시도할 수 있다.
- Voting
- 여러 개의 모델이 투표를 통해 최종 결과를 결정한다 (일반적으로 서로 다른 알고리즘 사용)
- 사용하는 데이터 셋은 모두 같다
- Hard voting: 다수의 모델이 예측한 결과값을 최종 결과로 선정한다
- Soft voting: 각 모델이 계산한 확률을 평균하여 가장 확률이 높은 결과물을 최종 결과로 선정한다
- Bagging (Bootstrap Aggregating)
- 데이터 샘플을 여러 번 뽑아서 (bootstrap sampling, 중복 허용) 모델을 학습시킨 후 결과를 집계하는 방법
- 이 때의 모델은 모두 같은 모델, 학습하는 데이터가 다름
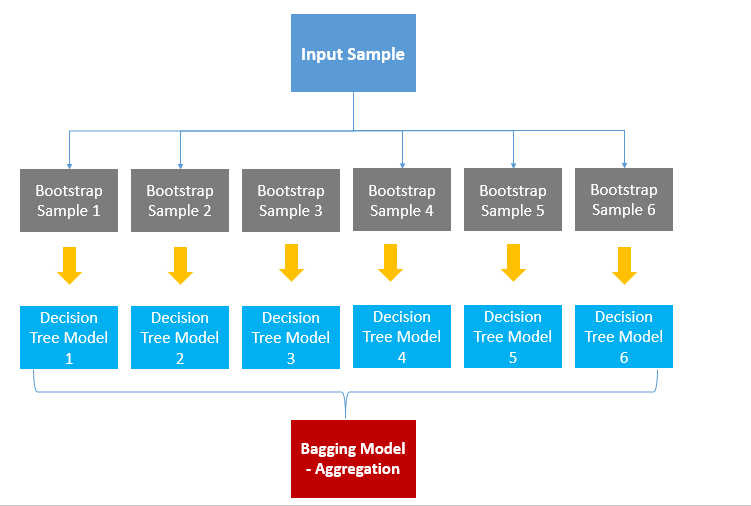
- 모델의 variance는 줄이고, overfitting을 줄여준다
(사실 같은말) - 대표적으로 random forest
-
Boosting
- 여러 개의 모델이 순차적으로 학습을 수행한다
- 이전 모델이 틀린 데이터에 대해 가중치를 부여하기 때문에 더 높은 예측 성능을 기대할 수 있다
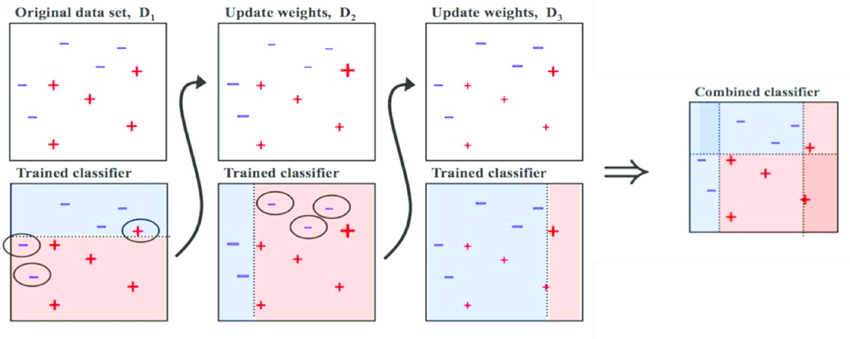
- 성능이 좋지만 속도가 느리고 overfitting이 발생할 가능성이 존재한다
- 대표적으로 XGBoost, LightGBM
-
Stacking
- 여러 모델이 예측한 결과를 가지고 meta 모델이 새로 예측하는 방법
앙상블에 여러가지 방법이 있는 것은 알았고, 그 중에서 XGBoost와 LightGBM이 속한 부스팅 계열의 앙상블 알고리즘에 대해 자세히 보자.
그 중에서 부스팅 Boosting
대표적인 4가지 Boosting 앙상블이 어떻게 작동하는지 알아보자
1. AdaBoost
2. GradientBoost
3. XGBoost
4. LightGBM
#1 AdaBoost (Adaptive Boosting)
1995년 고안된 방법, 유튜브 영상
node 하나에 2 개의 leaf를 가진 트리를 stump라고 한다.
