
데이터베이스란?
in-memory 는 휘발성 메모리고, File I/O 는 원하는 데이터만 가져올 수 없고, 항상 모든 데이터를 가져온 뒤 서버에서 필터링 필요하다보니 서버 부하가 많이 걸리는 단점이 발생했다. 이 단점을 보완하기 위해 나타난 것이 데이터베이스이다. 여러 기능을 갖고 있는 데이터를 효율적으로 관리하기 위한 서버다.
데이터베이스는 별도의 인터페이스가 존재하지 않기 때문에 아래와 같은 SQL 언어를 통해 데이터에 접근할 수 있다.
//모든 열을 출력하라
SELECT *
// employee 테이블에서
FROM employee
// 성별이 M인 데이터들을
WHERE gender = 'M';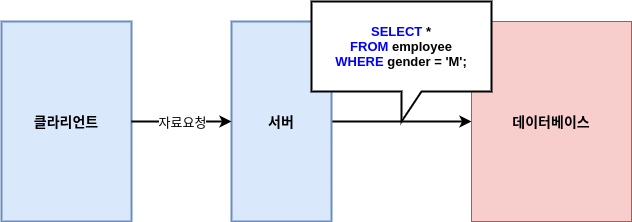
ORM = JS도 가능
SQL?(Structured Query Language)
구조화된 쿼리 언어로 DB용 프로그래밍 언어다. DB에 쿼리를 보내서 원하는 데이터만 뽑아올 수 있다.
Query : 저장되어있는 정보를 필터하기 위한 질문
ex) 검색창에 적는 검색어도 쿼리의 일종
Databse Tables
데이터베이스에서는 하나 혹은 그 이상의 'Table'이 존재하는데 각각의 테이블은 고유한 이름을 갖고 있다. 테이블 안에는 데이터가 기록된다.
주의사항
- SQL은 대소문자를 구분하지 않는다.
- 세미콜론은 각 SQL 구문을 분리하는 표준 방법이다.
- AND,OR 과 같은 논리연산자 사용시 각 연사자를 모두 '괄호'로 묶어주는 것이 좋다.
SQL 대표 키워드
SELECT
//테이블에서 특정 열
SELECT column1, column2, ...
FROM table_name;
//테이블의 모든 열 검색
SELECT * FROM table_name;- SELECT DSTINCT : 중복값을 제거해서 보여준다.
WHERE
SELECT 구문 외에도 UPDATE, DELETE 구문 등과 함께 사용할 수 있다.
SELECT column1, column2, ...
FROM table_name
//조건을 건다(필터링)
WHERE condition;문자열 검색 시, 따옴표를 사용하지만 숫자의 경우 따옴표가 없어도 된다.
- 연산자
AND, OR, NOT
- AND : 복합 조건
- OR : 하나 이상의 조건 만족 시, 출력
and, or은 원하는 만큼 추가할 수 있어서, 복잡한 필터링도 가능하다.
- NOT : 조건이 아닌 것만 출력한다
ORDER BY ... ASC | DESC
ORDER BY는 정렬 시, ascending 이 기본 값으로 매겨져 있다. ASC 순차 | DESC 역순정렬을 의미한다. ORDER BY 열1, 열2 일 경우, 열1이 정렬 기준이 된다.
INSERT INTO
테이블에 새로운 값을 넣는데 사용하는 구문으로, 2가지 방법이 있다. 예시
// 1.테이블의 특정 열에 넣는 경우 - 1:1 매핑
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);
// 2.테이블의 모든 열에 값을 넣는 경우
// 컬럼 순서대로 빠짐없이 넣지 않으면 에러가 날 수 있으므로 전자 방법을 추천
INSERT INTO table_name
VALUES (value1, value2, value3, ...);- 정의되지 않은 열은 NULL이 디폴트 값으로 잡힌다
- Primary Key 또는 Not NULL 의 경우, 데이터를 반드시 넣어줘야한다.
NULL
필드 값이 NULL인 경우는 해당 필드가 '값이 없다' 즉, 해당 필드는 비어있다는 것(blank)을 의미한다. '0'이나 '공백'을 가진 필드랑은 다른 의미이다.
비교연산자(=,<> 등)로는 NULL 값을 판별할 수 없다. 꼭 IS 혹은 IS NOT을 써줘야한다.
