
1. Introduction
의사소통할 때 서로 구사하는 언어체계가 다르다면 여러가지 애로사항이 존재할 것이다.
한국인과 아르헨티나인이 전화통화를 한다고 생각해보자. 한 쪽은 한국어로 말하고 다른 한 쪽은 스페인어로 대답을 한다. 육성으로 밖에 표현을 못하니 바디랭귀지도 사용할 수 없다. 의사 전달에 장애를 겪을 확률이 높으며 대화 내내 서로 한 마디도 이해하지 못하는 상황이 생길 수도 있겠다.
사람과 컴퓨터의 관계도 그러하다. 서로 이해하는 언어체계가 다르기 때문에 그 사이에서 통역을 해줄 무언가가 필요하다.
1.1 How computer runs program?
통역 이야기에 앞서, 컴퓨터가 프로그램을 실행하는 과정에 대해 살펴보자.
컴퓨터의 하드웨어를 구성하는 요소들은 다양하지만, 설명의 편의를 위해 Processor와 Memory만 존재한다고 상정하겠다.
(본 문서에서 Processor를 CPU로 동일시하지만 하드웨어적 관점에서 엄밀히 따지면 둘은 다른 개념이라고 한다. Memory 역시 주기억 장치와 보조기억장치가 있지만 Memory라는 큰 개념 하나로 갈음하겠다. 이 부분에 대한 설명을 위해서는 공부가 더 필요할 듯.)
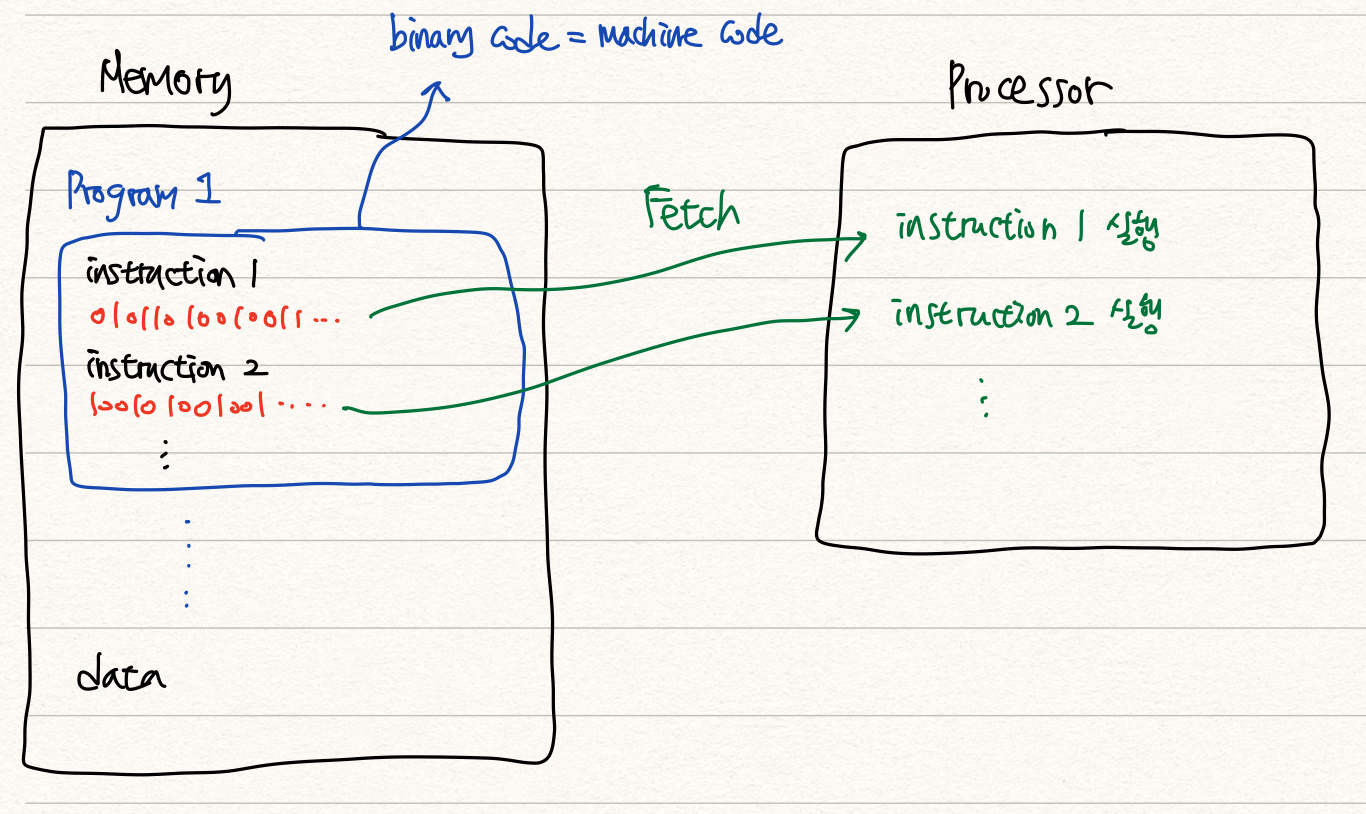
Program이란, 컴퓨터가 실행할 수 있는 instruction들을 모아놓은 것이다. 이 때, 이 instruction들은 0과 1로만 이루어진 binary code로 기록되며 이를 기계가 이해할 수 있는 체계라는 의미에서 machine code라고 부른다.
Instruction의 집합체인 Program은 평상시에는 memory (보조기억장치)에 저장되어있으며, user가 실행할 경우 Processor가 이용할 수 있도록 주기억장치에 올라가게 된다.
주기억 장치에 올라간 program은 그 instruction들이 차례로 Processor에 의해 fetch되어 해석 + 실행하는 과정을 거친다. (산술연산을 진행하던, 메모리에 저장하는 작업을 거치던 해당 instruction에 대응하는 작업을 진행한다.)
이 때 이 실행되는, 실행 가능한 program이 모두 binary system으로 기록되었다는 점에 주목해야한다. CPU는 전기신호로 대변되는 0과 1의 binary system만을 이해하고 실행할 수 있다.
컴퓨터의 입장에서 우리가 작성한 Python이나 JavaScript 파일은 의미가 정말 1도 없는 text파일일 뿐이다.
우리가 VS Code같은 IDE에 익숙해져있어 놓치고 있지만, txt 파일 확장자로도 특정 언어로 작성된 script를 해석 (compile or interprete)해 실행할 수 있다는 점을 상기해보자.
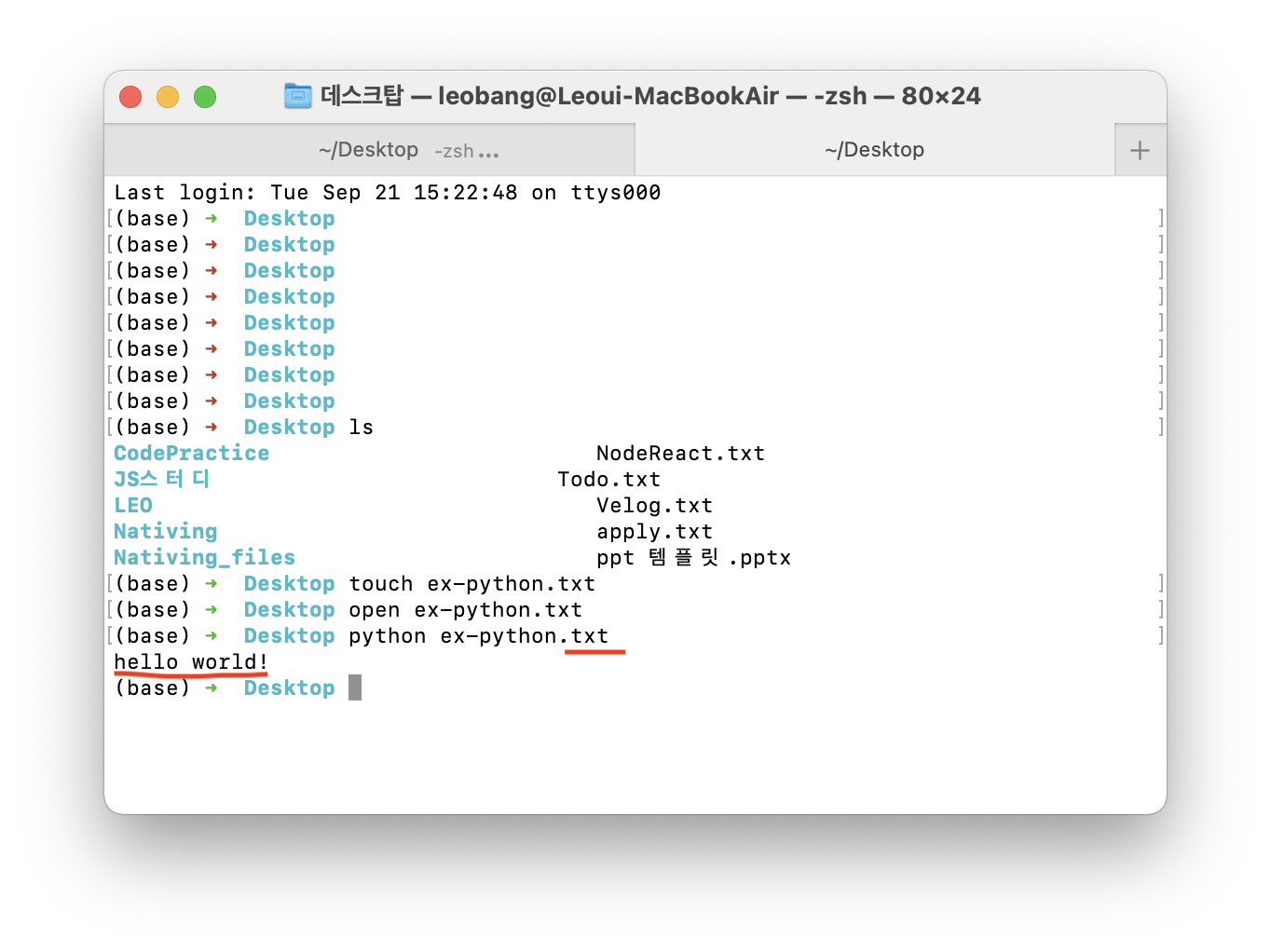
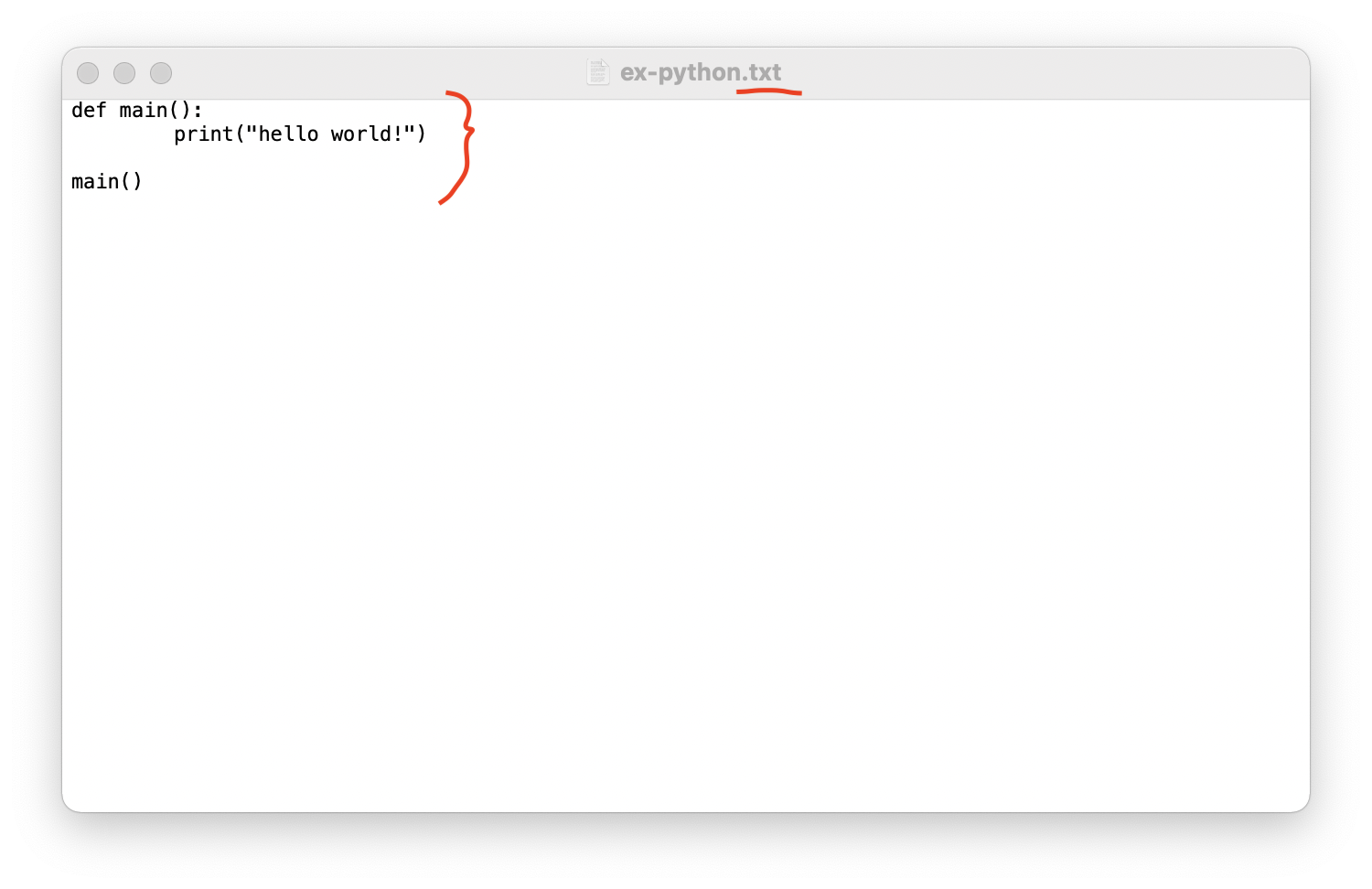
txt파일에 적은 main함수의 "hello world"가 잘 print된다.
이때 터미널에 $ python ex-python.txt 의 앞에 적은 python은 "python interpreter로 뒤에 등장할 파일을 python의 형식에 맞게 해석하고 실행해 달라" 는 명령어이다.
이 부분에 대해서는 Interpreter에 대해 설명할 때 자세히 다루겠다.
아무튼 방금의 예시를 통해 .js, .py의 형식으로 작성된 코드들이 대단한 technology가 아니라 컴퓨터에게는 그저 의미 없는 텍스트의 나열이란게 와닿았으면 좋겠다.
