공부의 목적
Spring Framework에 대해 공부하면서 계속 드는 생각은 그래서 왜? 어떤 점이 구체적으로 좋아서 Spring Framework를 쓰느냐였다. Spring Framework를 활용해서 기존에 있던 기술의 어떤 점을 해결했는지 알아야 그 부분을 계속 잘 활용하면서 Spring Framework를 이용할 수 있을 것 같았다.
따라서 이 포스팅에서 크게 답하고자 하는 질문은 두 가지이다.
Q1. 스프링이란 무엇인가?
Q2. DI란?
이 두 가지 질문을 종합하여 마지막에 스프링을 이용해야 하는 이유를 정리해보려고 한다.
Q1. 스프링이란 무엇인가?
스프링은 간단히 말해서 규모가 큰 애플리케이션을 자바로 만들 때 개발을 편하게 해주는 프레임워크이다.
구체적인 정의는 다음과 같다.
DIxAOP 컨테이너를 중심으로 MVC 프레임워크(스프링 MVC, 스프링 웹 플로), JDBC를 추상화한 프레임워크(스프링 JDBC), 기존 프레임워크와의 통합 기능 등을 개발자에게 제공하는 애플리케이션 아키텍쳐의 기반이 되는 것 - 스프링 4 입문 p.70 발췌
그렇다..
용어가 너무 어렵다. 위의 용어에 대해 모두 알고 있다면 저 정의를 모두 이해할 수 있을테지만, 아직 저 개념을 다 알지 못해서 먼저 spring core에 해당되고 가장 특징적인 기능인 DI에대해 알아보도록 하겠다.
Q2. 스프링 DI란?
Dependency Inversion으로 의존 관계의 주입을 말한다. 쉽게 말해 어떤 오브젝트의 프로퍼티(인스턴스 변수)에 그 오브젝트가 이용할 오브젝트를 설정한다는 의미이다.
그렇다면 무엇이 의존관계를 주입해줄까?
바로 IoC 컨테이너가 객체를 생성하고 관리하면서 의존관계를 연결해준다.
IoC
Inversion of Control로 프로그램을 구동하는데 필요한 객체에 대한 생성, 변경 등의 관리를 프로그램을 개발하는 사람이 아닌 프로그램을 구동하는 컨테이너에서 직접 관리하는 것을 말한다. 스프링은 IoC 구조를 통해 구동 시 필요한 객체의 생성부터 생명 주기까지 해당 객체에 대한 관리를 직접 수행한다.
IoC 컨테이너
스프링에서는 관리하는 객체를 'Bean(빈)'이라고 하고, 해당 빈들을 관리한다는 의미로 컨테이너를 'Bean Factory'라고 한다.
뒤의 설명을 쉽게 이해하기 위해서 일단 아래의 그림을 짚고 넘어가면, IoC 컨테이너는 POJO(Plain Old Java Object - 일반적으로 알고 있는 기본적인 기능만 가진 자바 객체)와 Bean으로 등록하고자 한 객체를 호출해서 반환한 Configuration Metadata를 가지고 해당 객체들을 모두 Bean으로 등록해준다.
그리고 해당 객체들을 생성하고 관리하면서 의존관계를 주입해준다.
