[논문리뷰] VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
VGGNet에 대한 논문입니다.

(초록)
큰 스케일의 image recognition에 있어서 convolutional network의 깊이의 정확도에 기여한 것으로 이러한 주된 정확도 기여에는 아주 작은 3x3 convolution filters를 사용한 구조를 깊게 쌓음으로써 달성한 것을 알 수 있습니다. 그리고 2014발표 당시 굉장히 성능면에서나 범용성의 분야에서나 computer vison분야에 큰 발전에 기여한 것을 알 수 있습니다.


(introduction)
convolution networks는 large-scale image와 video recognition에서 이미 좋은 성능을 내는 networks입니다. 그리고 계속해서 이러한 얇고 고차원의 특징들을 사용함으로써 깊은 시각 인지 구조로써의 중요한 역할을 해왔는데 이러한 구조에 많은 시도를 통해서 더 나은 성능을 낼 수 있도록 만들었습니다. 예를들면 더 작은 반응형 창사이즈와 더 작은 stride를 첫번째 convolution layer에 적용한다던가 하는 방법 등과 같이 방법을 취함으로써 convolution network의 발전을 시켰습니다. 그리고 이 논문에서는 우리는 ConvNet구조의 디자인 중 그것의 깊이에 주목하였습니다. 결과적으로 구조의 다른 파라미터는 고정시키고 convolution filter들을 계속 쌓음으로써 그 network의 깊이를 증가시켰습니다. 그리고 이렇게 구조를 쌓을 때 아주 작은 3x3 convolution filter를 모든 layer에 사용하였습니다.
그리고 이러한 방법을 취함으로써 결과적으로 더 정확한 ConvNet architecture를 만들어 냈으며 이는 정확도뿐아니라 다른 이미지 인식 dataset에서도 좋은 성능을 보이며 이를 단순한 파이프라인으로 만들어 냈습니다.
2번sect에서는 ConvNet의 구조를 묘사하고 3번 sect에서는 image classification의 training과 평가의 디테일들을 보며 sect4에서는ILSVRC의 clssification task와 비교해서의 구조적 차이를 비교하고 sect5에서는 논문을 마무리합니다. 부록 A의 ILSVRC-2014 객체 위치 파악 시스템을 설명하고 평가하며 부록 B의 다른 데이터 세트에 대한 매우 심층적인 기능의 일반화에 대해 논의하고 마지막으로 부록 C에는 주요 논문 수정 목록이 포함합니다.

나머지 조건이 동일한 상태에서 convNet의 깊이 증가로 인한 개선을 측정하기 위해 모든 ConvNet계층 구성은 Ciresan et al.(2011); Krizhevsky et al.(2012)와 동일한 원리로 설계되었습니다. 그렇다면 2.1에서 ConvNet구성의 일반적인 레이아웃을 설명한 다음 2.2에서 평가에 사용된 특정 구성을 설명,설계에서의 선택에 대해 논의하고 이전과의 비교를 2.3에서 진행합니다.

input으로 들어오는 ConvNets은 고정된 사이즈 224x224를 갖습니다. 그리고 이때 우리가 유일하게 전처리할 수 있는 것은 평균rgb값을 빼는 것 뿐이며, 그 이미지는 아주 작은 필터 3x3필터를 사용하는 convolutional layers의 stack을 통과시킵니다.
그외에도 input channels의 선형 변형으로 보이는 1x1 convolution filter또한 사용합니다.
convolution stride는 1 pixel로 고정하며 컨볼루션 레이어 인풋의 공간적인 패딩은 마치 컨볼루션 이후의 spartial resolution의 보존과 같습니다. 몇가지의 컨볼루션레이어를 따르는 5개의 max-pooling layers에 의해 spartial pooling은 수행되며 max-pooling은 stride가 2인 2x2 pixel창으로 수행되어집니다.
convolution layers의 stack 각각은 서로 다른 깊이의 서로 다른 구조를 갖추고 있는데 이러한 stack은 fully-connected layers를 따릅니다. 또한 그 첫번째 2개는 4093개의 channels를 각각 갖추고 있으며 그 세번째는 1000가지의 분류를 수행하므로 1000개의 채널을 포함합니다. 그리고 마지막 계층은 soft-max layer로 구성되어 있습니다. 이렇게 완전히 연결된 계층들은 모든 네트워크에서 동일하며 모든 hidden layer들은 Relu를 통해 비선형성을 갖추고 있습니다.
그런데 이때 이 네트워크에서 하나를 제외하고 LRN정규화를 포함한다는 점에서 이러한 정규화는 memory consumption이나 computation time을 증가시킨다는 단점이 존재하는 것을 알 수 있었습니다.