다시 말해, 컴퓨터의 입장에서 볼 때, 저 텍스트들을 binary code로 변환해주는 무언가가 없다면 아무리 대단하고 멋진 코드도 "앙기모띠" 한 줄 적힌 메모장 파일과 별반 다를 것이 없다.
1.2 Compiler, Interpreter = 파파고
Compiler와 Interpreter는 위와 같은 니즈에 의해 설계된, 인간의 언어를 컴퓨터의 언어로 번역해주는 program이다. 이를테면, 프로그래밍 언어계의 파파고인 셈이라 할 수 있겠다.
이 때 사람이 작성하는, 사람이 이해할 수 있는 언어를 source code 혹은 high level language라 칭하고 반대로 기계가 이해할 수 있는 언어는 machine code 혹은 low level language라고 부른다.
1.3 Low Level Language와 High Level Language

대략적인 의미로 봐주셈
Low와 High의 뜻으로 미루어보아 두 언어 간의 비교우위를 나타내는 것이라고 넘겨짚기 쉽다. 하지만 이는 어떤 언어가 뛰어나고, 어떤 언어가 열등한지 나타내는 것이 아니라 사람과 기계중 어느쪽에 가까운 언어인지 구분하는 용어이다.
High level로 갈수록 인간에게 가까운 언어이며, Low level로 갈수록 기계에게 가까운 언어이다.
우리가 직접 작성하는 source code는 모두 High Level Language의 범주에 속한다.
물론 문법을 모르는 상태에서 본다면 입문하기 좋다는 python 코드 역시 알쏭달쏭하다. 하지만 한번 source 코드를 자세히 들여다본다면, 얼마나 사람의 편의를 고려해 설계한 언어인지 알 수 있을 것이다.
1.3.1 High Level Language
흔히들 "코딩"한다고 키보드에 뚱땅대는 언어는 대부분 High Level Language이다. (사람이 machine code나 assembly language를 직접 코딩하는 경우는 드무니까...)
남이 쓴 코드보면 외계어같을 때가 많은데 도대체 어느 곳이 인간친화적이냐 묻는다면...
대부분의 프로그래밍 언어는 기본적인 표기문자로 알파벳을 채택했으며, 각 언어마다 내장되어있는 reserved word (예약어)들도 영단어의 축약어인 경우가 많다. (int - integer, list - list 그 자체) 시각적 편의를 위한 줄바꿈, 괄호, 인덴트 등등 기계의 입장에서는 쓸모없는 구성요소들이다.
특히 파이썬의 경우 간단한 문장 정도는 프로그래밍을 모르는 사람이 보아도 곰곰히 생각해본다면 이해할 수 있을만큼 직관적이다.
사람이 작성하는 프로그래밍 언어를 모두 High Level Language로 퉁치긴 했지만 이 안에서도 누가누가 기계에 가깝고, 사람에 가까운지 스펙트럼을 나누어 볼 수 있다.
예를들어, C와 C++은 메모리 관리를 직접할 수 있다는 점에서 타 언어에 비해 기계어에 가까운 언어이다. 반면, python과 javascript의 경우 동적 타이핑 (99%의 확률로 개떡같이 줘도 찰떡같이 알아들음)을 지원한다는 점에서 보다 인간에게 가까운 언어라 할 수 있다.
low level 일수록 사람이 머리 굴려가며 입력해야할 코드가 길어지지만, 기계어로 translate 하는데 적은 노력이 필요하며 정교한 프로그래밍이 가능하다.
반대로 high level로 갈수록 간단한 코드만으로도 원하는 바를 구현할 수 있으며, 이를 두고 생산성이 높다고 한다. 대신 기계어와 멀어진 만큼 translate하는데 시간이 더 오래걸린다는 단점이 있다.