//IS NULL Syntax
SELECT column_names
FROM table_name
WHERE column_name IS NULL;
//IS NOT NULL Syntax
SELECT column_names
FROM table_name
WHERE column_name IS NOT NULL;UPDATE
테이블 안의 데이터를 '갱신/수정' 한다.
단, 여기서 주의해야할 점은 UPDATE 문에서 WHERE 절을 주목한다. WHERE 절은 업데이트할 레코드를 지정한다. WHERE 절을 생략하면 표의 모든 레코드가 업데이트된다!
//테이블을 갱신한다
UPDATE table_name
// 아래의 값들로
SET column1 = value1, column2 = value2, ...
// 조건에 해당하는
WHERE condition; DELETE
테이블 안의 데이터를 삭제한다.
UPDATE와 마찬가지로 WHERE 절을 주목한다. WHERE 절은 삭제할 레코드를 지정한다. WHERE 절을 생략하면 표의 모든 레코드가 삭제된다!
DELETE FROM table_name WHERE condition;COUNT 공식문서
SELECT COUNT(column_name)
FROM table_name
WHERE condition;- MIN,MAX,AVG,SUM 도 비슷하게 활용가능
LIKE 예시
열에서 특정한 패턴을 찾을 때 사용할 수 있다.
- 자주 쓰는 wildcards
- % : 0,1 또는 다중 문자, %의 위치에 따라 시작하는지, 끝나는 문자인지도 설정 가능.
- 'A%'
- '%A'
- '%A%'
- 'A%B'
- 'A%%'
- _ : single character
- % : 0,1 또는 다중 문자, %의 위치에 따라 시작하는지, 끝나는 문자인지도 설정 가능.

SELECT column1, column2, ...
FROM table_name
WHERE columnN LIKE pattern;//a로 시작하지 않는 고객이름을 모두 표현하라.
SELECT * FROM Customers
WHERE CustomerName NOT LIKE 'a%'; - AND 또는 OR 연산자와 함께 활용가능
// 고객이름이 a나 b로 시작하는 모든 열을 표시하라
SELECT * FROM Customers
WHERE (CustomerName LIKE 'b%' OR CustomerName LIKE 'a%');
// b로 시작하면서 세번째에 a가 위치한 고객이름을 가진 데이터를 표시하라
SELECT * FROM Customers
WHERE (CustomerName LIKE 'b%' AND CustomerName LIKE '__a%');WILDCARDS
- %
- _
- [] : 괄호 안에 포함된 문자열 찾기
- h[oa]t → hot 또는 hat, hit은 해당하지 않는다.
- ^ : 괄호 안에 제시한 문자를 포함하지 않은 문자열 찾기
- h[^oa]t → hit, hot과 hat은 제외한다.
- : 문자열의 범위
- c[a-b]t → a부터 b를 포함한 c-t 단어를 찾는다. cat, cbt
// O 나 M으로 시작하지 않는 도시 데이터를 나타내라
SELECT * FROM Customers
WHERE City LIKE '[!OM]%';
// 같은 결과
SELECT * FROM Customers
WHERE City NOT LIKE '[OM]%';ALIASES
- 임시이름에 공백이 있을 경우, []로 감싸주면 된다.(따옴표도 가능하다)
- 여러 데이터를 합칠 경우, + 기호로 엮어주고 ', ' 나 공백을 넣어서 합칠 수도 있다.
//Alias Column Syntax
SELECT column_name AS alias_name
FROM table_name;
//Alias Table Syntax
SELECT column_name(s)
FROM table_name AS alias_name; - Table과 함께 사용하는 Alias
// o = Orders의 약칭, c = Customers의 약칭
SELECT o.OrderID, o.OrderDate, c.CustomerName
FROM Customers AS c, Orders AS o
// Customers 테이블의 고객명이 A~ 이면서 ID가 OrderID가 같은 데이터를 추출
WHERE c.CustomerName='Around the Horn' AND c.CustomerID=o.CustomerID; JOINS
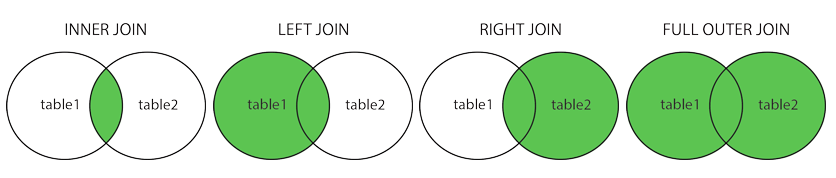
JOIN .. ON 구문은 2개 혹은 그 이상의 테이블을 합치는 명령어인데, 해당 테이블의 열들이 관련되어있다는 것을 기반으로 둔다.