2.2에서는 앞에서 말했듯이 평가에 사용된 특정 구성에 대해 설명하는데 모든 구성은 2.1절에 제시된 일반적인 설계를 따르며 네트워크 A의 11개 가중치 레이어(8개의 변환 및 3개의 FC 레이어)부터 네트워크 E의 19개 가중치 레이어(16개의 변환 및 3개의 FC 레이어)까지 깊이만 다른 것을 알 수 있습니다. ConvNet의 폭(채널 수)은 첫 번째 레이어에서 64개로 시작하여 각 최대 풀링 레이어가 512개가 될 때까지 2배씩 증가합니다. 2.3에서 나오는 표2를 보면 깊이가 깊음에도 불구하고 네트워크의 가중치의 수가 더 얕고 넓은 레이어의 가중치수 보다 크지 않은 것을 알 수 있습니다.

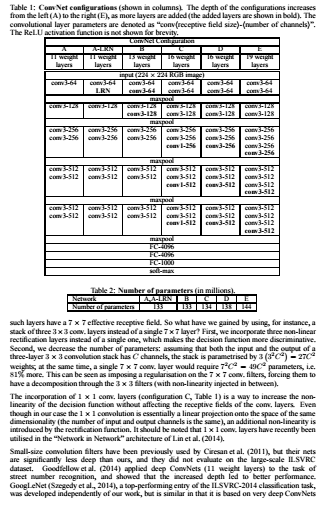

이전에 있었던 네트워크와 다른점을 꼽자면 앞서 말했듯이 아주작은 필터를 사용한다는 것인데 다른 네트워크에서는 7x7x1을(넓고 얇은 필터) 사용하는 것과 다르게 3x3x3(좁고 깊은 필터)사용한다는 것이고 그리고 스트레이드 1을 사용함에 따라서 5x5의 수용 필드를 갖는다는 것을 알 수 있습니다.
표1에서 볼 수 있듯이 A에서 E로 갈 수록 depth가 깊어지는 것을 알 수 있습니다. 또한 그리고 ReLU는 간결성을 위해 쓰지않았습니다.
그렇다면 7X7대신에 3X3X3 layer를 써서 얻는 장점은 무엇이 있는가?
1) 1개 대신에 3개의 비선형성 수정 layers들을 얻을 수 있다. 또한 이것은 decision funciton을 더 식별가능하게 해주는 것을 알 수 있다.
2) 파라미터 개수를 줄일 수 있다. layer당 채널 C가 있다고 할 때, 파라미터 개수는 7x7일때는 49C^2이고 3x3일때는 27C^2인 것을 알 수 있다.따라서 1 × 1 의 1 층의 통합은
Conv 레이어의 수용 필드에 영향을 주지 않고 decision function의 비선형성을 증가시킵니다.
작은 크기의 컨볼루션 필터는 이전에 Ciresan et al. (2011)에서 사용되었지만 net의 깊이가 우리보다 현저히 낮으며 대규모 ILSVRC 데이터 세트에서 평가하지 않았습니다.
그러나 이후에 대규모 ILSVRC 데이터 세트의 classification작업의 최상위 항목인 googleNet와 유사하지만 그들의 topology가 더 복잡하며 feature map 중 첫 번째 레이어에서 더 공격적으로 축소하여 계산량을 줄인다는 것을 알 수 있었습니다. 또한 4.5절에서 볼 수 있듯이, 우리 모델은 Szegdy et al. 의 모델보다 성능이 뛰어난 것을 알 수 있었습니다.