입문자의 입장에서 볼 때, 고급언어를 익히는게 쉽다고는 하지만 괜찮은 프로그램을 빌드하기 위해서는 무엇이 좋고 나쁨을 논하기는 어렵다. 둘 다 모두 장단이 있으니!
1.3.2 Low level language
기계가 바로 읽고 이해할 수 있거나, 기계와 매우 가까운 언어를 뜻한다.
보통 machine code 그 자체나, Assembly lanugage을 묶어 Low Level Language라고 칭한다.
컴퓨터가 우리의 언어를 이해할 수 없듯, 우리도 이 low level langauge를 이해할 수 없다. 보통은.
1.3.2.1 machine code

말그대로 기계, 컴퓨터가 이해할 수 있는 언어로 0과 1만으로 이루어져 있다. (binary system)
컴파일러나 인터프리터나 궁극적으로 High Level Langauge를 binary code로 변경하는 것에 목적을 두고있다.
1.3.2.2 Assembly Language

machine code에 비해 한 단계 위의 언어.
당연히 컴퓨터는 이를 바로 읽을 수 없기 때문에 이 Assembly Language를 또 machine code로 번역해주어야 하는데 이를 수행하는 프로그램을 Assembler라고 부른다.
0과 1밖에 없는 machine code에 비해 알파벳으로 표기하고 대충 move랑 jump가 보이는 것 같지만 여전히 이해하기 어렵다.
엄밀히 말하자면 컴퓨터가 바로 읽을 수 있는 언어는 아니기에 간혹 medium level language로 분류하기도 한다.
2. Difference between Interpreter and Compiler
이러쿵저러쿵 긴 설명 끝에 Interpreter와 Compiler가 우리가 직접 타이핑한 high level language를 컴퓨터가 읽을 수 있는 low level language로 변환해주는 녀석이라는 것을 알게 되었다.
이어서 Complier와 Interpreter의 개략적인 차이를 훑어보자.
하나 먼저 말해두자면, 이는 Compiler와 Interpreter의 기술적 특성에 주목한 차이점이다. 프로그래밍 언어들을 Compiler와 Interpreter라는 기준으로 양분하기에는 그 경계가 모호하며 두 해석 방법은 상호 배타적인 것이 아니다.
언어를 해석하고 실행할 때 Compiler와 Interpreter 형식을 동시에 차용할 수 있으며, 현대 언어는 발전을 거듭하면서 그 경계가 희석되고 있다.
Compile 언어의 대표격인 C++ 도 Cling이라는 interpreter가 존재하며, Python과 Java는 compile한 결과물을 interprete한다.
언어들을 구분짓는 구분선으로 바라보는 대신 compiler와 interpreter의 각 기술적 특성에 집중하기 바람.
한 줄씩 vs 통째로
Interpreter
- source code를 한 줄씩 읽어나가며 machine code로 해석하고, 실행한다.
- Interpreter가 해석하는 과정 역시 runtime (실행시간)에 포함된다.
Compiler
- 전체 source code를 한번에 통으로 해석해서 object code로 만든다.
- runtime 전에 전체 source code를 변환하므로 compile하는 시간 (해석)은 runtime에 포함되지 않는다.
Analyzing time과 Run-time
Interpreter
- Interpreter는 한 번에 한 줄씩 해석하기 때문에 souce code를 분석하는 시간은 짧다.
- 하지만 process를 실행하는 전체적인 시간은 느리다.
Compiler
-
한 번에 전체 source code를 분석하므로 시간이 오래걸리지만 실행시간은 훨씬 빠르다.
-
당연한게, Compiler는 애초에 번역과정만을 뜻하므로 실행시간과는 무관하다.
-
번역이 완료된 후 생성한 실행파일을 실행하는 순간부터 runtime이 시작되므로 runtime 중에 번역을 매번 반복하는 interpreter보다 빠를 수 밖에 없다.
추가적인 메모리가 필요한지
Interpreter
- 한 줄씩 해석하면서, 해석과 동시에 실행하므로 추가적인 메모리 측면에서 효율적이다
Compiler
-
항상 object code를 생성한다.
-
이 object code들을 linker로 모아 다시 실행파일을 생성하므로 추가적으로 메모리를 잡아먹는다.
이 부분에 대해서는 후술할 Compiler에 대한 설명에서 보강하겠음.
디버깅이 용이한가
Interpreter
- 에러를 맞닥뜨릴 때까지 한 줄씩 읽어나가다가 error를 발견하면 바로 실행을 멈춘다.
- 따라서 디버깅이 쉬운 편이다.
Compiler
-
전체 source code를 scan한 후에 에러가 존재할 경우 에러메시지를 띄운다.
-
따라서 디버깅이 비교적 어렵다.
프로그래밍 언어
앞서 말했듯 각 언어의 해석 방식을 대표하는, 더 가까운 방식에 꼬리표를 붙여주는 것일 뿐 두 기술은 배타적인 것이 아님을 기억하기 바람.
Interpreter
- Python, JavaScript, Perl, MATLAB, Ruby 등등의 언어.
- High Level Language의 대부분이 인터프리터 언어이며, 약 70% 정도의 파이를 차지한다고 한다 (나무위키 피셜)
Compiler
- 대표적으로 C, C++ 가 컴파일러 언어
3. Compiler
사전적인 정의로는 한 프로그래밍 언어를 다른 프로그래밍 언어로 변환하는 프로그램의 총체를 일컫지만, 일반적으로 Compiler라 하면 High level language로 쓰여진 source code를 Low level language 프로그램으로 변환하는 프로그램을 말한다.
3.1 Compile VS Build
Source code를 실행가능한 하나의 program(예를 들어 .exe 확장자를 가진 파일)으로 변환하는 과정까지를 Compile이라 하는 경우도 있지만, 엄밀히 말하자면 이는 틀린 설명이다.
Source code를 실행가능한 single program으로 만드는 과정 전체는 Build라고 한다.
source code를 target language (= object code)로 변환하는 과정까지가 compiler의 역할이며, 이때 이 target language는 기계어 그 자체가 될 수도 있고 다른 compiler나 interpreter, 혹은 assembler에 제공할 언어가 될 수도 있다.
또한 기계어 그 자체로 변환하더라도 이를 바로 실행할 수는 없다. 생성된 object code들을 모아 하나의 실행가능한 프로그램 (single executable program) 으로 만드는 과정이 필요한데, 이를 수행하는 것이 Linker이다.
3.2 Build Process
Object code는 뭐고, Assembly code는 갑자기 왜나오고 실행가능한 program으로 만드는게 대체 뭔 개소린지 이해하려면 Compile 과정이 어떠한 절차를 거치는지 슬쩍 들여다볼 필요가 있다.
Compile 과정의 핵심인 Parsing과 같은 분석론에 대해서는 생략하겠다.. 이거도 공부하려면 한바가지 ㅜㅜ
compiler의 역할은 각 source code를 각각의 object code로 번역해주는 것이고, 이제 이렇게 source code 1개당 나온 여러개의 object code를 한데 모아 실행가능한 (예를들어 .exe 확장자) 파일로 변환시키는 것은 linker의 몫이라 했다.
(compiler가 assembly code로 번역하는 경우엔 assembler가 assembly code -> object code로의 변환을 맡는다. interperter에 제공할 언어로 변환하는 경우는 밑의 Interpreter 챕터에서 설명하겠다.)
그림으로 이해하는 편이 빠를 것이다.

우선 점선의 왼쪽에 주목해 보자.
compiler라는 놈들이 application code를 .o 확장자인 파일로 변환해주고 있다.
여기서 application code가 source code고 .o가 object code이다.
이렇듯 compiler의 역할은 source code를 1개 이상 (보통 1대1 대응)의 object code로 변환해주는 것이다.
문제는 이 source code라는 녀석이 한 프로젝트 내에 한 개만 있는 것이 아니라는 점이다. 아이디어톤과 해커톤 때 장고로 웹을 개발했을 때를 돌아보면, 적어도 100개 이상의 py 파일을 만들었다.
컴파일 언어인 c와 c++ 도 똑같다.
간단한 계산기를 만들거나 알고리즘 문제를 푸는 정도야 source code가 담긴 파일 1개만으로 프로젝트를 마무리해도 되지만 규모가 커질수록 여러개의 파일이 생길 것이다. 따라서 한 project를 컴파일하게되면, compile해야할 source code가 여러 개인 만큼 그 결과물인 object code도 여럿 생성되게 된다.
따라서 이 object code들을 한데 모아 하나의 실행가능한 파일로 만들어줄 프로그램이 필요한데, 이 역할을 이행하는 것이 Linker이다.
3.2.1 용어 정리
정리하자면,
Object code (= Target code)
- source code나 assembly code를 Compile한 결과물
- 컴파일러에 국한된 개념이 아니라, 그냥 해석의 결과물이 되는 코드의 총체로 이해하면 좋다.
- object code는 assembly code가 될 수도 있고, machine code가 될 수도 있고, bytecode가 될 수도 있고 아니면 다른 high level language가 될 수도 있다!
- source code 파일 개수만큼 (혹은 그 이상) 생성됨
- 0과 1로 이루어진 machine code
- 실행파일의 재료들
Compiler
- source code를 object code로 변환하는 프로그램 (object code가 assembly code일 경우 추후에 assembler가 이를 machine code인 object code로 변환한다)
- 한 번에 전체 source code를 분석.