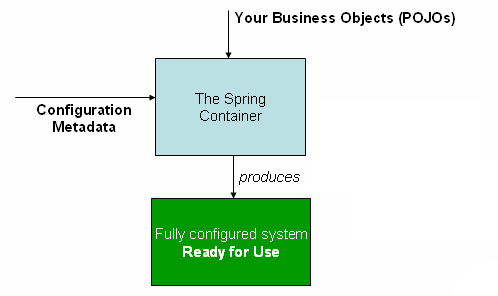
🔼 IoC 컨테이너가 하는 일
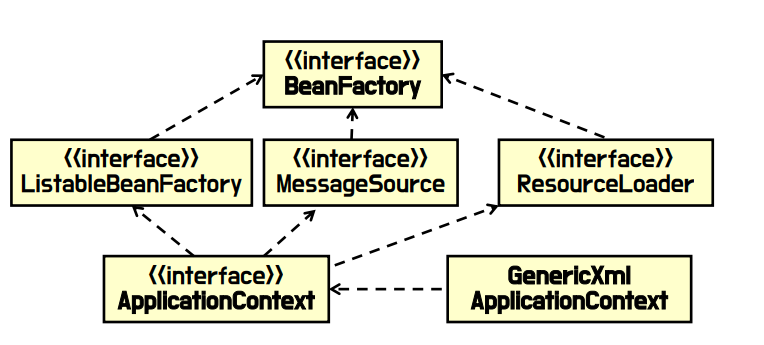
🔼 IoC 컨테이너 구조
IoC 컨테이너는 일반적으로 Application Context를 의미하는데, 먼저 최상위 인터페이스인 Bean Factory부터 보면, 빈을 객체 생성과 검색에 대한 기능 정의하며, getBean() 메서드가 정의되어 있다. Application Context는 Bean Factory를 확장한 인터페이스로 빈 객체의 생성, 초기화, 제거 등을 담당하며 보통 스프링 컨테이너라고 표현된다. 그리고 XML로 빈을 등록한다고 했을 때 빈 객체는 GenericXmlApplicationContext 클래스에서 XML 파일로부터 정보를 읽어와서 객체를 생성하고 초기화한다.
// IoC 컨테이너 - ApplicationContext
ApplicationContext context = new GenericXmlApplicationContext("com/greedy/section01/xmlconfig/spring-context.xml");
System.out.println(context);
// IoC 컨테이너를 통해 등록된 객체인 Bean을 가져올 수 있음!
MemberDTO member = (MemberDTO) context.getBean("member");🔼 XML 파일에 Bean을 등록해놓았을 때 getBean으로 인스턴스 생성하는 예시
객체를 Bean으로 등록하는 방법
객체를 Bean으로 등록하는 방법에는 여러가지가 있는데, 그 중 xml 파일에서 bean으로 해당 class를 등록하는 방법에 대해 알아보겠다. spring framework를 사용해서 구현한 프로젝트인 펫팔을 구현할 때 쓴 코드를 바탕으로 알아보자.
spring의 세팅 파일인 servlet-context.xml은 스프링 프로젝트가 실행되면 가장 먼저 web.xml을 읽어 들이게 되고 거기서 DispatcherServlet으로 이동한 다음, servlet-context.xml을 참조하게 된다. 그리고 이 설정 파일을 이용해서 스프링 컨테이너를 초기화시킬 수 있다. 펫팔 프로젝트를 구현할 때는 servlet-context.xml에서 component-scan을 통해 클래스를 빈으로 등록해주는 방식을 사용했다.
- 펫팔 프로젝트에서 Annotation을 사용할 수 있도록 설정해놓은 코드
<!-- Enables the Spring MVC @Controller programming model -->
<annotation-driven />- 펫팔에서 베이스 패키지를 스캔해서 Annotation을 명시한 클래스를 빈으로 등록해주는 코드
- @Component, @Service 등의 어노테이션이 설정된 클래스를 읽어들여서, DI 컨테이너에 등록되고 base-package 속성으로 지정한 패키지 아래의 컴포넌트를 검색한다.
<context:component-scan base-package="com.nobanryeo.petpal" />@Controller // 이렇게 어노테이션이 설정된 클래스를 읽어들인다.
@RequestMapping("/admin/*")
public class AdAdminController {
private AdAdminService adAdminService;
@Autowired
public AdAdminController(AdAdminService adAdminService) {
this.adAdminService = adAdminService;
}
}의존성을 주입해주는 방법
등록된 Bean 객체를 어떻게 불러와서 쓸 거냐에 따라 의존성 주입을 해주는 방식이 달라진다.
기본적으로 세가지 방식이 있다.
1. 생성자를 통한 의존성 주입
2. Getter, Setter를 통한 의존성 주입
3. 필드를 통한 의존성 주입
이 중 생성자를 통한 의존성 주입을 이용해서 펫팔을 구현했는데, 이에 대해 알아보기 전에 기본적으로 알아야 되는 개념이 Autowired이다.