피쳐를 하나만 쓴다는 것!

AdaBoost는 가중치가 있는 stump들을 모아둔 모델이다.
(random forest는 리프가 여러개인 full tree)
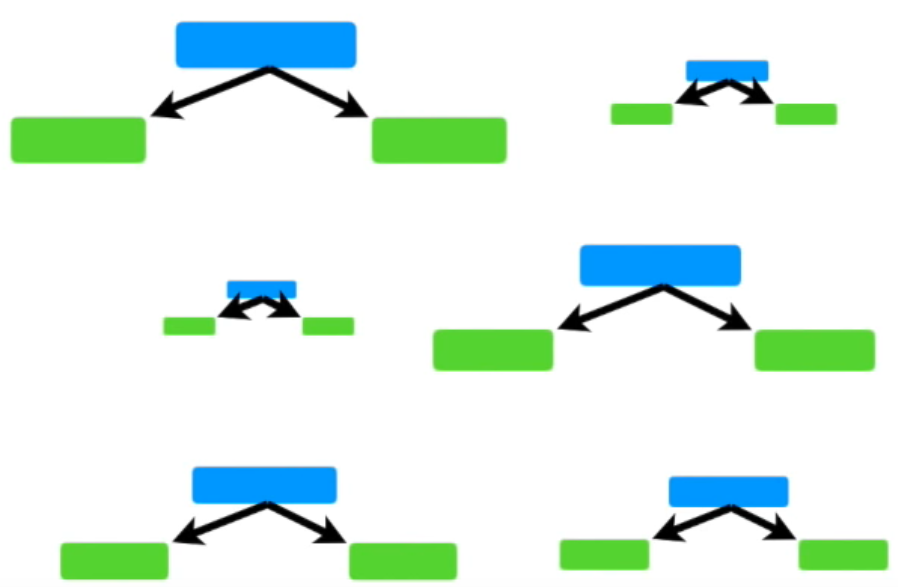
Algorithm
1) 처음에는 모든 데이터의 sample weight를 동일하게 두고 stump를 만들어 각 stump의 지니계수를 계산한다.
2) 지니계수가 가장 작은 (=잘 분류해낸) stump가 첫 stump로 선정된다.
3) 첫 stump에서 잘못 분류한 샘플에 대해서는 sample weight가 커지게 되고, 잘 분류해낸 샘플에 대해서는 sample weight가 작아지게 된다.
4) 업데이트 한 sample weight를 가진 데이터에서 데이터를 중복을 허용하여 샘플링하는데, sample weight가 큰 샘플은 확률적으로 더 많이 뽑히게 된다.
5) 뽑힌 sample에 대해 다시 모든 sample weight를 동일하게 두고 1번 과정을 반복한다.
#2 Gradient Boost
출처 유튜브 영상
AdaBoost에서 stump의 weight가 달라지면서 학습이 진행됐다면,
Gradient Boost는 leaf가 많은 형태의 tree를 사용한다.
(일반적으로 8~32 leaves)
그리고 tree들의 가중치는 모두 같다.
아주아주 요약하자면, 예측하려는 데이터들의 Y값을 모두 Y값의 평균이라고 두고 그 차이를 줄여나가는 방식으로 학습한다.
Algorithm
- 먼저 예측하고자 하는 Y값의 평균을 구한다.
- 각 데이터들의 실제 Y값과 평균값의 차이인 'residual'을 계산한다.