3.1에서는 training을 어떻게 시키는지를 볼건데 먼저 이 ConvNet Training 절차는 일반적으로 Krizhevky et al을 따릅니다.즉, training은 모멘텀을 갖춘 미니 배치 gradient-descent를 사용한 multinomial logistic regression objective의 방식을 따르고 있습니다. 이때 batch size는 256, 모멘텀은 0.9로 set되어있으며 그 학습은 weight-decay와 dropout 정규화를 첫번째 2개의 fully-connected layers에 적용함을 통해 정규화 되고있습니다. 그 learning rate는 초기에는 10^-2로 설정되어 있지만 그리고 validation set의 정확도가 향상되지 않았을 때 10배 감소합니다. 종합적으로 learning rate는 3번 감소되어지며 학습은 370K의 반복을 했을 때 중단됩니다, 그런데 우리는 Krizhevsky et al., 2012에 비해 더 많은 수의 매개변수와 더 큰 깊이에도 불구하고, 더 큰 깊이와 더 작은 Conv filter size(즉, 특정 layers의 미리 초기화된)에 의해 제기된 암묵적인 정규화로 인해 network이 수렴하는 데 더 적은 에포크가 필요하다고 추측합니다.
그리고 네트워크 가중치의 초기화는 딥 네트의 기울기 불안정성으로 인해 학습이 지연될 수 있기 때문에 중요합니다.
그리고 이러한 문제점을 완화하기 위해서 우리는 Table1의 A와 같이 시작했습니다. 즉 랜덤 초기화와 함께 train될 얇은 층을 갖춘 뒤 더 깊은 구조를 training할 때 우리는 첫번째 4개의 convolutional layers를 초기화 하고 net A의 층을 갖춘 그 마지막 세개의 fully-connected layers둡니다. 그리고 사전 초기화된 layers를 위해 learning rate를 줄이지 않습니다. 그리고 랜덤 초기화를 위해 우리는 정규분포로부터 가중치를 sampled하고 그 biases는 0으로 초기화 되어집니다. 그리고 Glorot & Bengio (2010)의 방법대로 랜덤초기화를 사용하여 pre-trainning없이 가중치를 초기화하는 것이 가능한 점에서 괄목할만 하다고 볼 수 있습니다. 처음 cropped 된 size는 224x224이고,그리고 이 사이즈는 training image의 가장 작은 이미지 사이즈이며 학습시킬 이미지는 224보다 커야합니다.
그리고 언급된 trainig scale S는 2가지의 approaches를 고려해야되는데 첫번째 approach는 S를 수정한다는 것입니다. 우리는 실험에서 S=256 와 S=384로 주어진 구조에서 우리는 처음에는 256사이즈를 사용하다가 training을 빠르게 하기 위해서는 384를 사용합니다.두번째 approach는 S는 multi-scale trainning으로 설정되어 있다는 것입니다. rkrrkrdml training image는 개별적으로 rescaled되어질 수 있는데 가장 작은 사이즈인 256에서 가장 큰 사이즈인 512까지 가능합니다. 그리고 이미지 안의 객체들이 각각 다른사이즈이기 때문에 training할 때 이러한 점은 이점으로 작용하는것을 알 수 있습니다. 그리고 이것은 또한 scale jittering에의해 training set의 증강처럼 보입니다, 그리고 스피드의 이유로 우리는 S=384의 고정된 미리 trained된 같은 구조로 되어있는 single-scale model의 모든 층들을 fine-tunning함으로써 우리는 다중 스케일 모델들을 학습합니다.

3.2에서는 test time에서는 주어진 trained된 ConvNet과 input이미지를 사용하여 진행되는데 첫째로 미리 정의된 가장 작은 이미지사이드는 등방성으로 rescaled되어집니다. 그리고 이렇게 rescaled된 것을 Q라고 명시하고 이후에 설명하면 Q는 S와 같을 필요가 없으며 따라서 네트워크는 리스케일링된 테스트 이미지 위에(Serman et al., 2014)와 유사한 방식으로 촘촘하게 적용됩니다. 즉, fully-connected layer들은 첫번째로 convolutional layers로 바뀌고 (FC에서 7x7로 그리고 마지막 2개의 FC들은 1x1 layer로)그 결과 fully-convolutional net는 그 다음 전체(크롭되지 않은)이미지로 적용된다. 따라서 그 결과 채널의 개수가 함께있는 class score map의 결과는 class의 개수와 동일하게된다. 마지막으로 이미지를 위한 class scores의 고정된 벡터를 얻기위해 그 class score map은 공간적인 평균을 낼 수있는 것을 알 수 있습니다, 그리고 우리는 또한 그 이미지의 수평flipping을 함으로써 그 test set을 보강시킬수 있다.
FC network가 전체 이미지에 적용되기 때문에 test time에 sample multiple crops를 할 필요는 없습니다. 동시에 크롭의 큰 set를 사용하면서 정확도를 개선시킬수 있고 결과적으로 FCnet과 비교했을때 정교한 샘플링을 할 수 있습니다.또한 multi-crop 평가는 다른 convolution boundary conditions 이기 때문에 더 촘촘한 평가를 보완할 수 있습니다.: ConvNet을 크롭에 적용할 때 컨볼루션 특징 맵은 0으로 패딩되는 반면, 고밀도 평가의 경우 동일한 크롭에 대한 패딩은 이미지의 이웃 부분에서 자연스럽게 나오므로 전체 네트워크 수신 필드가 크게 증가하므로 더 많은 context를 얻게 됩니다. 반면에 우리는 다중크롭의 계산시간의 증가가 정확도의 향상을 가져오지 않는다는 것을 알 수 있다.