Linker
-
한 프로젝트를 compile하게 되면, 여러 개의 object file이 생성된다.
-
이 object file들을 한 곳에 모아 하나의 실행가능한 파일을 생성하는 프로그램
-
source code가 이용하는 library를 모아 object code에 넣어줌 (이 부분은 좀 이따 다시 다룸.)
Build
- Compile + Link
- 한 프로젝트의 source code들 가지고 single executable program (machine code)을 생성하는 과정의 총체
3.3 Compiler under the hood (Visual Studio와 C++을 중심으로)
비주얼 스튜디오로 C 파일을 컴파일 하는 과정을 따라가보며 object code가 뭐고 실행가능한 single program이 뭔지 직접 확인해보자!
프로젝트 생성

visual studio를 켜고 새 프로젝트를 생성하면 설정한 directory에 프로젝트 폴더가 생성된다.
소스코드 작성
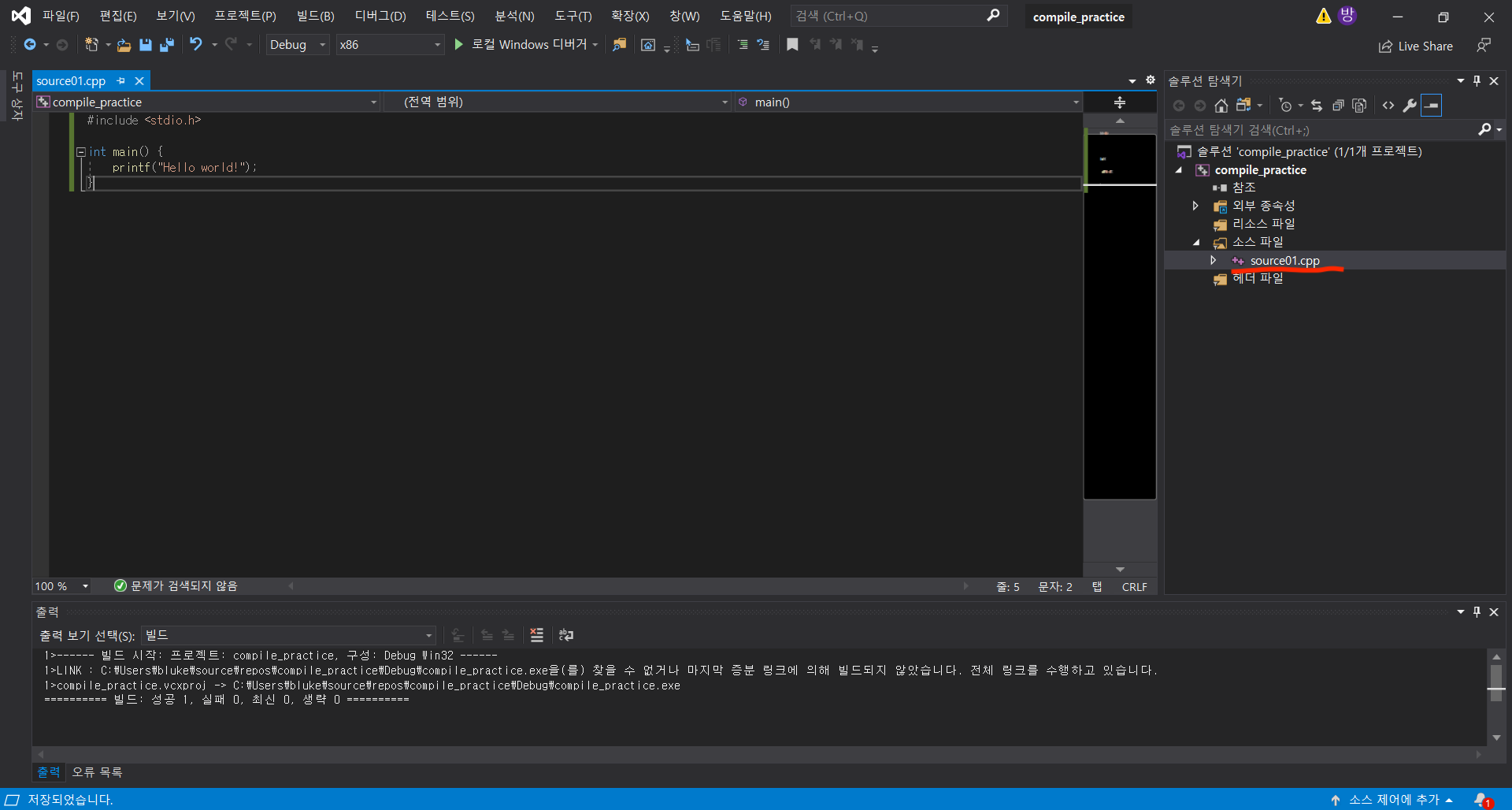
c++ 파일을 소스파일 폴더에 생성하고, 표준 입출력을 지원하는 라이브러리인 <stdio.h> 헤더 파일을 include해준 후 main 함수로 "Hello World!" 를 출력하는 코드를 작성해보았다.
디버그 (빌드 후 실행)
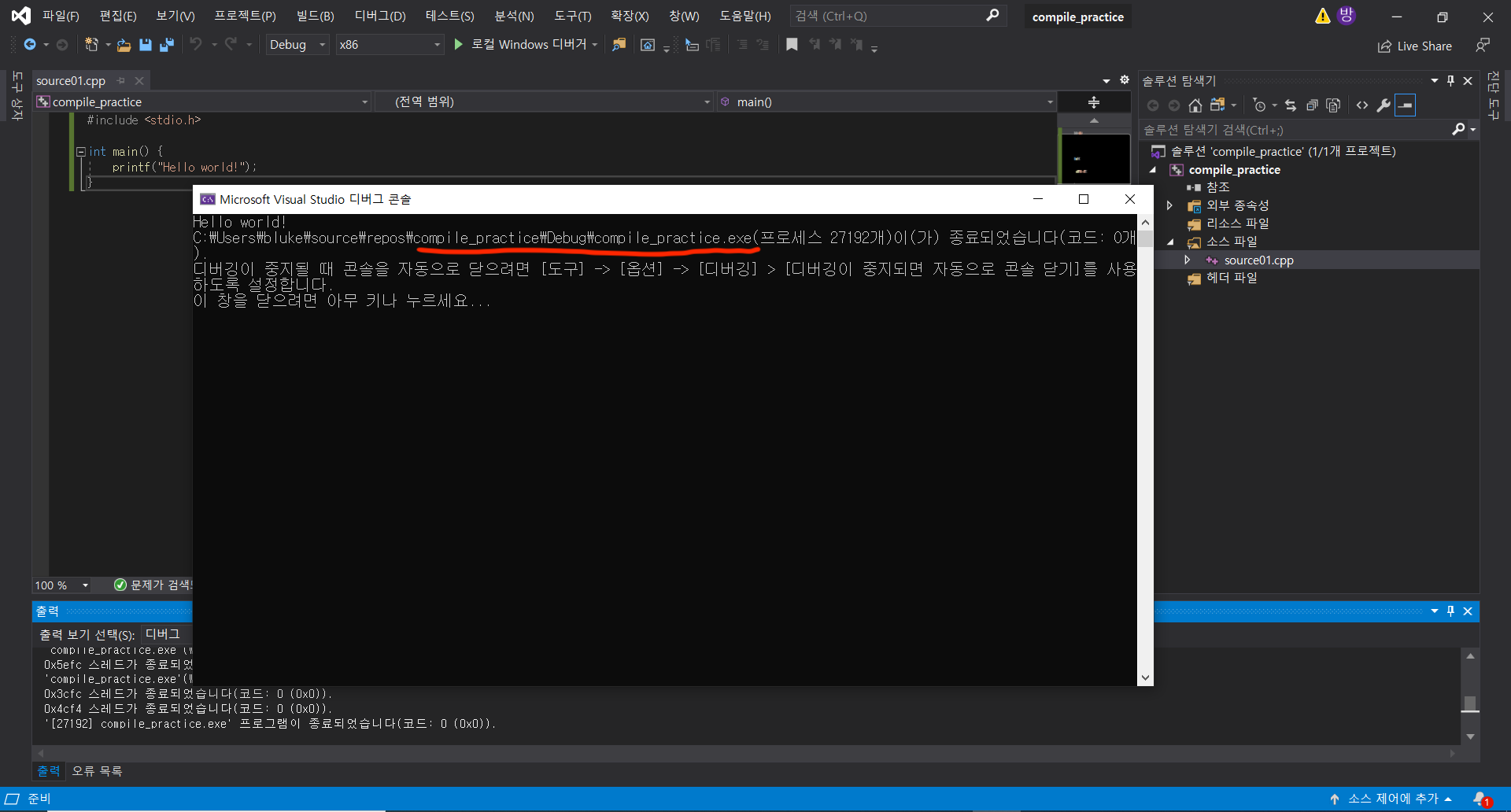
평소대로 F5 를 눌러 실행해보면!