Autowired
필요한 의존 객체의 타입에 해당하는 빈을 찾아 자동으로 주입해주는 어노테이션을 말한다. 타입을 찾아서 주입해서 동일한 Bean 타입의 객체가 여러개 있을 경우, Bean을 찾기 위해 @Qualifier 어노테이션을 같이 사용해야 한다.
그리고 Autowired는 기본값이 true이기 때문에 의존성 주입을 할 대상을 찾지 못한다면 애플리케이션 구동에 실패한다.
이제 펫팔 코드를 보면서 어떻게 생성자를 통해 의존성을 주입받았는지 보자.
@Service
public class AdAdminServiceImpl implements AdAdminService {
private AdAdminMapper adAdminMapper;
// 생성자를 통한 DI
@Autowired
public AdAdminServiceImpl(AdAdminMapper adAdminMapper) {
this.adAdminMapper = adAdminMapper;
}
}🔼 생성자를 통해 DI 받는 펫팔 코드
구현 클래스인 AdAdminServiceImpl에서 adAdminMapper 인터페이스의 의존성을 주입받는 코드이다.
의존성을 주입해주는 방법별 특성
그렇다면, 의존성을 주입해주는 방법별로 특성이 어떻게 될까?
위에서 살펴보았던 의존성을 주입해주는 방법에는 3가지가 있다.
- 생성자를 통한 의존성 주입
- Getter, Setter를 통한 의존성 주입
- 필드를 통한 의존성 주입
// 1. Constructor Injection with 'final' declaration
private final BoardDao boardDao;
public ChessServiceImpl(BoardDao boardDao) {
this.boardDao = boardDao;
}
// 2. Field Injection using Autowired Annotation
@Autowired
private BoardDao boardDao;
// 3. setter Injection with Autowired Annotation
private BoardDao boardDao;
@Autowired
public void setBoardDao(BoardDao boardDao) {
this.boardDao = boardDao;
}- setter 주입
장점
- 객체 생성 이후에도 객체를 변경할 수 있어, 변경이 발생하는 의존관계에서 사용 가능하다
단점 - 객체가 생성된 이후에 setter를 통해 의존성을 주입하는 방식이기에 객체의 상태값을 외부에서 변경할 수 있는 여지가 생겨 캡슐화가 깨질 수 있다
- 애플리케이션 동작 중에 의도치 않게 상태값이 변경될 수 있어 신뢰할 수 없게 된다
- 필드 주입
장점
- 코드가 간결해진다
단점 - 외부에서 필드의 객체 수정이 불가능해진다 (private)
- final 키워드(더이상 수정이 불가능한 필드) 사용이 불가능해진다. 그 이유는 final 선언된 필드는 객체의 생성 시점에 값이 할당되어야 하는데, 객체의 생성 이후에 의존성이 주입되기 때문이다. 필드 주입은 객체 생성 이후 reflection으로 우회해서 강제로 값을 할당한다.
cf. reflection이란?
구체적인 클래스 타입을 알지 못해도 동적으로 클래스를 사용해야 할 때, 그 클래스의 메소드, 타입, 변수들을 접근할 수 있도록 해주는 자바 API
런타임 시에 개발자가 등록한 빈을 어플리케이션에서 가져와 사용할 수 있도록 한다.