3.3장에서는 우리는 the publicly available C++ Caffe toolbox, multiple GPUs installed in a single system가 있었기에 위와 같은 실험이 가능했던 것을 알 수 있었습니다.


dataset. 4장에서는 우리는 image classification의 결과들이 ILSVRC-2012 dataset을 이용하여 Convnet의 구조를 설명한 것이며 이 dataset은 1000개의 classes의 이미지를 포함하는 것을 알 수 있습니다.그리고 이 데이터셋은 1.3M의 images의 training set,50K images의 validation, 그리고 100K images with held-out class labels의 testing set이 있는 것을 알 수 있었습니다.주로 이실험에서는 validset과 testset을 사용하였습니다.
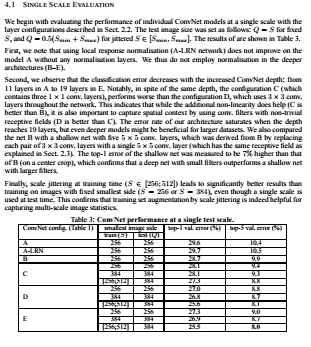
4.1(Single Scale Evaluation) 우리는 2.2에서 묘사된 single-scale 의 성능을 평가하면 먼저 test image size는 Q=S로 고정되어 있는 것을 알 수 있습니다. 그리고 이때 Q는 (Smin+Smax)/2로 set되어있습니다 이에 대한 결과는 표3에서 볼 수 있으며 첫번째로 우리는 지역 반응 정규화를 이용한 A-LRN을 볼 수 있습니다. 먼저, 로컬 응답 정규화(A-LRN 네트워크)를 사용해도 정규화 계층이 없는 모델 A에서 개선되지 않는다는 점에 주목합니다. 우리는 그래서 B-E모델에서 처럼 더 깊은 구조에는 정규화를 적용하지않도록 하였습니다.
두번째로 우리는 ConvNet 깊이가 증가함에 따라 분류 오류가 감소하는 것을 볼 수 있습니다. 11층에서 19층 즉, A에서 E까지. 깊이가 증가함에 따라 오류가 감소하였습니다. 그리고 C와 D는 같은 깊이임에도 불구하고 D에서는 3x3 conv층을 추가하였기 때문에 더 좋은 성능을 낸 것을 확인 할 수 있었습니다. 이것을 통해 우리는 추가적인 비선형성이 돕는 것과 더불어서 trival receptive fields가 없는 컨벡터 필터를 사용하여 공간 정보(spartial context)를 캡처하는 것도 중요합니다.그리고 E와 같이 깊은 모델은 오류율이 포화되지만 더 큰 데이터셋에서는 유용할 수 있습니다. 우리는 또한 5x5conv layer를 갖춘 B와 비교하면 얕은 net의 상위 1개 오차는 B보다 7% 높은 것으로 측정되었으며, 이는 작은 필터가 있는 깊은 net이 큰 필터가 있는 얕은 net보다 성능이 우수함을 확인시켜줍니다.
마지막으로 training time에서 scale jittering은 고정된 작은 사이드의 이미지를 training하는것보다 더 나은 결과를 내며 이것은 scale jittering을 통한 training set 증강이 multi-scale image statistics capturing에 분명한 도움을 주는 것을 알 수 있습니다.