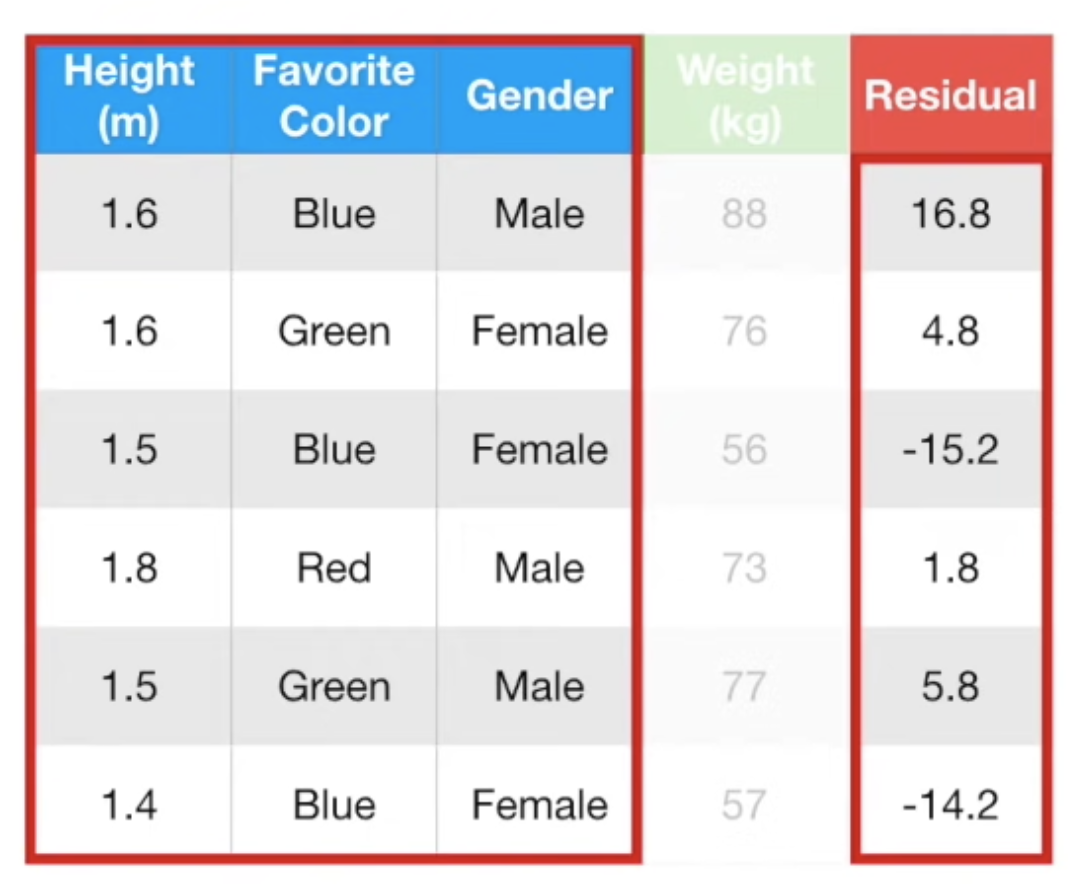
- residual값에 따라 데이터를 분류하는 decision-tree를 생성한다.
(여기서 hyperparameter 로써 max_num_leaves를 제한하여 학습과정을 제어할 수 있다)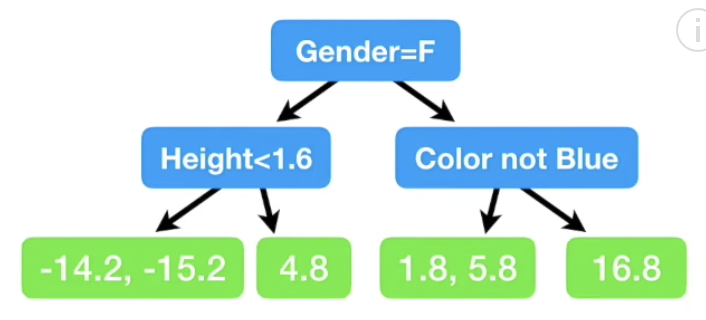
- 같은 leaf로 들어간 데이터의 residual을 그들의 평균값으로 대체한다.
(-14.2, -15.2 --> -14.7)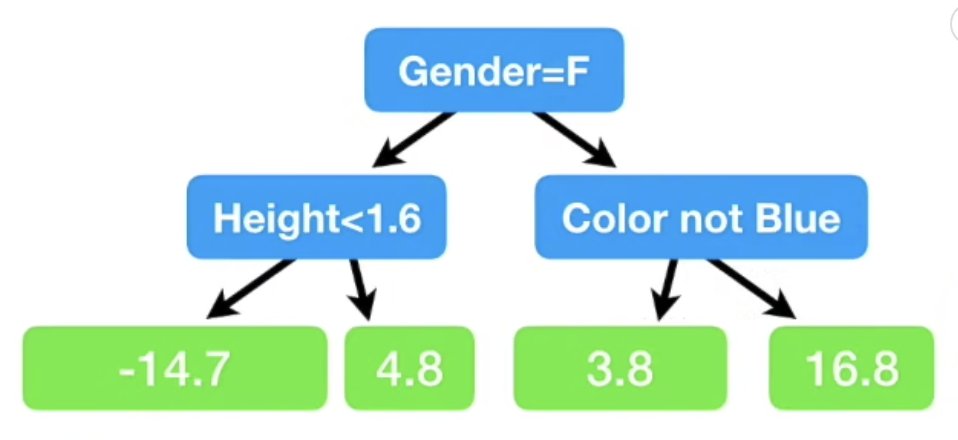
- 첫 예측값인 Average 값에 첫번째로 만들어진 decision-tree의 residual 값을 가중치 (learning-rate)를 곱하여 새로운 예측값을 계산한다.