우리는 분명 .cpp가 확장자인 c++ 파일을 만들고 실행하고자 했는데, 실행된 것은 해당 프로젝트 이름을 가진 compile_practice.exe 파일이다.
F5를 통해 실행을 누르면 Visual Studio가 compile과 link 과정을 거쳐 해당 프로젝트에 대응하는 하나의 .exe 파일을 생성하게 되고, 해당 .exe 파일을 바로 실행하기 때문이다.
만약 linking은 하지 않고, compile을 통해 object file만 생성하고싶다면 빌드 옵션의 컴파일을 선택하면 된다. 이렇게 되면 .exe 파일은 생성하지 않게 된다. (물론 이전에 생성된게 있다면 존재야 하겠지만 방금 컴파일한 내용이 업데이트된 버전은 아니다.)
또, 실행파일은 생성하고 싶지만 바로 실행은 하고싶지 않다면 빌드 옵션의 빌드를 선택하면 된다.
.exe 파일
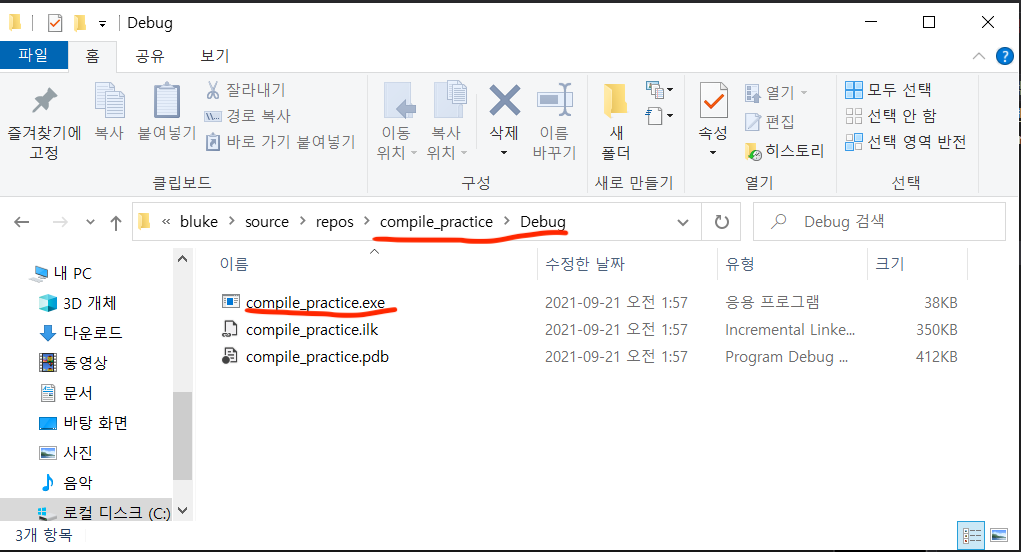
아무튼 이렇게 생성된 .exe 파일은 별다른 설정을 하지 않았다면 project_file/Debug/의 위치에 생성된다.
더블클릭하거나 터미널 커맨드로 바로 실행가능한데, 사용자와 상호작용하는 코드 (input과 같은 입력 함수)나 대기하도록 하는 명령어가 없을 경우 순식간에 실행된 후 꺼진다. (해당 exe파일은 "Hello World!"가 출력된 것을 확인하기도 전에 바로 꺼진다.)
이제 Compiler가 실행시간이 빠르다는 점이 이해가 될 것이다.
compile + linking (= build)하는 시간은 오래걸리지만, 결국 그 과정은 프로그램을 실행하는 Runtime과는 상관이 없다. source code에 수정사항이 없다면, 이미 빌드를 완료한 실행파일을 실행하기만 하면 되므로 매 실행 마다 해석하는 과정을 진행하는 Interpreter와 비교했을 때 실행 속도에 우위가 있는 것이다.
.obj 파일
그럼 exe파일이 생성되는 거는 확인했고, source code를 compile한 결과물인 object code는 어디에 있는지 확인할 차례이다.
그 전에 compiler가 해석할 source code를 하나 더 만들어보자! object code는 source code 1개당 하나씩 생성된다고 했으니 이 역시 눈으로 확인해보자.
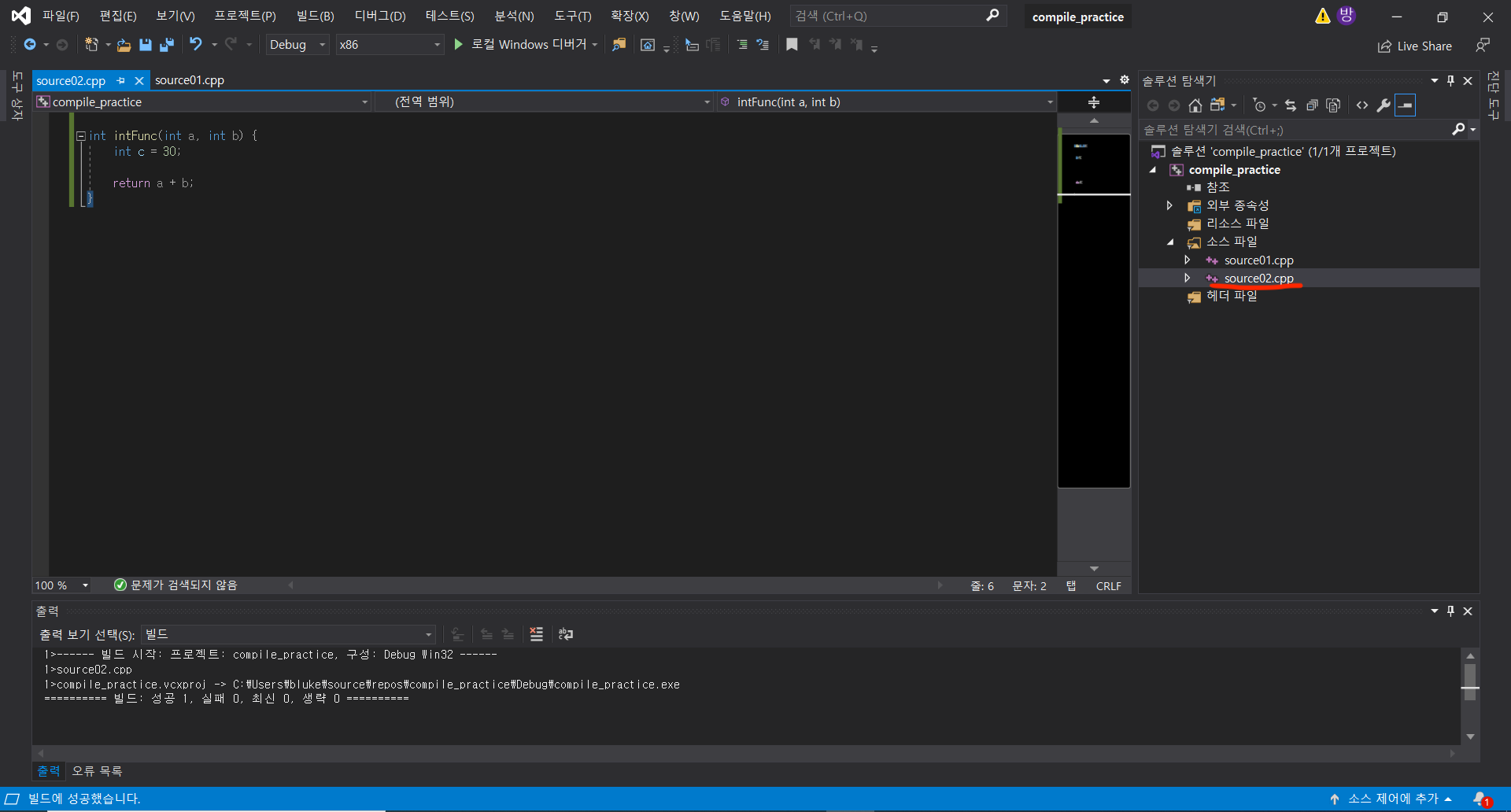
그냥 대충 소스파일 폴더에 새 .cpp 파일을 생성하고, 안에 덧셈 역할을 해주는 함수를 작성했다.
그리고 이걸 compile하면...
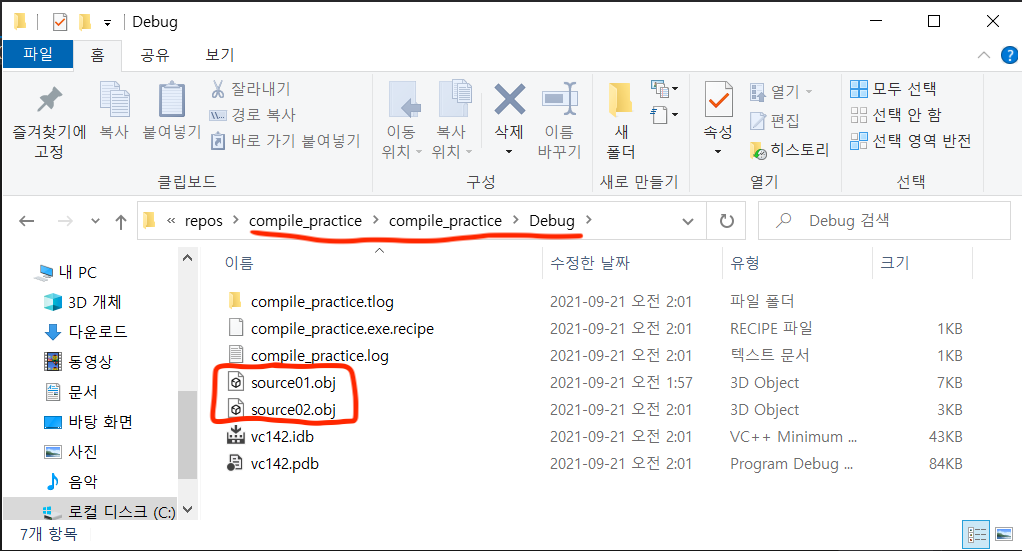
cpp 파일의 이름을 딴 object code가 1개 씩 생성된 것을 확인할 수 있다!