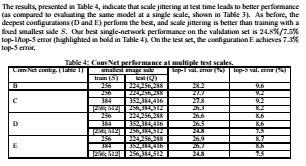
4.2에서는 테스트 시간에 스케일 지터의 영향을 평가합니다.테스트 이미지의 스케일 재조정된 여러 버전에 대해 모델을 실행한 다음(Q의 다른 값에 해당) 결과 클래스 값을 평균화하는 것으로 구성됩니다. 훈련 척도와 테스트 척도 간의 큰 불일치가 성능 저하로 이어진다는 점을 고려하여 고정 S로 훈련된 모델은 훈련 이미지에 가까운 세 가지 테스트 이미지 크기에 대해 평가되었습니다: 다음과 같습니다.{S − 32, S, S + 32} 동시에 training time에 scale jittering은 test time에 있어서 더 넓은 scales에 적용되는 network를 허용할수 있도록 해줍니다. 결과적으로 표4에 따른 것 처럼 test time에 있어서 scale jittering은 표3에서보이는 것과 같이 single scale에서 같은 모델을 평가한 것과 비교한 것처럼 더 나은 성능을 보여주는 것을 알 수 있습니다.
그 전에 더 깊은 구조인 D와 E는 최고의 성능을 보여주며 scale jittering은 고정된 가장작은 side 인 S와 함께 training할때 더 나은 것을 알 수 있습니다.
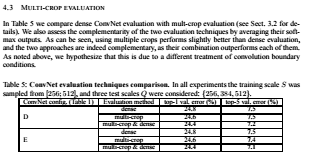
4.3에서는 multi-crop evaluation과 함께한 dense ConvNet 평가를 비교한 표5를 볼 수 있는데 우리는 소프트맥스 출력을 평균하여 두 평가 기법의 상호보완성을 평가합니다. 표에서 볼수있듯이 multi-crop & dense를 사용한 것이 나머지 것들보다 더 나은것을 확인 할 수 있습니다.그리고 이러한 결과는 컨볼루션 경계 조건의 다른 처리 때문이라고 가정합니다.

4.4에서는 우리는 소프트-맥스 클래스 후 순위를 평균화하여 여러 모델의 출력을 결합합니다.
표6에서 볼 수 있듯이 ILSVRC submission이전까지는 D로 좋은 성능을 냈었습니다다. 그러나 이 ILSVRC submission에서 D와 E의 두가지의 조합으로 error를 더 낮춘것을 볼 수 있었습니다.

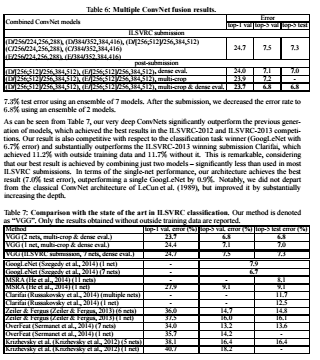
4.5에서는 결론적으로 표7에서 볼 수 있듯이 ILSVRC-2014 challenge에서 classification task주제로 VGG team은 7.3%로 2등을 차지했으며 submission 이후에 error rate를 6.8까지 낮췄습니다.

5장에서는
결론적으로 이번 과제에서 우리는 더 깊은 convoltional networks(19개까지의)를 large-scale image classification에 적용하여서 평가되었으며 이것은 곧 표현 깊이가 분류 정확도에 유리함을 입증하였고,그리고 우리는 또한 우리의 모델이 더 적은 심층 이미지 표현을 중심으로 구축된 더 복잡한 인식 파이프라인과 일치하거나 성능이 뛰어난 광범위한 작업 및 데이터 세트와 같은 것들에 대해 잘 일반화된다는 것을 보여줍니다.다시말해 이러한 결과는 우리의 결과는 시각적 표현에서 깊이의 중요성을 다시 확인합니다.
------------------정리하자면------------------------
VGGNet은 합성곱층의 파라미터 개수를 줄이고 훈련시간을 개선하려고 탄생한 것으로 VGGNet16은 D, VGG19는 E로 layers 개수에 따라 여러 유형의 VGGNet이 있는 것을 알 수 있습니다.
그 중에서 VGG16을 보면 VGG 16의 파라미터는 총 1억 3300만개가 있으며 합성곱 커널의 크기는 3x3,최대 풀링 커널의 크기는 2x2이며 stride는 2입니다.
