
- 외국인 발화 한국어 음성 인식률 향상 해커톤에 참가하면서 한국어 STT를 공부하고 구현한 내용을 정리해 보려 한다.
- 이번 포스터에서는 STT가 무엇인지, 실제 사용했던 오픈소스인 Kospeech에 대한 설명, 기본적인 개발환경 구축에 대해 작성할 생각이다.
STT란?
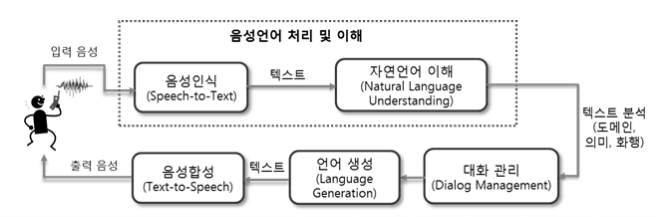
음성인식(Speech Recognition)이란 사람이 말하는 음성 언어를 컴퓨터가 해석해 그 내용을 문자데이터로 전환하는 처리를 말하며 STT(Speech-to-Text)라고도 한다.
기존에 상용 서비스에 적용되는 음향 모델의 대부분은 확률 통계 방식인 HMM(Hidden Markov Model) 기반으로 이루어졌으며, 2010년대 들어서면서 딥러닝 기반으로 HMM/DNN 방식으로 단어 인식 오류를 개선하여 20% 성능 향상을 이루어 냈다.
최근에는 시퀀스-투-시퀀스(Sequence-to-Sequence) 방식의 RNN 기반으로 속도와 성능 면에서 좋은 결과를 가져오면서, 음성 인식에서도 번역어(End-to-End) 학습 방식의 발전으로 일련의 오디오 특징을 입력으로 일련의 글자(character) 또는 단어들을 출력으로 하는 단일 함수를 학습할 수 있게 되었다. 또한 CTC(Connectionist Temporal Classification) 이라는 모델로 입력 데이터와 레이블 사이의 음성 정렬(alignment) 정보가 없어도 학습이 가능하게 되었다. 이와 같은 다양한 학습법을 통해 계속해서 STT의 성능은 향상되고 있다.
아래 링크를 통해 최근 STT 모델들의 WER(단어 오류율)과 CER(문자 오류율)을 확인할 수 있다.
모델 선정
먼저 STT 오픈소스 모델을 선정할 때 2가지 정도를 고려했다.
- 외국인 발화 한국어 음성의 경우 내국인 발화 음성과는 구분되는 특성이 있을 것이라는 여러 연구 결과에서 근거를 얻어 외국인 발화 음성만으로 학습시킨 모델을 만들고, 그 성능을 Pre-trained 모델과 비교해 볼 필요가 있다
- 한국어 음성으로 구현된 STT 모델이 있는지 여부를 고려했는데, 대부분 오픈소스 STT 모델들은 그 성능이 영어에 한정해서 알려져 있었기 때문에, 한국어 음성에 대해서도 검증된 사례가 있는지 여부가 중요했다.
- 그 결과 Kospeech가 제공하는 다양한 어쿠스틱 모델 중에서도 성능이 가장 우수한 것으로 알려진 Deepspeech2를 베이스 모델로 선택했다.
Kospeech
👉 깃허브
👉 Kospeech 설명 영상