- 생성자 주입
컴파일 시점에 객체를 주입받게 되는 방식
장점
- 생성자의 호출시점에 주입하는 객체가 1회 호출되는 것이 보장된다 -> 객체 생성 시점에 딱 한 번만 호출되므로 불변하게 설계 가능
- 주입받은 객체가 변하지 않는다
- DI를 강제할 수 있다
- final 키워드를 사용할 수 있다 -> 대부분의 의존관계는 애플리케이션 종료까지 변하지 않아야 좋은 설계이다
--- 정리하면 ---
- 필수적으로 사용해야 하는 reference 없이는 인스턴스를 만들지 못하도록 강제할 수 있음. 의존관계 설정이 되지 않으면 객체 생성 불가 → 컴파일 타임에 인지 가능, NPE 방지
- reference (DI 되는 클래스)가 반드시 있어야 클래스가 제대로 동작 가능
- 강제하기 위해 가장 좋은 수단이 생성자를 사용해서 DI 하는 것
- setter나 필드를 통해서 DI를 하면 의존성 없이도 인스턴스 생성 가능 다만, 인스턴스들이 “Circular Dependency(순환 참조)”를 하는 경우에는 생성자로 Injection을 했을 때 생성되지 않음 이것이 setter나 필드로 Injection 하는 것의 장점이 되기도 함 일단 인스턴스를 생성해 두고서는 서로의 인스턴스를 주입해줄 수 있음 이 경우에 Circular Dependency 문제 해결 가능 (그러나 순환 참조가 그리 좋진 않음)
https://www.youtube.com/watch?v=IVzYerodIyg
생성자 주입 방식을 사용하면 좋은 이유?
- final 키워드 사용을 통한 객체의 불변성 확보
setter와 필드로 의존성을 주입하는 방식은 객체의 생성자 호출 이후에 주입되므로 final 키워드를 사용할 수 없지만, 생성자로 의존성을 주입하는 방식은 객체가 생성되는 시점에 값이 할당되므로 final 키워드를 사용해서 Bean 간 의존성이 변경되는 가능성을 배제하고 불변성을 보장할 수 있다. - final 키워드를 사용해서 컴파일 시점(객체 생성 시점)에서 오류 검출 가능
final 키워드 사용으로 생성자에서 혹시라도 값이 설정되지 않는 오류를 컴파일 시점에서 검출할 수 있다. 즉, 컴파일 시점에 객체를 주입 받으므로 해당 시점에 주입 관계에서의 오류까지 잡아낼 수 있다.
DI를 사용하는 이유는?
그렇다면, DI를 사용하는 이유는 무엇일까? 이를 이해하기 위해서는 DI는 다양한 의존관계가 인터페이스로 추상화되고 있다는 것을 알아야 한다. 위의 코드에도 인터페이스인 객체의 의존성을 주입받았는데, "인터페이스"를 활용하는 이유는 다음과 같다.
class BurgerChef {
private BurgerRecipe burgerRecipe;
public BurgerChef() {
burgerRecipe = new HamBurgerRecipe();
//burgerRecipe = new CheeseBurgerRecipe();
//burgerRecipe = new ChickenBurgerRecipe();
}
}
interface BugerRecipe {
newBurger();
// 이외의 다양한 메소드
}
class HamBurgerRecipe implements BurgerRecipe {
public Burger newBurger() {
return new HamBerger();
}
// ...
}의존관계를 인터페이스로 추상화하게 되면, 더 다양한 의존 관계를 맺을 수가 있고, 실제 구현 클래스와의 관계가 느슨해지고, 결합도가 낮아진다. 하나의 BurgerRecipe가 아니라 다양한 BurgerRecipe를 가진 인터페이스 안의 메소드들을 활용해서 의존성을 주입받은 클래스에서는 해당 클래스에서 필요한 메소드만 가지고 구현을 할 수 있다. 바로 해당 클래스를 연결해서 new 키워드로 객체를 생성하면 그 객체를 수정하면 클래스의 코드 또한 수정해야 한다. 그러나 인터페이스의 경우 이미 다른 메소드를 활용하고 있기 때문에 클래스의 코드를 따로 수정할 필요가 없다.
따라서, 정리하면 DI를 사용하는 이유는
-
의존성이 줄어든다.
DI로 구현하게 되었을 때, 주입받는 대상이 변하더라도 그 구현 자체를 수정할 일이 없거나 줄어들게 된다. -
재사용성이 높은 코드가 된다.
기존에 객체를 생성했던 클래스 내부에서만 사용되었던 객체를 별도로 구분하여 구현하면, 다른 클래스에서 재사용할 수가 있다. -
테스트하기 좋은 코드가 된다.
의존성을 주입받은 클래스의 테스트를 의존한 객체와 분리하여 진행할 수 있다.
스프링을 사용하는 이유?