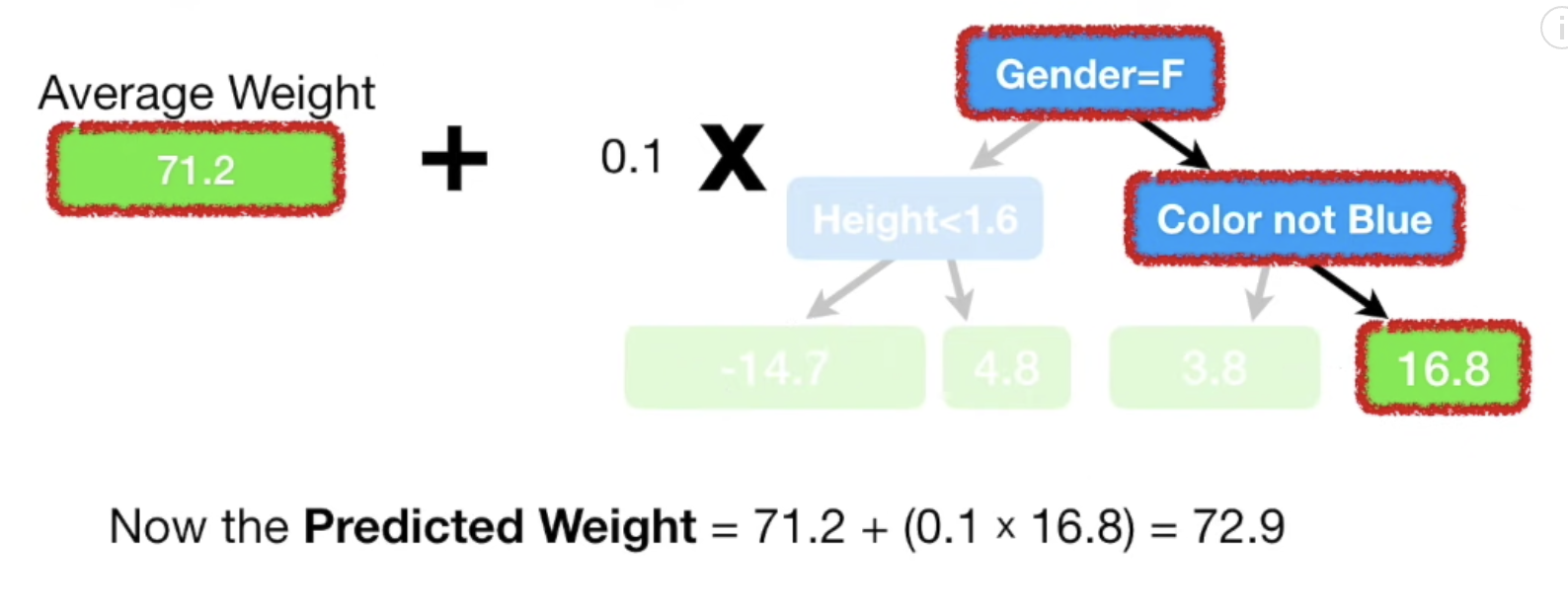
- 이제는 (1)단계에서 average로 모든 예측값을 초기화했었던 것처럼 (5)단계에서 계산한 새로운 예측값을 이용하여 residual = (observed-predicted) 을 계산한다. residual 값이 점점 작아질 것이다!