- INNER JOIN : 디폴트 값, 두 테이블에서 매칭되는 값을 반환한다.
- LEFT (OUTER) JOIN : 우측 테이블과 매칭되는 좌측 테이블의 모든 값을 반환한다. From 절이 left! 즉 이 테이블을 기준으로, join 절의 right 값을 붙여나간다.
- RIGHT (OUTER) JOIN : 좌측 테이블과 매칭되는 우측 테이블의 모든 값을 반환한다. LEFT와 반대개념
- FULL (OUTER) JOIN : 우측 혹은 좌측에서 매치되는 모든 값을 반환한다.
참고 학습자료 : 생활코딩
GROUP BY
지정한 열을 기준으로 그룹으로 묶어서 요약을 해준다. COUNT 등과 함께 쓸 수 있다.
- HAVING 은 그룹화를 끝낸 후 제시하는 '조건문'으로 WHERE과는 다르다.(WHERE는 그룹화 전에 진행한다.)
SQL DataBase
DATABASE 관련
- CREATE DATABASE 데이터베이스이름
- DB를 생성한 후,
SHOW DATABASES를 통해 잘 생성되었는지 확인할 수 있다. - DROP DATABASE 데이터베이스이름 : DB 삭제
- BACKUP DATABESE 데이터베이스이름 TO DISK = '경로' : DB 백업
TABLE 관련
- CREATE TABLE 테이블명 : 새로운 테이블 생성
- SHOW TABLES : 생성된 테이블 목록 출력
- DESCRIBE 테이블명 : 테이블 구조 조회
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
column3 datatype,
....
); 만약 기존에 만들어둔 테이블의 형태와 특정 데이터를 가져온 테이블을 제작하고 싶을 때도 만들 수 있다. 예시
CREATE TABLE new_table_name AS
SELECT column1, column2,...
FROM existing_table_name
WHERE ....; - DROP TABLE 테이블명 : 테이블 삭제
- TRUNCATE TABLE 테이블 : 테이블 안의 데이터만 삭제(데이터 복구 불가)하는데 보통 '조건없이 모든 행 삭제 시 사용'한다. 보통은 DELETE 사용
- ALTER TABLE
존재하는 테이블 안에서 '열'을 추가/삭제/수정하는 명령어이다.
// 열 추가
ALTER TABLE table_name
ADD column_name datatype;
// 열 삭제
ALTER TABLE table_name
DROP COLUMN column_name;
// 열 데이터 타입 수정
ALTER TABLE table_name
ALTER COLUMN column_name datatype; SQL Constraints(제약조건)
- NOT NULL : NULL 값 입력 금지
- UNIQUE : 중복값 입력금지(NULL은 가능)
- PRIMARY KEY : NOT NULL+UNIQUE
- FOREIGN KEY : 다른 테이블 컬럼 조회+무결성검사
- CHECK : 조건으로 설정된 값만 입력 허용
- DEFAULT : 기본값 세팅
- INDEX : DB에서 데이터를 빠르게 검색하거나 만들 때 사용
//DATA TYPE 수정
// int로 설정된 Age 열의 데이터 타입을 NOT NULL로 수정
ALTER TABLE Persons
MODIFY Age int NOT NULL; //MySQL
ALTER TABLE Persons
ALTER City SET DEFAULT 'Sandnes'; 생성한 제약조건 확인 및 추가/삭제
select * from information_schema.table_constraints;SQL AUTO INCREMENT
고유 숫자를 자동적으로 생성해주는 역할을 한다. 새로운 데이터가 들어올 때마다 1씩 증가한다.
CREATE TABLE Persons (
Personid int NOT NULL AUTO_INCREMENT,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Age int,
PRIMARY KEY (Personid)
);SQL Dates
- MySQL
- DATE - format YYYY-MM-DD
- DATETIME - format: YYYY-MM-DD HH:MI:SS
- TIMESTAMP - format: YYYY-MM-DD HH:MI:SS
- YEAR - format YYYY or YY
SQL Data Types