위치는 설정을 통해 변경하지 않았다면 project_name/project_name/Debug/ 이다.
Linker
Linker의 사전적 정의는 컴파일러나 어셈블러에 의해 생성된 하나 이상의 object file을 하나의 실행 가능한 파일 (혹은 라이브러리 파일이나 또 다른 object file)로 변환하는 시스템 프로그램이다.
지금은 겉핥기만 하는 것이니 library 파일로 변환하거나, 다른 object file로 변환하는 경우는 무시하도록 하자.
프로젝트 파일 내에 여러 개로 모듈화시켜, 분산된 소스코드들을 compiler나 compiler-assembler (이 경우에는 compiler가 assembly로 컴파일하고, assambler가 그걸 object로 변환한 경우)가 obj 파일로 만들었으면, 그걸 모아서 하나의 실행가능한 파일로 묶어주는 것이 linker의 역할이다.
Library
또한 Linker는 라이브러리를 관리해주는 역할도 수행한다.
라이브러리란,
사전적 정의를 보면 software를 개발할 때 program이 사용하는 비휘발성 자원 (non-volatile resource)의 collection이다.
쉽게 말하자면, 사람들이 자주 이용할 법한 기능들을 미리 만들어놓아서 언제든지 필요할 때 호출하여 사용할 수 있도록 해놓은 것을 말한다.
파이썬으로 예를들면 데이터 전처리에 유용한 numpy나 pandas 같은 것들이 있으며 주로 from ... import ... (as)를 통해 호출하여 이용하는 것들이 라이브러리이다.
사실 우리가 python에서 자연스럽게 이용하는 int, append, print 이런 것들도 파이썬에서 표준으로 제공하는 라이브러리다.
라이브러리는 주로 compile되어 목적코드 형태로 존재한다.
다시 c++의 예시로 돌아가보자
우리가 프로그램을 구현할 때 모든 것을 하나부터 열까지 코딩하기는 힘들다. 우리는 출력을 위한 명령인 printf을 이용하기 위해서 -source01.cpp의 맨 윗줄에 #include <stdio.h>를 선언했었다.
여기 있는 stdio.h가 바로 c언어의 표준 입출력 라이브러리 함수의 선을 담고 있는 헤더 파일이다. 이 라이브러리 안에 printf 함수의 선언이 있다.
printf라는 출력 명령을 유저가 설계하지 않고도 이용할 수 있는 이유는, 우리가 전처리기 부분에 라이브러리가 담긴 헤더파일을 include해주면 linker가 "user가 이 라이브러리에서 이 함수를 쓰고 싶어하는구나" 는 걸 인식해서 그걸 가져다 실행파일에 담아주기 때문이다.
이처럼 Linker는 source code에서 이용하고픈 라이브러리를 관리해주는 역할을 수행하기도 한다.
3.4 Compiler의 장단점
3.4.1 Pros
이제 object code가 뭐고, 왜 이게 메모리를 잡아먹는다고 했는지, 왜 runtime이랑 분석하는 시간이 분리되어있는지 이해가 되었으면 좋겠다!
"Build"를 누르면 열심히 Compile + Link 과정을 거쳐서 binary code로 된 executable한 program을 생성하게 된다. 이 program은 다시 번역할 필요 없이 두고두고 실행할 수 있다. 번역과 실행이 분리되어있기 때문에 빠르다는 것이다.
이 외의 장점을 더 말해보자면,
- 한 번에 전부 번역하니까 배포시 구문오류가 존재할 수 없다.
- 만들어진 실행파일을 실행만 하면 되니까 수행성능이 좋다.
- Compiler는 기본적으로 code optimization을 수행한다.
3.4.2 Cons
Compiler가 빌드한 실행파일들은 OS 별로 호환이 되지 않을 수 있다.
맨 처음 chapter (How computer runs program?)에서 program이 어떻게 실행되는지에 대해 되돌아보자.
instruction들, 즉 binary system을 실행하는 방식은 processor에 종속적이다.
processor가 인식해서 기능을 이해하고 실행할 수 있는 기계어 명령의 집합을 Instruction Set Architecture (ISA)라고 하고, 이 ISA는 프로세서마다 다르다.
즉, "101011011" 이라는 instruction을 memory에서 fetch했을 때 Intel에서 만든 cpu와 amd에서 만든 cpu, 그리고 M1 processor가 각각 다른 implementation을 내놓을 수 있다는 것이다.
Compiler는 빌드과정을 통해 source code을 분석해 특정 processor의 ISA에 맞는 실행파일 (machine code로 이루어짐)을 생성하게 된다. 특정 processor의 ISA에 종속되는 실행파일이라는 것은, 다른 processor는 실행할 수 없다는 뜻이고 이는 자연히 호환 문제로 연결된다.
따라서 배포자는 유저가 이용하는 processor에 맞는 실행파일을 제각각 빌드한 후 배포해야하고, 이게 바로 우리가 실행파일을 다운 받을 때 Mac OS, Linux, Windows 별로 따로 다운로드 받도록 하는 이유다.
3.5 Cross Compiler, Native Compiler
일반적으로 컴파일러라함은 네이티브 컴파일러를 뜻한다.
네이티브 컴파일러는 개발자가 이용하는 환경에서 실행가능한 파일을 생성한다. 따라서 윈도우 환경에서 네이티브 컴파일러로 빌드한 실행파일은 linux나 맥에서 실행이 불가능하다.
크로스 컴파일러는 개발자의 개발환경이 아닌 다른 CPU가 실행할 수 있는 코드로 컴파일하는 프로그램을 뜻한다. 즉, 윈도우에서 mac이나 linux 환경에서 실행가능한 code를 빌드한 것은 크로스 컴파일러를 이용한 것이다.
4. Interpreter
Interpreter란 프로그래밍 언어로 쓰여진 instructuion을 machine code로 compile할 필요 없이 한줄씩 번역해서 바로 실행하는 프로그램을 말한다.
Interpreter는 일반적으로 다음 셋 중 하나의 프로그램 실행 순서를 따른다.
-
source code를 parse하고 각각의 지시사항을 즉시 실행한다.
-
source code를 효율적인 intermediate representation이나 object code로 변환한 후 (compile), 즉시 실행한다 (interpreter로).
-
compiler에 의해 미리 compile된 code를 interpreter로 바로바로 실행한다.
Lisp 프로그래밍 언어와 같이 고전적인 interpreter 언어는 1번을 따른다. Interpreter의 기술적 특성 그 자체에 가까운 실행순서이다.
Perl, Python, MATLAB, Ruby 같은 언어들은 2번째를 따르며, UCSD Pascal은 3번째를 따른다. 2번째와 3번째를 섞을 수도 있다.
또한 기존의 compiler 언어인 Algol, fortran, cobol, c c++와 같은 것들을 지원하기 위한 인터프리터도 많이 나와있다.
Interpreter와 Compiler의 차이를 다룬 챕터에서 이야기 했듯이, Interpreter와 Compiler는 절대 상호 배타적인 기술이 아님을 기억하자. 대부분의 현대적인 interpreter 시스템은 compiler와 같은 translation work도 진행한다.
4.1 Interperter under the hood (Python Interpreter를 중심으로)
위에서 python은 source code를 intermediate code로 compile한 후 실행하는 방식을 따른다고 했다.
우선 Interpreter도 하나의 프로그램이라는 것을 알아두어야 한다.
python을 실행하기 위한 개발환경을 준비할 때, python.org에서 python x.xx.x 버전을 다운로드 받은 기억이 있을 것이다.
Python Software를 설치하면 해당 기기에 Python Interpreter와 Python이 지원하는 Library들이 설치된다.
이 interpreter가 있어야만 .txt 나 .py에 python 문법으로 적힌 텍스트들을 python 문법에 맞게 실행할 수 있다.
설치된 Python Interpreter는 Compiler와과 PVM (Python Virtual Machine)으로 구성된다.
다음 그림을 통해 Python Interpreter가 source code를 실행하는 과정을 살펴보자

-
source code 작성
# hello.py def main(): print("Hello world!") main() -
source code 실행
$ python3 hello.py- 앞에 쓴 python3, 혹은 python은 python interpreter를 뜻한다.
- 뒤에 나오는 text 파일을 python interpreter가 python 문법에 맞게 해석하고, 실행해달라는 의미의 명령이다.
-
Python Interperter의 Compiler가 source code를 받는다.
-
Compiler가 source code 각 줄의 syntax를 확인한다.