-
Kospeech는 2020년 김수환이라는 개발자가 공개한 한국어 음성인식 모델을 제공하는 오픈소스 툴킷이다. Kospeech의 모델들은 End-to-End 방식을 따르는데, 여기서 End-to-End는 음성 데이터가 포함하는 문법, 발음 등의 특징까지 모두 모델이 학습하도록 하는 방식을 말한다. 따라서 Raw audio를 통째로 input으로 넣어주는 것이 특징이다.
-
즉, 오디오 신호가 입력되면 특징을 추출하고 특징들이 모델과 CTC 알고리즘을 통과하면서 텍스트로 출력된다.
-
STT를 구현하기 위해 필요한 음성데이터를 AI hub의 Kspon이라는 1,000시간의 한국어 음성 데이터와 이를 전사해 놓은 Label을 가져와 3가지 방식으로 전처리를 제공한다.
-
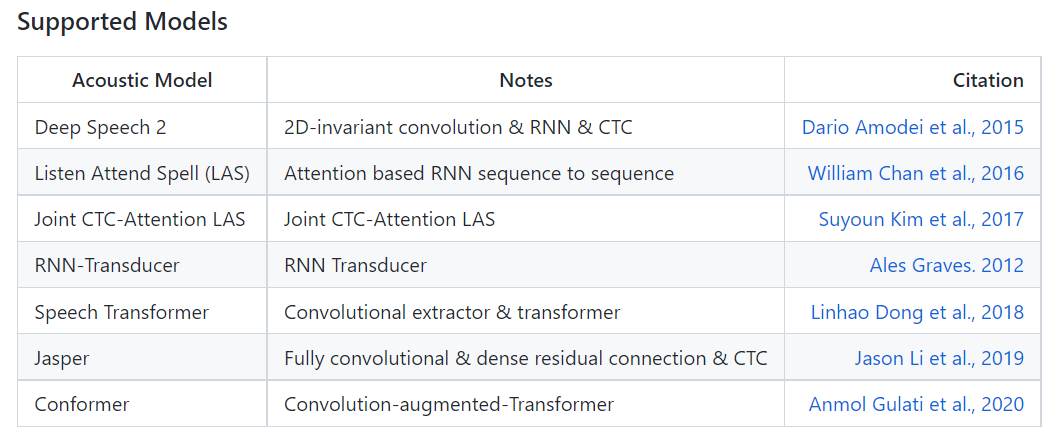
Pytorch 기반의 딥러닝 모델로 한국어만 지원하고 DeepSpeech2, Las, SpeechTransformer 등 다양한 모델과 프레임워크를 제공한다.
Kospeech 환경설정
먼저 기본적인 환경 같은 경우, 나는 해커톤 참가하고 노트북을 반납할꺼여서 따로 가상환경을 파지 않고 그대로 실행을 했다(복기해보면서 새로 가상환경 파긴 했다..ㅎㅎ) Window 10과 파이썬 3.8 기반으로 프로젝트를 실행했고, 다른 팀원들은 같은 조건으로 가상환경을 만들어서 실행했다.
노트북 자체에 내장 GPU가 있었지만, 메모리 부족 등의 이슈로 로컬 환경에서 학습이 불가했기 때문에, 팀원들과 Colab pro를 결제해서 진행을 했다.
가상환경
conda create -n kospeech python==3.8
- 그래서 깃에서 kospeech를 가져왔다면 아나콘다에서 kospeech로 가상환경을 만들어 주자!
conda activate kospeech
- 가상환경을 실행한 뒤 아래처럼 kospeech-latest 폴더(setup.py)가 있는 경로로 들어간다.
pip install -e .
- kospeech 깃 허브 readme에서 실행하라는대로 설치를 실행해준다.
- 설치를 하다 보면 여러 이유로 충돌이 일어나고 엄청 빨간줄이 뜨지만 그래도 완료가 되긴한다..ㅎ
- 막상 필요한 모듈을 설치를 했지만 나중에 없다고 에러가 뜨고 그랬다.
- 그러면 그때 필요한 모듈을 바로 설치하는 식으로 진행을 했다
💡
여기까지 왔으면 기본적으로 Kospeech를 통한 한국어 STT 모델 구현을 위해 준비가 끝난거라고 생각하면 된다.
다음 포스팅부터 본격적으로 kospeech를 활용하면서 겪은 시행착오에 대해 작성해 볼 생각이다!
참고로 우리가 참가한 해커톤이다.. 진짜 할많하않...

🙂


안녕하세요 좋은 포스팅 감사합니다!