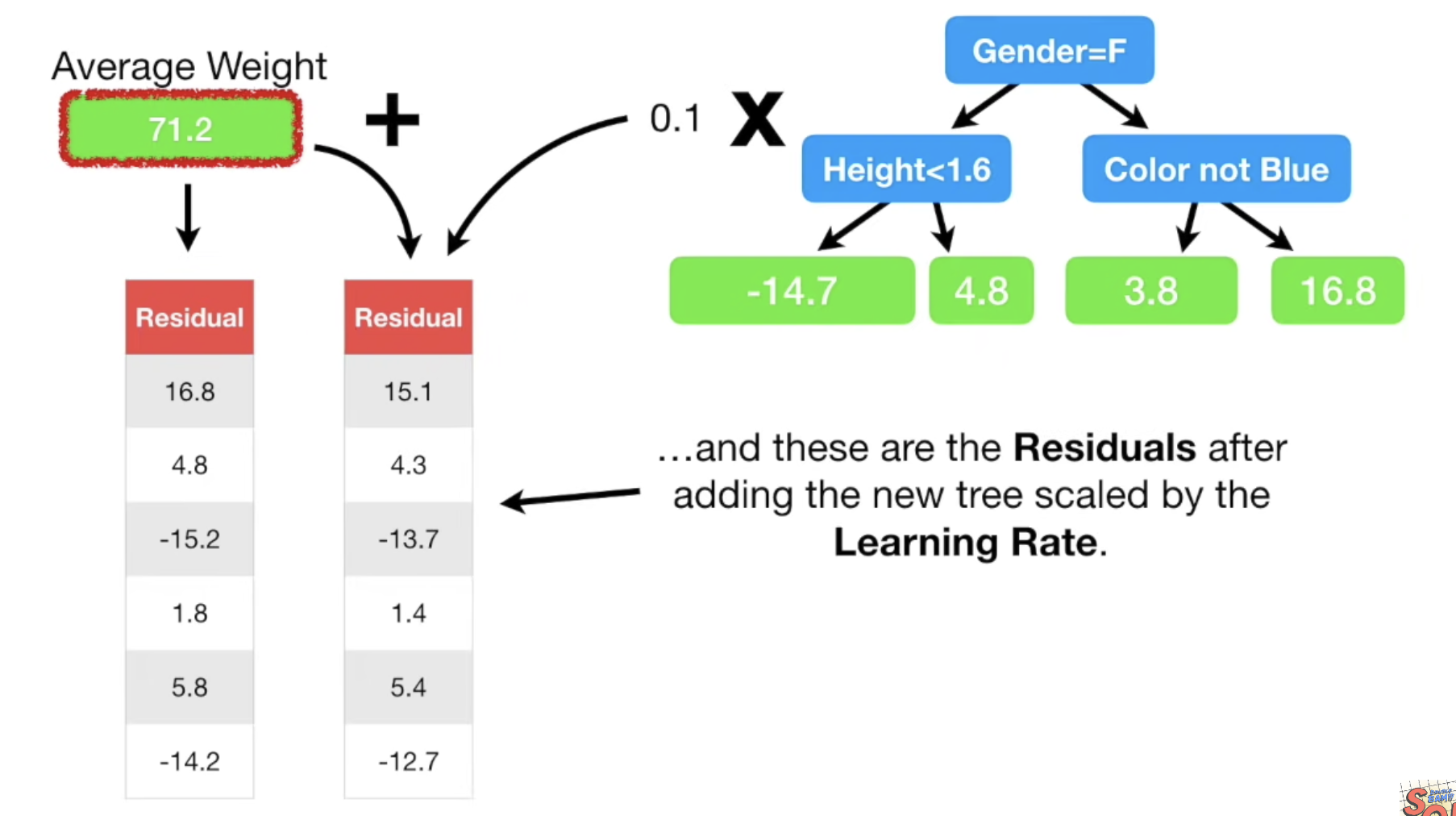
- 새로운 residual을 기반으로 (3)단계 부터 과정을 반복한다.
- 처음 average 예측값에 이전 트리를 더한 값에 새로운 트리까지 더해서 또 다른 예측값을 계산해낸다.
- 위 과정을 반복한다.
- 한 번의 사이클마다 residual 크기가 작아진다.