-
Compiler가 error를 발견할 경우 translation process를 멈추고 error message (Syntax Error)를 띄운다
-
Error가 없다면 source code를 Bytecode로 번역.
-
Bytecode를 Python Virtual Machine (PVM)에 전달한다.
-
PVM은 Bytecode + (input 과정이 있다면) user가 전달한 input + Library module을 가지고
-
Bytecode를 실행한다. 에러가 있다면 error message를 띄워준다 (Runtime Error)
-
실행에 Error가 없다면, output을 정상적으로 출력한다.
Hello world!
위처럼
$ python3 hello.py로 바로 실행하게 되면 python compiler가 번역한 bytecode는 메모리에 저장되지않는다.
근데 compile의 증거인 bytecode를 확인하고 싶다면?
$ python3 -m py_compile hello.py를 입력하면 된다. 이 명령은 PVM을 거치지 않고, compile만 수행하는 것이다.
그러면 .py 파일의 위치에 __pycache__ 폴더가 생성되고, 그 안에 python compiler가 번역한 bytecode가 저장된다.
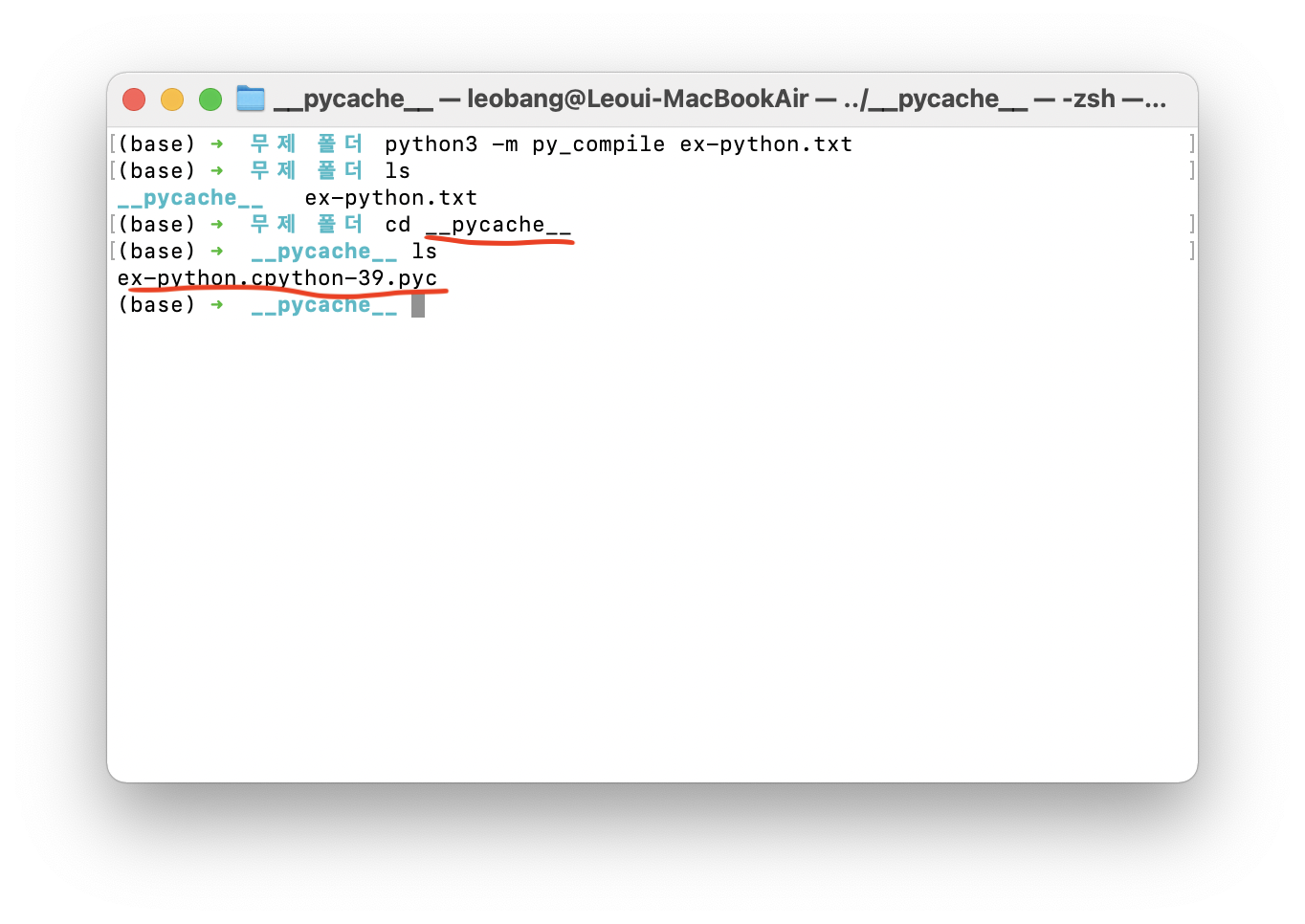
당연히 bytecode는 open 명령이나 더블클릭으로는 그 content를 확인할 수 없다.
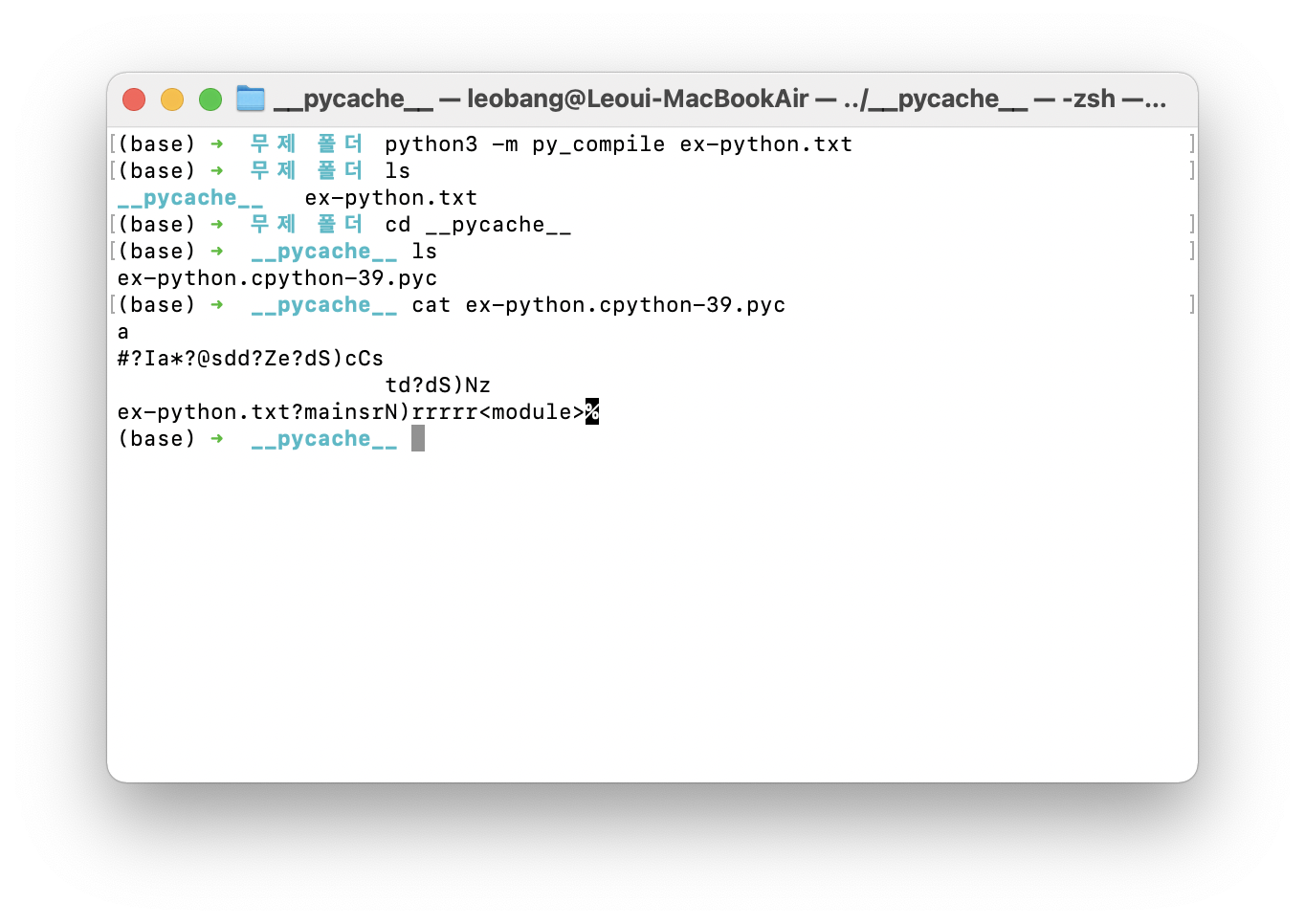
어차피 확인해도 이진코드로 작성된 것이라 알아볼 수 없는 형태지만, 그래도 확인해보고 싶다면
$ cat ex-python.cpython-39.pyc 을 입력하면 된다
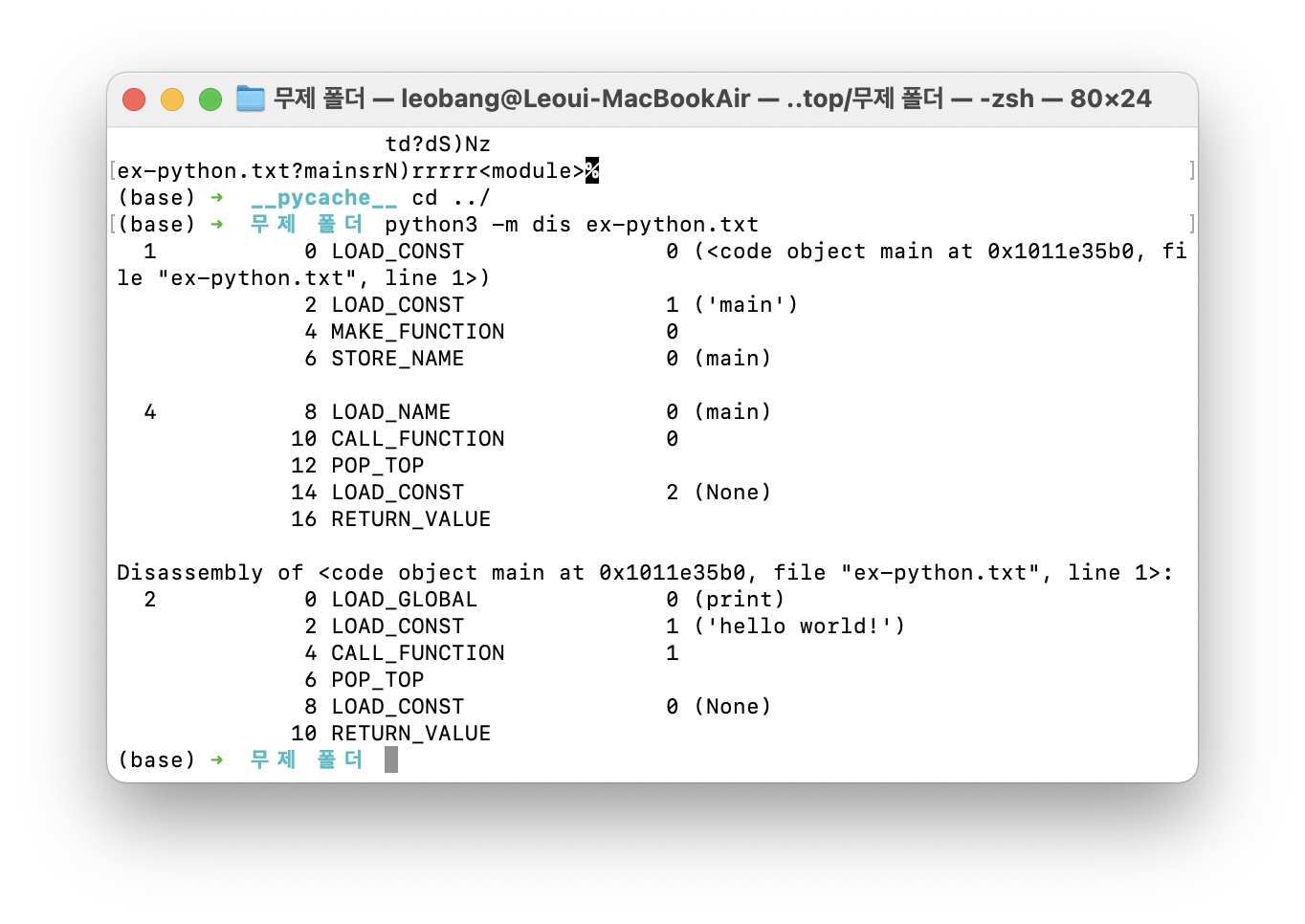
bytecode instruction들을 사람이 볼 수 있는 형태로 보고 싶다면
$ python -m dis ex-python.txt를 입력하면 된다.