DI의 특성과 장점에 대해 정리했으면, 여기까지 보았을 때 스프링을 사용해야 하는 이유의 일부를 정리해볼 수 있다.
- 오브젝트의 생명주기를 DI 컨테이너로 해결할 수 있다
- DI 컨테이너를 통해 오브젝트 간 약한 결합을 유지하여 오브젝트를 쉽게 확장 및 변경이 가능하다
먼저, DI 컨테이너를 통해 오브젝트의 생명주기를 관리할 수 있다. 그 중 한 가지 방법으로 인스턴스의 생성과 소멸 타이밍에 호출되는 메서드를 설정하기 위해 @PostConstruct와 @preDestroy라는 2개의 어노테이션이 있다.
- @PostConstruct : 초기화 하는 메서드 선언. DI 컨테이너에 의해 인스턴스 변수에 무언가 인젝션된 다음에 호출되어 인젝션된 값으로 초기화를 할 때 사용.
- @PreDestroy : 종료 처리를 하는 메서드 선언.
두 번째로, DI 컨테이너를 활용해서 오브젝트 간에 약한 결합을 유지하고 오브젝트를 쉽게 확장 및 변경이 가능하다. 위에서 말한대로 인터페이스를 매개로 구현에 의존하지 않음으로써 약한 결합으로 유지가 가능한데, 기본적으로 DI를 하면 어떤 객체를 다른 클래스에서 사용할 때, 해당 객체를 변경하면 그 객체를 생성한 다른 클래스에서도 똑같이 변경해줄 필요가 없다.
의존성을 주입받는 클래스를 변경해줄 필요가 없다는 게 계속 잘 이해되지 않았는데, 이번에 좋은 예시를 찾았다.
- new 키워드를 쓰는 강한 결합하는 경우

Cat이라는 클래스에서 Animal 객체를 생성
1. Animal이라는 객체를 선언
public class Animal {
}- Cat이라는 클래스에서 Animal 객체를 생성
public class Cat{
public Animal animal;
public Cat() {
this.animal = new Animal();
}
}- Animal 클래스에서 Animal 객체에게 이름을 지어준다면,
public class Animal {
public Animal(String name) {
}
}- Cat 클래스에 있는 Animal 객체에게도 해당 변경사항을 적용시켜 줘야한다.
public class Cat{
public Animal animal;
public Cat() {
this.animal = new Animal(String name);
}
}- DI를 사용해서 약한 결합하는 경우
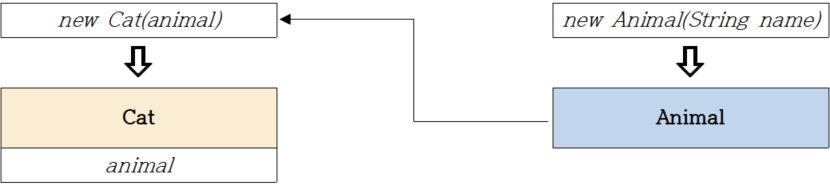
객체를 변경하면 해당 객체를 재사용한 곳에 자동적으로 반영된다.
public class Cat {
private final Animal animal;
public Cat(Animal animal) {
this.animal = animal;
}
}
Cat cat = new Cat(animal);- Animal 객체에게 이름을 지어줘도,
public class Animal {
}
Animal animal = new Animal(String name);- 변경을 할 데가 없다.
public class Cat {
private final Animal animal;
public Cat(Animal animal) {
this.animal = animal;
}
}
Cat cat = new Cat(animal);다음에 공부할 것
spring-core의 다른 중요한 부분인 AOP에 대해서 공부해보아야겠다.
Ref.
https://velog.io/@suyeon-jin/리플렉션-스프링의-DI는-어떻게-동작하는걸까
https://velog.io/@zihs0822/DI의존성-주입-방식별-장단점
https://creampuffy.tistory.com/156
https://life-with-coding.tistory.com/433
https://devlog-wjdrbs96.tistory.com/166
https://tecoble.techcourse.co.kr/post/2021-04-27-dependency-injection/
https://velog.io/@raddaslul/강한-결합을-약한-결합으로DI