Source: StatQuest YouTube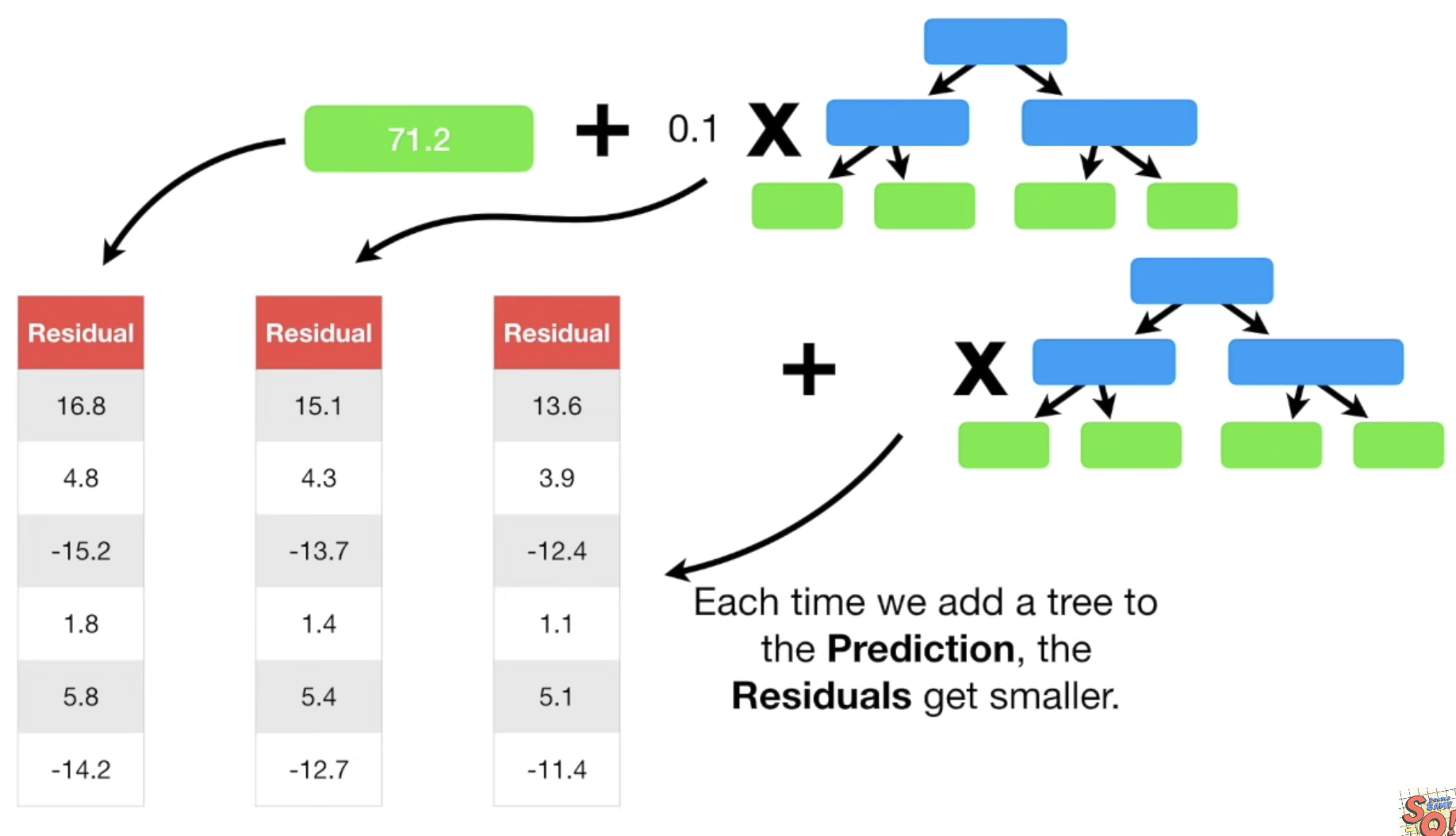
나머지 XGBoost 와 LightGBM 은 Part.2에서 계속...
(cf) The bias and variance of a classifier
모델의 bias와 variance는 뭐지?? Leo Breiman, 1996
= 모델이 내어놓는 prediction 들의 bias(예측값과 실제값의 차이)와 variance(예측값들이 얼마나 흩어져있는지)를 얘기하는 것
쉬운 한글 설명은 여기
Reference