4.2 Python Implementations
파이썬엔 다양한 Implementation들이 있다.
CPython
C언어로 만들어진 python implementation으로, python.org에서 python software를 설치했으면 default로 이용하는게 바로 Cpython이다.
일반적으로 Python Interpreter하면 CPython이라고 보면 된다.
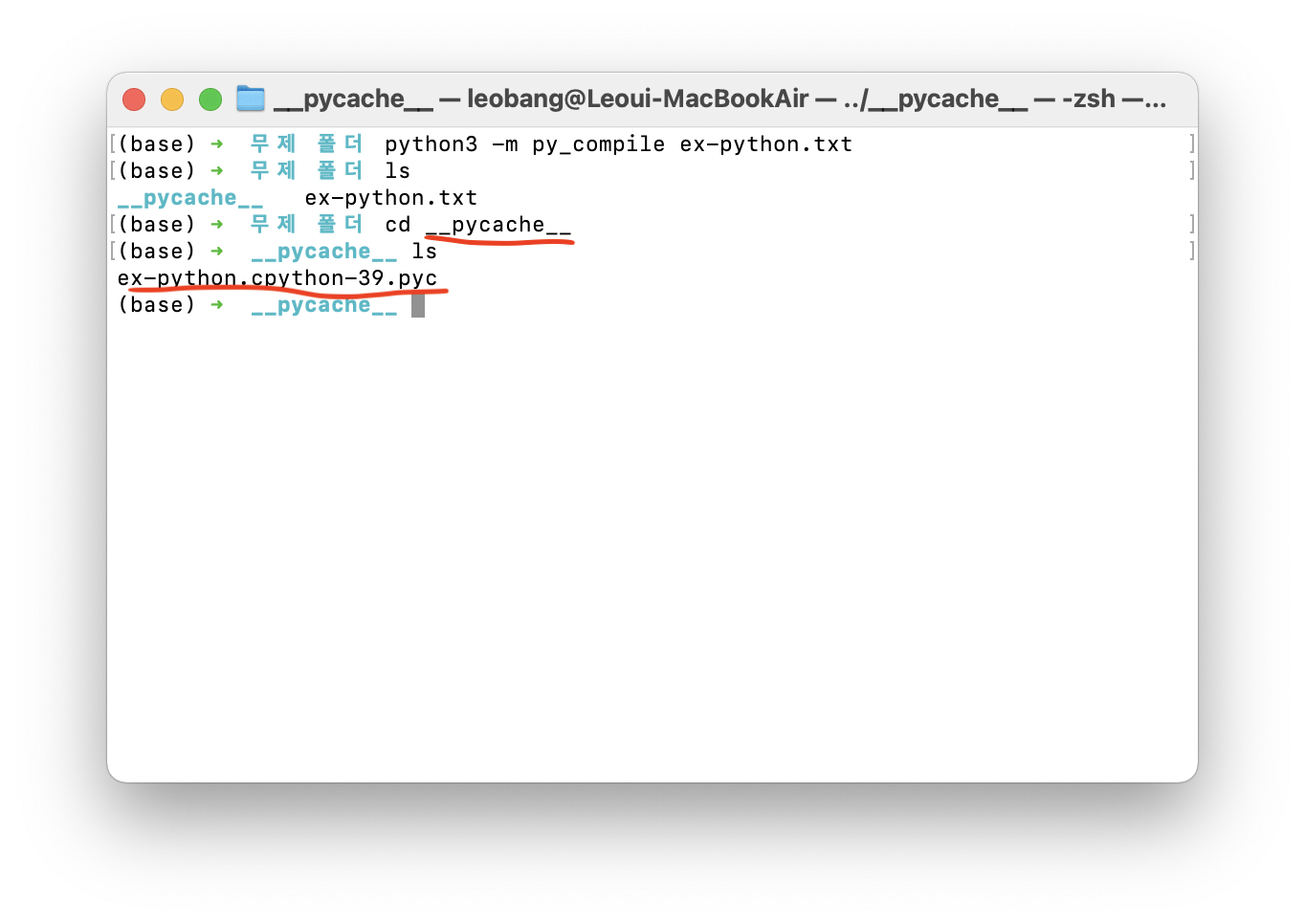
컴파일과정을 다시 보면, .pyc 확장자 앞에 cpython-39 가 붙은게 보인다.
CPython compiler로 .pyc 바이트 코드를 생성하고, Cpython virtual machine으로 바이트코드를 실행한다.
Jython
Python의 Java implementation이다.
Python 코드를 Java Bytecode로 변환하고, JVM이 그 bytecode를 실행한다.
CPython에 비해 느리다
IronPython
C#으로 쓰여진 python implementation. 닷넷 virtual machine을 이용한다.
다른 .NET 언어들도 이를 통해 python code를 쉽게 이용할 수 있다.
PyPy
Python으로 쓰여진 Python implementation. PyPy는 Bytecode를 실행할 때 JIT (Just-In-Time) 컴파일러를 이용한다.
JIT 컴파일러는 bytecode를 native machine code (맥이면 맥에 맞는 기계어)로 변환해서 python의 실행속도를 높여준다.
따라서 이는 기존의 default인 CPython보다 실행시간이 빠르며, 백준에 PyPy로 실행하면 기존 Python으로 실행했을 때 시간초과가 나던게 잘 통과되는 이유가 이것이다.
기타등등
Python이 인기있는 언어다보니, 다른 Python Implementation도 무지 많다. 궁금하면 직접 검색 ㄱㄱ
References
